python利用有道翻译实现"语言翻译器"的功能实例
实例如下:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入需要翻译的内容(退出输入Q):')
if content == 'Q':
break
else:
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=http://www.youdao.com/'
data = {}
data['type'] = 'AUTO'
data['i'] = content
data['doctype'] = 'json'
data['xmlVersion'] = '1.8'
data['keyfrom'] = 'fanyi.web'
data['ue'] = 'UTF-8'
data['action'] = 'FY_BY_CLICKBUTTON'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
response = urllib.request.urlopen(url, data)
html = response.read().decode('utf-8')
target = json.loads(html)
print('翻译的结果:%s' % target['translateResult'][0][0]['tgt'])
程序执行情况:
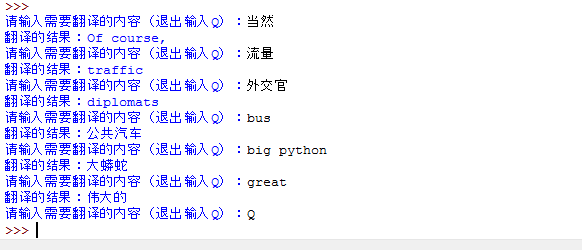
这里要注意的是两个函数urllib.request.urlopen()与urllib.parse.urlencode()。
urllib.request.urlopen()其实不止一个参数,有好几个哦,其中第二个是data,data应该是一个buffer的标准应用程序/ x-www-form-urlencoded格式(python标准库原文:data should be a buffer in the standard application/x-www-form-urlencoded format)。urllib.parse.urlencode()函数接受一个映射或序列集合,并返回一个字符串的格式(python标准库原文:The urllib.parse.urlencode() function takes a mapping or sequence of 2-tuples and returns a string in this format)。我们可以看看urllib.parse.urlencode()的结果是什么样的:
