Python人工智能实战之以图搜图的实现
目录
- 前言
- 一、实验要求
- 二、环境配置
- 三、代码文件
- 1、vgg.py
- 2、index.py
- 3、test.py
- 四、演示
- 1、项目文件夹
- 2、相似度排序输出
- 3、保存结果
- 五、尾声
前言
基于vgg网络和Keras深度学习框架的以图搜图功能实现。
一、实验要求
给出一张图像后,在整个数据集中(至少100个样本)找到与这张图像相似的图像(至少5张),并把图像有顺序的展示。
二、环境配置
解释器:python3.10
编译器:Pycharm
必用配置包:
numpy、h5py、matplotlib、keras、pillow
三、代码文件
1、vgg.py
# -*- coding: utf-8 -*-
import numpy as np
from numpy import linalg as LA
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input as preprocess_input_vgg
class VGGNet:
def __init__(self):
self.input_shape = (224, 224, 3)
self.weight = 'imagenet'
self.pooling = 'max'
self.model_vgg = VGG16(weights = self.weight, input_shape = (self.input_shape[0], self.input_shape[1], self.input_shape[2]), pooling = self.pooling, include_top = False)
self.model_vgg.predict(np.zeros((1, 224, 224 , 3)))
#提取vgg16最后一层卷积特征
def vgg_extract_feat(self, img_path):
img = image.load_img(img_path, target_size=(self.input_shape[0], self.input_shape[1]))
img = image.img_to_array(img)
img = np.expand_dims(img, axis=0)
img = preprocess_input_vgg(img)
feat = self.model_vgg.predict(img)
# print(feat.shape)
norm_feat = feat[0]/LA.norm(feat[0])
return norm_feat
2、index.py
# -*- coding: utf-8 -*-
import os
import h5py
import numpy as np
import argparse
from vgg import VGGNet
def get_imlist(path):
return [os.path.join(path, f) for f in os.listdir(path) if f.endswith('.jpg')]
if __name__ == "__main__":
database = r'D:\pythonProject5\flower_roses'
index = 'vgg_featureCNN.h5'
img_list = get_imlist(database)
print(" feature extraction starts")
feats = []
names = []
model = VGGNet()
for i, img_path in enumerate(img_list):
norm_feat = model.vgg_extract_feat(img_path) # 修改此处改变提取特征的网络
img_name = os.path.split(img_path)[1]
feats.append(norm_feat)
names.append(img_name)
print("extracting feature from image No. %d , %d images in total" % ((i + 1), len(img_list)))
feats = np.array(feats)
output = index
print(" writing feature extraction results ...")
h5f = h5py.File(output, 'w')
