详解Bagging算法的原理及Python实现
目录
- 一、什么是集成学习
- 二、Bagging算法
- 三、Bagging用于分类
- 四、Bagging用于回归
一、什么是集成学习
集成学习是一种技术框架,它本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务,一般结构是:先产生一组“个体学习器”,再用某种策略将它们结合起来,目前,有三种常见的集成学习框架(策略):bagging,boosting和stacking
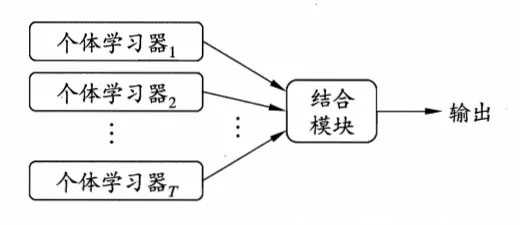
也就是说,集成学习有两个主要的问题需要解决,第一是如何得到若干个个体学习器,第二是如何选择一种结合策略,将这些个体学习器集合成一个强学习器
集成学习是指将若干弱分类器组合之后产生一个强分类器。弱分类器(weak learner)指那些分类准确率只稍好于随机猜测的分类器(error rate < 50%)。如今集成学习有两个流派,一种是bagging流派,它的特点是各个弱学习器之间没有依赖关系,可以并行拟合,随机森林算法就属于bagging派系;另一个是boosting派系,它的特点是各个弱学习器之间有依赖关系,Adaboost算法就属于boosting派系。在实现集成学习算法时,很重要的一个核心就是如何实现数据的多样性,从而实现弱分类器的多样性
集成学习有如下的特点:
(1)将多个分类方法聚集在一起,以提高分类的准确率(这些算法可以是不同的算法,也可以是相同的算法。);
(2)集成学习法由训练数据构建一组基分类器,然后通过对每个基分类器的预测进行投票来进行分类;
(3)严格来说,集成学习并不算是一种分类器,而是一种分类器结合的方法;
(4)通常一个集成分类器的分类性能会好于单个分类器;
(5)如果把单个分类器比作一个决策者的话,集成学习的方法就相当于多个决策者共同进行一项决策。
Bagging和Boosting的使用区别如下:
1)样本选择:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
5)计算效果
Bagging主要减小了variance,而Boosting主要减小了bias,而这种差异直接推动结合Bagging和Boosting的MultiBoosting的诞生
二、Bagging算法
Bagging(装袋算法)的集成学习方法非常简单,假设我们有一个数据集D,使用Bootstrap sample(有放回的随机采样,这里说明一下,有放回抽样是抽一个就放回一个,然后再抽,而不是这个人抽10个,再放回,下一个继续抽,它是每一个样本被抽中概率符合均匀分布)的方法取了k个数据子集(子集样本数都相等):D1,D2,…,Dk,作为新的训练集,我们使用这k个子集分别训练一个分类器(使用分类、回归等算法),最后会得到k个分类模型。我们将测试数据输入到这k个分类器,会得到k个分类结果,比如分类结果是0和1,那么这k个结果中谁占比最多,那么预测结果就是谁。
大致过程如下:
1.对于给定的训练样本S,每轮从训练样本S中采用有放回抽样(Booststraping)的方式抽取M个训练样本,共进行n轮,得到了n个样本集合,需要注意的是这里的n个训练集之间是相互独立的。
2.在获取了样本集合之后,每次使用一个样本集合得到一个预测模型,对于n个样本集合来说,我们总共可以得到n个预测模型。
3.如果我们需要解决的是分类问题,那么我们可以对前面得到的n个模型采用投票的方式得到分类的结果,对于回归问题来说,我们可以采用计算模型均值的方法来作为最终预测的结果。

那么我们什么时候该使用bagging集成方法:学习算法不稳定:就是说如果训练集稍微有所改变就会导致分类器性能比较大大变化那么我们可以采用bagging这种集成方法AdaBoost只适用于二分类任务不同,Bagging可以用于多分类,回归的任务举个例子可以看出bagging的好处:X 表示一维属性,Y 表示类标号(1或-1)测试条件:当x<=k时,y=?;当x>k时,y=?;k为最佳分裂点下表为属性x对应的唯一正确的y类别:

每一轮随机抽样后,都生成一个分类器。然后再将五轮分类融合

即是说当我们模型拿捏不住样本属于哪个,或者是分裂时的阈值,我们多做几次,得到多个结果,然后投票决定
优缺点:
(1) Bagging通过降低基分类器的方差,改善了泛化误差;
(2)其性能依赖于基分类器的稳定性;如果基分类器不稳定,bagging有助于降低训练数据的随机波动导致的误差;如果稳定,则集成分类器的误差主要由基分类器的偏倚引起;
(3)由于每个样本被选中的概率相同,因此bagging并不侧重于训练数据集中的任何特定实例
1.优点,可以减小方差和减小过拟合
2.缺点,重复有放回采样的道德样本集改变了数据原有的分布,因此在一定程度上引入了偏差,对最终的结果预测会造成一定程度的影响
为什么说Bagging算法会减少方差?
