解决spring data jpa saveAll() 保存过慢问题
目录
- spring data jpa saveAll() 保存过慢
- 问题发现
- 解决方案1 此方案在第二天失效了
- 以上方案有问题,下面附上彻底解决的截图和记录
- JPA的saveAll方法执行效率很差
spring data jpa saveAll() 保存过慢
问题发现
今天在生产环境执行保存数据时 影响队列中其他程序的运行 随后加日志排查 发现 执行 4500条 insert操作时 耗时 9分钟 我类个去…
解决方案1 此方案在第二天失效了
废话不多说 直接上配置文件参数
application-prod.yml 部分参数如下
jpa:
show-sql: false
hibernate:
ddl-auto: none
properties:
hibernate:
jdbc:
#为spring data jpa saveAll方法提供批量插入操作 此处可以随时更改大小 建议500哦
batch_size: 500
batch_versioned_data: true
order_inserts: true
通过日志打印 执行结果如下
未开批处理 4507条 耗时: 227167ms
开启批处理 500/次 4507条 耗时: 29140ms
开启批处理 1000/次 4507条 耗时: 29631ms
以上方案有问题,下面附上彻底解决的截图和记录
后来发现在生产运行了一天 还是会导致保存阻塞的问题 100条保存耗时 9分钟!!!
数据库此时数据有300w条
于是分析 saveAll()的源代码
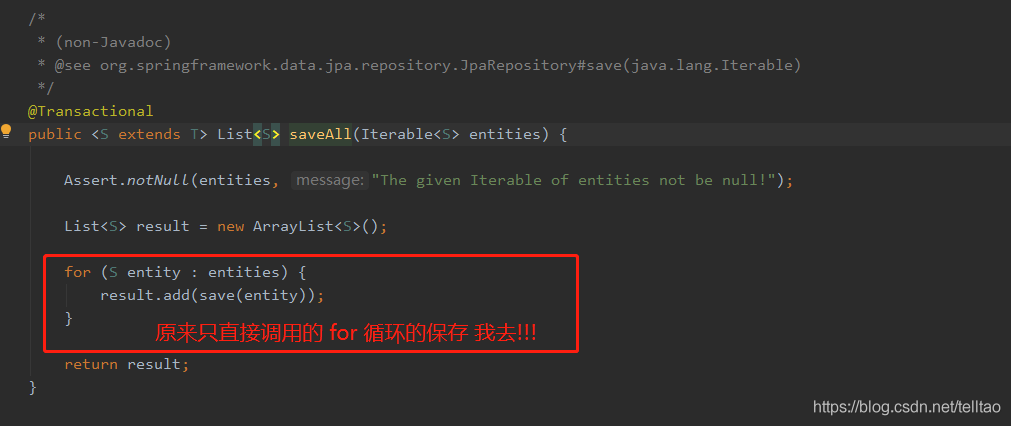
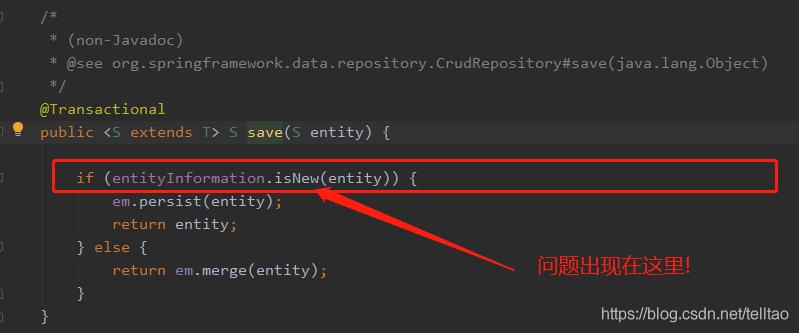
原来这个保存的时候 会去数据库查询这条数据是否存在 如果存在 则修改 不存在则直接添加 如下图
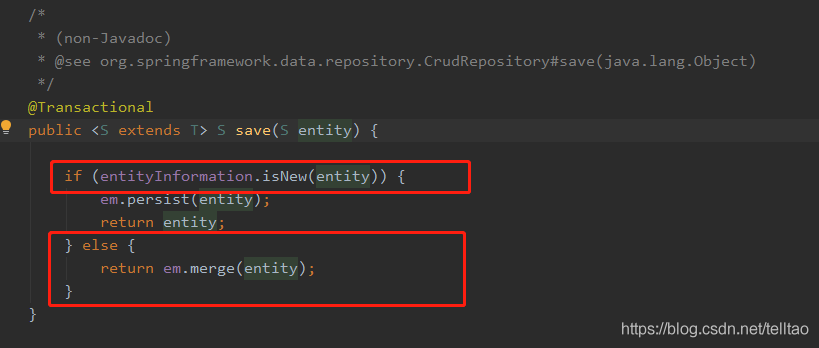
重写 saveAll() 的方法 就是仿照它 for循环里面直接调用 save()方法
@PersistenceContext() protected EntityManager em;

此处你们可以改成泛型的方式,提取公共类,封装一下即可。
JPA的saveAll方法执行效率很差
springboot项目中使用了SpringDataJpa的技术,很方便,省了很多dao层繁琐的步骤,但是有一个接口需要批量更新或者插入,数据量挺大,大概1-2w条,每条记录20-30个字段吧,对于刚工作不久的我还是比较大的。我开始使用的saveAll(),因为本地单元测试,也没考虑那么多(其实更早期更蠢,遍历再save,压根不去考虑数据库连接池的压力或者说每次遍历都要去连接数据库的时间损耗…),但是客户压力测试,我的接口就拉胯了。接口等待时间太久…诶
刚开始的思路想解决saveAll方法为什么这么慢的问题,因为saveAll是有则更新,无则新增,所以每条记录都要去比对该记录是否存在表中,效率比较差(我以后还是用JPA去适应数据量较小的吧,jpa可能还有什么别的路子后面可以配置进去也行)。
最后改用了mybatis的foreach方式,虽然比较老套而且肯定不是最快的办法,但是还是实用。
使用过程中,出现了这个报错:
Packet for query is too large (3227 > 1024). You can change this value on the server by setting the max_allowed_packet' variable.
应该是一下子丢进来的数据太大,超过了mysql的限制,有人说通过修改数据库的max_allowed_packet这个属性来修改,不过我这里是jenkins部署的服务器,能操作到数据库的只有navicat这个可视化工具,如果使用命令行修改这个属性,好像只能暂时起效。我只好类似分页,把18000条数据按照2000一次批量操作,分成9次,这样既不会报错,也会比savelAll快一些。后续再研究一下更快更高效的方法。
