RocketMQ存储文件的实现
RocketMQ存储路径默认是${ROCKRTMQ_HOME}/store,主要存储消息、主题对应的消息队列的索引等。
1、概述
查看其目录文件

commitlog:消息的存储目录config:运行期间一些配置信息

consumequeue:消息消费队列存储目录index:消息索引文件存储目录abort:如果存在abort文件说明Broker非正常关闭,该文件默认启动时创建,正常退出时删除checkpoint:文件检测点。存储commitlog文件最后一次刷盘时间戳、consumequeue最后一次刷盘时间、index索引文件最后一次刷盘时间戳。
2、文件简介
2.1、commitlog文件
commitlog文件的存储地址:$HOME\store\commitlog${fileName},每个文件的大小默认1G =102410241024,commitlog的文件名fileName,名字长度为20位,左边补零,剩余为起始偏移量;比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当这个文件满了,第二个文件名字为00000000001073741824,起始偏移量为1073741824,以此类推,第三个文件名字为00000000002147483648,起始偏移量为2147483648 ,消息存储的时候会顺序写入文件,当文件满了,写入下一个文件。

commitlog目录下的文件主要存储消息,每条消息的长度不同,查看其存储的逻辑视图,每条消息的前面4个字节存储该条消息的总长度。

文件的消息单元存储详细信息
| 编号 | 字段简称 | 字段大小(字节) | 字段含义 |
|---|---|---|---|
| 1 | msgSize | 4 | 代表这个消息的大小 |
| 2 | MAGICCODE | 4 | MAGICCODE = daa320a7 |
| 3 | BODY CRC | 4 | 消息体BODY CRC 当broker重启recover时会校验 |
| 4 | queueId | 4 | |
| 5 | flag | 4 | |
| 6 | QUEUEOFFSET | 8 | 这个值是个自增值不是真正的consume queue的偏移量,可以代表这个consumeQueue队列或者tranStateTable队列中消息的个数,若是非事务消息或者commit事务消息,可以通过这个值查找到consumeQueue中数据,QUEUEOFFSET * 20才是偏移地址;若是PREPARED或者Rollback事务,则可以通过该值从tranStateTable中查找数据 |
| 7 | PHYSICALOFFSET | 8 | 代表消息在commitLog中的物理起始地址偏移量 |
| 8 | SYSFLAG | 4 | 指明消息是事物事物状态等消息特征,二进制为四个字节从右往左数:当4个字节均为0(值为0)时表示非事务消息;当第1个字节为1(值为1)时表示表示消息是压缩的(Compressed);当第2个字节为1(值为2)表示多消息(MultiTags);当第3个字节为1(值为4)时表示prepared消息;当第4个字节为1(值为8)时表示commit消息;当第3/4个字节均为1时(值为12)时表示rollback消息;当第3/4个字节均为0时表示非事务消息 |
| 9 | BORNTIMESTAMP | 8 | 消息产生端(producer)的时间戳 |
| 10 | BORNHOST | 8 | 消息产生端(producer)地址(address:port) |
| 11 | STORETIMESTAMP | 8 | 消息在broker存储时间 |
| 12 | STOREHOSTADDRESS | 8 | 消息存储到broker的地址(address:port) |
| 13 | RECONSUMETIMES | 8 | 消息被某个订阅组重新消费了几次(订阅组之间独立计数),因为重试消息发送到了topic名字为%retry%groupName的队列queueId=0的队列中去了,成功消费一次记录为0; |
| 14 | PreparedTransaction Offset | 8 | 表示是prepared状态的事物消息 |
| 15 | messagebodyLength | 4 | 消息体大小值 |
| 16 | messagebody | bodyLength | 消息体内容 |
| 17 | topicLength | 1 | topic名称内容大小 |
| 18 | topic | topicLength | topic的内容值 |
| 19 | propertiesLength | 2 | 属性值大小 |
| 20 | properties | propertiesLength | propertiesLength大小的属性数据 |
2.2、consumequeue
RocketMQ基于主题订阅模式实现消息的消费,消费者关心的是主题下的所有消息。
但是由于不同的主题的消息不连续的存储在commitlog文件中,如果只是检索该消息文件可想而知会有多慢,为了提高效率,对应的主题的队列建立了索引文件,为了加快消息的检索和节省磁盘空间,每一个consumequeue条目存储了消息的关键信息commitog文件中的偏移量、消息长度、tag的hashcode值。

