scrapy爬虫:scrapy.FormRequest中formdata参数详解
1. 背景
在网页爬取的时候,有时候会使用scrapy.FormRequest向目标网站提交数据(表单提交)。参照scrapy官方文档的标准写法是:
# header信息
unicornHeader = {
'Host': 'www.example.com',
'Referer': 'http://www.example.com/',
}
# 表单需要提交的数据
myFormData = {'name': 'John Doe', 'age': '27'}
# 自定义信息,向下层响应(response)传递下去
customerData = {'key1': 'value1', 'key2': 'value2'}
yield scrapy.FormRequest(url = "http://www.example.com/post/action",
headers = unicornHeader,
method = 'POST', # GET or POST
formdata = myFormData, # 表单提交的数据
meta = customerData, # 自定义,向response传递数据
callback = self.after_post,
errback = self.error_handle,
# 如果需要多次提交表单,且url一样,那么就必须加此参数dont_filter,防止被当成重复网页过滤掉了
dont_filter = True
)
但是,当表单提交数据myFormData 是形如字典内嵌字典的形式,又该如何写?
2. 案例 — 参数为字典
在做亚马逊网站爬取时,当进入商家店铺,爬取店铺内商品列表时,发现采取的方式是ajax请求,返回的是json数据。
请求信息如下:


响应信息如下:

如上图所示,From Data中的数据包含一个字典:
marketplaceID:ATVPDKIKX0DER
seller:A2FE6D62A4WM6Q
productSearchRequestData:{"marketplace":"ATVPDKIKX0DER","seller":"A2FE6D62A4WM6Q","url":"/sp/ajax/products","pageSize":12,"searchKeyword":"","extraRestrictions":{},"pageNumber":"1"}
# formDate 必须构造如下:
myFormData = {
'marketplaceID' : 'ATVPDKIKX0DER',
'seller' : 'A2FE6D62A4WM6Q',
# 注意下面这一行,内部字典是作为一个字符串的形式
'productSearchRequestData' :'{"marketplace":"ATVPDKIKX0DER","seller":"A2FE6D62A4WM6Q","url":"/sp/ajax/products","pageSize":12,"searchKeyword":"","extraRestrictions":{},"pageNumber":"1"}'
}
在amazon中实际使用的构造方法如下:
def sendRequestForProducts(response):
ajaxParam = response.meta
for pageIdx in range(1, ajaxParam['totalPageNum']+1):
ajaxParam['isFirstAjax'] = False
ajaxParam['pageNumber'] = pageIdx
unicornHeader = {
'Host': 'www.amazon.com',
'Origin': 'https://www.amazon.com',
'Referer': ajaxParam['referUrl'],
}
'''
marketplaceID:ATVPDKIKX0DER
seller:AYZQAQRQKEXRP
productSearchRequestData:{"marketplace":"ATVPDKIKX0DER","seller":"AYZQAQRQKEXRP","url":"/sp/ajax/products","pageSize":12,"searchKeyword":"","extraRestrictions":{},"pageNumber":1}
'''
productSearchRequestData = '{"marketplace": "ATVPDKIKX0DER", "seller": "' + f'{ajaxParam["sellerID"]}' + '","url": "/sp/ajax/products", "pageSize": 12, "searchKeyword": "","extraRestrictions": {}, "pageNumber": "' + str(pageIdx) + '"}'
formdataProduct = {
'marketplaceID': ajaxParam['marketplaceID'],
'seller': ajaxParam['sellerID'],
'productSearchRequestData': productSearchRequestData
}
productAjaxMeta = ajaxParam
# 请求店铺商品列表
yield scrapy.FormRequest(
url = 'https://www.amazon.com/sp/ajax/products',
headers = unicornHeader,
formdata = formdataProduct,
func = 'POST',
meta = productAjaxMeta,
