Java 定时任务技术趋势详情
目录
- Java 中自带的解决方案
- Spring 中自带的解决方案
- 业务幂等解决方案
- 开源任务调度中间件
- 企业级解决方案
定时任务技术趋势简介:定时任务是每个业务常见的需求,比如每分钟扫描超时支付的订单,每小时清理一次数据库历史数据,每天统计前一天的数据并生成报表等等。
Java 中自带的解决方案
使用 Timer
创建 java.util.TimerTask 任务,在 run 方法中实现业务逻辑。通过 java.util.Timer 进行调度,支持按照固定频率执行。所有的 TimerTask 是在同一个线程中串行执行,相互影响。也就是说,对于同一个 Timer 里的多个 TimerTask 任务,如果一个 TimerTask 任务在执行中,其它 TimerTask 即使到达执行的时间,也只能排队等待。如果有异常产生,线程将退出,整个定时任务就失败。
import java.util.Timer;
import java.util.TimerTask;
public class TestTimerTask {
public static void main(String[] args) {
TimerTask timerTask = new TimerTask() {
@Override
public void run() {
System.out.println("hell world");
}
};
Timer timer = new Timer();
timer.schedule(timerTask, 10, 3000);
}
}
使用 ScheduledExecutorService
基于线程池设计的定时任务解决方案,每个调度任务都会分配到线程池中的一个线程去执行,解决 Timer 定时器无法并发执行的问题,支持 fixedRate 和 fixedDelay。
import java.util.Timer;
import java.util.TimerTask;
public class TestTimerTask {
public static void main(String[] args) {
TimerTask timerTask = new TimerTask() {
@Override
public void run() {
System.out.println("hell world");
}
};
Timer timer = new Timer();
timer.schedule(timerTask, 10, 3000);
}
}
Spring 中自带的解决方案
Springboot 中提供了一套轻量级的定时任务工具 Spring Task,通过注解可以很方便的配置,支持 cron 表达式、fixedRate、fixedDelay。
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class TestTimerTask {
public static void main(String[] args) {
ScheduledExecutorService ses = Executors.newScheduledThreadPool(5);
//按照固定频率执行,每隔5秒跑一次
ses.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
System.out.println("hello fixedRate");
}
}, 0, 5, TimeUnit.SECONDS);
//按照固定延时执行,上次执行完后隔3秒再跑
ses.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
System.out.println("hello fixedDelay");
}
}, 0, 3, TimeUnit.SECONDS);
}
}
Spring Task 相对于上面提到的两种解决方案,最大的优势就是支持 cron 表达式,可以处理按照标准时间固定周期执行的业务,比如每天几点几分执行。
业务幂等解决方案
现在的应用基本都是分布式部署,所有机器的代码都是一样的,前面介绍的 Java 和 Spring 自带的解决方案,都是进程级别的,每台机器在同一时间点都会执行定时任务。这样会导致需要业务幂等的定时任务业务有问题,比如每月定时给用户推送消息,就会推送多次。
于是,很多应用很自然的就想到了使用分布式锁的解决方案。即每次定时任务执行之前,先去抢锁,抢到锁的执行任务,抢不到锁的不执行。怎么抢锁,又是五花八门,比如使用 DB、zookeeper、redis。
使用 DB 或者 Zookeeper 抢锁
使用 DB 或者 Zookeeper 抢锁的架构差不多,原理如下:
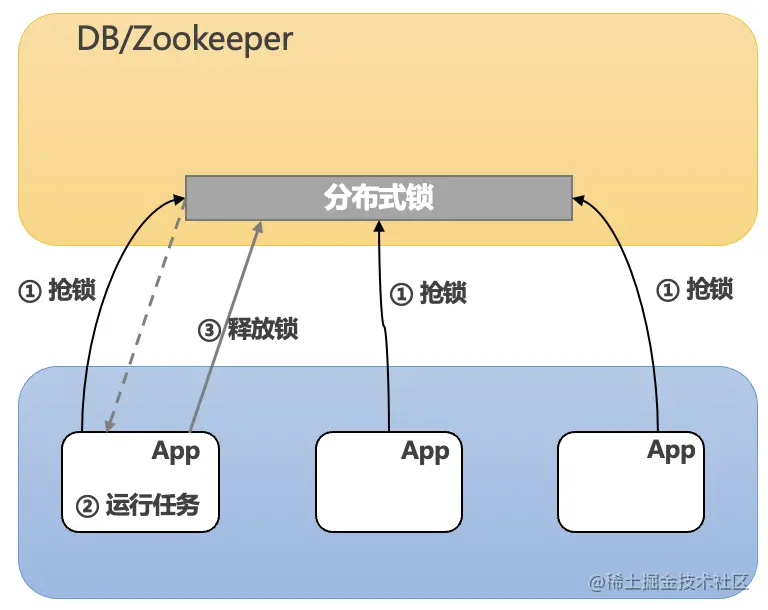
- 定时时间到了,在回调方法里,先去抢锁。
- 抢到锁,则继续执行方法,没抢到锁直接返回。
- 执行完方法后,释放锁。
示例代码如下:
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
@Component
@EnableScheduling
public class MyTask {
/**
* 每分钟的第30秒跑一次
*/
@Scheduled(cron = "30 * * * * ?")