首先我们来看看偏差和方差的概念
偏差:描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据
方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大
- bias描述的是根据样本拟合出的模型的输出预测结果的期望与样本真实结果的差距,简单讲,就是在样本上拟合的好不好。要想在bias上表现好,low bias,就得复杂化模型,增加模型的参数,但这样容易过拟合 (overfitting),过拟合对应上图是high variance,点很分散。low bias对应就是点都打在靶心附近,所以瞄的是准的,但手不一定稳。
- varience描述的是样本上训练出来的模型在测试集上的表现,要想在variance上表现好,low varience,就要简化模型,减少模型的参数,但这样容易欠拟合(unfitting),欠拟合对应上图是high bias,点偏离中心。low variance对应就是点都打的很集中,但不一定是靶心附近,手很稳,但是瞄的不准。
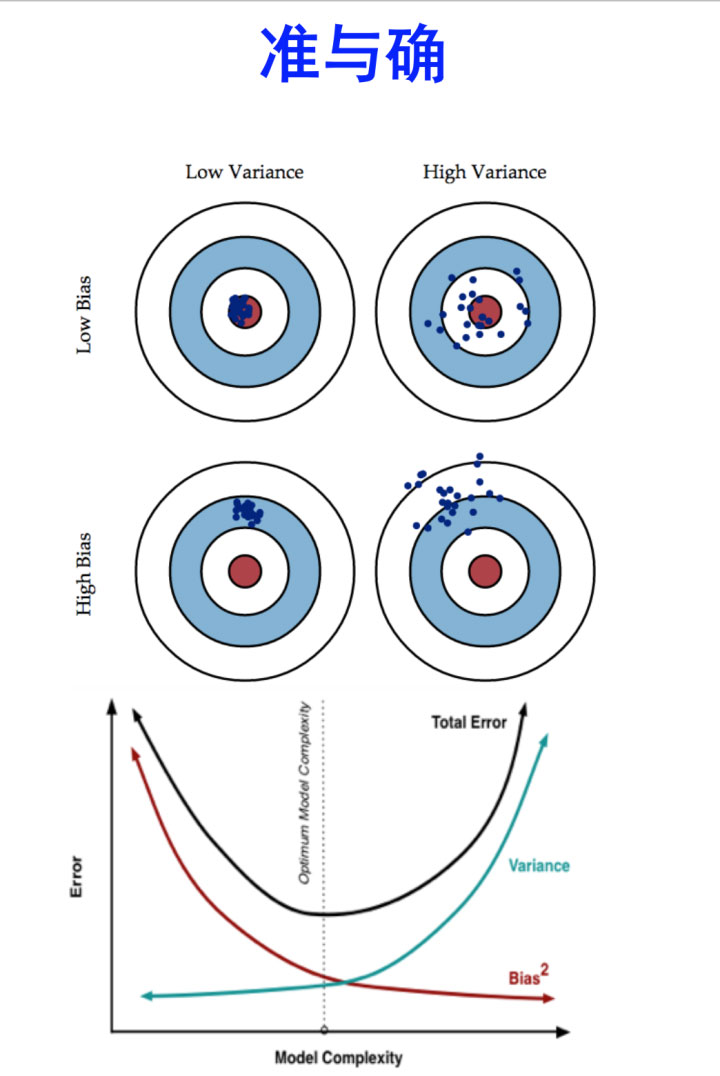
bagging是对许多强(甚至过强)的分类器求平均。在这里,每个单独的分类器的bias都是低的,平均之后bias依然低;而每个单独的分类器都强到可能产生overfitting的程度,也就是variance高,求平均的操作起到的作用就是降低这个variance。
boosting是把许多弱的分类器组合成一个强的分类器。弱的分类器bias高,而强的分类器bias低,所以说boosting起到了降低bias的作用。variance不是boosting的主要考虑因素。Boosting则是迭代算法,每一次迭代都根据上一次迭代的预测结果对样本进行加权,所以随着迭代不断进行,误差会越来越小,所以模型的bias会不断降低。这种算法无法并行,例子比如Adaptive Boosting
Bagging和Rand Forest
1)Rand Forest是选与输入样本的数目相同多的次数(可能一个样本会被选取多次,同时也会造成一些样本不会被选取到),而Bagging一般选取比输入样本的数目少的样本
2)bagging是用全部特征来得到分类器,而Rand Forest是需要从全部特征中选取其中的一部分来训练得到分类器; 一般Rand forest效果比Bagging效果好!