查看目录结构:
单个consumequeue文件中默认包含30万个条目,每个条目20个字节,所以每个文件的大小是固定的20w x 20字节,单个consumequeue文件可认为是一个数组,下标即为逻辑偏移量,消息的消费进度存储的偏移量即逻辑偏移量。
2.3、IndexFile
IndexFile:用于为生成的索引文件提供访问服务,通过消息Key值查询消息真正的实体内容。在实际的物理存储上,文件名则是以创建时的时间戳命名的,固定的单个IndexFile文件大小约为400M,一个IndexFile可以保存 2000W个索引;
2.3.1、IndexFile结构分析
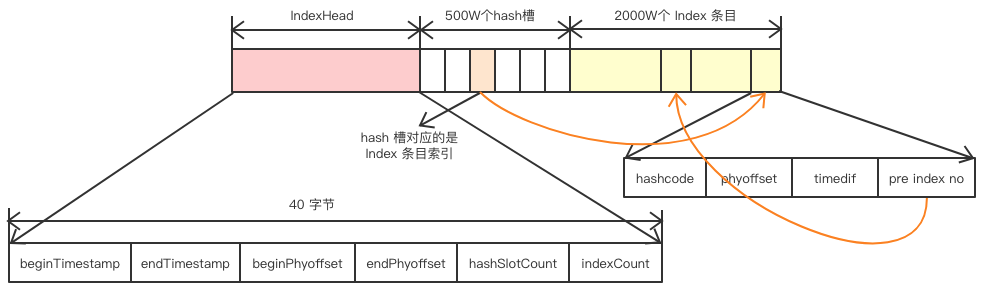
IndexHead 数据: beginTimestamp:该索引文件包含消息的最小存储时间 endTimestamp:该索引文件包含消息的最大存储时间 beginPhyoffset:该索引文件中包含消息的最小物理偏移量(commitlog 文件偏移量) endPhyoffset:该索引文件中包含消息的最大物理偏移量(commitlog 文件偏移量) hashSlotCount:hashslot个数,并不是 hash 槽使用的个数,在这里意义不大, indexCount:已使用的 Index 条目个数
Hash 槽: 一个 IndexFile 默认包含 500W 个 Hash 槽,每个 Hash 槽存储的是落在该 Hash 槽的 hashcode 最新的 Index 的索引
Index 条目列表 hashcode:key 的 hashcode phyoffset:消息对应的物理偏移量 timedif:该消息存储时间与第一条消息的时间戳的差值,小于 0 表示该消息无效 preIndexNo:该条目的前一条记录的 Index 索引,hash 冲突时,根据该值构建链表结构
2.3.2、IndexFile条目存储
RocketMQ将消息索引键与消息的偏移量映射关系写入IndexFile中,其核心的实现方法是public boolean putKey(final String key, final long phyOffset, final long storeTimestamp);参数含义分别是消息的索引、消息的物理偏移量、消息的存储时间。
public boolean putKey(final String key, final long phyOffset, final long storeTimestamp) {
//判断当前的条目数是否大于最大的允许的条目数
if (this.indexHeader.getIndexCount() < this.indexNum) {
//获取KEY的hash值(正整数)
int keyHash = indexKeyHashMethod(key);
//计算hash槽的下标
int slotPos = keyHash % this.hashSlotNum;
//获取hash槽的物理地址
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
FileLock fileLock = null;
try {
// fileLock = this.fileChannel.lock(absSlotPos, hashSlotSize,
// false);
//获取hash槽中存储的数据
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
//判断值是否小于等于0或者 大于当前索引文件的最大条目
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()) {
slotValue = invalidIndex;
}
//计算当前消息存储时间与第一条消息时间戳的时间差
long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();
//秒
timeDiff = timeDiff / 1000;
if (this.indexHeader.getBeginTimestamp() <= 0) {
timeDiff = 0;
} else if (timeDiff > Integer.MAX_VALUE) {
timeDiff = Integer.MAX_VALUE;
} else if (timeDiff < 0) {
timeDiff = 0;
}
//计算条目的物理地址 = 索引头部大小(40字节) + hash槽的大小(4字节)*槽的数量(500w) + 当前索引最大条目的个数*每index的大小(20字节)
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ this.indexHeader.getIndexCount() * indexSize;
//依次存入 key的hash值(4字节)+消息的物理偏移量(8字节)+消息存储时间戳和index文件的时间戳差(4字节)+当前hash槽的值(4字节)