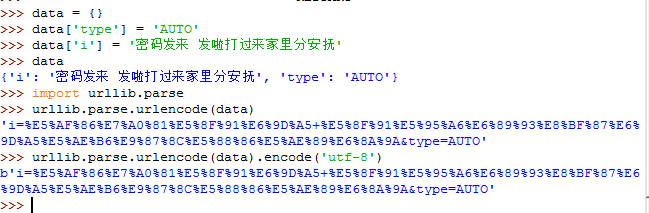
上图的结果刚好与urllib.request.urlopen()的data参数的数据类型要求一致了。
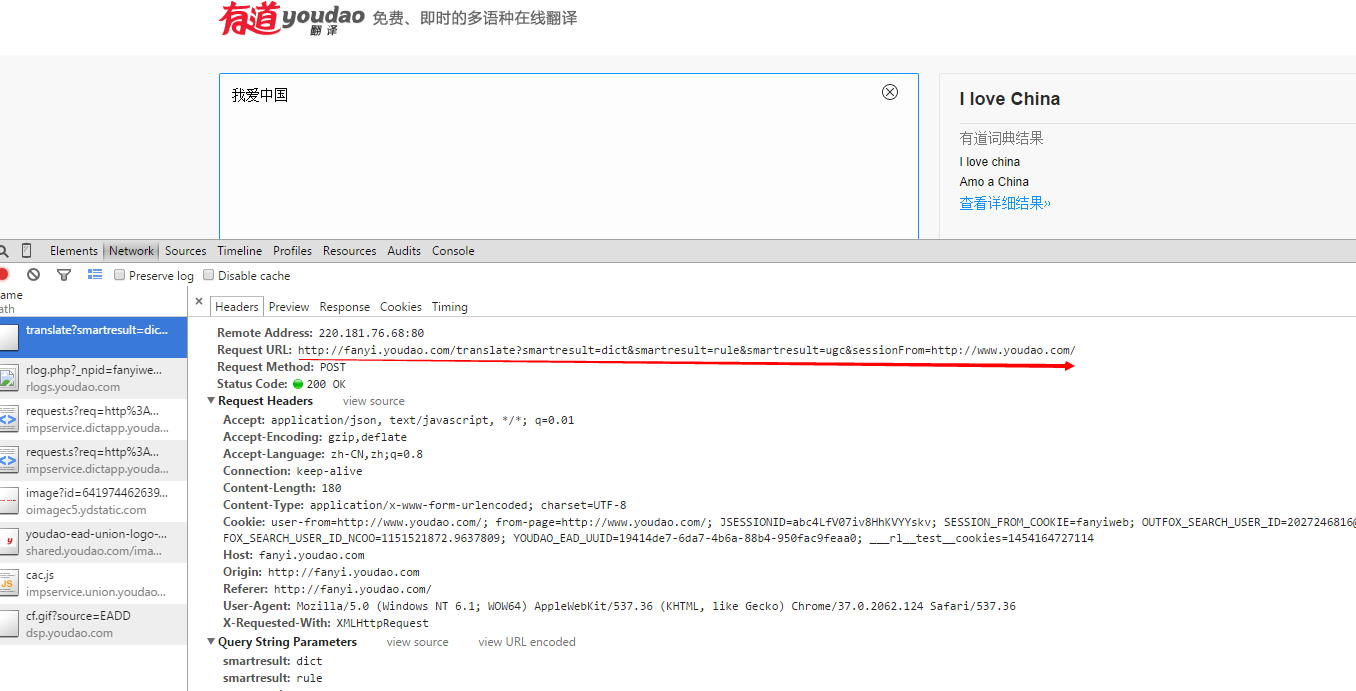
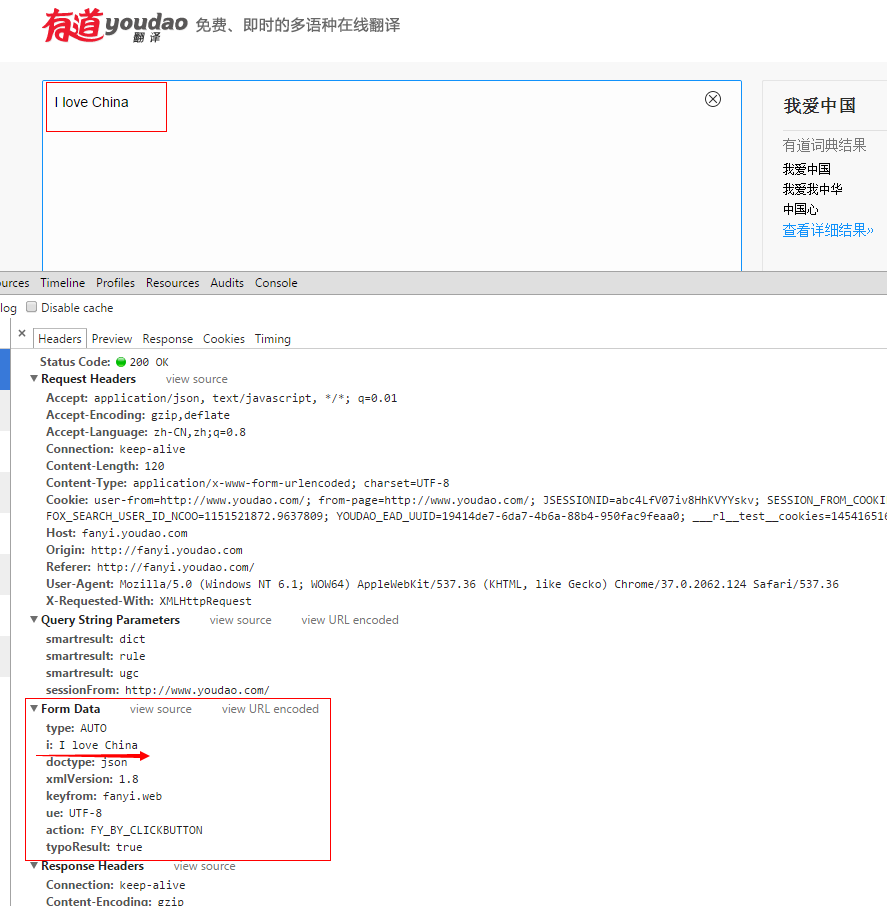
注意,上面urlopen当中的url,这个是分析有道翻译页面的真实的Request URL:
以上这篇python利用有道翻译实现"语言翻译器"的功能实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
cmd下在win上做vpn的命令分享
CMD下建立VPN 1.前提 服务里 windows防火墙停止(或者麻烦点可以把router协议,端口1723配进去) 远程注册表服务必须开启 server服务必须开启 router路由服务必须开启 两块以上网卡的win2000做vpn很方便,添加nat协议后,客户端拨入,能够使用远程网络连接internet. 使得部分客户端可提高网络速度,并达到代理的作用. 一块网卡的winxp,win2003做类似的vpn仍然很方便,nat协议添加后,再添加两个接口,一个是本地连接,一个是内部,设置本地连接
-
使用Python从有道词典网页获取单词翻译
从有道词典网页获取某单词的中文解释. import re import urllib word=raw_input('input a word\n') url='http://dict.youdao.com/search?q=%s'%word content=urllib.urlopen(url) pattern=re.compile("</h2.*?</ul>",re.DOTALL) result=pattern.search(content.read()).gro
-
Python 实现的 Google 批量翻译功能
首先声明,没有什么不良动机,因为经常会用 translate.google.cn,就想着用 Python 模拟网页提交实现文档的批量翻译.据说有 API,可是要收费. 生成 Token Google 为防爬虫而生成 token 的代码是 Javascript 的,且是根据网站的 TKK 值和提交的文本动态生成.更新规律未知,只好定时去取一下了. 网上能找到的 Python 代码大部分是去调用 PyExecJS 库,先不说执行效率的高低(大概是差一个数量级),首先是舍近求远,不纯粹,本人不喜欢.
