C++高级数据结构之优先队列
目录
- 前言
- 高级数据结构(Ⅱ)优先队列(Priority Queue)
- API
- 实现
- 堆的定义
- 二叉堆表示法
- 堆的算法
- 插入元素
- 删除最大元素
- 基于堆的优先队列
- 堆排序
前言
- 高级数据结构(Ⅱ)优先队列(Priority Queue)
- API
- 堆的定义
- 二叉堆表示法
- 堆的算法
- 基于堆的优先队列
- 堆排序
高级数据结构(Ⅱ)优先队列(Priority Queue)
许多应用程序都需要处理有序的元素,但不一定要求它们全部有序,或是不一定要一次就将它们排序。很多情况下我们会收集一些元素,处理当前键值最大的元素,然后再收集更多的元素,再处理当前键值最大的元素,如此这般。例如,你可能有一台能够同时运行多个应用程序的电脑(或者手机)。这是通过为每个应用程序事件分配一个优先级,并总是处理下一个优先级最高的事件来实现的。例如,绝大多数手机分配给来电的优先级都会被游戏程序的高。
在这种情况下,一个合适的数据结构应该支持两种操作:删除最大元素和插入元素。这种数据类型叫做优先队列。优先队列的使用和队列(删除最老的元素)以及栈(删除最新的元素)类似,但高效地实现它则更有挑战性。
在本篇中,我们会学习一种基于二叉堆数据结构的一种优先队列的经典实现方法,用数组保存元素并按照一定条件排序,以实现高效地(对数级别的)删除最大元素和插入元素操作。
API
优先队列是一种抽象数据类型,它表示了一组值和对这些值的操作,它的抽象层使我们能够方便地将应用程序和各种具体实现隔离开来。
实现
public class MaxPQ <Key extends Comparable<Key>> ----------------------------------------------------------------------- MaxPQ() //创建一个优先队列 MaxPQ(int max) //创建一个初始容量为max的优先队列 MaxPQ(Key[] a) //用a中的元素创建一个优先队列 void insert(Key v) //向优先队列中插入一个元素 Key max() //返回最大元素 Key delMax() //删除并返回最大元素 boolean isEmpty() //返回队列是否为空 int size() //返回优先队列中元素个数
堆的定义
数据结构二叉堆能够很好地实现优先队列的基本操作。在二叉堆的数组中,每个元素都要保证大于等于另外两个特定位置的元素。相应地,这些位置的元素又至少要大于等于数组中的另外两个元素,以此类推。如果我们将所有的元素画成一颗二叉树,将每个较大元素和较小的元素用边连接就可以很容易地看出这种结构。
命题:当一颗二叉树的每个结点都大于等于它的另外两个子节点时,它被称为堆有序。
相应地,在堆有序的二叉树中,每个结点都小于等于它的父节点(如果有的话)。从任意结点向上,我们都能得到一列非递减的元素;从任意结点向下,我们都能得到一列非递增的元素。
命题:根节点是堆有序的二叉树中最大的结点
二叉堆表示法
如果我们用指针来表示堆有序的二叉树,那么每个元素都需要三个指针来找到它的上下结点(父节点和两个子节点)。如下图所示,如果我们使用完全二叉树,表达就会变的特别方便

可以先定下根节点,然后一层一层地由上向下、从左至右,在每个结点的下方连接两个更小的结点,直至将N个结点全部连接完毕。完全二叉树只用数组而不需要指针就可以表示。具体方法就是将二叉树的结点按照层级顺序放入数组中,根结点在位置1,它的子节点在位置2和位置3,而子节点的子节点分别在位置4、5、6和7,以此类推。
定义:二叉堆是一组能够用堆有序的完全二叉树排序的元素,并在数组中按照层级存储(不使用数组的第一个位置)
在一个堆中,位置k的结点的父节点的位置为[k/2]向下取整,而它的两个子节点的位置则分别为2k和2k+1。用数组(堆)实现的完全二叉树的结构是很严格的,但它的灵活性已经足以让我们高效地实现优先队列。用它们我们能将实现对数级别的插入元素和删除最大元素的操作。利用数组中无需指针即可沿树上下移动的便利和以下性质,算法保证了对数复杂度的性能。
命题:一颗大小为N的完全二叉树的高度为lg[N]

堆的算法
