NodeJs实现简单的爬虫功能案例分析
1.爬虫:爬虫,是一种按照一定的规则,自动地抓取网页信息的程序或者脚本;利用NodeJS实现一个简单的爬虫案例,爬取Boss直聘网站的web前端相关的招聘信息,以广州地区为例;
2.脚本所用到的nodejs模块
express 用来搭建一个服务,将结果渲染到页面
swig 模板引擎
cheerio 用来抓取页面的数据
requests 用来发送请求数据(具体可查:https://www.npmjs.com/package/requests)
async 用来处理异步操作,解决请求嵌套的问题,脚本中只使用了async.whilst(test,iteratee,callback),具体可见:https://caolan.github.io/async/
3.实现流程:
首先先获取到所爬取页面的URL,打开boss直聘网站,搜索web前端既可以获取到 https://www.zhipin.com/c101280100-p100901/?page=1&ka=page-next
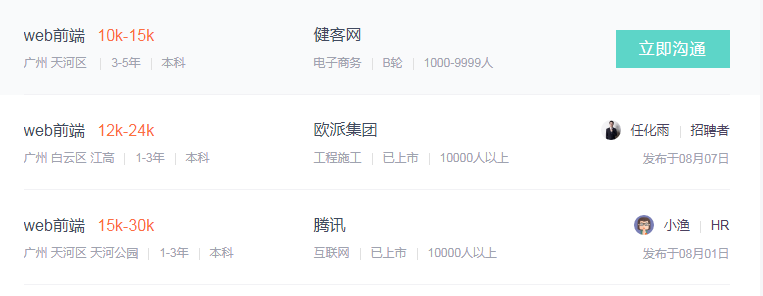
然后通过Chrome浏览器打开F12,获取到信息中多对应的dom节点,即可知道想要获取信息;
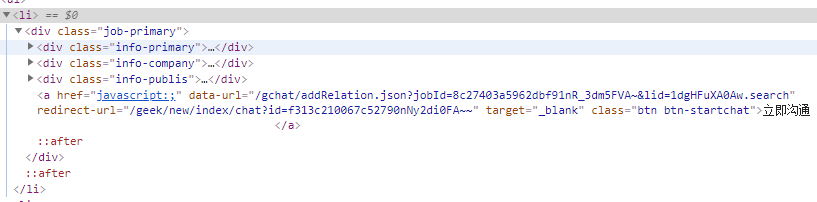
4.代码实现
目录结构:
app.js
var cheerio = require('cheerio');
var requests = require('requests');
var async = require('async');
var express = require('express');
var swig = require('swig');
var app = express();
swig.setDefaults({cache:false});
app.set('views','./views/');
app.set('view engine','html');
app.engine('html',swig.renderFile);
app.get('/',function(req,res,next){
var page = 1; //当前页数
var list = []; //保存记录
async.whilst(
function(){
return page < 11;
},
function(callback){
requests(`https://www.zhipin.com/c101280100-p100901/?page=${page}&ka=page-next`)
.on('data',function(chunk){
var $ = cheerio.load(chunk.toString());
$('.job-primary').each(function(){
var company = $(this).find('.info-company .company-text .name').text();
var job_title = $(this).find('.info-primary .name .job-title').text();
var salary = $(this).find('.info-primary .name .red').text();
var description = $(this).find('.info-company .company-text p').text();
var area = $(this).find('.info-primary p').text();
var item = {
company:company,
job_title:job_title,
salary:salary,
description:description,
area:area
};
list.push(item);
});
page++;
callback();
}).on('end',function(err){
if(err){
console.log(err);
}
if(page==10){
res.render('index',{
lists:list
});
}
});
},
function(err){
console.log(err);
}
);
});
//监听
app.listen(8080);
