Python和JS反爬之解决反爬参数 signKey
目录
- 实战场景
- 系统分析
实战场景
Python 反爬中有一大类,叫做字体反爬,核心的理论就是通过字体文件或者 CSS 偏移,实现加密逻辑
本次要采集的站点是:54yr55y855S15b2x(Base64 加密) 站点地址为:https%3A%2F%2Fmaoyan.com%2Ffilms%2F522013(URL 编码)
上述地址打开之后,用开发者工具选中某文字之后,会发现 Elements 中,无法从源码读取到数据,
如下图所示:

类似的所有场景都属于字体编码系列,简单理解就是:
服务器源码,无法直接读取文字。
也可以用请求页面预览选项卡,判断是否为字体加密,当出现如下结论时,可以判断,其中数字信息,显示为方框。

系统分析
本以为直接进入字体加密解密逻辑,本案例就可以解决,但是当打开请求头之后,发现出现了一个请求参数 signKey,而且还加密了,那解决字体反爬前,先解决这个加密问题吧。
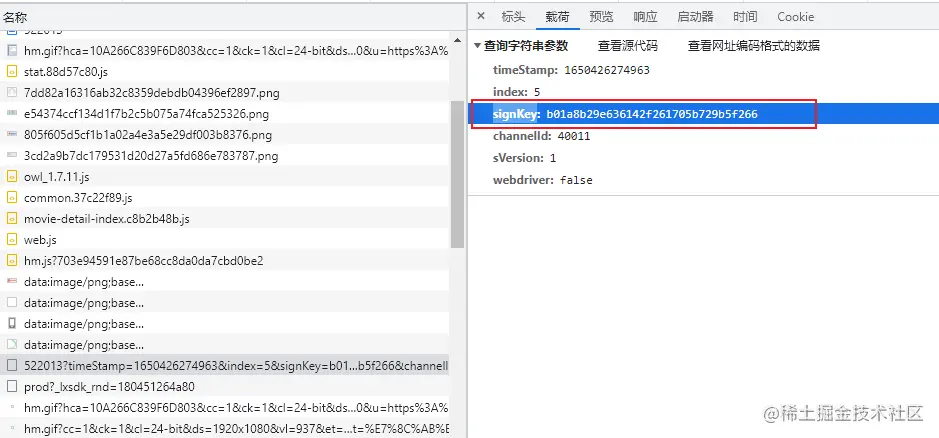
打开控制台,直接检索 signKey 参数,发现只有一个文件所有涉及。

打开 common.js 文件之后,进行格式化,继续检索关键字。
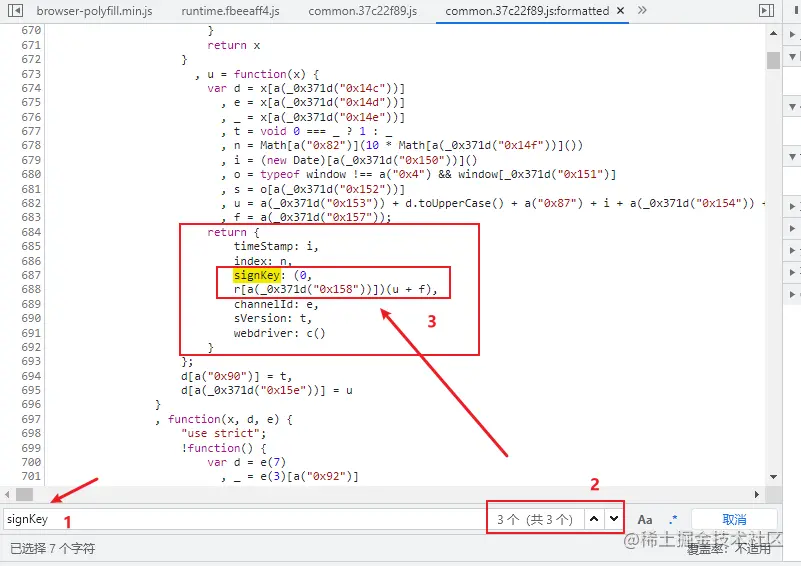
直接将断点打在 688 行附近,然后刷新页面,等待断点请求。