h5f.create_dataset('dataset_1', data=feats)
# h5f.create_dataset('dataset_2', data = names)
h5f.create_dataset('dataset_2', data=np.string_(names))
h5f.close()
3、test.py
# -*- coding: utf-8 -*-
from vgg import VGGNet
import numpy as np
import h5py
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import argparse
query = r'D:\pythonProject5\rose\red_rose.jpg'
index = 'vgg_featureCNN.h5'
result = r'D:\pythonProject5\flower_roses'
# read in indexed images' feature vectors and corresponding image names
h5f = h5py.File(index, 'r')
# feats = h5f['dataset_1'][:]
feats = h5f['dataset_1'][:]
print(feats)
imgNames = h5f['dataset_2'][:]
print(imgNames)
h5f.close()
print(" searching starts")
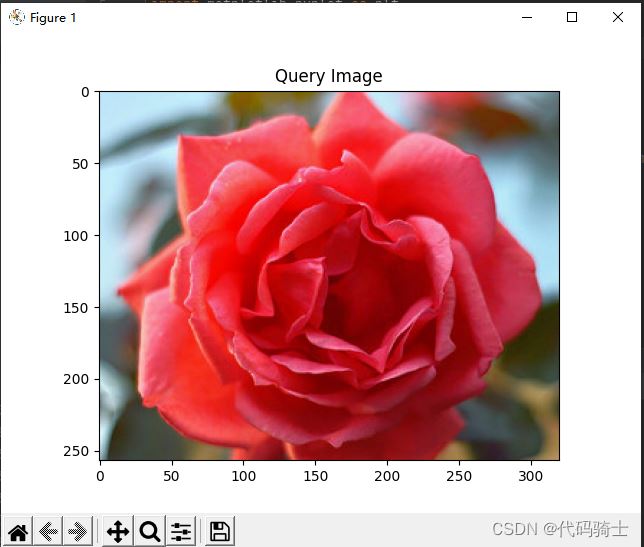
queryImg = mpimg.imread(query)
plt.title("Query Image")
plt.imshow(queryImg)
plt.show()
# init VGGNet16 model
model = VGGNet()
# extract query image's feature, compute simlarity score and sort
queryVec = model.vgg_extract_feat(query) # 修改此处改变提取特征的网络
print(queryVec.shape)
print(feats.shape)
scores = np.dot(queryVec, feats.T)
rank_ID = np.argsort(scores)[::-1]
rank_score = scores[rank_ID]
# print (rank_ID)
print(rank_score)
# number of top retrieved images to show
maxres = 6 # 检索出6张相似度最高的图片
imlist = []
for i, index in enumerate(rank_ID[0:maxres]):
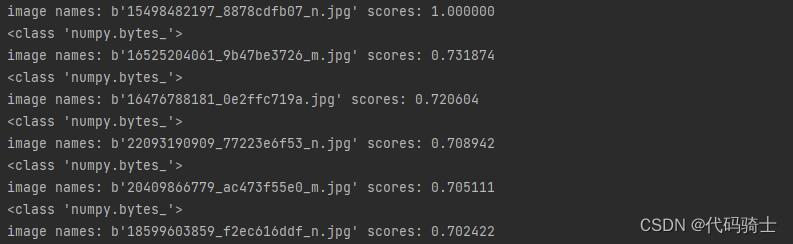
imlist.append(imgNames[index])
print(type(imgNames[index]))
print("image names: " + str(imgNames[index]) + " scores: %f" % rank_score[i])
print("top %d images in order are: " % maxres, imlist)
# show top #maxres retrieved result one by one
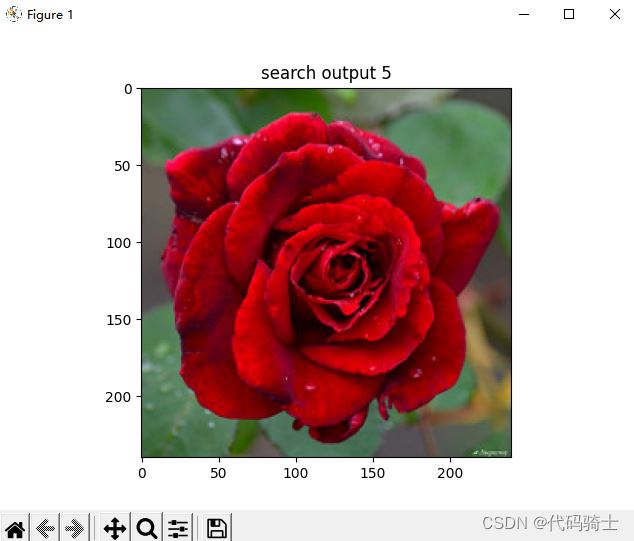
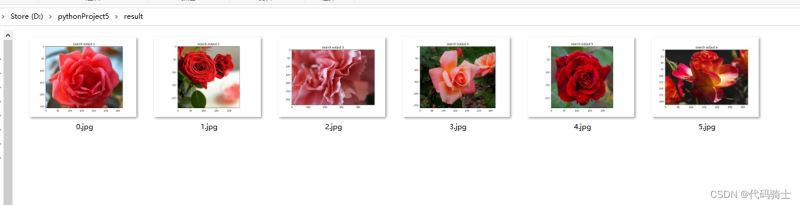
for i, im in enumerate(imlist):
image = mpimg.imread(result + "/" + str(im, 'utf-8'))
plt.title("search output %d" % (i + 1))
plt.imshow(np.uint8(image))
f = plt.gcf() # 获取当前图像
f.savefig(r'D:\pythonProject5\result\{}.jpg'.format(i),dpi=100)
#f.clear() # 释放内存
plt.show()
四、演示


1、项目文件夹
数据集
结果(运行前)
原图

2、相似度排序输出
3、保存结果
五、尾声
分享一个实用又简单的爬虫代码,搜图顶呱呱!
