浅谈hashmap为什么查询时间复杂度为O(1)
hashmap为什么查询时间复杂度为O(1)
Hashmap是java里面一种类字典式数据结构类,能达到O(1)级别的查询复杂度,那么到底是什么保证了这一特性呢,这个就要从hashmap的底层存储结构说起
下来看一张图:
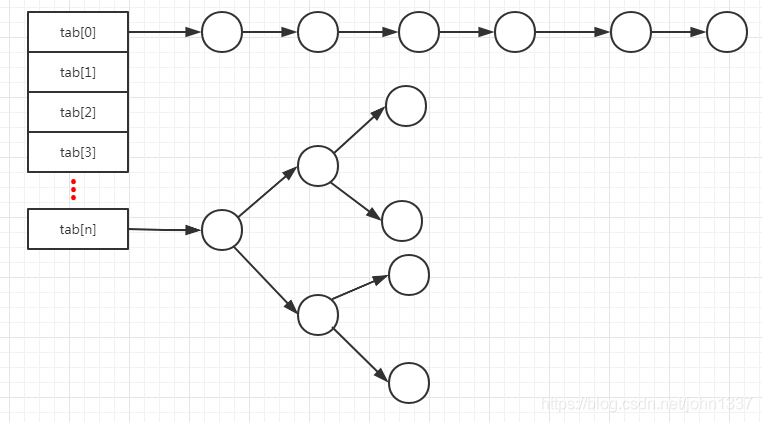
上面就是hashmap的底层存储示意图,要想查看一个键值对应的值,首先根据该键值的hash值找到该键的hash桶位置,即是tab[2]还是tab[1]等,计算某个键对应的哈希桶位置很简单,就是
int pos = (n - 1) & hash,也就是hash%n,因为位运算效率高所以在hashmap实现时使用的是位运算这种方式,需要注意的是哈希桶的数量必须是2^n,所以hashmap一旦扩容必定是哈希桶数量翻番。
通过上面的描述,我们可以知道,根据键值找到哈希桶的位置时间复杂度为O(1),使用的就是数组的高效查询。但是仅仅有这个是无法满足整个hashmap查询时间复杂度为O(1)的。hashmap在处理哈希冲突的方式如上图所示的拉链法,在冲突数据没有达到8个以前该哈希桶内部存储使用的是链表的方式,当某个哈希桶的数据超过8个的情况下,
有下面两种处理方式:
1、哈希桶的数量是没有超过64个,那么此时哈希桶数量double,然后数据迁移
2、哈希桶的数量超过了64个,将该哈希桶内部数据进行红黑树化处理
所以我们可以看到如果所有哈希桶内部数据都是链表存储的,那么每个哈希桶的数据量不会超过8个,这样当定位到某个哈希桶时,在该哈希桶继续查找也可以在O(1)时间内完成,下面看一种极端情况,所有的数据都在同一个桶里面(这种情况只在所有键值hash值相同的情况下,这种情况下查询的时间复杂度为O(lgn),比如下面给出的一个类,所有我们在设置hashmap的键值时需要特别注意),在hashmap的文档里面有这么一段描述,每个哈希桶中元素数量是成泊松分布的,
listSize = (exp(-0.5) * pow(0.5, k) / * factorial(k)),
不同数量出现的概率如下:
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
大于8: <千万分之1
通过上面的统计来看,hashmap的键值正常(不同对象的hash值不同的情况),哈希桶数量超过8个概率低于千万分之一,所以我们通常认为hashmap的查询时间复杂度为O(1)
PS:
1、哈希冲突百分百的类
/**
测试哈希冲突的类,所有的对象都返回同样的hash值
**/
public static class Student{
private String name;
Student(String name){
this.name = name;
}
@Override
public int hashCode(){
return 1;
}
@Override
public boolean equals(Object obj){
if(this == obj){
return true;
}
if(obj == null){
return false;
}
return this.name.equals(((Student)obj).name);
}
}
2、我们在实际使用hashmap时需要确保实现hashcode方法以及equals方法,否则不能作为hashmap的键值
3、在设置hashmap的键值hashcode方法时尽量保证较好的离散型
4、hashmap的键值需保证equals方法返回true时,hashcode必须相同,所以在实际中经常使用的键值类string,重写了equals以及hashcode方法
HashMap时间复杂度问题
HashMap底层采用了hash算法
根据 key 获得 hashCode 值
HashMap 初始有很多个类似于“桶”的数据结构,比如说预设了 10 个桶,通过 hashCode 经过一定的算法(这个算法必须是快速的)
得到这个 hashCode 应存在哪个桶中,然后内部生成 Map.Entry 对象将 key 和 value 存到桶中去。
所以一般情况下HashMap的插入和查找的时间复杂度都是O(1);
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

