详解基于Scrapy的IP代理池搭建
一、为什么要搭建爬虫代理池
在众多的网站防爬措施中,有一种是根据ip的访问频率进行限制,即在某一时间段内,当某个ip的访问次数达到一定的阀值时,该ip就会被拉黑、在一段时间内禁止访问。
应对的方法有两种:
1. 降低爬虫的爬取频率,避免IP被限制访问,缺点显而易见:会大大降低爬取的效率。
2. 搭建一个IP代理池,使用不同的IP轮流进行爬取。
二、搭建思路
1、从代理网站(如:西刺代理、快代理、云代理、无忧代理)爬取代理IP;
2、验证代理IP的可用性(使用代理IP去请求指定URL,根据响应验证代理IP是否生效);
3、将可用的代理IP保存到数据库;
在《Python爬虫代理池搭建》一文中我们已经使用Python的 requests 模块简单实现了一个IP代理池搭建,但是爬取速度较慢。由于西刺代理、快代理和云代理等网站需要爬取的IP代理列表页多达上千页,使用此种方法来爬取其实并不适合。
本文将以快代理网站的IP代理爬取为例,示例如何使用 Scrapy-Redis 来爬取代理IP。
三、搭建代理池
scrapy 项目的目录结构如下:
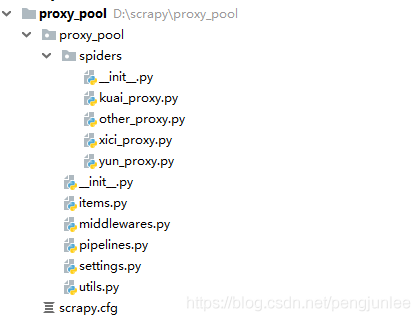
items.py
# -*- coding: utf-8 -*-
import re
import scrapy
from proxy_pool.settings import PROXY_URL_FORMATTER
schema_pattern = re.compile(r'http|https$', re.I)
ip_pattern = re.compile(r'^([0-9]{1,3}.){3}[0-9]{1,3}$', re.I)
port_pattern = re.compile(r'^[0-9]{2,5}$', re.I)
class ProxyPoolItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
'''
{
"schema": "http", # 代理的类型
"ip": "127.0.0.1", # 代理的IP地址
"port": "8050", # 代理的端口号
"original":"西刺代理",
"used_total": 11, # 代理的使用次数
"success_times": 5, # 代理请求成功的次数
"continuous_failed": 3, # 使用代理发送请求,连续失败的次数
"created_time": "2018-05-02" # 代理的爬取时间
}
'''
schema = scrapy.Field()
ip = scrapy.Field()
port = scrapy.Field()
original = scrapy.Field()
used_total = scrapy.Field()
success_times = scrapy.Field()
continuous_failed = scrapy.Field()
created_time = scrapy.Field()
# 检查IP代理的格式是否正确
def _check_format(self):
if self['schema'] is not None and self['ip'] is not None and self['port'] is not None:
if schema_pattern.match(self['schema']) and ip_pattern.match(self['ip']) and port_pattern.match(
self['port']):
return True
return False
# 获取IP代理的url
def _get_url(self):
return PROXY_URL_FORMATTER % {'schema': self['schema'], 'ip': self['ip'], 'port': self['port']}
kuai_proxy.py
# -*- coding: utf-8 -*-
import re
import time
import scrapy
from proxy_pool.utils import strip, logger
from proxy_pool.items import ProxyPoolItem
class KuaiProxySpider(scrapy.Spider):
name = 'kuai_proxy'
allowed_domains = ['kuaidaili.com']
start_urls = ['https://www.kuaidaili.com/free/inha/1/', 'https://www.kuaidaili.com/free/intr/1/']
def parse(self, response):
logger.info('正在爬取:< ' + response.request.url + ' >')
tr_list = response.css("div#list>table>tbody tr")
for tr in tr_list:
ip = tr.css("td[data-title='IP']::text").get()
port = tr.css("td[data-title='PORT']::text").get()
schema = tr.css("td[data-title='类型']::text").get()
if schema.lower() == "http" or schema.lower() == "https":
item = ProxyPoolItem()
item['schema'] = strip(schema).lower()
item['ip'] = strip(ip)
item['port'] = strip(port)
item['original'] = '快代理'
item['created_time'] = time.strftime('%Y-%m-%d', time.localtime(time.time()))