我们用长度为N+1的私有数组pq[]来表示一个大小为N的堆。我们不会使用pq[0],堆元素放在pq[1]至pq[N]中。在排序算法中,我们只通过私有辅助函数less()和exch()来访问元素,但因为所有的元素都在数组pq[]中,我们在下面基于堆的优先队列中会用更紧凑的实现方式,不再将数组作为参数传递。堆的操作会首先进行一些简单的改动,打破堆的状态,然后再遍历堆并按照要求将堆的状态恢复。我们称这个过程为堆的有序化(reheapifying)。
实现:
private boolean less(int i, int j) {
return pq[i].compareTo(pq[j]) < 0;
}
private void exch(int i, int j) {
Key t = pq[i];
pq[i] = pq[j];
pq[j] = t;
}
在堆有序化的过程中我们会遇到两种情况。当某个结点的优先级上升(或是在堆底加入一个新的元素)时,我们需要由下至上恢复堆的顺序。当某个结点的优先级下降(例如,将根节点替换为一个较小的元素)时,我们需要由下至上恢复堆的顺序。首先来学习如何实现这两种辅助操作,然后再用它们实现插入元素和删除最大元素的操作。
由下至上的堆的有序化(上浮)
如果堆的有序状态因为某个结点变得比它的父节点更大而被打破,那么我们就需要通过交换它和它的父节点来修复堆。交换后,这个结点比它的两个子结点都大(一个是曾经的父节点,另一个比它更小,因为它是它曾经父节点的子节点),但这个结点仍然可能比它现在的父节点更大。我们可以一遍遍地用同样的方法恢复秩序,将这个结点不断向上移动直到我们遇到了一个更大的父节点。位置k的结点的父结点为[k/2],swim()方法中的循环可以保证只有位置k上的结点大于它的父节点时堆的有序状态才会被打破。因此只要该结点不再大于父结点,堆的有序状态就恢复了。当一个结点优先级太大的时候它需要浮(swim)到堆的更高层,详细代码如下
private void swim(int k) {
while(k > 1 && less(k / 2, k)) {
exch(k / 2, k);
k = k / 2;
}
}

由上至下的堆的有序化(下沉)
如果堆的有序状态因为某个结点变得比它的两个子结点或是其中之一更小了而被打破了,那么我们可以通过将它和它的两个子结点中的较大者交换来恢复堆。交换可能会在子结点处继续打破堆的有序状态,因此我们都需要用相同的方式来将其修复,将结点向下移动直到它的子结点都比它更小或者是达到了堆的底部。由位置为k的结点的子结点为2k和2k+1可以直接得到对应的代码。方法名为了形象表示这个过程称为sink()下沉,即当一个结点优先级太低时它需要沉(sink)到堆的更低层,
码实现如下:
private void sink(int k) {
while(2 * k <= N) {
int j = 2 * k;
if(j < N && less(j, j + 1)) j++;
if(!less(k, j)) break;
exch(k, j);
k = j;
}
}

插入元素
我们将新元素插入到数组末尾,增加堆的大小并让这个元素上浮到合适的位置(如下图左半部分所示)
删除最大元素
我们从数组顶端删去最大的元素并将数组的最后一个元素放到顶端,减小堆的大小并让这个元素下沉到合适的位置(如下图右半部分所示)
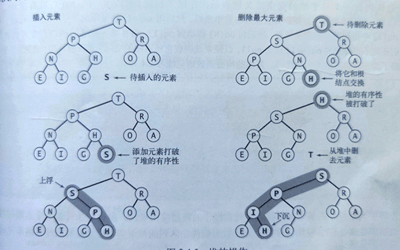
基于堆的优先队列
优先队列由一个基于堆的完全二叉树表示,存储于数组pq[1..N]中,pq[0]没有使用,pq[0]的值有时可以作为哨兵来用。在insert()中,我们将N加1并把新元素添加在数组最后,然后用swim()恢复堆的秩序。在delMax()中,我们从pq[1]中得到需要返回的元素,然后将pq[N]移动到pq[1],将N减1并用sink()来恢复堆的秩序。同时我们还将不再使用的pq[N+1]设为null,以便系统回收它所占用的空间。此处省略动态调整数组大小的代码,有兴趣的朋友可以自己写写。
命题:对于一个含有N个元素的基于堆的优先队列,插入元素操作只需不超过(lgN+1)次比较,删除最大元素的操作需要不超过2lgN次比较
基于堆的优先队列详细代码如下:
public class MaxPQ<Key extends Comparable<Key>> {
private Key[] pq; //基于堆的完全二叉树
private int N = 0; //存储于pa[1..N]中,pq[0]没有使用
public MaxPQ(int maxN) {
pq = (Key[]) new Comparable[maxN + 1];
