解决Python字典查找报Keyerror的问题
Python的字典一般都直接查找key ,比如
dict={'a':1,'b':2,'c':3}
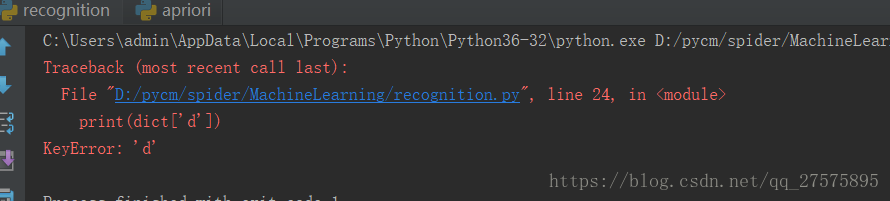
print(dict['a'])
但是如果在查找的key不存在的时候就会报:KeyError:
比如你要查看print(dict['d'])
由于这个时候dict里面并没有这个key ,所以就会直接报错,那么这个时候其实python给我们提供了一种很棒的解决方法,那就是用
setdefault,用法如下: dict.setdefault(key,[这里设置如果不存在想将值设置为啥,默认为None])
那么这里我们可以用此方法解决:
print(dict.setdefault('d',0))
然后就没有问题啦,注意下就是setdefault是如果要想往dict中添加新值的时候就使用此函数,如果只是单纯想要做查找,碰到key不存在或者希望在通过这个键读取值的时候能得到一个默认值,那么建议用defaultdict
首先先介绍下这个所谓的defaultdict,来自于collections模块,collections是个集合模块,defaultdict(function_factory)构建的是一个类似dictionary的对象,其中key的值,自行确定赋值,但是value的类型是function_factory的类实例,而且具有默认值.这里还引入了一个概念就是工厂函数,python的工厂函数就是指那些内建函数都是类对象,当你调用他们时,实际上是创建了一个类实例。
比如int(),str(),set()等,这里我们看下例子:
import collections
s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]
d = collections.defaultdict(list)
for k, v in s:
d[k].append(v)
print(d['yellow'])
print(d['white'])
print(list(d.items()))
我们最后得到的输出结果如下:
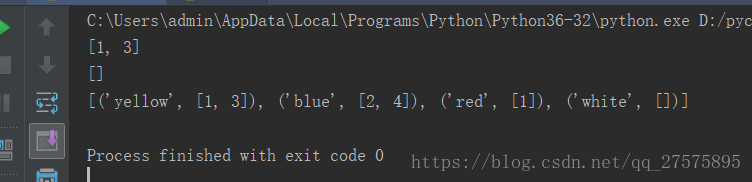
我们可以看到,当d中没有对应的key时最后返回的是个空列表,那是因为我们在设置defaultdict的时候用的工厂函数是list,而list的默认值是空列表,下面我们在看下如果工厂函数是set()会是什么样子
import collections
s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]
d = collections.defaultdict(set)
for k, v in s:
d[k].add(v)
print(d['yellow'])
print(d['white'])
print(list(d.items()))
结果输出如下:
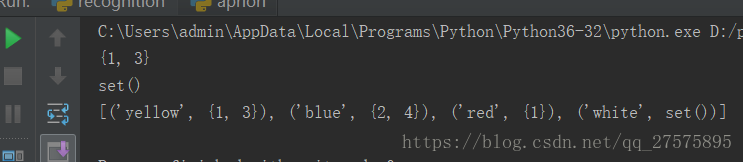
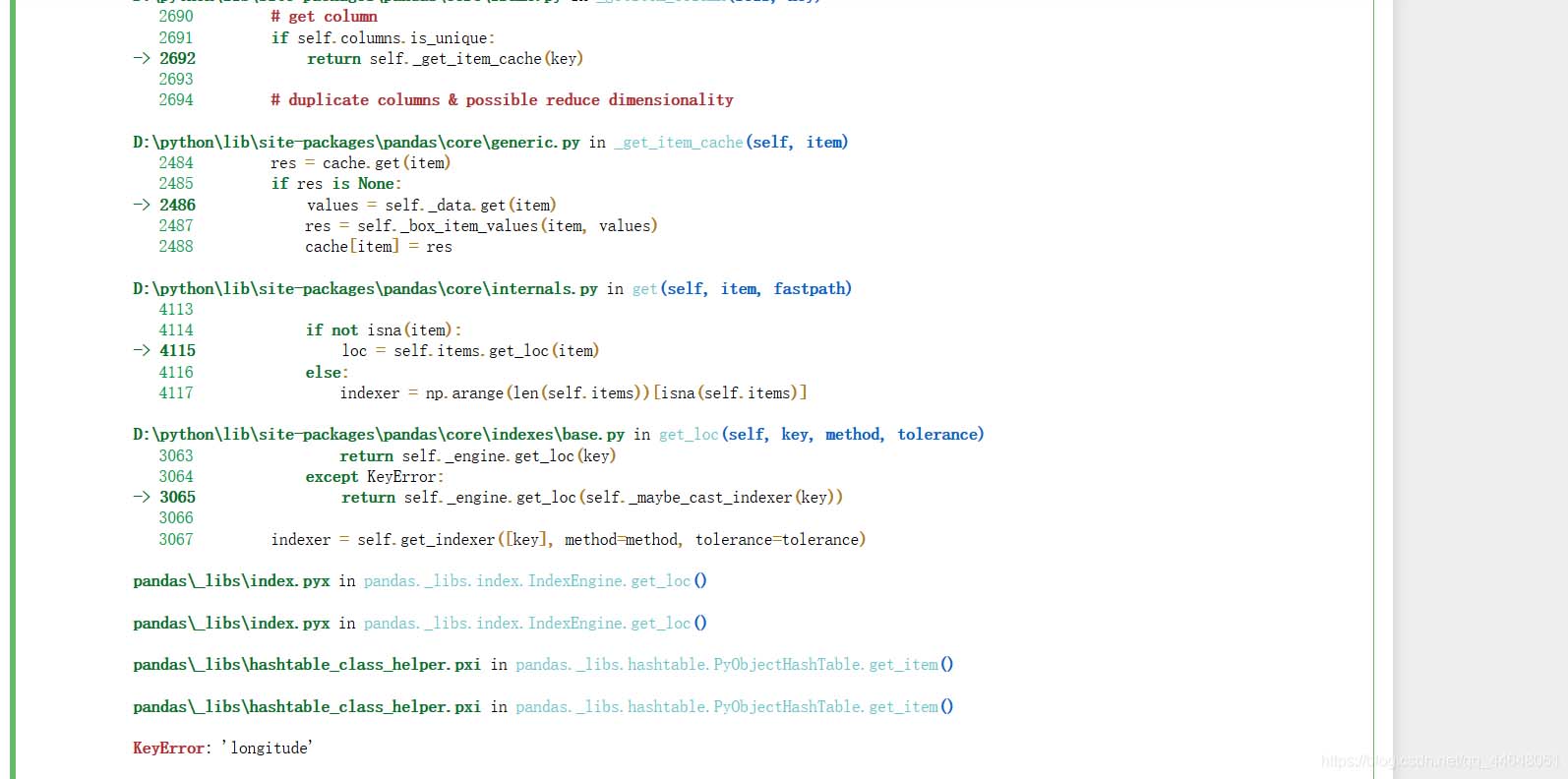