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
//存储当前index中包含的条目数量存入hash槽中,覆盖原先hash槽的值
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
if (this.indexHeader.getIndexCount() <= 1) {
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
}
//更新文件索引的头信息,hash槽的总数、index条目的总数、最后消息的物理偏移量、最后消息的存储时间
this.indexHeader.incHashSlotCount();
this.indexHeader.incIndexCount();
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);
return true;
} catch (Exception e) {
log.error("putKey exception, Key: " + key + " KeyHashCode: " + key.hashCode(), e);
} finally {
if (fileLock != null) {
try {
fileLock.release();
} catch (IOException e) {
log.error("Failed to release the lock", e);
}
}
}
} else {
log.warn("Over index file capacity: index count = " + this.indexHeader.getIndexCount()
+ "; index max num = " + this.indexNum);
}
return false;
}
以上详细了分析了IndexFile条目存储的业务逻辑
2.3.3、通过KEY查找消息

DefaultMessageStore类中的
public QueryMessageResult queryMessage(String topic, String key, int maxNum, long begin, long end)
中其核心方法是
QueryOffsetResult queryOffsetResult = this.indexService.queryOffset(topic, key, maxNum, begin, lastQueryMsgTime);
获取消息的物理存储地址,通过偏移量去commitLog中获取消息集。
public QueryOffsetResult queryOffset(String topic, String key, int maxNum, long begin, long end)
核心方法又是IndexFile类中的
public void selectPhyOffset(final List<Long> phyOffsets, final String key, final int maxNum, final long begin, final long end, boolean lock)
方法
public void selectPhyOffset(final List<Long> phyOffsets, final String key, final int maxNum,
final long begin, final long end, boolean lock) {
if (this.mappedFile.hold()) {
//获取key的hash信息
int keyHash = indexKeyHashMethod(key);
//获取hash槽的下标
int slotPos = keyHash % this.hashSlotNum;
//获取hash槽的物理地址
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
FileLock fileLock = null;
try {
if (lock) {
// fileLock = this.fileChannel.lock(absSlotPos,
// hashSlotSize, true);
}
//获取hash槽的值
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
// if (fileLock != null) {
// fileLock.release();
// fileLock = null;
// }
//判断值是否小于等于0或者 大于当前索引文件的最大条目
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()
|| this.indexHeader.getIndexCount() <= 1) {
} else {
for (int nextIndexToRead = slotValue; ; ) {
if (phyOffsets.size() >= maxNum) {
break;
}
//计算条目的物理地址 = 索引头部大小(40字节) + hash槽的大小(4字节)*槽的数量(500w) + 当前索引最大条目的个数*每index的大小(20字节)