数据库配置加上allowMultiQueries=true才会支持foreach循环操作。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
使用Spring Data JPA的坑点记录总结
前言 Spring-data-jpa的基本介绍:JPA诞生的缘由是为了整合第三方ORM框架,建立一种标准的方式,百度百科说是JDK为了实现ORM的天下归一,目前也是在按照这个方向发展,但是还没能完全实现.在ORM框架中,Hibernate是一支很大的部队,使用很广泛,也很方便,能力也很强,同时Hibernate也是和JPA整合的比较良好,我们可以认为JPA是标准,事实上也是,JPA几乎都是接口,实现都是Hibernate在做,宏观上面看,在JPA的统一之下Hibernate很良好的运行. 最近在
-

详解SpringBoot实现JPA的save方法不更新null属性
序言:直接调用原生Save方法会导致null属性覆盖到数据库,使用起来十分不方便.本文提供便捷方法解决此问题. 核心思路 如果现在保存某User对象,首先根据主键查询这个User的最新对象,然后将此User对象的非空属性覆盖到最新对象. 核心代码 直接修改通用JpaRepository的实现类,然后在启动类标记此实现类即可. 一.通用CRUD实现类 public class SimpleJpaRepositoryImpl<T, ID> extends SimpleJpaRepository&l
-
解决spring data jpa 批量保存更新的问题
spring data jpa 批量保存更新问题 使用jpa批量保存时,看日志发现是一条一条打印的,然后去看了下源码,果然是循环调用的单个保存(巨坑啊) 经查询jpa是可以实现批量保存更新的,具体设置如下: spring.jpa.properties.hibernate.jdbc.batch_size=500 spring.jpa.properties.hibernate.jdbc.batch_versioned_data=true spring.jpa.properties.hibernate
-
解决spring data jpa saveAll() 保存过慢问题
目录 spring data jpa saveAll() 保存过慢 问题发现 解决方案1 此方案在第二天失效了 以上方案有问题,下面附上彻底解决的截图和记录 JPA的saveAll方法执行效率很差 spring data jpa saveAll() 保存过慢 问题发现 今天在生产环境执行保存数据时 影响队列中其他程序的运行 随后加日志排查 发现 执行 4500条 insert操作时 耗时 9分钟 我类个去- 解决方案1 此方案在第二天失效了 废话不多说 直接上配置文件参数 application
-
解决Spring Data Jpa 实体类自动创建数据库表失败问题
目录 Spring Data Jpa 实体类自动创建数据库表失败 找了半天发现是一个配置的问题 可能导致JPA 无法自动建表的问题汇总 1.没加@Entity或引错Entity所在包 2.jpa配置中ddl-auto未设置update 3.实体类的包不是启动程序所在包的子包 4.mysql配置问题 5.依赖不全 6.实体类间关系错误 7.启动类注解问题 8.其他问题 Spring Data Jpa 实体类自动创建数据库表失败 先说一下我遇到的这个问题,首先我是通过maven创建了一个spring
-
Spring data jpa @Query update的坑及解决
目录 Springdatajpa@Queryupdate的坑 可以参考这个例子 Springdatajpa的update操作 1.调用保存实体的方法 2.@Query注解,自己写JPQL语句 Spring data jpa @Query update的坑 jpa默认只有save(Entity)方法,如果数据库中没有记录就新增,如果数据库中有记录就更新记录. 如果要手动添加update(Entity)方法, 可以参考这个例子 @Modifying @Query(value = "UPDATE
