Python实现的北京积分落户数据分析示例
本文实例讲述了Python实现的北京积分落户数据分析。分享给大家供大家参考,具体如下:
北京积分落户状况 获取数据(爬虫/文件下载)—> 分析 (维度—指标)
- 从公司维度分析不同公司对落户人数指标的影响 , 即什么公司落户人数最多也更容易落户
- 从年龄维度分析不同年龄段对落户人数指标影响 , 即什么年龄段落户人数最多也更容易落户
- 从百家姓维度分析不同姓对落户人数的指标影响 , 即什么姓的落户人数最多即也更容易落户
- 不同分数段的占比情况
# 导入库 import numpy as np import pandas as pd import matplotlib.pyplot as plt from matplotlib import font_manager
#读取数据(文件) , 并查看数据相应结构和格式
lh_data = pd.read_csv('./bj_luohu.csv',index_col='id',usecols=(0,1,2,3,4))
lh_data.describe()
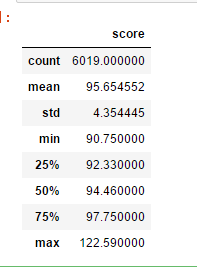
# 1. 公司维度---人数指标
# 对公司进行分组聚合 , 并查看分数的相关数据 (个数 , 总分数 , 平均分 , 人数占比)
group_company = lh_data.groupby('company',as_index=False)['score'].agg(['count','sum','mean']).sort_values('count',ascending=False)
#更改列名称
group_company.rename(columns={'count':'people_num','sum':'score_sum','mean':'score_mean'},inplace=True)
#定一个函数 , 得到占比
def num_percent(people_num=1,people_sum=1):
return str('%.2f'%(people_num / people_sum * 100))+'%'
#增加一个占比列
group_company['people_percent'] = group_company['people_num'].apply(num_percent,people_sum=lh_data['name'].count())
#查看只有一个人落户的公司 布尔索引
group_company[group_company['people_num'] == 1]
group_company.head(10)

# 2.年龄维度----人数指标
#将出生年月转为年龄
lh_data['age'] = (pd.to_datetime('2019-09') - pd.to_datetime(lh_data['birthday'])) / pd.Timedelta('365 days')
# 分桶
lh_data.describe()
bins_age = pd.cut(lh_data['age'],bins=np.arange(30,70,5))
bins_age_group = lh_data['age'].groupby(bins_age).count()
bins_age_group.index = [str(i.left) + '~' + str(i.right) for i in bins_age_group.index]
bins_age_group.plot(kind='bar',alpha=1,rot=60,grid=0.2)

# 3. 姓维度----人数指标
# 增加姓列
#定义一个函数 得到姓名的姓
def get_fname(name):
if len(str(name)) <= 3:
return str(name[0])
else:
return str(name[0:2])
lh_data['fname'] = lh_data['name'].apply(get_fname)
# 对姓进行分组
group_fname = lh_data.groupby('fname')['score'].agg(['count','sum','mean']).sort_values('count',ascending=False)
# 更改列名称
group_fname.rename(columns={'count':'people_num','sum':'people_sum','mean':'score_mean'},inplace=True)
# 增加占比列
group_fname['people_percent'] = group_fname['people_num'].apply(num_percent,people_sum=lh_data['name'].count())
group_fname.head(10)

# 4. 查看分数段占比 # 分桶 将分数划分为一个个的区间 bins_score = pd.cut(lh_data['score'],np.arange(90,130,5)) # 将分数装入对应的桶里 bins_score_group = lh_data['score'].groupby(bins_score).count() # 更改索引显示格式 bins_score_group.index = [str(i.left)+'~'+str(i.right) for i in bins_score_group.index] bins_score_group.plot(kind='bar',alpha=1,rot=60,grid=0.2,title='score-people_num',colormap='RdBu_r')

总结
1.pandas的绘图方法不够灵活 , 功能也不够强大 , 最好还是使用matplotlib绘图
2.记住数据分析最重要的两个方法 分组: groupby() 和 分桶:cut() , 前者一般用于离散的数据(姓,公司) , 后者用于连续数据 (年龄段,分数段)
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数学运算技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。
相关推荐
-
Python数据分析matplotlib设置多个子图的间距方法
注意,要看懂这里,必须具备简单的Python数据分析知识,必须知道matplotlib的简单使用! 例1: plt.subplot(221) # 第一行的左图 plt.subplot(222) # 第一行的右图 plt.subplot(212) # 第二整行 plt.title('xxx') plt.tight_layout() #设置默认的间距 例2: for i in range(25): plt.subplot(5,5,i+1) plt.tight_layout() 例3: # 设定画图板
-
分享一下Python数据分析常用的8款工具
Python是数据处理常用工具,可以处理数量级从几K至几T不等的数据,具有较高的开发效率和可维护性,还具有较强的通用性和跨平台性.Python可用于数据分析,但其单纯依赖Python本身自带的库进行数据分析还是具有一定的局限性的,需要安装第三方扩展库来增强分析和挖掘能力. Python数据分析需要安装的第三方扩展库有:Numpy.Pandas.SciPy.Matplotlib.Scikit-Learn.Keras.Gensim.Scrapy等,以下是千锋武汉Python培训老师对该第三方扩展库的
-
Python数据分析中Groupby用法之通过字典或Series进行分组的实例
在数据分析中有时候需要自己定义分组规则 这里简单介绍一下用一个字典实现分组 people=DataFrame( np.random.randn(5,5), columns=['a','b','c','d','e'], index=['Joe','Steve','Wes','Jim','Travis'] ) mapping={'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'} by_column=people.grou
-
Python数据分析之获取双色球历史信息的方法示例
本文实例讲述了Python数据分析之获取双色球历史信息的方法.分享给大家供大家参考,具体如下: 每个人都有一颗中双色球大奖的心,对于技术人员来说,通过技术分析,可以增加中奖几率,现使用python语言收集历史双色球中奖信息,之后进行预测分析. 说明:采用2016年5月15日获取的双色球数据为基础进行分析,总抽奖数1940次. 初级代码,有些内容比较繁琐,有更好的代码,大家可以分享. #!/usr/bin/python # -*- coding:UTF-8 -*- #coding:utf-8 #a
-