三、Bagging用于分类
我们使用葡萄酒数据集进行建模(数据处理):
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 11 10:12:48 2020
@author: Admin
"""
## 我们使用葡萄酒数据集进行建模(数据处理)
import pandas as pd
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
df_wine.columns = ['Class label', 'Alcohol','Malic acid', 'Ash','Alcalinity of ash','Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols','Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
df_wine['Class label'].value_counts()
'''
2 71
1 59
3 48
Name: Class label, dtype: int64
'''
df_wine = df_wine[df_wine['Class label'] != 1] # drop 1 class
y = df_wine['Class label'].values
X = df_wine[['Alcohol','OD280/OD315 of diluted wines']].values
from sklearn.model_selection import train_test_split # 切分训练集与测试集
from sklearn.preprocessing import LabelEncoder # 标签化分类变量
le = LabelEncoder()
y = le.fit_transform(y) #吧y值改为0和1 ,原来是2和3
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y) #2、8分
## 我们使用单一决策树分类:
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=None) #选择决策树为基本分类器
from sklearn.metrics import accuracy_score #计算准确率
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred) #训练集准确率
tree_test = accuracy_score(y_test,y_test_pred) #测试集准确率
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))
#Decision tree train/test accuracies 1.000/0.833
## 我们使用BaggingClassifier分类:
from sklearn.ensemble import BaggingClassifier
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=None) #选择决策树为基本分类器
bag = BaggingClassifier(base_estimator=tree,n_estimators=500,max_samples=1.0,max_features=1.0,bootstrap=True,
bootstrap_features=False,n_jobs=1,random_state=1)
from sklearn.metrics import accuracy_score
bag = bag.fit(X_train,y_train)
y_train_pred = bag.predict(X_train)
y_test_pred = bag.predict(X_test)
bag_train = accuracy_score(y_train,y_train_pred)
bag_test = accuracy_score(y_test,y_test_pred)
print('Bagging train/test accuracies %.3f/%.3f' % (bag_train,bag_test))
#Bagging train/test accuracies 1.000/0.917
'''
我们可以对比两个准确率,测试准确率较之决策树得到了显著的提高
我们来对比下这两个分类方法上的差异
'''
## 我们来对比下这两个分类方法上的差异
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2,sharex='col',sharey='row',figsize=(12, 6))
for idx, clf, tt in zip([0, 1],[tree, bag],['Decision tree', 'Bagging']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) #ravel()方法将数组维度拉成一维数组,np.c_是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0],X_train[y_train==0, 1],c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0],X_train[y_train==1, 1],c='green', marker='o')
axarr[idx].set_title(tt)
axarr[0].set_ylabel('Alcohol', fontsize=12)
plt.tight_layout()