import os
import time
import requests
import re
def imgdata_set(save_path,word,epoch):
q=0 #停止爬取图片条件
a=0 #图片名称
while(True):
time.sleep(1)
url="https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={}&pn={}&ct=&ic=0&lm=-1&width=0&height=0".format(word,q)
#word=需要搜索的名字
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.56'
}
response=requests.get(url,headers=headers)
# print(response.request.headers)
html=response.text
# print(html)
urls=re.findall('"objURL":"(.*?)"',html)
# print(urls)
for url in urls:
print(a) #图片的名字
response = requests.get(url, headers=headers)
image=response.content
with open(os.path.join(save_path,"{}.jpg".format(a)),'wb') as f:
f.write(image)
a=a+1
q=q+20
if (q/20)>=int(epoch):
break
if __name__=="__main__":
save_path = input('你想保存的路径:')
word = input('你想要下载什么图片?请输入:')
epoch = input('你想要下载几轮图片?请输入(一轮为60张左右图片):') # 需要迭代几次图片
imgdata_set(save_path, word, epoch)
到此这篇关于Python人工智能实战之以图搜图的实现的文章就介绍到这了,更多相关Python以图搜图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

利用Python实现简单的相似图片搜索的教程
大概五年前吧,我那时还在为一家约会网站做开发工作.他们是早期创业公司,但他们也开始拥有了一些稳定用户量.不像其他约会网站,这家公司向来以洁身自好为主要市场形象.它不是一个供你鬼混的网站--是让你能找到忠实伴侣的地方. 由于投入了数以百万计的风险资本(在US大萧条之前),他们关于真爱并找寻灵魂伴侣的在线广告势如破竹.Forbes(福布斯,美国著名财经杂志)采访了他们.全国性电视节目也对他们进行了专访.早期的成功促成了事业起步时让人垂涎的指数级增长现象--他们的用户数量以每月加倍的速度增长.对他们而
-
Python图片检索之以图搜图
一.待搜索图 二.测试集 三.new_similarity_compare.py # -*- encoding=utf-8 -*- from image_similarity_function import * import os import shutil # 融合相似度阈值 threshold1 = 0.70 # 最终相似度较高判断阈值 threshold2 = 0.95 # 融合函数计算图片相似度 def calc_image_similarity(img1_path, img2_path
-
Python大批量搜索引擎图像爬虫工具详解
python图像爬虫包 最近在做一些图像分类的任务时,为了扩充我们的数据集,需要在搜索引擎下爬取额外的图片来扩充我们的训练集.搞人工智能真的是太难了
-
Python爬取网页中的图片(搜狗图片)详解
前言 最近几天,研究了一下一直很好奇的爬虫算法.这里写一下最近几天的点点心得.下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 本地下载 我们这里以sogou作为爬取的对象. 首先我们进入搜狗图片http://pic.sogou.com/,进入壁纸分类(当然只是个例子Q_Q),因为如果需要爬取某网站资料,那么就要初步的了解它- 进去后就是这个啦,然后F12进入开发人员选项,笔者用的是Chrome. 右键图片>>检查 发现我们需要的图片src是在img标签下的,于是先试着用
-
Python人工智能实战之以图搜图的实现
目录 前言 一.实验要求 二.环境配置 三.代码文件 1.vgg.py 2.index.py 3.test.py 四.演示 1.项目文件夹 2.相似度排序输出 3.保存结果 五.尾声 前言 基于vgg网络和Keras深度学习框架的以图搜图功能实现. 一.实验要求 给出一张图像后,在整个数据集中(至少100个样本)找到与这张图像相似的图像(至少5张),并把图像有顺序的展示. 二.环境配置 解释器:python3.10 编译器:Pycharm 必用配置包: numpy.h5py.matplotlib