-
spring data jpa @Query注解中delete语句报错的解决
目录 spring data jpa @Query注解中delete语句报错 项目中需要删除掉表中的一些数据 JPA使用@Query注解实例 1. 一个使用@Query注解的简单例子 2. Like表达式 3. 使用Native SQL Query 4. 使用@Param注解注入参数 5. SPEL表达式(使用时请参考最后的补充说明) 6. 一个较完整的例子 7. S模糊查询注意问题 8. 解释例6中错误的原因 spring data jpa @Query注解中delete语句报错 项目中需要删
-
Springboot使用Spring Data JPA实现数据库操作
SpringBoot整合JPA 使用数据库是开发基本应用的基础,借助于开发框架,我们已经不用编写原始的访问数据库的代码,也不用调用JDBC(Java Data Base Connectivity)或者连接池等诸如此类的被称作底层的代码,我们将从更高的层次上访问数据库,这在Springboot中更是如此,本章我们将详细介绍在Springboot中使用 Spring Data JPA 来实现对数据库的操作. JPA & Spring Data JPA JPA是Java Persistence API
-
Spring Data JPA使用JPQL与原生SQL进行查询的操作
1.使用JPQL语句进行查询 JPQL语言(Java Persistence Query Language)是一种和SQL非常类似的中间性和对象化查询语言,它最终会被编译成针对不同底层数据库的SQL语言,从而屏蔽不同数据库的差异. JPQL语言通过Query接口封装执行,Query 接口封装了执行数据库查询的相关方法.调用 EntityManager 的 Query.NamedQuery 及 NativeQuery 方法可以获得查询对象,进而可调用Query接口的相关方法来执行查询操作. JPQ
-
聊聊Spring data jpa @query使用原生SQl,需要注意的坑
目录 Spring data jpa @Query 使用原生Sql的坑 根据代码来解说: 需要注意的方法有以下几点 SpringData JPA @Query动态SQL语句 思路 实现 Spring data jpa @Query 使用原生Sql的坑 根据代码来解说: @Query(value = "select bill.id_ as id, bill.created_date as date, bill.no, lawyer_case .case_no as caseNo, " +
-
详谈hibernate,jpa与spring data jpa三者之间的关系
目录 前提 文字说明 CRUD操作 前提 其实很多框架都是对另一个框架的封装,我们在学习类似的框架的时候,难免会进入误区,所以我们就应该对其进行总结归纳,对比.本文就是对hibernate,jpa,spring data jpa三者之间进行文字对比,以及对其三者分别进行CRUD操作. 文字说明 Hibernate Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生
-
springboot+spring data jpa实现新增及批量新增方式
目录 springboot+spring data jpa实现新增及批量新增 springdatajpa 新增操作注意 springboot+spring data jpa实现新增及批量新增 spring data jpa (以下简称jpa).这个orm其实和mybatis还是差不多的.但是相对于mybatis来说,省去很多方法,毕竟jpa来说,官方文档给的说法是编写者只需要书写接口.剩下的事就交由jpa来完成.当时,洒家还是不信的.当你用过一次后,你就会发现.真的是这样.只能用两个字来形容,即