当发现关键字 _0x371d 时,就知道,这里需要一点点扣 JS 代码了,又是一个细致活。
待提取的 JS 代码如下所示:
u = function(x) {
var d = x[a(_0x371d("0x14c"))]
, e = x[a(_0x371d("0x14d"))]
, _ = x[a(_0x371d("0x14e"))]
, t = void 0 === _ ? 1 : _
, n = Math[a("0x82")](10 * Math[a(_0x371d("0x14f"))]())
, i = (new Date)[a(_0x371d("0x150"))]()
, o = typeof window !== a("0x4") && window[_0x371d("0x151")]
, s = o[a(_0x371d("0x152"))]
, u = a(_0x371d("0x153")) + d.toUpperCase() + a("0x87") + i + a(_0x371d("0x154")) + s + _0x371d("0x155") + n + a("0x89") + e + a(_0x371d("0x156")) + t
, f = a(_0x371d("0x157"));
return {
timeStamp: i,
index: n,
signKey: (0,
r[a(_0x371d("0x158"))])(u + f),
channelId: e,
sVersion: t,
webdriver: c()
}
每次页面刷新的时候,都可以捕获一下相关参数与值。

例如,这里可以直接得到 d = "GET",写入到我们的 JS 文件即可。
第一步加密之后,得到各个参数值,其中 u 与 f 比较重要。 通过每次断点,可以依次将代码逐步还原。 下述是一些比较重要的步骤,如果路径不清楚,可以点击下面卡片,直接询问橡皮擦。
获取 f 值

获取 _0x5827 函数内容

下述内容 r 是一个数组,可以通过索引获取其中的字符串

a(_0x371d("0x158"));
("default");
随着代码的深入,发现了最核心 signKey 参数的加密位置,截图如下:

这就是一个大工程了,没有 1 个小时,无法翻译完毕。
我们先将核心的函数扣出来,然后一点点进行替换,核心未翻译代码如下所示:
function() {
var d = e(7)
这里面好多代码
, v = u
, M = f;
s = m(s, c, u, f, i[l + 0], 7, -680876936),
f = m(f, s, c, u, i[l + 1], 12, -389564586),
u = m(u, f, s, c, i[l + 2], 17, 606105819),
c = m(c, u, f, s, i[l + 3], 22, -1044525330),
这里面好多代码
}()
翻译的时候,关注几个重点参数即可。 ** _0x371d **
var _0x371d = function (x, d) {
return (x -= 0), _0x5827[x];
};
** _0x5827 **
var _0x5827 = ["parseJSON", "parseXML", "ajaxSettings", "ajaxSetup", "statusCode", "canceled", "success", "dataType", …………;
复制到编辑器中,直接好家伙,超过 7W 字了。

加密变量 a
var a = function (x, d) {
return (x -= 0), r[x];
};
加密变量 r
加密参数 d

了解上述几个值的取值方式,解决 signKey 就变得非常简单了。
除此之外,最简单的办法是直接将 common.js 文件搭建在本地,然后用 Python 去调用,直接就可以获取到对应的数据。
JS 代码在 Python 中执行,使用如下 Demo 即可实现:
import execjs
# 执行 JS 文件
js = "js 脚本内容"
ctx = execjs.compile(js)
x = {
'method': 'GET',
'channelId': 40011,
'sVersion': 1,
'type': 'object'
}
# 传入参数
n = ctx.call('翻译之后的加密函数名', x)
到此这篇关于Python和JS反爬之解决反爬参数 signKey的文章就介绍到这了,更多相关反爬参数 signKey内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python爬虫的一个常见简单js反爬详解
前言 我们在写爬虫是遇到最多的应该就是js反爬了,今天分享一个比较常见的js反爬,这个我已经在多个网站上见到过了. 我把js反爬分为参数由js加密生成和js生成cookie等来操作浏览器这两部分,今天说的是第二种情况. 目标网站 列表页url: http://www.hnrexian.com/archives/category/jk. 正常网站我们请求url会返回给我们网页数据内容等,看看这个网站返回给我们的是什么呢? 我们把相应中返回的js代码格式化一下,方便查看. < script typ
-