this.N = maxN;
}
public boolean isEmpty() {
return N == 0;
}
public int size() {
return N;
}
public void insert(Key v) {
pq[++N] = v;
swim(N);
}
public Key delMax(Key v) {
Key max = pq[1]; //根节点得到最大元素
exch(1, N--); //将其和最后一个结点交换
pq[N + 1] = null; //防止对象游离
sink(1); //恢复堆的有序性
return max;
}
private boolean less(int i, int j) {
return pq[i].compareTo(pq[j]) < 0;
}
private void exch(int i, int j) {
Key t = pq[i];
pq[i] = pq[j];
pq[j] = t;
}
private void swim(int k) {
while(k > 1 && less(k / 2, k)) {
exch(k / 2, k);
k = k / 2;
}
}
private void sink(int k) {
while(2 * k <= N) {
int j = 2 * k;
if(j < N && less(j, j + 1)) j++;
if(!less(k, j)) break;
exch(k, j);
k = j;
}
}
}
过程:

堆排序
堆排序可以分为两个阶段。在堆的构造阶段中,我们将原始数组重新组织安排进一个堆中;然后在下沉排序阶段,我们从堆中按递减顺序取出所有元素并得到排序结果。为了和我们学过的代码保持一致,我们将使用一个面向最大元素的优先队列并重复删除最大元素。我们不再使将优先队列的具体表示隐藏,并将直接使用swim()和sink()操作。这样我们在排序时就可以将需要排序的数组本身作为堆,因此无需任何额外空间。
注意:将对应下标减1可以得到与其他排序算法一样的排序结果。否则将是忽略下标0的排序算法

到此这篇关于C++高级数据结构之优先队列的文章就介绍到这了,更多相关 C++优先队列内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C++ 实现优先队列的简单实例
C++ 实现优先队列的简单实例 优先队列类模版实现: BuildMaxHeap.h头文件: #include<iostream> using namespace std; #define Left(i) i*2+1 #define Right(i) i*2+2 #define Parent(i) (i-1)/2 void Max_Heapify(int a[],int length,int i) { int left,right; left=Left(i); right=Right(i); i
-
C++非递归队列实现二叉树的广度优先遍历
本文实例讲述了C++非递归队列实现二叉树的广度优先遍历.分享给大家供大家参考.具体如下: 广度优先非递归二叉树遍历(或者说层次遍历): void widthFirstTraverse(TNode* root) { queue<TNode*> q; // 队列 q.enqueue(root); TNode* p; while(q.hasElement()) { p = q.dequeue(); // 队首元素出队列 visit(p); // 访问p结点 if(p->left) q.enqu
-
C++ 中"priority_queue" 优先级队列实例详解
C++ 中"priority_queue" 优先级队列实例详解 1. 简介 标准库队列使用了先进先出(FIFO)的存储和检索策略. 进入队列的对象被放置在尾部, 下一个被取出的元素则取自队列的首部. 标准库提供了两种风格的队列: FIFO 队列(FIFO queue, 简称 queue), 以及优先级队列(priority queue). priority_queue 允许用户为队列中存储的元素设置优先级. 这种队列不是直接将新元素放置在队列尾部, 而是放在比它优先级低的元素前面. 标
-
c++优先队列用法知识点总结