view/index.html页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<style>
table{
width:1300px;
border:1px solid #ccc;
border-collapse: collapse;
text-align: center;
margin:0 auto;
}
td,tr,th{
border:1px solid #ccc;
border-collapse: collapse;
}
tr{
height:30px;
line-height: 30px;
}
</style>
<body>
<table>
<thead>
<tr>
<th>公司名称</th>
<th>公司地址</th>
<th>薪资</th>
<th>公司描述</th>
<th>岗位名称</th>
</tr>
</thead>
<tbody>
{% for list in lists %}
<tr>
<td>{{list.company}}</td>
<td>{{list.area}}</td>
<td>{{list.salary}}</td>
<td>{{list.description}}</td>
<td>{{list.job_title}}</td>
</tr>
{% endfor %}
</tbody>
</table>
</body>
</html>
5.启动
直接通过 node app.js启动即可;
6.运行结果(http://localhost:8080),只截取部分数据

总结
以上所述是小编给大家介绍的NodeJs实现简单的爬虫功能,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-

Nodejs爬虫进阶教程之异步并发控制
之前写了个现在看来很不完美的小爬虫,很多地方没有处理好,比如说在知乎点开一个问题的时候,它的所有回答并不是全部加载好了的,当你拉到回答的尾部时,点击加载更多,回答才会再加载一部分,所以说如果直接发送一个问题的请求链接,取得的页面是不完整的.还有就是我们通过发送链接下载图片的时候,是一张一张来下的,如果图片数量太多的话,真的是下到你睡完觉它还在下,而且我们用nodejs写的爬虫,却竟然没有用到nodejs最牛逼的异步并发的特性,太浪费了啊. 思路 这次的的爬虫是上次那个的升级版,不过呢,上次那个虽
-
nodejs爬虫抓取数据乱码问题总结
一.非UTF-8页面处理. 1.背景 windows-1251编码 比如俄语网站:https://vk.com/cciinniikk 可耻地发现是这种编码 所有这里主要说的是 Windows-1251(cp1251)编码与utf-8编码的问题,其他的如 gbk就先不考虑在内了~ 2.解决方案 1. 使用js原生编码转换 但是我现在还没找到办法哈.. 如果是utf-8转window-1251还可以http://stackoverflow.com/questions/2696481/encoding
-
NodeJS制作爬虫全过程(续)
书接上回,我们需要修改程序以达到连续抓取40个页面的内容.也就是说我们需要输出每篇文章的标题.链接.第一条评论.评论用户和论坛积分. 如图所示,$('.reply_author').eq(0).text().trim();得到的值即为正确的第一条评论的用户. {<1>} 在eventproxy获取评论及用户名内容后,我们需要通过用户名跳到用户界面继续抓取该用户积分 复制代码 代码如下: var $ = cheerio.load(topicHtml); //此URL为下一步抓取目标URL var
-
nodejs制作爬虫实现批量下载图片
今天想获取一大批猫的图片,然后就在360流浪器搜索框中输入 猫 ,然后点击图片.就看到了一大波猫的图片: http://image.so.com/i?q=%E7%8... ,我在想啊,要是审查元素,一张张手动下载,多麻烦,所以打算写程序来实现.不写不知道,一写发现里面还是有很多道道的. 1. 爬取图片链接 因为之前也写过nodejs爬虫功能(参见:NodeJS制作爬虫全过程),所以觉得应该很简单,就用cheerio来处理dom啦,结果打印一下啥也没有,后来查看源代码: 发现 waterfall_
-
nodeJs爬虫获取数据简单实现代码
