提高python代码可读性利器pycodestyle使用详解
目录
- 关于PEP-8
- 目的
- 安装
- 基本用法
- 高级用法
- 结论
编程是数据科学中不可或缺的技能,虽然创建脚本来执行基本功能很容易,但编写大规模可读性良好的代码需要更多的思考。
关于PEP-8
pycodestyle 检查器提供基于 PEP-8 样式约定的代码建议。那么 PEP-8 到底是什么呢?
PEP 代表 Python 增强建议,PEP-8 是一个概述编写 Python 代码最佳实践的指南。它的主要目标是通过标准化代码样式来提高代码的整体一致性和可读性。
目的
快速浏览一下PEP-8文档,就会发现有太多的最佳实践需要记住。
而且,已经花了这么多精力编写了这么多行代码,你当然不希望浪费更多的时间手动检查脚本的可读性。
这就是 pycodestyle 自动分析 Python 脚本并指出代码可以改进的地方。
安装
pip 是首选的安装程序,你可以通过在终端中运行以下命令来安装或升级 pycodestyle:
# Install pycodestyle pip install pycodestyle # Upgrade pycodestyle pip install --upgrade pycodestyle
基本用法
最直接的用法是在 Python 脚本(.py文件)上作为命令在终端中运行pycodestyle。
让我们使用以下示例脚本(名为 pycodestyle_sample_script.py)进行演示:
# pycodestyle_sample_script.py
# Import libraries
import numpy as np, pandas as pd
# Take the users input
words = raw_input("Enter some text to translate to pig latin: " )
# Break apart the words into a list
words_list = words.split(' ' )
for word in words_list:
if len(word) >= 3 : # For this pig latin translation, we only want to translate words greater than 3 characters
pig_latin = word + "%say" % (word[0])
pig_latin = pig_latin[ 1: ]
print(pig_latin )
else:
pass
我们通过运行以下简单命令来实现pycodestyle:
pycodestyle pycodestyle_sample_script.py
输出指定违反PEP-8样式约定的代码位置:
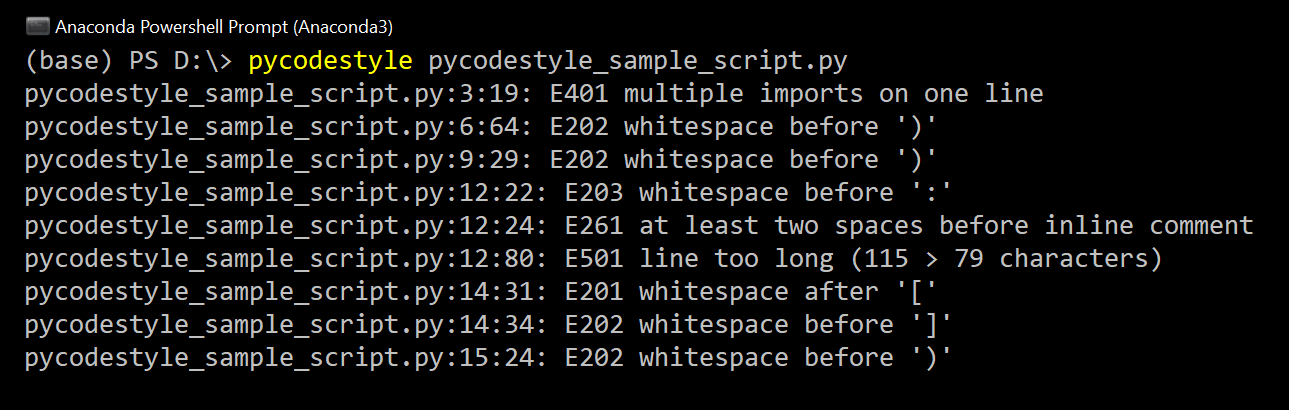
每行中由冒号分隔的一对数字(如3:19)分别表示行号和字符号。
例如,在")"之前输出6:64 E202空格意味着在第6行中,第64个字符标记处有一个意外的空格。
你也可以通过分析 statistics 参数来查看错误发生的频率:
pycodestyle --statistics -qq pycodestyle_sample_script.py

在上面的输出中,我们看到在右括号“)”之前出现了4次意外的空白。
高级用法
我们还可以将 pycodestyle 直接导入到 Python 代码中,以执行自动化测试。这对于自动测试多个脚本的编码风格一致性非常有用。
例如,可以编写以下类来自动检查是否符合PEP-8约定:
import unittest
import pycodestyle
class TestCodeFormat(unittest.TestCase):
def test_conformance(self):
"""Test that the scripts conform to PEP-8."""