callback = self.solderProductAjax,
errback = self.error, # 处理http error
dont_filter = True, # 需要加此参数的
)
3. 原理分析
举例来说,目前有如下一笔数据:
formdata = {
'Field': {"pageIdx":99, "size":"10"},
'func': 'nextPage',
}
从网页上,可以看到请求数据如下:
Field=%7B%22pageIdx%22%3A99%2C%22size%22%3A%2210%22%7D&func=nextPage
第一种,按照如下方式发出请求,结果如下(正确):
yield scrapy.FormRequest(
url = 'https://www.example.com/sp/ajax',
headers = unicornHeader,
formdata = {
'Field': '{"pageIdx":99, "size":"10"}',
'func': 'nextPage',
},
func = 'POST',
callback = self.handleFunc,
)
# 请求数据为:Field=%7B%22pageIdx%22%3A99%2C%22size%22%3A%2210%22%7D&func=nextPage
第二种,按照如下方式发出请求,结果如下(错误,无法获取到正确的数据):
yield scrapy.FormRequest(
url = 'https://www.example.com/sp/ajax',
headers = unicornHeader,
formdata = {
'Field': {"pageIdx":99, "size":"10"},
'func': 'nextPage',
},
func = 'POST',
callback = self.handleFunc,
)
# 经过错误的编码之后,发送的请求为:Field=size&Field=pageIdx&func=nextPage
我们跟踪看一下scrapy中的源码:
# E:/Miniconda/Lib/site-packages/scrapy/http/request/form.py
# FormRequest
class FormRequest(Request):
def __init__(self, *args, **kwargs):
formdata = kwargs.pop('formdata', None)
if formdata and kwargs.get('func') is None:
kwargs['func'] = 'POST'
super(FormRequest, self).__init__(*args, **kwargs)
if formdata:
items = formdata.items() if isinstance(formdata, dict) else formdata
querystr = _urlencode(items, self.encoding)
if self.func == 'POST':
self.headers.setdefault(b'Content-Type', b'application/x-www-form-urlencoded')
self._set_body(querystr)
else:
self._set_url(self.url + ('&' if '?' in self.url else '?') + querystr)
# 关键函数 _urlencode
def _urlencode(seq, enc):
values = [(to_bytes(k, enc), to_bytes(v, enc))
for k, vs in seq
for v in (vs if is_listlike(vs) else [vs])]
return urlencode(values, doseq=1)
分析过程如下:
# 第一步:items = formdata.items() if isinstance(formdata, dict) else formdata
# 第一步结果:经过items()方法执行后,原始的dict格式变成如下列表形式:
dict_items([('func', 'nextPage'), ('Field', {'size': '10', 'pageIdx': 99})])
# 第二步:再经过后面的 _urlencode方法将items转换成如下:
[(b'func', b'nextPage'), (b'Field', b'size'), (b'Field', b'pageIdx')]
# 可以看到就是在调用 _urlencode方法的时候出现了问题,上面的方法执行过后,会使字典形式的数据只保留了keys(value是字典的情况下,只保留了value字典中的key).
解决方案: 就是将字典当成普通的字符串,然后编码(转换成bytes),进行传输,到达服务器端之后,服务器会反过来进行解码,得到这个字典字符串。然后服务器按照Dict进行解析。
拓展:对于其他特殊类型的数据,都按照这种方式打包成字符串进行传递。
4. 补充1 ——参数类型
formdata的 参数值 必须是unicode , str 或者 bytes object,不能是整数。
案例:
yield FormRequest(
url = 'https://www.amztracker.com/unicorn.php',
headers = unicornHeader,
# formdata 的参数必须是字符串
formdata={'rank': 10, 'category': productDetailInfo['topCategory']},