HashMap红黑树入门(实现一个简单的红黑树)
目录 1.树结构入门 1.1 什么是树? 1.2 树结构常用术语 1.3 二叉搜索树 2.红黑树原理讲解 2.1 红黑树的性质: 2.2 红黑树案例分析 3.手写红黑树 4. HashMap底层的红黑树 5 将链表转换为红黑树 treeifyBin() 总结: JDK集合源码之HashMap解析 1.树结构入门 1.1 什么是树? 树(tree)是一种抽象数据类型(ADT),用来模拟具有树状结构性质的数据集合.它是由n(n>0)个有限节点通过连接它们的边组成一个具有层次关系的集合. 把它叫做&quo
-
关于Java中HashCode方法的深入理解
1.0前言 最近在学习 Go 语言,Go 语言中有指针对象,一个指针变量指向了一个值的内存地址.学习过 C 语言的猿友应该都知道指针的概念.Go 语言语法与 C 相近,可以说是类 C 的编程语言,所以 Go 语言中有指针也是很正常的.我们可以通过将取地址符&放在一个变量前使用就会得到相应变量的内存地址. package main import "fmt" func main() { var a int= 20 /* 声明实际变量 */ var ip *int /* 声明指针变量
-
HashMap容量和负载因子使用说明
HashMap底层数据结构是数组+链表,JDK1.8中还引入了红黑树,当链表长度超过8个时,会将链表转成红黑树,以提升其查找性能. 那么,给出一个<key, value>节点,HashMap是如何确定这个节点应该放在具体哪个位置呢?(以JDK1.8为例) final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p;
-
Java HashMap实现原理分析(一)
从本文开始,介绍一下最常用的一个集合对象HashMap,HashMap存储的是键值对,本文采用的基于JDK11的源码实现. 一般大家都知道HashMap是通过put操作把一组键值对(key和value)存储到HashMap中,然后可以通过get(key)去获取key对应的value.而最重要的这两个过程是怎么实现的呢?下面我们就来对put和get这两个过程做一个分析. HashMap基本工作原理 下面先看一段源码: /** * The table, initialized on first us
-
浅谈hashmap为什么查询时间复杂度为O(1)
hashmap为什么查询时间复杂度为O(1) Hashmap是java里面一种类字典式数据结构类,能达到O(1)级别的查询复杂度,那么到底是什么保证了这一特性呢,这个就要从hashmap的底层存储结构说起 下来看一张图: 上面就是hashmap的底层存储示意图,要想查看一个键值对应的值,首先根据该键值的hash值找到该键的hash桶位置,即是tab[2]还是tab[1]等,计算某个键对应的哈希桶位置很简单,就是 int pos = (n - 1) & hash,也就是hash%n,因为位运算效率
-
浅谈HashMap中7种遍历方式的性能分析
目录 一.前言 二.HashMap遍历 2.1.迭代器EntrySet 2.2.迭代器 KeySet 2.3.ForEachEntrySet 2.4.ForEach KeySet 2.5.Lambda 2.6.Streams API 单线程 2.7.Streams API 多线程 三.性能分析 四.字节码分析 五.EntrySet性能分析 六.安全性测试 6.1.迭代器方式 6.2.For 循环方式 6.3.Lambda 方式 6.4.Stream 方式 6.5.小结 七.总结 一.前言 随着
-
浅谈MySQL模糊查询中通配符的转义
sql中经常用like进行模糊查询,而模糊查询就要用到百分号"%",下划线"_"这些通配符,其中"%"匹配任意多个字符,"_"匹配单个字符.如果我们想要模糊查询带有通配符的字符串,如"60%","user_name",就需要对通配符进行转义,有两种方式.如下: 1.反斜杠是转义符,通过反斜杠来转义%,使其不再是通配符.这里第一个%是通配符,第二个%不是通配符. select perc
-
浅谈sql连接查询的区别 inner,left,right,full