-
python自动翻译实现方法
本文实例讲述了python自动翻译实现方法.分享给大家供大家参考,具体如下: 以前学过python的基础,一般也没用过.后来有一个参数表需要中英文.想了一下,还是用python做吧.调用的百度翻译接口,经历了乱码.模块不全等问题.一般google,一边做的.分享一下. #encoding=utf-8 ## eagle_91@sina.com ## created 2014-07-22 import urllib import urllib2 import MySQLdb import json
-
python翻译软件实现代码(使用google api完成)
复制代码 代码如下: # -*- coding: utf-8 -*- import httplibfrom urllib import urlencodeimport re def out(text): p = re.compile(r'","') m = p.split(text) print m[0][4:].decode('UTF-8').encode('GBK') if __name__=='__main__': while True: w
-
python使用百度翻译进行中翻英示例
利用百度词典进行中翻英 复制代码 代码如下: import urllib2import reimport sys reload(sys)sys.setdefaultencoding('utf-8')def tran(word): url='http://dict.baidu.com/s?wd={0}&tn=dict'.format(word) print url req=urllib2.Request(url) resp=urllib2.urlopen(req) r
-
python实现在线翻译功能
对于需要大量翻译的数据,人工翻译太慢,此时需要使用软件进行批量翻译. 1.使用360的翻译 def fanyi_word_cn(string): url="https://fanyi.so.com/index/search" #db_path = './db/tasks.db' Form_Data= {} #这里输入要翻译的英文 Form_Data['query']= string Form_Data['eng']= '1' #用urlencode把字典变成字符串,#服务器不接受字典,
-

Python使用tkinter制作在线翻译软件
tkinter的功能是如此强大,竟然还能做翻译软件.当然是在线的,我发现有一个quicktranslate模块,可以提供在线翻译功能,相当于提供了一个翻译的接口,利用它就可以制作在线翻译软件了.下面是代码,分享给大家. 注意要首先 pip install quicktranslate #-*- coding:utf-8 -*- import tkinter as tk #使用Tkinter前需要先导入 from tkinter import messagebox,ttk import datet
-
用python实现百度翻译的示例代码
用python实现百度翻译,分享给大家,具体如下: 首先,需要简单的了解一下爬虫,尽可能简单快速的上手,其次,需要了解的是百度的API的接口,搞定这个之后,最后,按照官方给出的demo,然后写自己的一个小程序 打开浏览器 F12 打开百度翻译网页源代码: 我们可以轻松的找到百度翻译的请求接口为:http://fanyi.baidu.com/sug 然后我们可以从方法为POST的请求中找到参数为:kw:job(job是输入翻译的内容) 下面是代码部分: from urllib import req
-
基于python实现百度翻译功能
运行环境: python 3.6.0 今天处于练习的目的,就用 python 写了一个百度翻译,是如何做到的呢,其实呢就是拿到接口,通过这个接口去访问,不过中间确实是出现了点问题,不过都解决掉了 先晾图后晾代码 运行结果: 代码: # -*- coding: utf-8 -*- """ 功能:百度翻译 注意事项:中英文自动切换 """ import requests import re class Baidu_Translate(object):