method = 'GET',
meta = {'productDetailInfo': productDetailInfo},
callback = self.amztrackerSale,
errback = self.error, # 本项目中这里触发errback占绝大多数
dont_filter = True, # 按理来说是不需要加此参数的
)
# 提示如下ERROR:
Traceback (most recent call last):
File "E:\Miniconda\lib\site-packages\scrapy\utils\defer.py", line 102, in iter_errback
yield next(it)
File "E:\Miniconda\lib\site-packages\scrapy\spidermiddlewares\offsite.py", line 29, in process_spider_output
for x in result:
File "E:\Miniconda\lib\site-packages\scrapy\spidermiddlewares\referer.py", line 339, in <genexpr>
return (_set_referer(r) for r in result or ())
File "E:\Miniconda\lib\site-packages\scrapy\spidermiddlewares\urllength.py", line 37, in <genexpr>
return (r for r in result or () if _filter(r))
File "E:\Miniconda\lib\site-packages\scrapy\spidermiddlewares\depth.py", line 58, in <genexpr>
return (r for r in result or () if _filter(r))
File "E:\PyCharmCode\categorySelectorAmazon1\categorySelectorAmazon1\spiders\categorySelectorAmazon1Clawer.py", line 224, in parseProductDetail
dont_filter = True,
File "E:\Miniconda\lib\site-packages\scrapy\http\request\form.py", line 31, in __init__
querystr = _urlencode(items, self.encoding)
File "E:\Miniconda\lib\site-packages\scrapy\http\request\form.py", line 66, in _urlencode
for k, vs in seq
File "E:\Miniconda\lib\site-packages\scrapy\http\request\form.py", line 67, in <listcomp>
for v in (vs if is_listlike(vs) else [vs])]
File "E:\Miniconda\lib\site-packages\scrapy\utils\python.py", line 117, in to_bytes
'object, got %s' % type(text).__name__)
TypeError: to_bytes must receive a unicode, str or bytes object, got int
# 正确写法:
formdata = {'rank': str(productDetailInfo['topRank']), 'category': productDetailInfo['topCategory']},
原理部分(源代码):
# 第一阶段: 字典分解为items
if formdata:
items = formdata.items() if isinstance(formdata, dict) else formdata
querystr = _urlencode(items, self.encoding)
# 第二阶段: 对value,调用 to_bytes 编码
def _urlencode(seq, enc):
values = [(to_bytes(k, enc), to_bytes(v, enc))
for k, vs in seq
for v in (vs if is_listlike(vs) else [vs])]
return urlencode(values, doseq=1)
# 第三阶段: 执行 to_bytes ,参数要求是bytes, str
def to_bytes(text, encoding=None, errors='strict'):
"""Return the binary representation of `text`. If `text`
is already a bytes object, return it as-is."""
if isinstance(text, bytes):
return text
if not isinstance(text, six.string_types):
raise TypeError('to_bytes must receive a unicode, str or bytes '
'object, got %s' % type(text).__name__)
5. 补充2 ——参数为中文
formdata的 参数值 必须是unicode , str 或者 bytes object,不能是整数。