plt.text(0, -0.2,s='OD280/OD315 of diluted wines',ha='center',va='center',fontsize=12,transform=axarr[1].transAxes)
plt.show()
'''
从结果图看起来,三个节点深度的决策树分段线性决策边界在Bagging集成中看起来更加平滑
'''

class sklearn.ensemble.BaggingClassifier(base_estimator=None, n_estimators=10, max_samples=1.0, max_features=1.0, bootstrap=True, bootstrap_features=False, oob_score=False, warm_start=False, n_jobs=None, random_state=None, verbose=0)
参数说明:
- base_estimator:Object or None。None代表默认是DecisionTree,Object可以指定基估计器(base estimator)
- n_estimators:int, optional (default=10) 。 要集成的基估计器的个数
- max_samples: int or float, optional (default=1.0)。决定从x_train抽取去训练基估计器的样本数量。int 代表抽取数量,float代表抽取比例
- max_features : int or float, optional (default=1.0)。决定从x_train抽取去训练基估计器的特征数量。int 代表抽取数量,float代表抽取比例
- bootstrap : boolean, optional (default=True) 决定样本子集的抽样方式(有放回和不放回)
- bootstrap_features : boolean, optional (default=False)决定特征子集的抽样方式(有放回和不放回)
- oob_score : bool 决定是否使用包外估计(out of bag estimate)泛化误差
- warm_start : bool, optional (default=False) 设置为True时,请重用上一个调用的解决方案以适合并为集合添加更多估计量,否则,仅适合一个全新的集合
- n_jobs : int, optional (default=None) fit和 并行运行的作业数predict。None除非joblib.parallel_backend上下文中,否则表示1 。-1表示使用所有处理器
- random_state : int, RandomState instance or None, optional (default=None)。如果int,random_state是随机数生成器使用的种子; 如果RandomState的实例,random_state是随机数生成器; 如果None,则随机数生成器是由np.random使用的RandomState实例
- verbose : int, optional (default=0)
属性介绍:
- estimators_ : list of estimators。The collection of fitted sub-estimators.
- estimators_samples_ : list of arrays
- estimators_features_ : list of arrays
- oob_score_ : float,使用包外估计这个训练数据集的得分。
- oob_prediction_ : array of shape = [n_samples]。在训练集上用out-of-bag估计计算的预测。 如果n_estimator很小,则可能在抽样过程中数据点不会被忽略。 在这种情况下,oob_prediction_可能包含NaN。
四、Bagging用于回归
再补充一下Bagging用于回归
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 11 10:12:48 2020
@author: Admin
"""
# 从 sklearn.datasets 导入波士顿房价数据读取器。
from sklearn.datasets import load_boston
# 从读取房价数据存储在变量 boston 中。
boston = load_boston()
# 从sklearn.cross_validation 导入数据分割器。
from sklearn.model_selection import train_test_split
X = boston.data
y = boston.target
# 随机采样 25% 的数据构建测试样本,其余作为训练样本。
X_train, X_test, y_train, y_test = train_test_split(X,
y,
random_state=33,
test_size=0.25)
# 从 sklearn.preprocessing 导入数据标准化模块。
from sklearn.preprocessing import StandardScaler
# 分别初始化对特征和目标值的标准化器。
ss_X = StandardScaler()
ss_y = StandardScaler()
# 分别对训练和测试数据的特征以及目标值进行标准化处理。
X_train = ss_X.fit_transform(X_train)
X_test = ss_X.transform(X_test)
y_train = ss_y.fit_transform(y_train.reshape(-1,1))
