在pandas多重索引multiIndex中选定指定索引的行方法
在multiIndex中选定指定索引的行
我们在用pandas类似groupby来使用多重index时,有时想要对多个level中的某个index对应的行进行操作,就需要在dataframe中找到该index对应的行,在单层index中我们可以方便的使用df.loc[index]来选择,在多重Index中我们可以利用的类似的思路,然而其中也有一些小坑,记录如下。
1 index为有序的
1.1 创建测试数据
首先创建一个dataframe数据
df = pd.DataFrame({'class':['A','A','A','B','B','B','C','C'],
'id':['a','b','c','a','b','c','a','b'],
'value':[1,2,3,4,5,6,7,8]})
df中内容如下图:

1.2 设置multiIndex
通过set_index设为多重索引
df = df.set_index(['class','id'])
设置索引后效果:
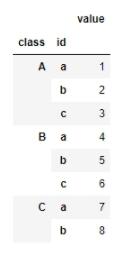
1.3 切片筛选index
这里同样使用loc定位
df.loc[('A',slice(None)),:]
各参数的解释如下:
loc[(a,b),c]中第一个参数元组为索引内容,a为level0索引对应的内容,b为level1索引对应的内容
因为df是一个dataframe,所以要用c来指定列
这里‘A',指选择class中的A类
slice(None), 是Python中的切片操作,这里用来选择任意的id,要注意!不能使用‘:'来指定任意index
‘:',用来指定dataframe任意的列
执行后的结果如下:

同样,如果想只保留id中的'a',则可以使用:
df.loc[(slice(None),'a'),:]
2 index无序
前面的例子对应的index列为数字或字母,是有序的,接下来我们看看index列为中文的情况。
2.1 创建无序测试数据
df2 = pd.DataFrame({'课程':['语文','语文','数学','数学'],'得分':['最高','最低','最高','最低'],'分值':[90,50,100,60]})
df2 = df2.set_index(['课程','得分'])
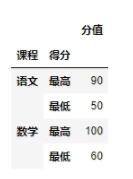
2.2 尝试切片选择index
df2.loc[('语文',slice(None)),:]
我们进行同样的操作,这时会发现提示出错:
UnsortedIndexError: 'MultiIndex Slicing requires the index to be fully lexsorted tuple len (2), lexsort depth (0)'
这是因为此时的index无法进行排序,在pandas文档中提到:Furthermore if you try to index something that is not fully lexsorted, this can raise:
我们可以通过 df2.index.is_lexsorted()来检查index是否有序,
In[1]: df2.index.is_lexsorted() out[1]: False
接下来,我们尝试对Index进行排序。(排序时要在level里指定index名)
2.3 对index排序后切片选择index
df2 = df2.sort_index(level='课程')
df2.loc[('语文',slice(None)),:]

得到了我们想要的结果。
参考文献:pandas-docs-MultiIndex / Advanced Indexing
以上这篇在pandas多重索引multiIndex中选定指定索引的行方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pandas将DataFrame的列变成行索引的方法
pandas提供了set_index方法可以将DataFrame的列(多列)变成行索引,通过reset_index方法可以将层次化索引的级别会被转移到列里面. 1.DataFrame的set_index方法 data = pd.DataFrame(np.arange(1,10).reshape(3,3),index=["a","b","c"],columns=["A","B","C"])
-
pandas.dataframe按行索引表达式选取方法
需要把一个从csv文件里读取来的数据集等距抽样分割,这里用到了列表表达式和dataframe.iloc 先生成索引列表: index_list = ['%d' %i for i in range(df.shape[0]) if i % 3 == 0] 在dataframe中选取 sample_df = df.iloc[index_list] 合起来 sample_df = df.iloc[['%d' %i for i in range(df.shape[0]) if i % 3 == 0]] 各
-
pandas数据清洗,排序,索引设置,数据选取方法
此教程适合有pandas基础的童鞋来看,很多知识点会一笔带过,不做详细解释 Pandas数据格式 Series DataFrame:每个column就是一个Series 基础属性shape,index,columns,values,dtypes,describe(),head(),tail() 统计属性Series: count(),value_counts(),前者是统计总数,后者统计各自value的总数 df.isnull() df的空值为True df.notnull() df的非空值为T
-
pandas实现选取特定索引的行
如下所示: >>> import numpy as np >>> import pandas as pd >>> index=np.array([2,4,6,8,10]) >>> data=np.array([3,5,7,9,11]) >>> data=pd.DataFrame({'num':data},index=index) >>> print(data) num 2 3 4 5 6 7 8 9
-
pandas数据处理基础之筛选指定行或者指定列的数据
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构). 本文为了方便理解会与excel或者sql操作行或列来进行联想类比 1.重新索引:reindex和ix 上一篇中介绍过数据读取后默认的行索引是0,1,2,3...这样的顺序号.列索引相当于字段名(即第一行数据),这里重新索引意思就是可以将默认的索引重新修改成自己想要的样子. 1.1 Series 比方说:data=Series([4,5,6],index=['a',
-
pandas重新生成索引的方法
在数据处理的过程中,出现了这样的问题,筛选某些数据,出现索引从600多开始,但是我希望这行数据下标从0开始. 这个时候,我想到的是: df.reindex(range(length)) 但是查看一下数据之后,发现0-624之间的值全为Nan,显然不是我需要的数据. 最后找到了说明: pandas调用reindex方法后净会根据新索引进行重排,如果某个索引值当前不存在,就会引入 缺失值:可以通过fill_value参数填充默认值,也可以通过method参数设置填充方法: 感谢身边同事的帮助,找到了
-
在pandas多重索引multiIndex中选定指定索引的行方法
在multiIndex中选定指定索引的行 我们在用pandas类似groupby来使用多重index时,有时想要对多个level中的某个index对应的行进行操作,就需要在dataframe中找到该index对应的行,在单层index中我们可以方便的使用df.loc[index]来选择,在多重Index中我们可以利用的类似的思路,然而其中也有一些小坑,记录如下. 1 index为有序的 1.1 创建测试数据 首先创建一个dataframe数据 df = pd.DataFrame({'class'
-
Python实现删除文件中含“指定内容”的行示例
本文实例讲述了Python实现删除文件中含指定内容的行.分享给大家供大家参考,具体如下: #!/bin/env python import shutil, sys, os darray = [ "Entering directory", "In function ", "Leaving directory", "__NR_SYSCALL_BASE", "arm-hisiv100-linux-ar ", &q
-
Linux bash删除文件中含“指定内容”的行功能示例
本文实例讲述了Linux bash删除文件中含"指定内容"的行功能.分享给大家供大家参考,具体如下: #!/bin/sh # 功能: 删除文件中含"指定内容"的行 # 运行方式: ./dline.sh c.log ==> 产生输出文件: c.log0 array=( "rm -f lvr_3531_pf_new" "arm-hisiv100-linux-gcc " "In function " &qu
-