以1688网站搜索产品为案例:
搜索信息如下(搜索关键词为:动漫周边):
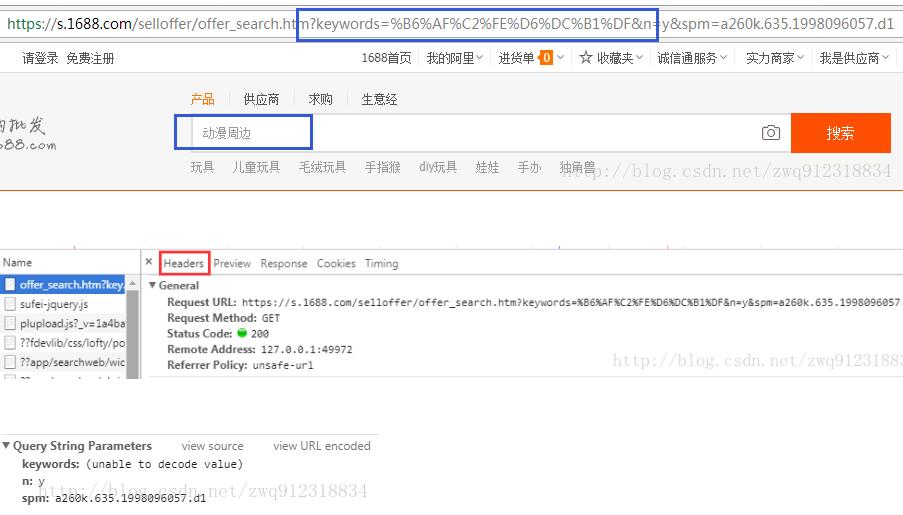
可以看到 动漫周边 == %B6%AF%C2%FE%D6%DC%B1%DF
# scrapy中这个请求的构造如下
# python3 所有的字符串都是unicode
unicornHeaders = {
':authority': 's.1688.com',
'Referer': 'https://www.1688.com/',
}
# python3 所有的字符串都是unicode
# 动漫周边 tobyte为:%B6%AF%C2%FE%D6%DC%B1%DF
formatStr = "动漫周边".encode('gbk')
print(f"formatStr = {formatStr}")
yield FormRequest(
url = 'https://s.1688.com/selloffer/offer_search.htm',
headers = unicornHeaders,
formdata = {'keywords': formatStr, 'n': 'y', 'spm': 'a260k.635.1998096057.d1'},
method = 'GET',
meta={},
callback = self.parseCategoryPage,
errback = self.error, # 本项目中这里触发errback占绝大多数
dont_filter = True, # 按理来说是不需要加此参数的
)
# 日志如下:
formatStr = b'\xb6\xaf\xc2\xfe\xd6\xdc\xb1\xdf'
2017-11-16 15:11:02 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://sec.1688.com/query.htm?smApp=searchweb2&smPolicy=searchweb2-selloffer-anti_Spider-seo-html-checklogin&smCharset=GBK&smTag=MTE1LjIxNi4xNjAuNDYsLDU5OWQ1NWIyZTk0NDQ1Y2E5ZDAzODRlOGM1MDI2OTZj&smReturn=https%3A%2F%2Fs.1688.com%2Fselloffer%2Foffer_search.htm%3Fkeywords%3D%25B6%25AF%25C2%25FE%25D6%25DC%25B1%25DF%26n%3Dy%26spm%3Da260k.635.1998096057.d1&smSign=05U0%2BJXfKLQmSbsnce55Yw%3D%3D> from <GET https://s.1688.com/selloffer/offer_search.htm?keywords=%B6%AF%C2%FE%D6%DC%B1%DF&n=y&spm=a260k.635.1998096057.d1>
# https://s.1688.com/selloffer/offer_search.htm?keywords=%B6%AF%C2%FE%D6%DC%B1%DF&n=y&spm=a260k.635.1998096057.d1
以上这篇scrapy爬虫:scrapy.FormRequest中formdata参数详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python爬虫:Request Payload和Form Data的简单区别说明
Request Payload 和 Form Data 请求头上的参数差别在于: Content-Type Form Data Post表单请求 代码示例 headers = { "Content-Type": "application/x-www-form-urlencoded" } requests.post(url, data=data, headers=headers) Request Payload 传递json数据 headers = { "C
-
python使用scrapy发送post请求的坑
使用requests发送post请求 先来看看使用requests来发送post请求是多少好用,发送请求 Requests 简便的 API 意味着所有 HTTP 请求类型都是显而易见的.例如,你可以这样发送一个 HTTP POST 请求: >>>r = requests.post('http://httpbin.org/post', data = {'key':'value'}) 使用data可以传递字典作为参数,同时也可以传递元祖 >>>payload = (('ke
-

python实现发送form-data数据的方法详解
本文实例讲述了python实现发送form-data数据的方法.分享给大家供大家参考,具体如下: 源代码 -----------------------------279361243530614 Content-Disposition: form-data; name="parent_dir" / -----------------------------279361243530614 Content-Disposition: form-data; name="file&qu
-
scrapy爬虫:scrapy.FormRequest中formdata参数详解