style = pycodestyle.StyleGuide(quiet=True)
result = style.check_files(['file1.py', 'file2.py'])
self.assertEqual(result.total_errors, 0, "Found style
errors")
还可以配置该工具,以便根据我们定义的样式规则首选项进行测试。例如,我们可以删除不希望在检查中检测到的特定错误:
style = pycodestyle.StyleGuide(ignore=['E201', 'E202', 'E501'])
或者,我们可以指示 pycodestyle 一起使用不同的配置文件(包含一组特定的样式规则)。
import pycodestyle style = pycodestyle.StyleGuide(config_file='/path/to/tox.ini')
如果你需要了解更多的功能,访问pycodestyle文档获取更多详细信息。
https://pycodestyle.pycqa.org/en/latest/intro.html
结论
代码的阅读频率高于编写频率,代码的一致性、可理解性和结构整洁是至关重要的。在本文中,我们研究了如何使用 pycodestyle 工具来检查 Python 脚本是否符合 PEP-8 代码样式规范。
相信掌握它后,我们代码质量会有质的飞跃。
以上就是提高python代码可读性利器pycodestyle使用详解的详细内容,更多关于python代码可读性利器pycodestyle的资料请关注我们其它相关文章!
相关推荐
-

python解释模型库Shap实现机器学习模型输出可视化
目录 安装所需的库 导入所需库 创建模型 创建可视化 1.Bar Plot 2.队列图 3.热图 4.瀑布图 5.力图 6.决策图 解释一个机器学习模型是一个困难的任务,因为我们不知道这个模型在那个黑匣子里是如何工作的.解释是必需的,这样我们可以选择最佳的模型,同时也使其健壮. 我们开始吧- 安装所需的库 使用pip安装Shap开始.下面给出的命令可以做到这一点. pip install shap 导入所需库 在这一步中,我们将导入加载数据.创建模型和创建该模型的可视化所需的库. df = pd
-
python机器学习使数据更鲜活的可视化工具Pandas_Alive
目录 安装方法 使用说明 支持示例展示 水平条形图 垂直条形图比赛 条形图 饼图 多边形地理空间图 多个图表 总结 数据动画可视化制作在日常工作中是非常实用的一项技能.目前支持动画可视化的库主要以Matplotlib-Animation为主,其特点为:配置复杂,保存动图容易报错. 安装方法 pip install pandas_alive # 或者 conda install pandas_alive -c conda-forge 使用说明 pandas_alive 的设计灵感来自 bar_ch
-
python机器学习朴素贝叶斯算法及模型的选择和调优详解
目录 一.概率知识基础 1.概率 2.联合概率 3.条件概率 二.朴素贝叶斯 1.朴素贝叶斯计算方式 2.拉普拉斯平滑 3.朴素贝叶斯API 三.朴素贝叶斯算法案例 1.案例概述 2.数据获取 3.数据处理 4.算法流程 5.注意事项 四.分类模型的评估 1.混淆矩阵 2.评估模型API 3.模型选择与调优 ①交叉验证 ②网格搜索 五.以knn为例的模型调优使用方法 1.对超参数进行构造 2.进行网格搜索 3.结果查看 一.概率知识基础 1.概率 概率就是某件事情发生的可能性. 2.联合概率 包
-
python机器学习基础K近邻算法详解KNN
目录 一.k-近邻算法原理及API 1.k-近邻算法原理 2.k-近邻算法API 3.k-近邻算法特点 二.k-近邻算法案例分析案例信息概述 第一部分:处理数据 1.数据量缩小 2.处理时间 3.进一步处理时间 4.提取并构造时间特征 5.删除无用特征 6.签到数量少于3次的地点,删除 7.提取目标值y 8.数据分割 第二部分:特征工程 标准化 第三部分:进行算法流程 1.算法执行 2.预测结果 3.检验效果 一.k-近邻算法原理及API 1.k-近邻算法原理 如果一个样本在特征空间中的k个最相