y_test = ss_y.transform(y_test.reshape(-1,1))
#BaggingRegressor
from sklearn.ensemble import BaggingRegressor
bagr = BaggingRegressor(n_estimators=500,max_samples=1.0,max_features=1.0,bootstrap=True,
bootstrap_features=False,n_jobs=1,random_state=1)
bagr.fit(X_train, y_train)
bagr_y_predict = bagr.predict(X_test)
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
# 使用 R-squared、MSE 以及 MAE 指标对默认配置的随机回归森林在测试集上进行性能评估。
print('R-squared value of BaggingRegressor:', bagr.score(X_test, y_test))
print('The mean squared error of BaggingRegressor:', mean_squared_error(
ss_y.inverse_transform(y_test), ss_y.inverse_transform(bagr_y_predict)))
print('The mean absoluate error of BaggingRegressor:', mean_absolute_error(
ss_y.inverse_transform(y_test), ss_y.inverse_transform(bagr_y_predict)))
'''
R-squared value of BaggingRegressor: 0.8417369323817341
The mean squared error of BaggingRegressor: 12.27192314456692
The mean absoluate error of BaggingRegressor: 2.2523244094488195
'''
#随机森林实现
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor(random_state=1)
rfr.fit(X_train, y_train)
rfr_y_predict = rfr.predict(X_test)
# 使用 R-squared、MSE 以及 MAE 指标对默认配置的随机回归森林在测试集上进行性能评估。
print('R-squared value of RandomForestRegressor:', rfr.score(X_test, y_test))
print('The mean squared error of RandomForestRegressor:', mean_squared_error(
ss_y.inverse_transform(y_test), ss_y.inverse_transform(rfr_y_predict)))
print('The mean absoluate error of RandomForestRegressor:', mean_absolute_error(
ss_y.inverse_transform(y_test), ss_y.inverse_transform(rfr_y_predict)))
'''
R-squared value of RandomForestRegressor: 0.8083674472512408
The mean squared error of RandomForestRegressor: 14.859436220472439
The mean absoluate error of RandomForestRegressor: 2.4732283464566924
'''
#用Bagging集成随机森林
bagr = BaggingRegressor(base_estimator=rfr,n_estimators=500,max_samples=1.0,max_features=1.0,bootstrap=True,
bootstrap_features=False,n_jobs=1,random_state=1)
bagr.fit(X_train, y_train)
bagr_y_predict = bagr.predict(X_test)
# 使用 R-squared、MSE 以及 MAE 指标对默认配置的随机回归森林在测试集上进行性能评估。
print('R-squared value of BaggingRegressor:', bagr.score(X_test, y_test))
print('The mean squared error of BaggingRegressor:', mean_squared_error(
ss_y.inverse_transform(y_test), ss_y.inverse_transform(bagr_y_predict)))
print('The mean absoluate error of BaggingRegressor:', mean_absolute_error(
ss_y.inverse_transform(y_test), ss_y.inverse_transform(bagr_y_predict)))
'''
R-squared value of BaggingRegressor: 0.8226953069216255
The mean squared error of BaggingRegressor: 13.748435433319694