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ nextIndexToRead * indexSize;
//获取key的hash值
int keyHashRead = this.mappedByteBuffer.getInt(absIndexPos);
//获取消息的物理偏移量
long phyOffsetRead = this.mappedByteBuffer.getLong(absIndexPos + 4);
//获取当前消息的存储时间戳与index文件的时间戳差值
long timeDiff = (long) this.mappedByteBuffer.getInt(absIndexPos + 4 + 8);
//获取前一个条目的信息(链表结构)
int prevIndexRead = this.mappedByteBuffer.getInt(absIndexPos + 4 + 8 + 4);
if (timeDiff < 0) {
break;
}
timeDiff *= 1000L;
long timeRead = this.indexHeader.getBeginTimestamp() + timeDiff;
//判断该消息是否在查询的区间
boolean timeMatched = (timeRead >= begin) && (timeRead <= end);
//判断key的hash值是否相等并且在查询的时间区间内
if (keyHash == keyHashRead && timeMatched) {
//加入到物理偏移量的List中
phyOffsets.add(phyOffsetRead);
}
if (prevIndexRead <= invalidIndex
|| prevIndexRead > this.indexHeader.getIndexCount()
|| prevIndexRead == nextIndexToRead || timeRead < begin) {
break;
}
//继续前一个条目信息获取进行匹配
nextIndexToRead = prevIndexRead;
}
}
} catch (Exception e) {
log.error("selectPhyOffset exception ", e);
} finally {
if (fileLock != null) {
try {
fileLock.release();
} catch (IOException e) {
log.error("Failed to release the lock", e);
}
}
this.mappedFile.release();
}
}
}
1、根据查询的 key 的 hashcode%slotNum 得到具体的槽的位置( slotNum 是一个索引文件里面包含的最大槽的数目,例如图中所示 slotNum=5000000)。
2、根据 slotValue( slot 位置对应的值)查找到索引项列表的最后一项(倒序排列, slotValue 总是指向最新的一个 索引项)。
3、遍历索引项列表返回查询时间范围内的结果集(默认一次最大返回的 32 条记彔)
4、Hash 冲突;寻找 key 的 slot 位置时相当于执行了两次散列函数,一次 key 的 hash,一次 key 的 hash 值取模,因此返里存在两次冲突的情况;第一种, key 的 hash 不同但模数相同,此时查询的时候会在比较一次key 的hash 值(每个索引项保存了 key 的 hash 值),过滤掉 hash 值不相等的项。第二种, hash 值相等但 key 不等,出于性能的考虑冲突的检测放到客户端处理( key 的原始值是存储在消息文件中的,避免对数据文件的解析),客户端比较一次消息体的 key 是否相同
2.4、checkpoint
checkpoint文件的作用是记录commitlog、consumequeue、index文件的刷盘时间点,文件固定长度4k,其中只用了该文件的前24个字节。查看其存储格式

physicMsgTimestamp:commitlog文件刷盘时间点
logicsMsgTimestamp:消息的消费队列文件刷盘时间点
indexMsgTimestamp:索引文件刷盘时间点
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
RocketMQ 延时级别配置方式
RocketMQ 支持定时消息,但是不支持任意时间精度,仅支持特定的 level,例如定时 5s, 10s, 1m 等. 其中,level=0 级表示不延时,level=1 表示 1 级延时,level=2 表示 2 级延时,以此类推. 如何配置: 在服务器端(rocketmq-broker端)的属性配置文件中加入以下行: messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h 描述了各级别与延时时
-

基于RocketMQ推拉模式详解