易语言在画板中画指定样式饼形的方法
画饼方法 英文命令:pie 操作系统支持:Windows 所属对象:画板 语法: 无返回值 画板.画饼 (椭圆左上角横坐标,椭圆左上角纵坐标,椭圆右下角横坐标,椭圆右下角纵坐标,弧线起始点横坐标,弧线起始点纵坐标,弧线终止点横坐标,弧线终止点纵坐标) 例程 说明 通过"画饼"命令在画板中画指定样式的饼. 运行结果: 总结 以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对我们的支持.如果你想了解更多相关内容请查看下面相关链接
-
理解Sql Server中的聚集索引
说到聚集索引,我想每个码农都明白,但是也有很多像我这样的猥程序员,只能用死记硬背来解决这个问题,什么表中只能建一个聚集索引,然后又扯到了目录查找来帮助读者记忆....问题就在这里,我们不是学文科,,,不需要去死记硬背,,,我们需要的就是能看到在眼里面的真实东西.....我们都喜欢聚集索引,因为它能够把无序的堆表记录变成有序,还玩起了B树...这样就把复杂度从N降低到了LogMN... 这样的话逻辑读,物理读就下来了. 一:现象 1:无索引的情况 还是老规矩,看个例子感受下,首先我有一个Prod
-
python pandas创建多层索引MultiIndex的6种方式
目录 引言 pd.MultiIndex.from_arrays() pd.MultiIndex.from_tuples() 列表和元组是可以混合使用的 pd.MultiIndex.from_product() pd.MultiIndex.from_frame() groupby() pivot_table() 引言 在上一篇文章中介绍了如何创建Pandas中的单层索引,今天给大家带来的是如何创建Pandas中的多层索引. pd.MultiIndex,即具有多个层次的索引.通过多层次索引,我们就可
-
JS实现选定指定HTML元素对象中指定文本内容功能示例
本文实例讲述了JS实现选定指定HTML元素对象中指定文本内容功能.分享给大家供大家参考,具体如下: 该功能用处多多,可以灵活运用之!主要函数如下: //选中文本中指定部分 function selectSomeText(obj,start,end){ if(document.selection){ if(obj.tagName=='TEXTAREA'){ var i=obj.value.indexOf("\r",0); while(i!=-1&&i<end){ e
-
在Pandas中给多层索引降级的方法
# 背景介绍 通常我们不会在Pandas中主动设置多层索引,但是如果一个字段做多个不同的聚合运算, 比如sum, max这样形成的Column Level是有层次的,这样阅读非常方便,但是对编程定位比较麻烦. # 数据准备 import pandas as pd import numpy as np df = pd.DataFrame(np.arange(0, 14).reshape(7,2),columns =['a','b'] ) df.a = df.a %3 df['who'] = 'Bo
-
pandas中去除指定字符的实例
例表: 假如想要去掉表中的'#',':'而且以'#'和':'为分割线切割数据: #将dfxA_2的每一个分隔符之间的数据提出来 col1=dfxA_2['travel_seq'].str.split('#').str[0] col2=dfxA_2['travel_seq'].str.split('#').str[1] col3=dfxA_2['travel_seq'].str.split('#').str[2].str.split(';').str[0] 这里只是部分代码,实际情况按需求可以灵活
-
如何使用pandas读取txt文件中指定的列(有无标题)
最近在倒腾一个txt文件,因为文件太大,所以给切割成了好几个小的文件,只有第一个文件有标题,从第二个开始就没有标题了. 我的需求是取出指定的列的数据,踩了些坑给研究出来了. import pandas as pd # 我们的需求是 取出所有的姓名 # test1的内容 ''' id name score 1 张三 100 2 李四 99 3 王五 98 ''' test1 = pd.read_table("test1.txt") # 这个是带有标题的文件 names = test1[&