The mean absoluate error of BaggingRegressor: 2.3744811023622048
'''
以上就是详解Bagging算法的原理及Python实现的详细内容,更多关于Python Bagging算法 的资料请关注我们其它相关文章!
相关推荐
-
基于sklearn实现Bagging算法(python)
本文使用的数据类型是数值型,每一个样本6个特征表示,所用的数据如图所示: 图中A,B,C,D,E,F列表示六个特征,G表示样本标签.每一行数据即为一个样本的六个特征和标签. 实现Bagging算法的代码如下: from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.preprocessing import StandardScaler i
-
python动态规划算法实例详解
如果大家对这个生僻的术语不理解的话,那就先听小编给大家说个现实生活中的实际案例吧,虽然现在手机是相当的便捷,还可以付款,但是最初的时候,我们经常会使用硬币,其中,我们如果遇到手中有很多五毛或者1块钱硬币,要怎么凑出来5元钱呢?这么一个过程也可以称之为动态规划算法,下面就来看下详细内容吧. 从斐波那契数列看动态规划 斐波那契数列:Fn = Fn-1 + Fn-2 ( n = 1,2 fib(1) = fib(2) = 1) 练习:使用递归和非递归的方法来求解斐波那契数列的第 n 项 代码如下: #
-

Python实现粒子群算法的示例
粒子群算法是一种基于鸟类觅食开发出来的优化算法,它是从随机解出发,通过迭代寻找最优解,通过适应度来评价解的品质. PSO算法的搜索性能取决于其全局探索和局部细化的平衡,这在很大程度上依赖于算法的控制参数,包括粒子群初始化.惯性因子w.最大飞翔速度和加速常数与等. PSO算法具有以下优点: 不依赖于问题信息,采用实数求解,算法通用性强. 需要调整的参数少,原理简单,容易实现,这是PSO算法的最大优点. 协同搜索,同时利用个体局部信息和群体全局信息指导搜索. 收敛速度快, 算法对计算机内存和CPU要
-
Python实现迪杰斯特拉算法并生成最短路径的示例代码
def Dijkstra(network,s,d):#迪杰斯特拉算法算s-d的最短路径,并返回该路径和代价 print("Start Dijstra Path--") path=[]#s-d的最短路径 n=len(network)#邻接矩阵维度,即节点个数 fmax=999 w=[[0 for i in range(n)]for j in range(n)]#邻接矩阵转化成维度矩阵,即0→max book=[0 for i in range(n)]#是否已经是最小的标记列表 dis=[
-
python里反向传播算法详解
反向传播的目的是计算成本函数C对网络中任意w或b的偏导数.一旦我们有了这些偏导数,我们将通过一些常数 α的乘积和该数量相对于成本函数的偏导数来更新网络中的权重和偏差.这是流行的梯度下降算法.而偏导数给出了最大上升的方向.因此,关于反向传播算法,我们继续查看下文. 我们向相反的方向迈出了一小步--最大下降的方向,也就是将我们带到成本函数的局部最小值的方向. 图示演示: 反向传播算法中Sigmoid函数代码演示: # 实现 sigmoid 函数 return 1 / (1 + np.exp(-x))
-
python 实现Harris角点检测算法
算法流程: 将图像转换为灰度图像 利用Sobel滤波器求出 海森矩阵 (Hessian matrix) : 将高斯滤波器分别作用于Ix².Iy².IxIy 计算每个像素的 R= det(H) - k(trace(H))².det(H)表示矩阵H的行列式,trace表示矩阵H的迹.通常k的取值范围为[0.04,0.16]. 满足 R>=max(R) * th 的像素点即为角点.th常取0.1. Harris算法实现: import cv2 as cv import numpy as np impo
-
Python用摘要算法生成token及检验token的示例代码
# 基础版,不依赖环境 import time import base64 import hashlib class Token_hander(): def __init__(self,out_time): self.out_time = out_time self.time = self.timer pass def timer(self): return time.time() def hax(self,str): """ 摘要算法加密 :param str: 待加密字符
-
Python实现K-means聚类算法并可视化生成动图步骤详解
K-means算法介绍 简单来说,K-means算法是一种无监督算法,不需要事先对数据集打上标签,即ground-truth,也可以对数据集进行分类,并且可以指定类别数目 牧师-村民模型 K-means 有一个著名的解释:牧师-村民模型: 有四个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的村民,于是每个村民到离自己家最近的布道点去听课. 听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的村民的地址,搬到了所有地址的中心地带,并且在海
-
详解Bagging算法的原理及Python实现
目录 一.什么是集成学习 二.Bagging算法 三.Bagging用于分类 四.Bagging用于回归 一.什么是集成学习 集成学习是一种技术框架,它本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务,一般结构是:先产生一组"个体学习器",再用某种策略将它们结合起来,目前,有三种常见的集成学习框架(策略):bagging,boosting和stacking 也就是说,集成学习有两个主要的问题需要解决,第一是如何得到若干个个体学习器,第二是如何选择一种结合策