本文实例为大家分享了nodeJs爬虫获取数据代码,供大家参考,具体内容如下 var http=require('http'); var cheerio=require('cheerio');//页面获取到的数据模块 var url='http://www.jcpeixun.com/lesson/1512/'; function filterData(html){ /*所要获取到的目标数组 var courseData=[{ chapterTitle:"", videosData:{ v
-
简单好用的nodejs 爬虫框架分享
这个就是一篇介绍爬虫框架的文章,开头就不说什么剧情了.什么最近一个项目了,什么分享新知了,剧情是挺好,但介绍的很初级,根本就没有办法应用,不支持队列的爬虫,都是耍流氓. 所以我就先来举一个例子,看一下这个爬虫框架是多么简单并可用. 第一步:安装 Crawl-pet nodejs 就不用多介绍吧,用 npm 安装 crawl-pet $ npm install crawl-pet -g --production 运行,程序会引导你完成配置,首次运行,会在项目目录下生成 info.json 文件 $
-
详解nodejs爬虫程序解决gbk等中文编码问题
使用nodejs写了一个爬虫的demo,目的是提取网页的title部分. 遇到最大的问题就是网页的编码与nodejs默认编码不一致造成的乱码问题.nodejs支持utf8, ucs2, ascii, binary, base64, hex等编码方式,但是对于汉语言来说编码主要分为三种,utf-8,gb2312,gbk.这里面gbk是完全兼容gb2312的,因此在处理编码的时候主要就分为utf-8以及gbk两大类.(这是在没有考虑到其他国家的编码情况,比如日本的Shift_JIS编码等,同时这里这
-
NodeJS制作爬虫全过程
今天来学习alsotang的爬虫教程,跟着把CNode简单地爬一遍. 建立项目craelr-demo 我们首先建立一个Express项目,然后将app.js的文件内容全部删除,因为我们暂时不需要在Web端展示内容.当然我们也可以在空文件夹下直接 npm install express来使用我们需要的Express功能. 目标网站分析 如图,这是CNode首页一部分div标签,我们就是通过这一系列的id.class来定位我们需要的信息. 使用superagent获取源数据 superagent就是
-
NodeJs实现简单的爬虫功能案例分析
1.爬虫:爬虫,是一种按照一定的规则,自动地抓取网页信息的程序或者脚本:利用NodeJS实现一个简单的爬虫案例,爬取Boss直聘网站的web前端相关的招聘信息,以广州地区为例: 2.脚本所用到的nodejs模块 express 用来搭建一个服务,将结果渲染到页面 swig 模板引擎 cheerio 用来抓取页面的数据 requests 用来发送请求数据(具体可查:https://www.npmjs.com/package/requests) async
-
nodeJS实现简单网页爬虫功能的实例(分享)
本文将使用nodeJS实现一个简单的网页爬虫功能 网页源码 使用http.get()方法获取网页源码,以hao123网站的头条页面为例 http://tuijian.hao123.com/hotrank var http = require('http'); http.get('http://tuijian.hao123.com/hotrank',function(res){ var data = ''; res.on('data',function(chunk){ data += chunk;
-
基于NodeJS+MongoDB+AngularJS+Bootstrap开发书店案例分析
这章的目的是为了把前面所学习的内容整合一下,这个示例完成一个简单图书管理模块,因为中间需要使用到Bootstrap这里先介绍Bootstrap. 示例名称:天狗书店 功能:完成前后端分离的图书管理功能,总结前端学习过的内容. 技术:NodeJS.Express.Monk.MongoDB.AngularJS.BootStrap.跨域 效果: 一.Bootstrap Bootstrap是一个UI框架,它支持响应式布局,在PC端与移动端都表现不错. Bootstrap是Twitter推出的一款简洁.直
-
Spring Boot 发送邮件功能案例分析