消费者客户端有两种方式从消息中间件获取消息并消费.严格意义上来讲,RocketMQ并没有实现PUSH模式,而是对拉模式进行一层包装,名字虽然是 Push 开头,实际在实现时,使用 Pull 方式实现. 通过 Pull 不断轮询 Broker 获取消息.当不存在新消息时,Broker 会挂起请求,直到有新消息产生,取消挂起,返回新消息. 1.概述 1.1.PULL方式 由消费者客户端主动向消息中间件(MQ消息服务器代理)拉取消息:采用Pull方式,如何设置Pull消息的拉取频率需要重点去考虑,举个
-
RocketMQ-延迟消息的处理流程介绍
概述 RocketMQ 支持发送延迟消息,但不支持任意时间的延迟消息的设置,仅支持内置预设值的延迟时间间隔的延迟消息: 预设值的延迟时间间隔为: 1s. 5s. 10s. 30s. 1m. 2m. 3m. 4m. 5m. 6m. 7m. 8m. 9m. 10m. 20m. 30m. 1h. 2h: 在消息创建的时候,调用 setDelayTimeLevel(int level) 方法设置延迟时间: broker在接收到延迟消息的时候会把对应延迟级别的消息先存储到对应的延迟队列中,等延迟消息时间到
-
RocketMQ消息过滤与查询的实现
消息过滤 RocketMQ分布式消息队列的消息过滤方式有别于其它MQ中间件,是在Consumer端订阅消息时再做消息过滤的. RocketMQ这么做是还是在于其Producer端写入消息和Consomer端订阅消息采用分离存储的机制来实现的,Consumer端订阅消息是需要通过ConsumeQueue这个消息消费的逻辑队列拿到一个索引,然后再从CommitLog里面读取真正的消息实体内容,所以说到底也是还绕不开其存储结构. 其ConsumeQueue的存储结构如下,可以看到其中有8个字节存储的M
-
解决SpringBoot整合RocketMQ遇到的坑
应用场景 在实现RocketMQ消费时,一般会用到@RocketMQMessageListener注解定义Group.Topic以及selectorExpression(数据过滤.选择的规则)为了能支持动态筛选数据,一般都会使用表达式,然后通过apollo或者cloud config进行动态切换. 引入依赖 <!-- RocketMq Spring Boot Starter--> <dependency> <groupId>org.apache.rocketmq<
-
基于rocketmq的有序消费模式和并发消费模式的区别说明
rocketmq消费者注册监听有两种模式 有序消费MessageListenerOrderly和并发消费MessageListenerConcurrently,这两种模式返回值不同. MessageListenerOrderly 正确消费返回 ConsumeOrderlyStatus.SUCCESS 稍后消费返回 ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT MessageListenerConcurrently 正确消费返回 Consu
-
使用RocketMQTemplate发送带tags的消息
RocketMQTemplate发送带tags的消息 RocketMQTemplate是RocketMQ集成到Spring cloud之后提供的个方便发送消息的模板类,它是基本Spring 的消息机制实现的,对外只提供了Spring抽象出来的消息发送接口. 在单独使用RocketMQ的时候,发送消息使用的Message是'org.apache.rocketmq.common.message'包下面的Message,而使用RocketMQTemplate发送消息时,使用的Message是org.s
-
RocketMQTemplate 注入失败的解决
RocketMQTemplate 注入失败 在使用rocketmq 发送消息时,会发现 @Autowired private RocketMQTemplate rocketMQTemplate; 注入RocketMQTemplate 失败. 解决方案 究其原因是因为,配置文件中,我们没有添加 上图中蓝色的两行代码,指定发送的组名.写上后,问题解决. 好了,再来说说RocketMQTemplate 的基本使用吧~ RocketMQTemplate的使用 1.pom.xml依赖 <dependenc
-
RocketMQ存储文件的实现
RocketMQ存储路径默认是${ROCKRTMQ_HOME}/store,主要存储消息.主题对应的消息队列的索引等. 1.概述 查看其目录文件 commitlog:消息的存储目录 config:运行期间一些配置信息 consumequeue:消息消费队列存储目录 index:消息索引文件存储目录 abort:如果存在abort文件说明Broker非正常关闭,该文件默认启动时创建,正常退出时删除 checkpoint:文件检测点.存储commitlog文件最后一次刷盘时间戳.consumeque
-
使用Idea调试RocketMQ源码教程