补充:python报错出现 KeyError: 'longitude'
python报错出现 KeyError: ‘longitude'
报错界面如下图所示:
我在网上寻找了方法,确实找到一个解决方案:对你可能有用的解决方案一
但是我试了还是没用,于是,当我定睛一看,发现竟又是由于俺的粗心造成的。啊,如下图,按在longitude前面少了个逗号,
如下图:
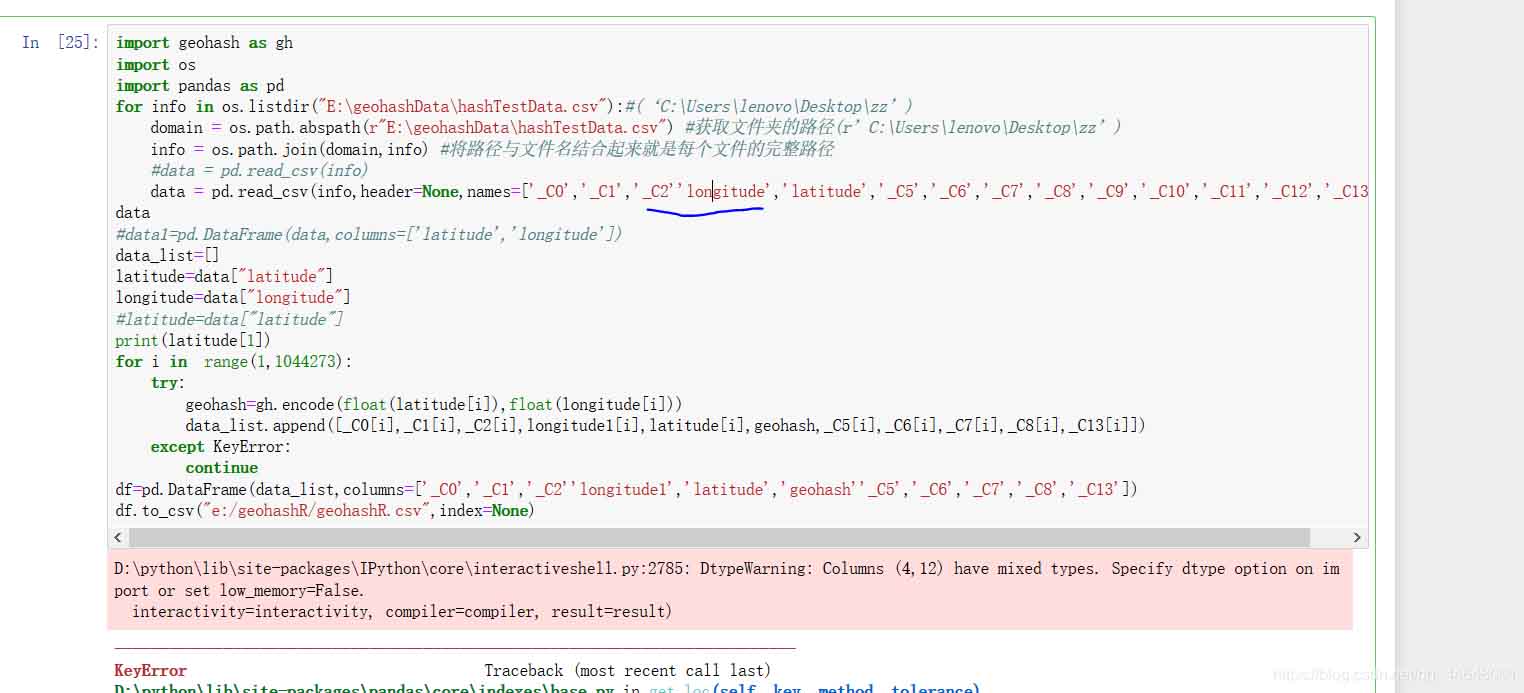
所以这个问题就解决啦,好,我继续我的课程设计了。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python操作dict时避免出现KeyError的几种解决方法
在读取dict的key和value时,如果key不存在,就会触发KeyError错误,如: t = { 'a': '1', 'b': '2', 'c': '3', } print(t['d']) 就会出现: KeyError: 'd' 第一种解决方法 首先测试key是否存在,然后才进行下一步操作,如: t = { 'a': '1', 'b': '2', 'c': '3', } if 'd' in t: print(t['d']) else: print('not exist') 会出现: not
-
python Manager 之dict KeyError问题的解决
程序需要多进程见共享内存,使用了Manager的dict. 最初代码如下: from multiprocessing import Process, Manager d = Manager().dict() d2 = {} def f(): d['a1'] = {} <span style="color:#ff6666;"> d['a1']['a2'] = 11</span> print d['a1']['a2'] if __name__ == '__main_
-
新手常见6种的python报错及解决方法
此篇文章整理新手编写代码常见的一些错误,有些错误是粗心的错误,但对于新手而已,会折腾很长时间才搞定,所以在此总结下我遇到的一些问题.希望帮助到刚入门的朋友们. 1.NameError变量名错误 报错: >>> print a Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'a' is not defined 解决方案:
-

Python基础中所出现的异常报错总结
今天我们来探索python中大部分的异常报错 首先异常是什么,异常白话解释就是不正常,程序里面一般是指程序员输入的格式不规范,或者需求的参数类型不对应,不全等等. 打个比方很多公司年终送苹果笔记本,你程序话思维以为是(MAC)电脑笔记本,结果给你个苹果+笔记本...首先类型不对,数量也不对. 先来看几个常见的报错如下: NameError 命名错误 原因是: name 'a' is not defined 命名a还未定义 简单来说就是程序不知道a带表谁 如果a=1 那程序就懂了 a代表1 所以
-
解决Python字典查找报Keyerror的问题