python起点网月票榜字体反爬案例
目录 前言: 1.解析过程 2.开始敲代码 前言: 字体反爬是什么个意思?就是网站把自己的重要数据不直接的在源代码中呈现出来,而是通过相应字体的编码,与一个字体文件(一般后缀为ttf或woff)把相应的编码转换为自己想要的数据,知道了原理,接下来开始展示才艺 1.解析过程 老规矩哈我们先进入起点月票榜f12调试,找到书名与其对应的月票数据所在,使用xpath尝试提取 可以看到刚刚好20条数据,接下来找月票数据: 这是什么鬼xpath检索出来20条数据但是数据为空,element中数据显示
-
Python爬虫突破反爬虫机制知识点总结
1.构建合理的HTTP请求标头. HTTP的请求头是一组属性和配置信息,当您发送一个请求到网络服务器时.因为浏览器和Python爬虫发送的请求头不同,反爬行器很可能会被检测到. 2.建立学习cookie. Cookie是一把双刃剑,有它不行,没有它更不行.站点将通过cookie来追踪你的访问情况,如果发现你有爬虫行为,将立即中断您的访问,例如,填写表格时速度过快,或在短时间内浏览大量网页.而且对cookies的正确处理,也可以避免许多采集问题,建议在收集网站的过程中,检查一下这些网站生成的coo
-
Python爬虫和反爬技术过程详解
目录 一.浏览器模拟(Headers) 如何找到浏览器信息 打开浏览器,按F12(或者鼠标右键+检查) 点击如下图所示的Network按钮 按键盘Ctrl+R(MAC:Command+R)进行抓包 在Python中使用user-agent的方式如下: 常用的请求头(模拟浏览器)信息如下: 二.IP代理 Python使用IP代理的方式如下: 控制访问频率使用time模块即可: 三.Cookies模拟 手动获取cookie 自动获取cookie 使用cookies 一.浏览器模拟(Headers)
-
python政策网字体反爬实例(附完整代码)
目录 1 字体反爬案例 2 使用环境 3 安装python第三方库 4 查看woff文件 5 woff文件解决字体反爬全过程 5.1 调用第三方库 5.2 请求woff链接下载woff文件到本地 5.3 查看woff文件内容,可以通过以下两种方式 5.5 建立字体反爬后与圆字体间对应关系 5.6 得到结果 6 完整代码如下 总结 字体反爬,也是一种常见的反爬技术,这些网站采用了自定义的字体文件,在浏览器上正常显示,但是爬虫抓取下来的数据要么就是乱码,要么就是变成其他字符.下面我们通过其中一种方式
-
python爬虫爬取淘宝商品比价(附淘宝反爬虫机制解决小办法)
因为评论有很多人说爬取不到,我强调几点 kv的格式应该是这样的: kv = {'cookie':'你复制的一长串cookie','user-agent':'Mozilla/5.0'} 注意都应该用 '' ,然后还有个英文的 逗号, kv写完要在后面的代码中添加 r = requests.get(url, headers=kv,timeout=30) 自己得先登录自己的淘宝账号才有自己登陆的cookie呀,没登录cookie当然没用 以下原博 本人是python新手,目前在看中国大学MOOC的嵩天
-
Python音乐爬虫完美绕过反爬
目录 前言 开始 分析(x0) 分析(x1) 分析(x2) 分析(x3) 分析(x4) 通过分析获取到音乐 JavaScript绕过之参数冗余 CSRF攻击与防御 总结 代码 前言 大家好,我叫善念. 这是我的第二篇博客,也是第一篇技术博客,希望大家多多支持,让我更加有动力去更新一些python爬虫类的案例教程. 开始 确立目标网址:点击进入 进入到跳转页面: 可以看到出现了咱们需要的一些音乐 分析(x0) 这些音乐的源文件地址是否在咱们的网页元素中,然后再查看网页源代码中是否有咱们需要的内容.
-
Requests什么的通通爬不了的Python超强反爬虫方案!
一.前言 一个非常强的反爬虫方案 -- 禁用所有 HTTP 1.x 的请求! 现在很多爬虫库其实对 HTTP/2.0 支持得不好,比如大名鼎鼎的 Python 库 -- requests,到现在为止还只支持 HTTP/1.1,啥时候支持 HTTP/2.0 还不知道. Scrapy 框架最新版本 2.5.0(2021.04.06 发布)加入了对 HTTP/2.0 的支持,但是官网明确提示,现在是实验性的功能,不推荐用到生产环境,原文如下: " HTTP/2 support in Scrapy is
-
Python和JS反爬之解决反爬参数 signKey
目录 实战场景 系统分析 实战场景 Python 反爬中有一大类,叫做字体反爬,核心的理论就是通过字体文件或者 CSS 偏移,实现加密逻辑 本次要采集的站点是:54yr55y855S15b2x(Base64 加密) 站点地址为:https%3A%2F%2Fmaoyan.com%2Ffilms%2F522013(URL 编码) 上述地址打开之后,用开发者工具选中某文字之后,会发现 Elements 中,无法从源码读取到数据, 如下图所示: 类似的所有场景都属于字体编码系列,简单理解就是: 服务器源