if item._check_format():
yield item
next_page = response.xpath("//a[@class='active']/../following-sibling::li/a/@href").get()
if next_page is not None:
next_url = 'https://www.kuaidaili.com' + next_page
yield scrapy.Request(next_url)
middlewares.py
# -*- coding: utf-8 -*-
import random
from proxy_pool.utils import logger
# 随机选择 IP 代理下载器中间件
class RandomProxyMiddleware(object):
# 从 settings 的 PROXIES 列表中随机选择一个作为代理
def process_request(self, request, spider):
proxy = random.choice(spider.settings['PROXIES'])
request.meta['proxy'] = proxy
return None
# 随机选择 User-Agent 的下载器中间件
class RandomUserAgentMiddleware(object):
def process_request(self, request, spider):
# 从 settings 的 USER_AGENTS 列表中随机选择一个作为 User-Agent
user_agent = random.choice(spider.settings['USER_AGENT_LIST'])
request.headers['User-Agent'] = user_agent
return None
def process_response(self, request, response, spider):
# 验证 User-Agent 设置是否生效
logger.info("headers ::> User-Agent = " + str(request.headers['User-Agent'], encoding="utf8"))
return response
pipelines.py
# -*- coding: utf-8 -*-
import json
import redis
from proxy_pool.settings import REDIS_HOST,REDIS_PORT,REDIS_PARAMS,PROXIES_UNCHECKED_LIST,PROXIES_UNCHECKED_SET
server = redis.StrictRedis(host=REDIS_HOST, port=REDIS_PORT,password=REDIS_PARAMS['password'])
class ProxyPoolPipeline(object):
# 将可用的IP代理添加到代理池队列
def process_item(self, item, spider):
if not self._is_existed(item):
server.rpush(PROXIES_UNCHECKED_LIST, json.dumps(dict(item),ensure_ascii=False))
# 检查IP代理是否已经存在
def _is_existed(self,item):
added = server.sadd(PROXIES_UNCHECKED_SET, item._get_url())
return added == 0
settings.py
# -*- coding: utf-8 -*-
BOT_NAME = 'proxy_pool'
SPIDER_MODULES = ['proxy_pool.spiders']
NEWSPIDER_MODULE = 'proxy_pool.spiders'
# 保存未检验代理的Redis key
PROXIES_UNCHECKED_LIST = 'proxies:unchecked:list'
# 已经存在的未检验HTTP代理和HTTPS代理集合
PROXIES_UNCHECKED_SET = 'proxies:unchecked:set'
# 代理地址的格式化字符串
PROXY_URL_FORMATTER = '%(schema)s://%(ip)s:%(port)s'
# 通用请求头字段
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,zh-TW;q=0.7',
'Connection': 'keep-alive'
}
# 请求太频繁会导致 503 ,在此设置 5 秒请求一次
DOWNLOAD_DELAY = 5 # 250 ms of delay
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'proxy_pool.middlewares.RandomUserAgentMiddleware': 543,
# 'proxy_pool.middlewares.RandomProxyMiddleware': 544,
}
ITEM_PIPELINES = {
'proxy_pool.pipelines.ProxyPoolPipeline': 300,
}
PROXIES = [
"https://171.13.92.212:9797",
"https://164.163.234.210:8080",
"https://143.202.73.219:8080",
"https://103.75.166.15:8080"
]
######################################################
##############下面是Scrapy-Redis相关配置################
######################################################