-
pyCaret效率倍增开源低代码的python机器学习工具
目录 PyCaret 时间序列模块 加载数据 初始化设置 统计测试 探索性数据分析 模型训练和选择 保存模型 PyCaret 是一个开源.低代码的 Python 机器学习库,可自动执行机器学习工作流.它是一种端到端的机器学习和模型管理工具,可以以指数方式加快实验周期并提高您的工作效率.欢迎收藏学习,喜欢点赞支持,文末提供技术交流群. 与其他开源机器学习库相比,PyCaret 是一个替代的低代码库,可用于仅用几行代码替换数百行代码. 这使得实验速度和效率呈指数级增长. PyCaret 本质上是围绕
-
python数据挖掘使用Evidently创建机器学习模型仪表板
目录 1.安装包 2.导入所需的库 3.加载数据集 4.创建模型 5.创建仪表板 6.可用报告类型 1)数据漂移 2)数值目标漂移 3)分类目标漂移 4)回归模型性能 5)分类模型性能 6)概率分类模型性能 解释机器学习模型是一个困难的过程,因为通常大多数模型都是一个黑匣子,我们不知道模型内部发生了什么.创建不同类型的可视化有助于理解模型是如何执行的,但是很少有库可以用来解释模型是如何工作的. Evidently 是一个开源 Python 库,用于创建交互式可视化报告.仪表板和 JSON 配置文
-
python机器学习算法与数据降维分析详解
目录 一.数据降维 1.特征选择 2.主成分分析(PCA) 3.降维方法使用流程 二.机器学习开发流程 1.机器学习算法分类 2.机器学习开发流程 三.转换器与估计器 1.转换器 2.估计器 一.数据降维 机器学习中的维度就是特征的数量,降维即减少特征数量.降维方式有:特征选择.主成分分析. 1.特征选择 当出现以下情况时,可选择该方式降维: ①冗余:部分特征的相关度高,容易消耗计算性能 ②噪声:部分特征对预测结果有影响 特征选择主要方法:过滤式(VarianceThreshold).嵌入式(正
-
提高python代码可读性利器pycodestyle使用详解
目录 关于PEP-8 目的 安装 基本用法 高级用法 结论 编程是数据科学中不可或缺的技能,虽然创建脚本来执行基本功能很容易,但编写大规模可读性良好的代码需要更多的思考. 关于PEP-8 pycodestyle 检查器提供基于 PEP-8 样式约定的代码建议.那么 PEP-8 到底是什么呢? PEP 代表 Python 增强建议,PEP-8 是一个概述编写 Python 代码最佳实践的指南.它的主要目标是通过标准化代码样式来提高代码的整体一致性和可读性. 目的 快速浏览一下PEP-8文档,就会发
-
提高Python代码可读性的5个技巧分享
目录 1. Comments 2. Explicit Typing 3. Docstrings (Documentation Strings) 4. Readable Variable Names 5. Avoiding Magic Numbers 总结 不知道小伙伴们是否有这样的困惑,当我们回顾自己 6 个月前编写的一些代码时,往往会看的一头雾水,或者是否当我们接手其他人的代码时, Python 中有许多方法可以帮助我们理解代码的内部工作原理,良好的编程习惯,可以使我们的工作事半功倍! 例如,
-
5行Python代码实现图像分割的步骤详解
众所周知图像是由若干有意义的像素组成的,图像分割作为计算机视觉的基础,对具有现有目标和较精确边界的图像进行分割,实现在图像像素级别上的分类任务. 图像分割可分为语义分割和实例分割两类,区别如下: 语义分割:将图像中每个像素赋予一个类别标签,用不同的颜色来表示: 实例分割:无需对每个像素进行标记,只需要找到感兴趣物体的边缘轮廓. 图像分割通常应用如下所示: 专业检测:应用于专业场景的图像分析,比如在卫星图像中识别建筑.道路.森林,或在医学图像中定位病灶.测量面积等: 智能交通:识别道路信息,包括车
-
通过PHP与Python代码对比的语法差异详解