-
图文详解梯度下降算法的原理及Python实现
目录 1.引例 2.数值解法 3.梯度下降算法 4.代码实战:Logistic回归 1.引例 给定如图所示的某个函数,如何通过计算机算法编程求f(x)min? 2.数值解法 传统方法是数值解法,如图所示 按照以下步骤迭代循环直至最优: ① 任意给定一个初值x0: ② 随机生成增量方向,结合步长生成Δx: ③ 计算比较f(x0)与f(x0+Δx)的大小,若f(x0+Δx)<f(x0)则更新位置,否则重新生成Δx: ④ 重复②③直至收敛到最优f(x)min. 数值解法最大的优点是编程简明,但缺陷也很
-
详解MD5算法的原理以及C#和JS的实现
目录 一.简介 二.C# 代码实现 三.js 代码实现 一.简介 MD5 是哈希算法(散列算法)的一种应用.Hash 算法虽然被称为算法,但实际上它更像是一种思想.Hash 算法没有一个固定的公式,只要符合散列思想的算法都可以被称为是 Hash 算法. 算法目的就是,把任意长度的输入(又叫做预映射 pre-image),通过散列算法变换成固定长度的输出,该输出就是散列值. 注意,不同的输入可能会散列成相同的输出,所以不能从散列值来确定唯一的输入值. 散列函数简单的说就是:一种将任意长度的消息压缩
-
图文详解感知机算法原理及Python实现
目录 写在前面 1.什么是线性模型 2.感知机概述 3.手推感知机原理 4.Python实现 4.1 创建感知机类 4.2 更新权重与偏置 4.3 判断误分类点 4.4 训练感知机 4.5 动图可视化 5.总结 写在前面 机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用.“深”在详细推导算法模型背后的数学原理:“广”在分析多个机器学习模型:决策树.支持向量机.贝叶斯与马尔科夫决策.强化学习等. 本期目标:实现这样一个效果 1.什么是线性模型 线性模型的假设形式是属性权重.偏置与属性
-
详解K-means算法在Python中的实现
K-means算法简介 K-means是机器学习中一个比较常用的算法,属于无监督学习算法,其常被用于数据的聚类,只需为它指定簇的数量即可自动将数据聚合到多类中,相同簇中的数据相似度较高,不同簇中数据相似度较低. K-MEANS算法是输入聚类个数k,以及包含 n个数据对象的数据库,输出满足方差最小标准k个聚类的一种算法.k-means 算法接受输入量 k :然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高:而不同聚类中的对象相似度较小. 核心思想 通过迭代寻找
-
python实现连续变量最优分箱详解--CART算法
关于变量分箱主要分为两大类:有监督型和无监督型 对应的分箱方法: A. 无监督:(1) 等宽 (2) 等频 (3) 聚类 B. 有监督:(1) 卡方分箱法(ChiMerge) (2) ID3.C4.5.CART等单变量决策树算法 (3) 信用评分建模的IV最大化分箱 等 本篇使用python,基于CART算法对连续变量进行最优分箱 由于CART是决策树分类算法,所以相当于是单变量决策树分类. 简单介绍下理论: CART是二叉树,每次仅进行二元分类,对于连续性变量,方法是依次计算相邻两元素值的中位
-
详解KMP算法以及python如何实现
算法思路 Knuth-Morris-Pratt(KMP)算法是解决字符串匹配问题的经典算法,下面通过一个例子来演示一下: 给定字符串"BBC ABCDAB ABCDABCDABDE",检查里面是否包含另一个字符串"ABCDABD". 1.从头开始依次匹配字符,如果不匹配就跳到下一个字符 2.直到发现匹配字符,然后经过一个内循环严查字符串是否匹配 3.发现最后一个D不匹配,下面就该思考应该把字符串向右移动多少个位置呢?传统做法可能是移动一格,KMP算法就创新在这里.K
-
详解Dijkstra算法原理及其C++实现
目录 什么是最短路径问题 Dijkstra算法 实现思路 案例分析 代码实现 什么是最短路径问题 如果从图中某一顶点(称为源点)到达另一顶点(称为终点)的路径可能不止一条,如何找到一条路径使得沿此路径上各边上的权值总和达到最小. 单源最短路径问题是指对于给定的图G=(V,E),求源点v0到其它顶点vt的最短路径. Dijkstra算法 Dijkstra算法用于计算一个节点到其他节点的最短路径.Dijkstra是一种按路径长度递增的顺序逐步产生最短路径的方法,是一种贪婪算法. Dijkstra算法
-
详解 Java HashMap 实现原理
HashMap 是 Java 中最常见数据结构之一,它能够在 O(1) 时间复杂度存储键值对和根据键值读取值操作.本文将分析其内部实现原理(基于 jdk1.8.0_231). 数据结构 HashMap 是基于哈希值的一种映射,所谓映射,即可以根据 key 获取到相应的 value.例如:数组是一种的映射,根据下标能够取到值.不过相对于数组,HashMap 占用的存储空间更小,复杂度却同样为 O(1). HashMap 内部定义了一排"桶",用一个叫 table 的 Node 数组表示:
-
详解Dijkstra算法之最短路径问题
一.最短路径问题介绍 问题解释: 从图中的某个顶点出发到达另外一个顶点的所经过的边的权重和最小的一条路径,称为最短路径 解决问题的算法: 迪杰斯特拉算法(Dijkstra算法) 弗洛伊德算法(Floyd算法) SPFA算法 这篇博客,我们就对Dijkstra算法来做一个详细的介绍 二.Dijkstra算法介绍 2.1.算法特点 迪科斯彻算法使用了广度优先搜索解决赋权有向图或者无向图的单源最短路径问题,算法最终得到一个最短路径树.该算法常用于路由算法或者作为其他图算法的一个子模块. 2.2.算法的