-
详解selenium + chromedriver 被反爬的解决方法
问题背景:这个问题是在爬取某夕夕商城遇到的问题,原本的方案是用selenium + chromedriver + mitmproxy开心的刷,但是几天之后,发现刷不出来了,会直接跳转到登陆界面(很明显,是遭遇反爬了) 讲实话,这还是第一次用硒被反爬的,于是进行大规模的测试对比. 同台机器,用铬浏览器正常访问是不用跳转到登陆界面的,所以不是IP的问题.再用提琴手抓包对比了一下两个请求头,请求头都是一样的,所以忽略标头的反爬. 最后通过分析,可能是硒被检测出来了.于是就去查资料.大概的查到是和web
-
PyInstaller将Python文件打包为exe后如何反编译(破解源码)以及防止反编译
环境: win7+python3.5(anaconda3) 理论上,win7及以上的系统和python任意版本均可. 一.基础脚本 首先我们构建一个简单的脚本,比如输出一串数字.文本之类,这里我们输出一串文字的同时计算一下3次方好了. # -*- coding: utf-8 -*- """ Created on Wed Aug 29 09:18:13 2018 @author: Li Zeng hai """ def test(num): pri
-
python中的正斜杠与反斜杠实例验证
目录 一.历史渊源 二.实例验证 三.总结 扩展:Python 基础篇-正斜杠("/")和反斜杠("\")的用法 一.历史渊源 UNIX操作系统:设计了使用 ‘/’ 的路径分割法 DOS系统:借鉴了UNIX的目录结构,但由于在DOS系统中,斜杠 ‘/’ 已经用来作为命令行参数的标志,因此只能使用反斜杠 ‘\’ Windows系统:很多时候已经没有命令行参数的干扰,因此正斜杠与反斜杠大多数情况下可以互换 二.实例验证 桌面新建临时Excel文件——test.xlsx,
-
jupyter notebook 使用过程中python莫名崩溃的原因及解决方式
最近在使用 Python notebook时老是出现python崩溃的现象,如下图,诱发的原因是"KERNELBASE.dll",异常代码报"40000015". 折腾半天,发现我启动notebook时是用自定义startup.bat方式方式启动的,bat文件的内容为 start C:\Anaconda3\python.exe "C:/Anaconda3/Scripts/jupyter-notebook-script.py" 平时双击这个bat文
-
Python 基于Selenium实现动态网页信息的爬取
目录 一.Selenium介绍与配置 1.Selenium简介 2. Selenium+Python环境配置 二.网页自动化测试 1.启动浏览器并打开百度搜索 2.定位元素 三.爬取动态网页的名人名言 1. 网页数据分析 2. 翻页分析 3.爬取数据的存储 4. 爬取数据 四.爬取京东网站书籍信息 五.总结 一.Selenium介绍与配置 1.Selenium简介 Selenium 是ThoughtWorks专门为Web应用程序编写的一个验收测试工具.Selenium测试直接运行在浏览器中,可以
-
Python执行js字符串常见方法示例
目录 方法 1--js2py 2--execjs 3--execjs 方法 执行大型js时有点慢 特殊编码的输入或输出参数会出现报错,解决方法: 可以把输入或输出的参数用base64编码一下.base64都是英文和数字,没有特殊字符了 1--js2py pip insatll js2py # 获取执行JS的环境 context = js2py.EvalJs() # 加载执行 context.execute('放JS字符代码') 2--execjs import execjs print(exec
-
python出现RuntimeError错误问题及解决
目录 下面是出现的错误解释 下面是出现错误代码的原代码 这是修改后的正确代码 python报错:RuntimeError 这种错误原因 解决办法 下面是出现的错误解释 RuntimeError: An attempt has been made to start a new process before the current process has finished its bootstrapping phase. This probably me
-
原生js的ajax和解决跨域的jsonp(实例讲解)
最近慢慢感觉,学再多框架,库,都不如老老实实先把基础弄扎实了. 不说废话,先上一个用ajax请求下本地的一个.txt文件 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <script> window.onload =function(){ var oBtn = d