Python Pandas两个表格内容模糊匹配的实现
目录
- 一、方法2
- 1. 导入库
- 2. 构建关键词
- 3. 构建句子
- 4. 建立统一索引
- 5. 表连接
- 6. 关键词匹配
- 二、方法2
- 1. 构建字典
- 2. 关键词匹配
- 3. 结果展示
- 4. 匹配结果展开
- 总结
一、方法2
此方法是两个表构建某一相同字段,然后全连接,在做匹配结果筛选,此方法针对数据量不大的时候,逻辑比较简单,但是内存消耗较大
1. 导入库
import pandas as pd import numpy as np import re
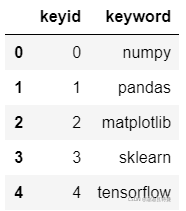
2. 构建关键词
#关键词数据
df_keyword = pd.DataFrame({
"keyid" : np.arange(5),
"keyword" : ["numpy", "pandas", "matplotlib", "sklearn", "tensorflow"]
})
df_keyword
3. 构建句子
df_sentence = pd.DataFrame({
"senid" : np.arange(10,17),
"sentence" : [
"怎样用pandas实现merge?",
"Python之Numpy详细教程",
"怎么使用Pandas批量拆分与合并Excel文件?",
"怎样使用pandas的map和apply函数?",
"深度学习之tensorflow简介",
"tensorflow和numpy的关系",
"基于sklearn的一些机器学习的代码"
]
})
df_sentence

4. 建立统一索引
df_keyword['match'] = 1 df_sentence['match'] = 1
5. 表连接
df_merge = pd.merge(df_keyword, df_sentence) df_merge
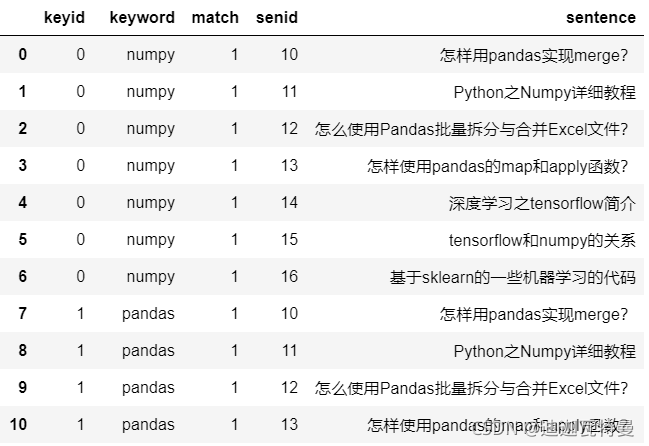
6. 关键词匹配
def match_func(row):
return re.search(row["keyword"], row["sentence"], re.IGNORECASE) is not None
df_merge[df_merge.apply(match_func, axis = 1)]
匹配结果如下

二、方法2
此方法对编程能力有要求,在大数据集上计算量较方法一小很多
1. 构建字典
key_word_dict = {
row.keyword : row.keyid
for row in df_keyword.itertuples()
}
key_word_dict
{'numpy': 0, 'pandas': 1, 'matplotlib': 2, 'sklearn': 3, 'tensorflow': 4}
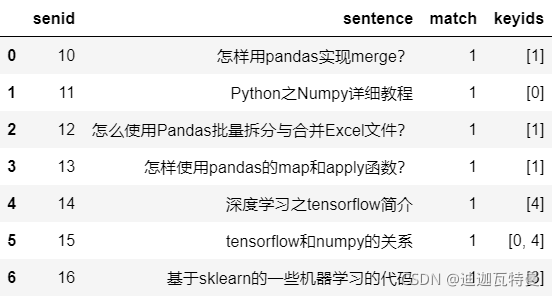
2. 关键词匹配
def merge_func(row):
#新增一列,表示可以匹配的keyid
row["keyids"] = [
keyid
for key_word, keyid in key_word_dict.items()
if re.search(key_word, row["sentence"], re.IGNORECASE)
]
return row
df_merge = df_sentence.apply(merge_func, axis = 1)
3. 结果展示
df_merge
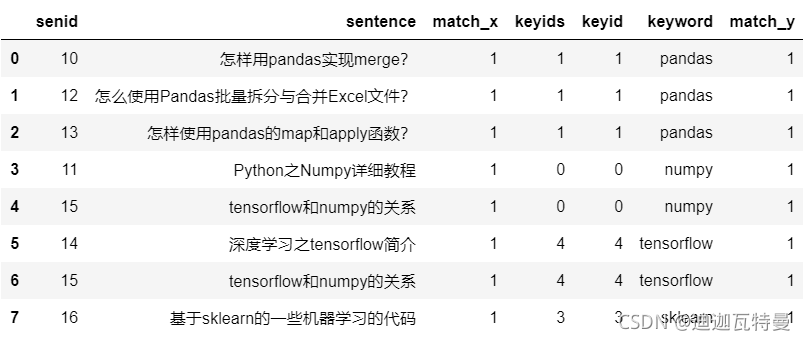
4. 匹配结果展开
df_result = pd.merge(
left = df_merge.explode("keyids"),
right = df_keyword,
left_on = "keyids",
right_on = "keyid")
df_result
总结
到此这篇关于Python Pandas两个表格内容模糊匹配搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python pandas模糊匹配 读取Excel后 获取指定指标的操作
1.首先读取Excel文件 数据代表了各个城市店铺的装修和配置费用,要统计出装修和配置项的总费用并进行加和计算: 2.pandas实现过程 import pandas as pd #1.读取数据 df = pd.read_excel(r'./data/pfee.xlsx') print(df) cols = list(df.columns) print(cols) #2.获取含有装修 和 配置 字段的数据 zx_lists=[] pz_lists=[] for name in cols: if
-
Python Pandas两个表格内容模糊匹配的实现
目录 一.方法2 1. 导入库 2. 构建关键词 3. 构建句子 4. 建立统一索引 5. 表连接 6. 关键词匹配 二.方法2 1. 构建字典 2. 关键词匹配 3. 结果展示 4. 匹配结果展开 总结 一.方法2 此方法是两个表构建某一相同字段,然后全连接,在做匹配结果筛选,此方法针对数据量不大的时候,逻辑比较简单,但是内存消耗较大 1. 导入库 import pandas as pd import numpy as np import re 2. 构建关键词 #关键词数据 df_keywo