Python的字典一般都直接查找key ,比如 dict={'a':1,'b':2,'c':3} print(dict['a']) 但是如果在查找的key不存在的时候就会报:KeyError: 比如你要查看print(dict['d']) 由于这个时候dict里面并没有这个key ,所以就会直接报错,那么这个时候其实python给我们提供了一种很棒的解决方法,那就是用 setdefault,用法如下: dict.setdefault(key,[这里设置如果不存在想将值设置为啥,默认为None])
-
解决Python字典写入文件出行首行有空格的问题
模拟购物车程序,判断用户薪资是否是0 如果是0就需要输入薪资,并记录到文件内. 可以预先存个字典格式的字符串,然后去读取文件的时候读到的是字字符串然后再去用eval去转换成字典. 当我们覆盖写到文件的时候就会发现首行会有空格,当我们再去读取eval的时候就会报错,那怎么样可以解决这个问题呢! import json info = { 'lisi':0, 'zhangshan':100, } f = open('json.txt','w') f.write(json.dumps(info)) {"
-
Python字典查找数据的5个基础操作方法
目录 前言 一.key值查找 二.函数查找 2.1 get() 2.2 keys() 2.3 values() 2.4 items() 附:字典的常用方法 总结 前言 上一篇文章写了关于字典操作方法的增删改,这篇主要讲解如何查找字典数据.查找数据写法一共有两种,一种能够是key值查找,另外一种是按照函数的写法进行数据查找. 一.key值查找 如果当前查找的key存在,则返回对应的值,否则则报错. 代码示例: dict1 = {'name': 'Rose', 'age': 30, 'sex': '
-
解决python字典对值(值为列表)赋值出现重复的问题
可能很少有人遇到这个问题,网上也没找到,这里记录一下,希望也可以帮到其他人. 问题描述:假设有一个字典data,其键不定,可能随时添加键(这不是关键),某一个键下面对应的值为一个长度为10的list,初始化为0,然后我想修改某些键下面的列表中的某一个值,比如data有一个键'k',对应的值为[0,0,0,0,0,0,0,0,0,0],现在我想把键'k'对应的列表的第三个数改成3,即[0,0,3,0,0,0,0,0,0,0],可是意外的事情发生了,如果data还有一个键'k1',假设其值为[0,0
-
解决python运行启动报错问题
问题一: python启动报错api-ms-win-crt-process-l1-1-0.dll 丢失 解决: 下载api-ms-win-crt-process-l1-1-0.dll文件丢到C:\Windows\SysWOW64(64位操作系统).C:\Windows\System32(32位操作系统)目录下 问题二: python运行时错误代码(0xc000007b) 解决: 下载directxrepair工具修复系统文件,修复成功后手动重启电脑 补充知识:Python3开启自带http服务
-