c++优先队列用法详解 优先队列也是队列这种数据结构的一种.它的操作不仅局限于队列的先进先出,可以按逻辑(按最大值或者最小值等出队列). 普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除. 在优先队列中,元素被赋予优先级.当访问元素时,具有最高优先级的元素最先删除.优先队列具有最高级先出 (first in, largest out)的行为特征. 首先要包含头文件#include<queue>, 他和queue不同的就在于我们可以自定义其中数据的优先级, 让优先级高的排在队
-
C++优先队列用法案例详解
c++优先队列(priority_queue)用法详解 普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除. 在优先队列中,元素被赋予优先级.当访问元素时,具有最高优先级的元素最先删除.优先队列具有最高级先出 (first in, largest out)的行为特征. 首先要包含头文件#include<queue>, 他和queue不同的就在于我们可以自定义其中数据的优先级, 让优先级高的排在队列前面,优先出队. 优先队列具有队列的所有特性,包括队列的基本操作,只是在这基础上
-
c++优先队列(priority_queue)用法详解
普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除. 在优先队列中,元素被赋予优先级.当访问元素时,具有最高优先级的元素最先删除.优先队列具有最高级先出 (first in, largest out)的行为特征. 首先要包含头文件#include<queue>, 他和queue不同的就在于我们可以自定义其中数据的优先级, 让优先级高的排在队列前面,优先出队. 优先队列具有队列的所有特性,包括队列的基本操作,只是在这基础上添加了内部的一个排序,它本质是一个堆实现的. 和队列基本
-
详解c++优先队列priority_queue的用法
既然是队列那么先要包含头文件#include <queue>, 他和queue不同的就在于我们可以自定义其中数据的优先级, 让优先级高的排在队列前面,优先出队 优先队列具有队列的所有特性,包括基本操作,只是在这基础上添加了内部的一个排序,它本质是一个堆实现的 和队列基本操作相同: top 访问队头元素 empty 队列是否为空 size 返回队列内元素个数 push 插入元素到队尾 (并排序) emplace 原地构造一个元素并插入队列 pop 弹出队头元素 swap 交换内容 定义:prio
-

C++高级数据结构之优先队列
目录 前言 高级数据结构(Ⅱ)优先队列(Priority Queue) API 实现 堆的定义 二叉堆表示法 堆的算法 插入元素 删除最大元素 基于堆的优先队列 堆排序 前言 高级数据结构(Ⅱ)优先队列(Priority Queue) API 堆的定义 二叉堆表示法 堆的算法 基于堆的优先队列 堆排序 高级数据结构(Ⅱ)优先队列(Priority Queue) 许多应用程序都需要处理有序的元素,但不一定要求它们全部有序,或是不一定要一次就将它们排序.很多情况下我们会收集一些元素,处理当前键值最大
-
Python中的高级数据结构详解
数据结构 数据结构的概念很好理解,就是用来将数据组织在一起的结构.换句话说,数据结构是用来存储一系列关联数据的东西.在Python中有四种内建的数据结构,分别是List.Tuple.Dictionary以及Set.大部分的应用程序不需要其他类型的数据结构,但若是真需要也有很多高级数据结构可供选择,例如Collection.Array.Heapq.Bisect.Weakref.Copy以及Pprint.本文将介绍这些数据结构的用法,看看它们是如何帮助我们的应用程序的. 关于四种内建数据结构的使用方
-
JavaScript数据结构之优先队列与循环队列实例详解
本文实例讲述了JavaScript数据结构之优先队列与循环队列.分享给大家供大家参考,具体如下: 优先队列 实现一个优先队列:设置优先级,然后在正确的位置添加元素. 我们这里实现的是最小优先队列,优先级的值小(优先级高)的元素被放置在队列前面. //创建一个类来表示优先队列 function Priorityqueue(){ var items=[];//保存队列里的元素 function QueueEle(e,p){//元素节点,有两个属性 this.element=e;//值 this.pr
-