目录 前言 下载源码 代码编译 运行namesrv 启动 启动broker 配置文件 启动broker 小结 前言 为了更好地了解RocketMQ,我打算看一看它的源码了.随着RocketMQ5.0版本的发布,应该有更多小伙伴在实际应用中选择RocketMQ.那么我们就从这一篇文章开始,逐步来了解RocketMQ的神秘源码吧!接下来我们先把调试环境搭建好. 下载源码 源码地址:github.com/apache/rock… 我们先把RocketMQ源码下载下来,为了方便一点,建议小伙伴先fork
-
PHP MongoDB GridFS 存储文件的方法详解
<?php //初始化gridfs $conn = new Mongo(); //连接MongoDB $db = $conn->photos; //选择数据库 $grid = $db->getGridFS(); //取得gridfs对象 gridfs有三种方式存储文件 第一种直接存储文件 $id = $grid->storeFile("./logo.png"); 第二种存储文件二进制流 $data = http://www.bkjia.com/PHPjc/get
-
PHP操作MongoDB GridFS 存储文件的详解
复制代码 代码如下: <?php //初始化gridfs $conn = new Mongo(); //连接MongoDB $db = $conn->photos; //选择数据库 $grid = $db->getGridFS(); //取得gridfs对象 //gridfs有三种方式存储文件 //第一种直接存储文件 $id = $grid->storeFile("./logo.png"); //第二种存储文件二进制流 $data = get_file_cont
-
浅谈Springboot整合RocketMQ使用心得
一.阿里云官网---帮助文档 https://help.aliyun.com/document_detail/29536.html?spm=5176.doc29535.6.555.WWTIUh 按照官网步骤,创建Topic.申请发布(生产者).申请订阅(消费者) 二.代码 1.配置: public class MqConfig { /** * 启动测试之前请替换如下 XXX 为您的配置 */ public static final String PUBLIC_TOPIC = "test"
-
java RocketMQ快速入门基础知识
如何使用 1.引入 rocketmq-client <dependency> <groupId>org.apache.rocketmq</groupId> <artifactId>rocketmq-client</artifactId> <version>4.1.0-incubating</version> </dependency> 2.编写Producer DefaultMQProducer produce
-
Docker中RocketMQ的安装与使用详解
搜索RocketMQ的镜像,可以通过docker的hub.docker.com上进行搜索,也可以在Linux下通过docker的search命令进行搜索,不过最近防火墙升级后,导致国外的网站打开都很慢,通过命令搜索反而会更加方便,操作Docker命令一定要是root用户或者具有root权限的用户.查询操作如下: docker search rocketmq 可以得到如下的结果: 镜像倒是蛮多的,不过看来看去没有一个是官方发布的,我就随便选一个吧,如foxiswho/rocketmq,以下是一个查
-
Window搭建部署RocketMQ步骤详解
序 以前简单用过ActiveMQ但是公司项目上使用的是RocketMQ,所以准备多花点时间在这上面,搞懂项目的配置使用. 看了很多资料,先说说我自己对RocketMQ的简单理解.不管是我们写的消费者还是生产者都属于客户端,而我们需要安装RocketMQ,这是属于服务端.和ActivieMQ.zookeeper类似,消费者.生成者.服务端(NameServer)之间是采取观察者模式实现. 在操作系统上安装RocketMQ,启动服务端NameServer.启动Broker,书写Consumer代码,
-
使用Kotlin+RocketMQ实现延时消息的示例代码
一. 延时消息 延时消息是指消息被发送以后,并不想让消费者立即拿到消息,而是等待指定时间后,消费者才拿到这个消息进行消费. 使用延时消息的典型场景,例如: 在电商系统中,用户下完订单30分钟内没支付,则订单可能会被取消. 在电商系统中,用户七天内没有评价商品,则默认好评. 这些场景对应的解决方案,包括: 轮询遍历数据库记录 JDK 的 DelayQueue ScheduledExecutorService 基于 Quartz 的定时任务 基于 Redis 的 zset 实现延时队列. 除此之外,
-
Java RocketMQ 路由注册与删除的实现
简介 RocketMQ路由注册与删除是通过Broker与NameServer的心跳功能实现的.Broker启动时向集群中所有的NameServer发送心跳语句,每隔30s向集群中所有NameServer发送心跳包,NameServer收到Broker心跳包时会更新brokerLiveTable中的lastUpdateTimestamp,然后NameServer每隔10s扫描brokerLiveTable,如果连续120s没有收到心跳包,NameServer将移除该Broker的路由信息. 路由信