Python运用于数据分析的简单教程
最近,Analysis with Programming加入了Planet Python.作为该网站的首批特约博客,我这里来分享一下如何通过Python来开始数据分析.具体内容如下: 数据导入 导入本地的或者web端的CSV文件: 数据变换: 数据统计描述: 假设检验 单样本t检验: 可视化: 创建自定义函数. 数据导入 这是很关键的一步,为了后续的分析我们首先需要导入数据.通常来说,数据是CSV格式,就算不是,至少也可以转
-
python数据分析数据标准化及离散化详解
本文为大家分享了python数据分析数据标准化及离散化的具体内容,供大家参考,具体内容如下 标准化 1.离差标准化 是对原始数据的线性变换,使结果映射到[0,1]区间.方便数据的处理.消除单位影响及变异大小因素影响. 基本公式为: x'=(x-min)/(max-min) 代码: #!/user/bin/env python #-*- coding:utf-8 -*- #author:M10 import numpy as np import pandas as pd import matplo
-
基于Python实现的微信好友数据分析
最近微信迎来了一次重要的更新,允许用户对"发现"页面进行定制.不知道从什么时候开始,微信朋友圈变得越来越复杂,当越来越多的人选择"仅展示最近三天的朋友圈",大概连微信官方都是一脸的无可奈何.逐步泛化的好友关系,让微信从熟人社交逐渐过渡到陌生人社交,而朋友圈里亦真亦幻的状态更新,仿佛在努力证明每一个个体的"有趣". 有人选择在朋友圈里记录生活的点滴,有人选择在朋友圈里展示观点的异同,可归根到底,人们无时无刻不在窥探着别人的生活,唯独怕别人过多地了解
-
使用Python对微信好友进行数据分析
1.准备工作 1.1 库介绍 只有登录微信才能获取到微信好友的信息,本文采用wxpy该第三方库进行微信的登录以及信息的获取. wxpy 在 itchat 的基础上,通过大量接口优化提升了模块的易用性,并进行丰富的功能扩展. wxpy一些常见的场景: •控制路由器.智能家居等具有开放接口的玩意儿 •运行脚本时自动把日志发送到你的微信 •加群主为好友,自动拉进群中 •跨号或跨群转发消息 •自动陪人聊天 •逗人玩 总而言之,可用来实现各种微信个人号的自动化操作. 1.2 wxpy库安装 wxpy 支持
-
Python数据分析:手把手教你用Pandas生成可视化图表的教程
大家都知道,Matplotlib 是众多 Python 可视化包的鼻祖,也是Python最常用的标准可视化库,其功能非常强大,同时也非常复杂,想要搞明白并非易事.但自从Python进入3.0时代以后,pandas的使用变得更加普及,它的身影经常见于市场分析.爬虫.金融分析以及科学计算中. 作为数据分析工具的集大成者,pandas作者曾说,pandas中的可视化功能比plt更加简便和功能强大.实际上,如果是对图表细节有极高要求,那么建议大家使用matplotlib通过底层图表模块进行编码.当然,我
-
Python数据分析库pandas基本操作方法
pandas是什么? 是它吗? ....很显然pandas没有这个家伙那么可爱.... 我们来看看pandas的官网是怎么来定义自己的: pandas is an open source, easy-to-use data structures and data analysis tools for the Python programming language. 很显然,pandas是python的一个非常强大的数据分析库! 让我们来学习一下它吧! 1.pandas序列 import nump
-
PowerBI和Python关于数据分析的对比
前言 如果你对数据分析有一定的了解,那你一定听说过一些亲民好用的数据分析的工具,如Excel.Tableau.PowerBI等等等等,它们都是数据分析的得力助手.像经常使用这些根据的伙伴肯定也有苦恼的时候,不足之处也是显而易见:操作繁琐,复用性差,功能相对局限单一. 很多经常会用到数据分析的伙伴会问有没有一款便捷好用的工具!肯定有啊,Python的出现和普及,很容易就能改变这些窘境! 怎么解决呢?--Python Python有很多优点,如果你能很好的运用到工作中,会发现工作效率大大提升,涨薪也
-
Python数据分析之双色球基于线性回归算法预测下期中奖结果示例
本文实例讲述了Python数据分析之双色球基于线性回归算法预测下期中奖结果.分享给大家供大家参考,具体如下: 前面讲述了关于双色球的各种算法,这里将进行下期双色球号码的预测,想想有些小激动啊. 代码中使用了线性回归算法,这个场景使用这个算法,预测效果一般,各位可以考虑使用其他算法尝试结果. 发现之前有很多代码都是重复的工作,为了让代码看的更优雅,定义了函数,去调用,顿时高大上了 #!/usr/bin/python # -*- coding:UTF-8 -*- #导入需要的包 import pan