邮件服务简介 邮件服务在互联网早期就已经出现,如今已成为人们互联网生活中必不可少的一项服务.那么邮件服务是怎么工作的呢?如下给出邮件发送与接收的典型过程: 1.发件人使用SMTP协议传输邮件到邮件服务器A: 2.邮件服务器A根据邮件中指定的接收者,投送邮件至相应的邮件服务器B: 3.收件人使用POP3协议从邮件服务器B接收邮件. SMTP(Simple Mail Transfer Protocol)是电子邮件(email)传输的互联网标准,定义在RFC5321,默认使用端口25: POP3(Po
-
Vue项目引用百度地图并实现搜索定位等功能(案例分析)
目录 一.效果图及功能点 二.前期准备 三.引入百度地图 四.功能解析 本文给大家介绍如何在vue项目中引用百度地图,并设计实现简单的地图定位.地址搜索功能. Tip:本篇文章为案例分析,技术点较多,所以篇幅较长,认真阅览的你一定会学到很多知识. 前言:百度地图开放平台 给开发者们提供了丰富的地图功能与服务,使我们的项目中可以轻松地实现地图定位.地址搜索.路线导航等功能.本文给大家介绍如何在vue项目中引用百度地图,并设计实现简单的地图定位.地址搜索功能. 一.效果图及功能点 先来看一下效果图
-
Python实现自动装机功能案例分析
前言 提示:在管理服务器的过程中,发现有很多服务器在启动的过程中默认以PXE方式启动,这就导致我们无法将PXE装机程序放开到所有的交换机端口中,本文是以Python对dell服务器进行了一些控制,更多厂商机器的管理和控制,仍在调研中. 提示:以下是本篇文章正文内容,下面案例可供参考 一.利用snmp协议获取到目标机器的网卡mac地址 代码如下 def get_mac(ipmi, netcard): #ipmi即服务器idrac_ip,netcard即网卡序列号(一般是4个,从1开始) # 将控制
-
使用Python实现企业微信通知功能案例分析
目录 前言 1.新建应用 2.获取Secret 3.代码实现 4.实现效果: 前言 常见的通知方式有:邮件,电话,短信,微信.短信和电话:通常是收费的,较少使用:邮件:适合带文件类型的通知,较正 式,存档使用:微信:适合告警类型通知,较方便.这里说的微信,是企业微信. 本文目的:通过企业微信应用给企业成员发消息. 如何实现企业微信通知? 1.新建应用 登陆网页版企业微信 (https://work.weixin.qq.com),点击 应用管理 → 应用 → 创建应用 上传应用的 logo,输入应
-
jQuery实现简单的计时器功能实例分析
本文实例讲述了jQuery实现简单的计时器功能.分享给大家供大家参考,具体如下: 在写项目的过程中遇到要前端60秒发送验证码的业务需求,于是用到计时器的功能: setInterval(function xxx(){ //业务逻辑 },隔多少时间执行一次) 60秒计时思路: 1.设置秒数:60s 2.设置内容:实时改变,秒数+内容 3.结束后:去掉按钮的disable,内容恢复原来样子 //计时器60秒 function timeInterval(){ $("#code_send_btn"
-
Vue.js递归组件实现组织架构树和选人功能案例分析
大家好!先上图看看本次案例的整体效果. **浪奔,浪流,万里涛涛江水永不休.如果在jq时代来实这个功能简直有些噩梦了,但是自从前端思想发展到现在的以MVVM为主流的大背景下,来实现一个这样繁杂的功能简直不能容易太多.下面就手把手带您一步步拨开这个案例的层层迷雾.** 实现步骤如下: 1. api构建部门和员工信息接口,vuex全局存放部门list和员工list数据信息. api: export default { getEmployeeList () { return { returncode:
-
Python编程快速上手——正则表达式查找功能案例分析
本文实例讲述了Python正则表达式查找功能.分享给大家供大家参考,具体如下: 题目如下: 编写一个程序,打开文件夹中所有的.txt文件,查找匹配用户提供的正则表达式的所有行.结果应该打印到屏幕上. 思路如下: 程序需要做的事情如下: 遍历文件夹得到所有.txt文件名 打开所有.txt文件,正则表达式进行模式匹配 查找结果显示到屏幕 代码需要做的事情如下: 导入re,os模块 定义正则表达式函数 函数内进行正则表达式匹配,并返回匹配所在行列表 for调用os.listdir(path),生成.t