C++高级数据结构之二叉查找树
目录 高级数据结构(Ⅳ)二叉查找树 基础概念 基本实现 数据表示 查找 插入 有序性相关的方法 最小键和最大键 向上取整和向下取整 选择操作 排名 范围查找 与删除相关的方法 删除最小键 删除最大键 删除操作 性能分析 完整代码和测试 完整代码 测试 前言: 文章目录 基础概念 基本实现 有序性相关的方法 与删除相关的方法 性能分析 完整代码和测试 高级数据结构(Ⅳ)二叉查找树 基础概念 此数据结构由结点组成,结点包含的链接可以为空(null)或者指向其他结点.在二叉树中,每个结点只能有一个父结
-
C++高级数据结构之并查集
目录 1.动态连通性 2.union-find算法API 3.quick-find算法 4.quick-union算法 5.加权quick-union算法 6.使用路径压缩的加权quick-union算法 7.算法比较 前言: 高级数据结构(Ⅰ)并查集(union-find) 动态连通性 union-find算法API quick-find算法 quick-union算法 加权quick-union算法 使用路径压缩的加权quick-union算法 算法比较 并查集 > 左神版 高级数据结构(Ⅰ
-
C++高级数据结构之线段树
目录 前言: 高级数据结构(Ⅲ)线段树(Segment Tree) 线段树的原理 树的创建 单点修改 区间查找 完整代码及测试 前言: 高级数据结构(Ⅲ)线段树(Segment Tree) 线段树的原理 树的创建 单点修改 区间查找 完整代码及测试 高级数据结构(Ⅲ)线段树(Segment Tree) 线段树的原理 线段树是一种二叉搜索树 , 对于线段树中的每一个非叶子结点[a,b],它的左儿子表示的区间为[a, (a+b)/2],右儿子表示的区间为[(a+b)/2+1, b].因此线段树是平衡
-
高级数据结构及应用之使用bitmap进行字符串去重的方法实例
bitmap 即为由单个元素为 boolean(0/1, 0 表示未出现,1 表示已经出现过)的数组. 如果C/C++ 没有原生的 boolean 类型,可以用 int 或 char 来作为 bitmap 使用,如果我们要判断某字符(char)是否出现过 使用 int 作为 bitmap 的底层数据结构,bitmap 即为 int 数组,一个 int 长度为 32 个 bit 位, c / 32 ⇒ bitmap 中的第几个 int c % 32 ⇒ bitmap 中的某 int 中的第几个 b
-
Python数据结构之哈夫曼树定义与使用方法示例
本文实例讲述了Python数据结构之哈夫曼树定义与使用方法.分享给大家供大家参考,具体如下: HaffMan.py #coding=utf-8 #考虑权值的haff曼树查找效率并非最高,但可以用于编码等使用场景下 class TreeNode: def __init__(self,data): self.data=data self.left=None self.right=None self.parent=None class HaffTree: def __init__(self): sel
-
常用的Java数据结构知识点汇总
目录 1.数据结构分类 2.线性数据结构 2.1数组 2.2可变数组 2.3链表 2.4栈 2.5队列 3.非线性数据结构 3.1树 3.2图 3.3散列表 3.4堆 1. 数据结构分类 按照线性和非线性可以将Java数据结构分为两大类: ①线性数据结构:数组.链表.栈.队列②非线性数据结构:树.堆.散列表.图 2. 线性数据结构 2.1 数组 数组是一种将元素存储于连续内存空间的数据结构,并且要求元素的类型相同. // 定义一个数组长度为5的数组array int[] array = new
-
Javascript数据结构之栈和队列详解
目录 前言 栈(stack) 栈实现 解决实际问题 栈的另外应用 简单队列(Queue) 队列实现 队列应用 - 树的广度优先搜索(breadth-first search,BFS) 优先队列 优先队列实现 线性数据结构实现优先队列 Heap(堆)数据结构实现优先队列 代码实现一个二叉堆 小顶堆在 React Scheduler 事务调度的包应用 最后 前言 我们实际开发中,比较熟悉的数据结构是数组.一般情况下够用了.但如果遇到复杂的问题,数组就捉襟见肘了.在解决一个复杂的实际问题的时候,选择一