1. 背景 在网页爬取的时候,有时候会使用scrapy.FormRequest向目标网站提交数据(表单提交).参照scrapy官方文档的标准写法是: # header信息 unicornHeader = { 'Host': 'www.example.com', 'Referer': 'http://www.example.com/', } # 表单需要提交的数据 myFormData = {'name': 'John Doe', 'age': '27'} # 自定义信息,向下层响应(respon
-
node获取命令行中的参数详解
目录 认识process process.arg 封装获取参数函数 认识process 在开发cli工具时,往往离不开获取指令中各种参数信息,接下来本文将带着你如何在Node.js中获取执行时的参数 process是nodejs内置的一个对象,该对象提供了当前有关nodejs进程的信息.(例如获取当前进程id,执行平台等与当前执行进程相关的对象和方法) node process文档 process.arg 在该对象中,有一个arg属性,它可以获取当前node执行时传入各个参数数据. 我们创建一个
-
Python之Scrapy爬虫框架安装及简单使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取(更确切来说,网络抓取)所设计的, 也可以应用在获取API所返回的数据(例如Amazon Associates Web Services) 或者通用的网络爬虫. 本文档将通过介绍Sc
-
Django的models中on_delete参数详解
在Django2.0以上的版本中,创建外键和一对一关系必须定义on_delete参数,我们可以在其源码中看到相关信息 class ForeignKey(ForeignObject): """ Provide a many-to-one relation by adding a column to the local model to hold the remote value. By default ForeignKey will target the pk of the r
-
MySQL中slave_exec_mode参数详解
今天无意当中看到参数slave_exec_mode,从手册里的说明看出该参数和MySQL复制相关,是可以动态修改的变量,默认是STRICT模式(严格模式),可选值有IDEMPOTENT模式(幂等模式).设置成IDEMPOTENT模式可以让从库避免1032(从库上不存在的键)和1062(重复键,需要存在主键或则唯一键)的错误,该模式只有在ROW EVENT的binlog模式下生效,在STATEMENT EVENT的binlog模式下无效.IDEMPOTENT模式主要用于多主复制和NDB CLUST
-
scrapy redis配置文件setting参数详解
scrapy项目 setting.py #Resis 设置 #使能Redis调度器 SCHEDULER = 'scrapy_redis.scheduler.Scheduler' #所有spider通过redis使用同一个去重过滤器 DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' #不清除Redis队列.这样可以暂停/恢复 爬取 #SCHEDULER_PERSIST = True #SCHEDULER_QUEUE_CLASS =
-
Jquery中$.ajax()方法参数详解
俗说好记性不如个烂笔头,下面是jquery中的ajax方法参数详解,这里整理了一些供大家参考. 1.url: 要求为String类型的参数,(默认为当前页地址)发送请求的地址. 2.type: 要求为String类型的参数,请求方式(post或get)默认为get.注意其他http请求方法,例如put和delete也可以使用,但仅部分浏览器支持. 3.timeout: 要求为Number类型的参数,设置请求超时时间(毫秒).此设置将覆盖$.ajaxSetup()方法的全局设置. 4.async:
-
linux 中的ls命令参数详解及ls命令的使用实例
一.ls命令参数详解 可以通过阅读 ls 的说明书页(man ls)来获得选项的完整列表. -a – 全部(all).列举目录中的全部文件,包括隐藏文件(.filename).位于这个列表的起首处的 .. 和 . 依次是指父目录和你的当前目录. -l – 长(long).列举目录内容的细节,包括权限(模式).所有者.组群.大小.创建日期.文件是否是到系统其它地方的链接,以及链接的指向. -F – 文件类型(File type).在每一个列举项目之后添加一个符号.这些符号包括:/ 表明是一个目录:
-
Webpack中SplitChunksPlugin 配置参数详解
代码分割本身和 webpack 没有什么关系,但是由于使用 webpack 可以非常轻松地实现代码分割,所以提到代码分割首先就会想到使用 webopack 实现. 在 webpack 中是使用 SplitChunksPlugin 来实现的,由于 SplitChunksPlugin 配置参数众多,接下来就来梳理一下这些配置参数. 官网上的默认配置参数如下: module.exports = { //... optimization: { splitChunks: { chunks: 'async'
-
OpenCV中findContours函数参数详解
注: 这篇文章用的OpenCV版本是2.4.10, 3以上的OpenCV版本相关函数可能有改动 Opencv中通过使用findContours函数,简单几个的步骤就可以检测出物体的轮廓,很方便.这些准备继续探讨一下findContours方法中各参数的含义及用法,比如要求只检测最外层轮廓该怎么办?contours里边的数据结构是怎样的?hierarchy到底是什么鬼?Point()有什么用? 先从findContours函数原型看起: findContours( InputOutputArray