--table1 表 ID NAME QQ PHONE 1 秦云 10102800 13500000 2 在路上 10378 13600000 3 LEO 10000 13900000 4 秦云 0241458 54564512 --table2 表 ID NAME sjsj gly 1 秦云 2004-01-01 00:00:00.000 李大伟 2 秦云 2005-01-01 00:00:00.000 马化腾 3 在路上 2005-01-01 00:00:00.000 马化腾 4 秦云 20
-
浅谈laravel数据库查询返回的数据形式
版本:laravel5.4+ 问题描述:laravel数据库查询返回的数据不是单纯的数组形式,而是数组与类似stdClass Object这种对象的结合体,即使在查询构造器中调用了toArray(),也无法转换成单纯的数组形式. 问题解析: (以上图片来源于laravel学院5.3版本到5.4版本的升级手册) 如上图所示:Laravel不再支持在配置文件中定制PDO的"fetch mode",取而代之,总是使用PDO::FETCH_OBJ,如果你仍然想要为应用定制fetch模式,需要监
-
浅谈HashMap、HashTable的key和value是否可为null
结论: HashMap对象的key.value值均可为null. HahTable对象的key.value值均不可为null. 且两者的的key值均不能重复,若添加key相同的键值对,后面的value会自动覆盖前面的value,但不会报错. public class Test { public static void main(String[] args) { Map<String, String> map = new HashMap<String, String>();//Has
-
浅谈MySQL数据查询太多会OOM吗
目录 全表扫描对server层的影响 全表扫描对InnoDB的影响 InnoDB内存管理 小结 我的主机内存只有100G,现在要全表扫描一个200G大表,会不会把DB主机的内存用光? 逻辑备份时,可不就是做整库扫描吗?若这样就会把内存吃光,逻辑备份不是早就挂了? 所以大表全表扫描,看起来应该没问题.这是为啥呢? 全表扫描对server层的影响 假设,我们现在要对一个200G的InnoDB表db1. t,执行一个全表扫描.当然,你要把扫描结果保存在客户端,会使用类似这样的命令: mysql -h$
-
浅谈HashMap在高并发下的问题
前言 总所周知,HashMap不是线程安全的,在高并发情况下会出现问题.特别是,在java1.7中,多线程的HashMap会出现CPU 100%的严重问题.这个问题是怎样产生的,后续版本还会有这个问题吗(指java8及后续版本)?下面就来用通俗的语言讲解下. 解析 关于这个问题,是由于java7多线程扩容机制下链表变为循环链表,再获取该链表导致的. 看下java7中扩容的代码.java7中HashMap的实现为数组+链表的形式,没有红黑树. java7扩容的原则很简单,新数组长度为原数组2倍.遍
-
浅谈Java如何实现一个基于LRU时间复杂度为O(1)的缓存
LRU:Least Recently Used最近最少使用,当缓存容量不足时,先淘汰最近最少使用的数据.就像JVM垃圾回收一样,希望将存活的对象移动到内存的一端,然后清除其余空间. 缓存基本操作就是读.写.淘汰删除. 读操作时间复杂度为O(1)的那就是hash操作了,可以使用HashMap索引 key. 写操作时间复杂度为O(1),使用链表结构,在链表的一端插入节点,是可以完成O(1)操作,但是为了配合读,还要再次将节点放入HashMap中,put操作最优是O(1),最差是O(n). 不少童鞋就
-
浅谈Mybatis中resultType为hashmap的情况
现在有一张user表 id ,name,age 我们进行一个简单的查询: <select id="test" resultType="Uer"> select id ,name,age from user </select> 查询完后,怎么去接收这个查询结果呢,通常在这个mapper.xml对应的接口中使用List<User>做为返回值去接收,最后存储的样子就是下面的图 这是一个很简单的单表查询操作,其实这种简单的单表查询操作不需