-
Python人工智能实战之对话机器人的实现
目录 背景 用到的技术 主要流程 代码模块 Joke对象 爬虫抓取笑话 代码实现 保存到sqlite数据库 抓取笑话并保存到数据库 背景 当我慢慢的开在高速公路上,宽敞的马路非常的拥挤!这时候我喜欢让百度导航的小度给我讲笑话,但她有点弱,每次只能讲一个. 百度号称要发力人工智能,成为国内人工智能的领军企业.但从小度的智商和理解能力上,我对此非常怀疑. 所以我们干脆用Python来开发一个可以讲笑话的机器人,可以自由定制功能,想讲几个笑话就讲几个笑话. 用到的技术 本文用到以下技术: 爬虫 - 抓
-
如何用python爬取微博热搜数据并保存
主要用到requests和bf4两个库 将获得的信息保存在d://hotsearch.txt下 import requests; import bs4 mylist=[] r = requests.get(url='https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6',timeout=10) print(r.status_code) # 获取返回状态 r.encoding=r.apparent_encoding demo
-
Python项目实战之使用Django框架实现支付宝付款功能
一.前言 春节即将来临,大家肯定各种掏腰包花花花,小编相信大家在支付时候,微信.支付宝支付肯定是优先选择.今天小编心血来潮,为大家带来一个很有趣的项目,那就是使用Python web框架Django来实现支付宝支付,废话不多说,一起来看看如何实现吧. 二.建立django应用 我们来建立一个Django项目然后在里面创建一个应用,如图: 三.配置并启动 然后我们设置urls文件的内容,如图: 然后再在子应用中创建一个urls.py文件,当然你也可以直接将一些视图函数写在项目中的urls.py文件
-
用python制作个论文下载器(图形化界面)
在科研学习的过程中,我们难免需要查询相关的文献资料,而想必很多小伙伴都知道SCI-HUB,此乃一大神器,它可以帮助我们搜索相关论文并下载其原文.可以说,SCI-HUB造福了众多科研人员,用起来也是"美滋滋". 在上一篇文章中介绍了分析过程以及相应的函数代码.根据小伙伴们的反映发现了一些问题,毕竟命令框的形式用起来难免没那么"丝滑".为了让大家更方便地使用,可以"纵享丝滑",kimol君决定写一个图形界面(GUI): PS.由于近期实属忙到晕厥,这
-
Python爬虫分析微博热搜关键词的实现代码
1,使用到的第三方库 requests BeautifulSoup 美味汤 worldcloud 词云 jieba 中文分词 matplotlib 绘图 2,代码实现部分 import requests import wordcloud import jieba from bs4 import BeautifulSoup from matplotlib import pyplot as plt from pylab import mpl #设置字体 mpl.rcParams['font.sans
-
Python爬虫实战之爬取携程评论
一.分析数据源 这里的数据源是指html网页?还是Aajx异步.对于爬虫初学者来说,可能不知道怎么判断,这里辰哥也手把手过一遍. 提示:以下操作均不需要登录(当然登录也可以) 咱们先在浏览器里面搜索携程,然后在携程里面任意搜索一个景点:长隆野生动物世界,这里就以长隆野生动物世界为例,讲解如何去爬取携程评论数据. 页面下方则是评论数据 从上面两张图可以看出,点击评论下一页,浏览器的链接没有变化,说明数据是Ajax异步请求.因此我们就找到了数据是异步加载过来的,这时候需要去network里面是查
-
Python趣味实战之手把手教你实现举牌小人生成器
Selenium库的安装与简单使用 1. 安装selenium库 pip install selenium 结果如下: 2. chromedriver驱动的配置 如果你想要驱动谷歌浏览器,自动打开浏览器,必须匹配chromedriver驱动,否则会报错. 配置chromedriver驱动,一定要注意 "驱动" 和 "谷歌浏览器" 版本一定是要相匹配,否则不能使用. ① 检查谷歌浏览器的版本 这里首先提供一个详细的地址供大家查看: https://jingyan.b
-
5行Python代码实现一键批量扣图
今天给大家分享一款Python装逼实用神器. 在日常生活或者工作中,经常会遇到想将某张照片中的人物抠出来,然后拼接到其他图片上去.专业点的人可以使用 PhotoShop 的"魔棒"工具进行抠图,非专业人士则使用各种美图 APP 来实现,但是这两类方式毕竟处理能力有限,一次只能处理一张图片,而且比较复杂的图像可能耗时较久.那今天就来向大家展示第三种扣图方式--用 Python代码来实现 一键批量抠图. 1. 准备工作- 安装paddlepaddle 既然要装逼,准备工作是少不了的.所谓&