一.背景 人工智能这几年一直都比较火,笔者一直想去学习一番:因为一直是从事PHP开发工作,对于Python接触并不算多,总是在关键时候面临着基础不牢,地动山摇的尴尬,比如在遇到稍微深入些的问题时候就容易卡壳,于是准备从Python入门从头学起: 笔者觉得应该有不少人同样熟悉PHP或者Python语言,对另外一个门语言并不是太熟悉,有想法学习另外一门语言,希望通过这篇文章能够对大家有一点帮助. 二.知识点 最近在完成一个小作业,题目要求:通过Python代码实现,让用户输入用户名密码,认证成功后显
-
Python代码的打包与发布详解
在python程序中,一个.py文件被当作一个模块,在各个模块中定义了不同的函数.当我们要使用某一个模块中的某一个函数时,首先须将这个模块导入,否则就会出现函数未定义的情况. 下面记录的是打包及安装包的方法. 本文示例是建立一个模拟登录的程序: logIn.py文件代码如下: pwd=int(raw_input('please input your passward: ')) if pwd==123: print 'success' else: print 'error' 一.打包 1.先建立一
-
分享10提高 Python 代码的可读性的技巧
目录 1.字符串反转 2.首字母大写 3.查询唯一元素 4.变量交换 5.列表排序 6.列表推导式 7.合并字符串 8.拆分字符串 9.回文串检测 10.统计列表元素出现次数 1. 字符串反转 字符串反转有很多方法,咱们再这里介绍两种:一种是切片,一种是python字符串的reversed方法. # -!- coding: utf-8 -!- string = 'hello world' # 方法1 new_str = string[::-1] ic(new_str) # 方法二 new_str
-
提高团队代码质量利器ESLint及Prettier详解
目录 正文 ESLint VUE 项目的规则 Prettier ESLint 与 Prettier 正文 每个开发人员都有独特的代码编写风格和不同的文本编辑器.在团队项目开发过程,不能强迫每个团队成员都写一样的代码风格. 可能会看到以下部分(或全部)内容: 缺少分号: 有单引号.双引号,风格不一致: 一些行之间有大量的空格,而其他行之间没有空格: 在使向右滚动多年以查看其中包含的所有内容的行上运行: 看似随意的缩进: 注释掉代码块: 初始化但未使用的变量: 一些使用“严格”JS 的文件和其他不使
-
提高python代码运行效率的一些建议
1. 优化代码和算法 一定要先好好看看你的代码和算法.许多速度问题可以通过实现更好的算法或添加缓存来解决.本文所述都是关于这一主题的,但要遵循的一些一般指导方针是: 测量,不要猜测. 测量代码中哪些部分运行时间最长,先把重点放在那些部分上. 实现缓存. 如果你从磁盘.网络和数据库执行多次重复的查找,这可能是一个很大的优化之处. 重用对象,而不是在每次迭代中创建一个新对象.Python 必须清理你创建的每个对象才能释放内存,这就是所谓的"垃圾回收".许多未使用对象的垃圾回收会大大降低软件
-
Python数据分析之绘图和可视化详解
一.前言 matplotlib是一个用于创建出版质量图表的桌面绘图包(主要是2D方面).该项目是由John Hunter于2002年启动的,其目的是为Python构建一个MATLAB式的绘图接口.matplotlib和IPython社区进行合作,简化了从IPython shell(包括现在的Jupyter notebook)进行交互式绘图.matplotlib支持各种操作系统上许多不同的GUI后端,而且还能将图片导出为各种常见的矢量(vector)和光栅(raster)图:PDF.SVG.JPG
-
Python数据结构与算法之算法分析详解
目录 0. 学习目标 1. 算法的设计要求 1.1 算法评价的标准 1.2 算法选择的原则 2. 算法效率分析 2.1 大O表示法 2.2 常见算法复杂度 2.3 复杂度对比 3. 算法的存储空间需求分析 4. Python内置数据结构性能分析 4.1 列表性能分析 4.2 字典性能分析 0. 学习目标 我们已经知道算法是具有有限步骤的过程,其最终的目的是为了解决问题,而根据我们的经验,同一个问题的解决方法通常并非唯一.这就产生一个有趣的问题:如何对比用于解决同一问题的不同算法?为了以合理的方式