解决Python安装cryptography报错问题
错误一: gcc -pthread -fno-strict-aliasing -DNDEBUG -g -fwrapv -O2 -Wall -Wstrict-prototypes -fPIC -DUSE__THREAD -DHAVE_SYNC_SYNCHRONIZE -I/usr/include/ffi -I/usr/include/libffi -I/usr/include/python2.7 -c c/_cffi_backend.c -o build/temp.linux-x86_64-2.7
-
解决Python 写文件报错TypeError的问题
处理上传的文件: f1 = request.FILES['pic'] fname = '%s/%s' % (settings.MEDIA_ROOT, f1.name) with open(fname, 'w') as pic: for c in f1.chunks(): pic.write(c) 测试报错: TypeError at /upload/ write() argument must be str, not bytes 把之前的打开语句修改为用二进制方式打开: f1 = request
-
详解Python字典查找性能
目录 timeit.repeat 字典获取性能 数据准备 复杂获取 总结 timeit.repeat timeit.repeat默认会执行3轮,每轮执行1000000次.返回每轮的总执行时间列表 字典获取性能 大家都知道字典获取分为 中括号获取,获取不到会抛出KeyError get获取,获取不到会返回默认值 下面比较两种获取方式的性能 数据准备 一条简单一条复杂 # logging标准库的level字典 level_mapping = {'CRITICAL': 50, 'FATAL': 50,
-
一文带你解决Python中的所有报错
目录 前言 Python安装 HTTPSConnectionPool(host=‘files.pythonhosted.org‘, port=443): Read timed out解决 xlrd.biffh.XLRDError: Excel xlsx file; not supported解决 Fatal error in launcher: Unable to create process using解决 报错Non-zero exit code (2)解决 [notice] A new r
-
解决Python 遍历字典时删除元素报异常的问题
错误的代码① d = {'a':1, 'b':0, 'c':1, 'd':0} for key, val in d.items(): del(d[k]) 错误的代码② -- 对于Python3 d = {'a':1, 'b':0, 'c':1, 'd':0} for key, val in d.keys(): del(d[k]) 正确的代码 d = {'a':1, 'b':0, 'c':1, 'd':0} keys = list(d.keys()) for key, val in keys: d