# 指定Redis的主机名和端口
REDIS_HOST = '172.16.250.238'
REDIS_PORT = 6379
REDIS_PARAMS = {'password': '123456'}
# 调度器启用Redis存储Requests队列
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 确保所有的爬虫实例使用Redis进行重复过滤
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 将Requests队列持久化到Redis,可支持暂停或重启爬虫
SCHEDULER_PERSIST = True
# Requests的调度策略,默认优先级队列
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
utils.py
# -*- coding: utf-8 -*-
import logging
# 设置日志输出格式
logging.basicConfig(level=logging.INFO,
format='[%(asctime)-15s] [%(levelname)8s] [%(name)10s ] - %(message)s (%(filename)s:%(lineno)s)',
datefmt='%Y-%m-%d %T'
)
logger = logging.getLogger(__name__)
# Truncate header and tailer blanks
def strip(data):
if data is not None:
return data.strip()
return data
到此这篇关于详解基于Scrapy的IP代理池搭建的文章就介绍到这了,更多相关Scrapy IP代理池搭建内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Scrapy 配置动态代理IP的实现
应用 Scrapy框架 ,配置动态IP处理反爬. # settings 配置中间件 DOWNLOADER_MIDDLEWARES = { 'text.middlewares.TextDownloaderMiddleware': 543, # 'text.middlewares.RandomUserAgentMiddleware': 544, # 'text.middlewares.CheckUserAgentMiddleware': 545, 'text.middlewares.ProxyMid
-

python3 Scrapy爬虫框架ip代理配置的方法
什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板.对于框架的学习,重点是要学习其框架的特性.各个功能的用法即可. 一.背景 在做爬虫项目的过程中遇到ip代理的问题,网上搜了一些,要么是用阿里云的ip代理,要么是搜一些网上现有的ip资源,然后配置在setting文件中.这两个方法都存在一些问题. 1.阿里云ip代理方法,网上大
-
Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例
本文实例讲述了Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能.分享给大家供大家参考,具体如下: 一.背景: 小编在爬虫的时候肯定会遇到被封杀的情况,昨天爬了一个网站,刚开始是可以了,在settings的设置DEFAULT_REQUEST_HEADERS伪装自己是chrome浏览器,刚开始是可以的,紧接着就被对方服务器封杀了. 代理: 代理,代理,一直觉得爬去网页把爬去速度放慢一点就能基本避免被封杀,虽然可以使用selenium,但是这个坎必须
-
Python基于scrapy采集数据时使用代理服务器的方法
本文实例讲述了Python基于scrapy采集数据时使用代理服务器的方法.分享给大家供大家参考.具体如下: # To authenticate the proxy, #you must set the Proxy-Authorization header. #You *cannot* use the form http://user:pass@proxy:port #in request.meta['proxy'] import base64 proxy_ip_port = "123.456.7
-
Scrapy框架爬取西刺代理网免费高匿代理的实现代码
分析 需求: 爬取西刺代理网免费高匿代理,并保存到MySQL数据库中. 这里只爬取前10页中的数据. 思路: 分析网页结构,确定数据提取规则 创建Scrapy项目 编写item,定义数据字段 编写spider,实现数据抓取 编写Pipeline,保存数据到数据库中 配置settings.py文件 运行爬虫项目 代码实现 items.py import scrapy class XicidailiItem(scrapy.Item): # 国家 country=scrapy.Field() # IP
-
讲解Python的Scrapy爬虫框架使用代理进行采集的方法
1.在Scrapy工程下新建"middlewares.py" # Importing base64 library because we'll need it ONLY in case if the proxy we are going to use requires authentication import base64 # Start your middleware class class ProxyMiddleware(object): # overwrite process
-
详解基于Scrapy的IP代理池搭建