-
python pandas处理excel表格数据的常用方法总结
目录 前言 1.读取xlsx表格:pd.read_excel() 2.获取表格的数据大小:shape 3.索引数据的方法:[ ] / loc[] / iloc[] 4.判断数据为空:np.isnan() / pd.isnull() 5.查找符合条件的数据 6.修改元素值:replace() 7.增加数据:[ ] 8.删除数据:del() / drop() 9.保存到excel文件:to_excel() 总结 前言 最近助教改作业导出的成绩表格跟老师给的名单顺序不一致,脑壳一亮就用pandas写了
-
python Pandas 读取txt表格的实例
运行环境 Python 2.7 操作实例 1.原始文本格式:空格分隔的txt,例如 2016-03-22 00:06:24.4463094 中文测试字符 2016-03-22 00:06:32.4565680 需要编辑encoding 2016-03-22 00:06:32.6835965 abc 2016-03-22 00:06:32.8041945 egb 2.pandas 读取数据 import pandas as pd data = pd.read_table('Z:/test.txt'
-
python进行两个表格对比的方法
如下所示: # -*- coding:utf-8 -*- import xlrd import sys import re import json dict1={} dict2={} mylist=[u'系统运维管理',u'安全管理机构',u'安全管理制度',u'人员安全管理',u'网络安全',u'物理安全',u'网络安全',u'主机安全',u'应用安全',u"网络安全",u"主机安全",u"主机安全",u'系统建设管理'] def check(
-
Python基于xlutils修改表格内容过程解析
一.xlutils是什么 是一个提供了许多操作修改excel文件方法的库: 属于python的第三方模块 xlrd库用于读取excel文件中的数据,xlwt库用于将数据写入excel文件,修改用xlutils模块: xlutils库也仅仅是通过复制一个副本进行操作后保存一个新文件,像是xlrd库和xlwt库之间的一座桥梁,需要依赖于xlrd和xlwt两个库 二.xlutils基础及应用 2.1 xlutils模块安装 命令行输入如下,进行联网在线安装 pip install xlutils 2.
-
使用Python完成公司名称和地址的模糊匹配的实现
github主页 导入: >>> from fuzzywuzzy import fuzz >>> from fuzzywuzzy import process 1) >>> fuzz.ratio("this is a test", "this is a test!") out 97 >>> fuzz.partial_ratio("this is a test", "
-
python使用xlsx和pandas处理Excel表格的操作步骤
目录 一.使用xls和xlsx处理Excel表格 1.1 用openpyxl模块打开Excel文档,查看所有sheet表 1.2 通过sheet名称获取表格 1.3 获取活动表的获取行数和列数 读取xlsx文件错误:xlrd.biffh.XLRDError: Excel xlsx file: not supported 二.使用pandas读取xlsx 2.1 读取数据 2.2 使用pandas查找两个列表中相同的元素 解决ValueError: Excel file format cannot
-
Python pandas对excel的操作实现示例
最近经常看到各平台里都有Python的广告,都是对excel的操作,这里明哥收集整理了一下pandas对excel的操作方法和使用过程.本篇介绍 pandas 的 DataFrame 对列 (Column) 的处理方法.示例数据请通过明哥的gitee进行下载. 增加计算列 pandas 的 DataFrame,每一行或每一列都是一个序列 (Series).比如: import pandas as pd df1 = pd.read_excel('./excel-comp-data.xlsx');
-
利用Python pandas对Excel进行合并的方法示例
前言 在网上找了很多Python处理Excel的方法和代码,都不是很尽人意,所以自己综合网上各位大佬的方法,自己进行了优化,具体的代码如下. 博主也是新手一枚,代码肯定有很多需要优化的地方,欢迎各位大佬提出建议~ 代码我自己已经用了一段时间,可以直接拿去用 主要功能 按行合并 ,即保留固定的表头(如前几行),实现多个Excel相同格式相同名字的表单按纵轴合并: 按列合并. 即保留固定的首列,实现多个Excel相同格式相同名字的表单按横轴合并: 表单集成 ,实现不同Excel中相同sheet的集成