一.为什么要搭建爬虫代理池 在众多的网站防爬措施中,有一种是根据ip的访问频率进行限制,即在某一时间段内,当某个ip的访问次数达到一定的阀值时,该ip就会被拉黑.在一段时间内禁止访问. 应对的方法有两种: 1. 降低爬虫的爬取频率,避免IP被限制访问,缺点显而易见:会大大降低爬取的效率. 2. 搭建一个IP代理池,使用不同的IP轮流进行爬取. 二.搭建思路 1.从代理网站(如:西刺代理.快代理.云代理.无忧代理)爬取代理IP: 2.验证代理IP的可用性(使用代理IP去请求指定URL,根据响应验证
-
python如何基于redis实现ip代理池
这篇文章主要介绍了python如何基于redis实现ip代理池,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 使用apscheduler库定时爬取ip,定时检测ip删除ip,做了2层检测,第一层爬取后放入redis--db0进行检测,成功的放入redis--db1再次进行检测,确保获取的代理ip的可用性 import requests, redis import pandas import random from apscheduler.sch
-
用python构建IP代理池详解
目录 概述 提供免费代理的网站 代码 导包 网站页面的url ip地址 检测 整理 必要参数 总代码 总结 概述 用爬虫时,大部分网站都有一定的反爬措施,有些网站会限制每个 IP 的访问速度或访问次数,超出了它的限制你的 IP 就会被封掉.对于访问速度的处理比较简单,只要间隔一段时间爬取一次就行了,避免频繁访问:而对于访问次数,就需要使用代理 IP 来帮忙了,使用多个代理 IP 轮换着去访问目标网址可以有效地解决问题. 目前网上有很多的代理服务网站提供代理服务,也提供一些免费的代理,但可用性较差
-
python3 requests中使用ip代理池随机生成ip的实例
啥也不说了,直接上代码吧! # encoding:utf-8 import requests # 导入requests模块用于访问测试自己的ip import random pro = ['1.119.129.2:8080', '115.174.66.148', '113.200.214.164'] # 在(http://www.xicidaili.com/wt/)上面收集的ip用于测试 # 没有使用字典的原因是 因为字典中的键是唯一的 http 和https 只能存在一个 所以不建议使用字典
-
Nginx配置参数中文说明详解(负载均衡与反向代理)
PS:最近在看<<高性能Linux服务器构建实战>>的Nginx章节,对其nginx介绍的非常详细,现把经常用到的Nginx配置参数中文说明摘录和nginx做负载均衡的本人真实演示实例抄录下来以便以后查看! Nginx配置参数中文详细说明 #定义Nginx运行的用户和用户组 user www www; # #nginx进程数,建议设置为等于CPU总核心数. worker_processes 8; # #全局错误日志定义类型,[ debug | info | notice | war
-
详解基于pycharm的requests库使用教程
目录 requests库安装和导入 requests库的get请求 requests库的post请求 requests库的代理 requests库的cookie 自动识别验证码 requests库安装和导入 第一步:cmd打开命令行,使用如下命令安装requests库. pip install requests 由于我的安装过了,所以如下: 如果提示你pip版本需要更新,按照提示的指令输入即可更新. 第二步:cmd使用如下命令,验证requests库安装完成. pip list 第三步:在pyc
-
详解ASP.NET Core 反向代理部署知多少
引言 最近在折腾统一认证中心,看到开源项目IdentityServer4.Admin集成了IdentityServer4和管理面板,就直接拿过来用了.在尝试Nginx部署时遇到了诸如虚拟目录映射,请求头超长.基础路径映射有误等问题,简单记录,以供后人参考. Nginx 配置路由转发 首先来看下IdentityServer4.Admin的项目结构: IdentityServer4.Admin / ├── Id4.Admin.Api # 用于提供访问Id4资源的WebApi项目 ├── Id4.Ad
-
python利用proxybroker构建爬虫免费IP代理池的实现
前言 写爬虫的小伙伴可能遇到过这种情况: 正当悠闲地喝着咖啡,满意地看着屏幕上的那一行行如流水般被爬下来的数据时,突然一个Error弹出,提示抓不到数据了... 然后你反复检查,确信自己代码莫得问题之后,发现居然连浏览器也无法正常访问网页了... 难道是网站被我爬瘫痪了? 然后你用手机浏览所爬网站,惊奇地发现居然能访问! 才原来我的IP被网站给封了,拒绝了我的访问 这时只能用IP代理来应对禁IP反爬策略了,但是网上高速稳定的代理IP大多都收费,看了看皱皱的钱包后,一个大胆的想法冒出 我要白嫖!
-
详解基于redis实现的四种常见的限流策略
目录 一.引言 二.固定时间窗口算法 三.滑动时间窗口算法 四.漏桶算法 五.令牌桶算法 一.引言 在web开发中功能是基石,除了功能以外运维和防护就是重头菜了.因为在网站运行期间可能会因为突然的访问量导致业务异常.也有可能遭受别人恶意攻击 所以我们的接口需要对流量进行限制.俗称的QPS也是对流量的一种描述 针对限流现在大多应该是令牌桶算法,因为它能保证更多的吞吐量.除了令牌桶算法还有他的前身漏桶算法和简单的计数算法 下面我们来看看这四种算法 二.固定时间窗口算法 固定时间窗口算法也可以叫做简单
-
详解Java的Proxy动态代理机制
一.Jvm加载对象 在说Java动态代理之前,还是要说一下Jvm加载对象的过程,这个依旧是理解动态代理的基础性原理: Java类即源代码程序.java类型文件,经过编译器编译之后就被转换成字节代码.class类型文件,类加载器负责读取字节代码,并转换成java.lang.Class对象,描述类在元数据空间的数据结构,类被实例化时,堆中存储实例化的对象信息,并且通过对象类型数据的指针找到类. 过程描述:源码->.java文件->.class文件->Class对象->实例对象 所以通过