public void task1() throws InterruptedException {
System.out.println("hello cron");
}
/**
* 每隔5秒跑一次
*/
@Scheduled(fixedRate = 5000)
public void task2() throws InterruptedException {
System.out.println("hello fixedRate");
}
/**
* 上次跑完隔3秒再跑
*/
@Scheduled(fixedDelay = 3000)
public void task3() throws InterruptedException {
System.out.println("hello fixedDelay");
}
}
当前的这个设计,仔细一点的同学可以发现,其实还是有可能导致任务重复执行的。比如任务执行的非常快,A 这台机器抢到锁,执行完任务后很快就释放锁了。B 这台机器后抢锁,还是会抢到锁,再执行一遍任务。
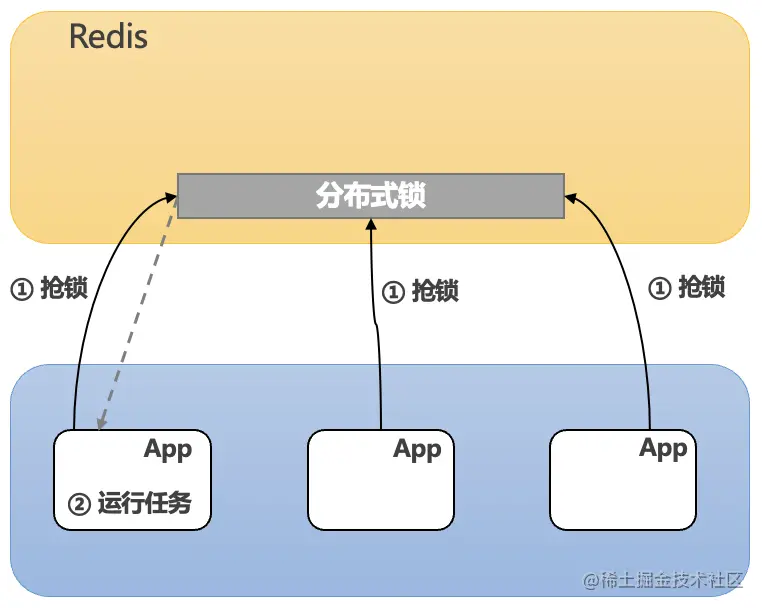
使用 redis 抢锁
使用 redis 抢锁,其实架构上和 DB/zookeeper 差不多,不过 redis 抢锁支持过期时间,不用主动去释放锁,并且可以充分利用这个过期时间,解决任务执行过快释放锁导致任务重复执行的问题,架构如下:
示例代码如下:
@Component
@EnableScheduling
public class MyTask {
/**
* 每分钟的第30秒跑一次
*/
@Scheduled(cron = "30 * * * * ?")
public void task1() throws InterruptedException {
String lockName = "task1";
if (tryLock(lockName, 30)) {
System.out.println("hello cron");
releaseLock(lockName);
} else {
return;
}
}
private boolean tryLock(String lockName, long expiredTime) {
//TODO
return true;
}
private void releaseLock(String lockName) {
//TODO
}
}
看到这里,可能又会有同学有问题,加一个过期时间是不是还是不够严谨,还是有可能任务重复执行?
——的确是的,如果有一台机器突然长时间的 fullgc,或者之前的任务还没处理完(Spring Task 和 ScheduledExecutorService 本质还是通过线程池处理任务),还是有可能隔了 30 秒再去调度任务的。
使用 Quartz
Quartz**[1]** 是一套轻量级的任务调度框架,只需要定义了 Job(任务),Trigger(触发器)和 Scheduler(调度器),即可实现一个定时调度能力。支持基于数据库的集群模式,可以做到任务幂等执行。
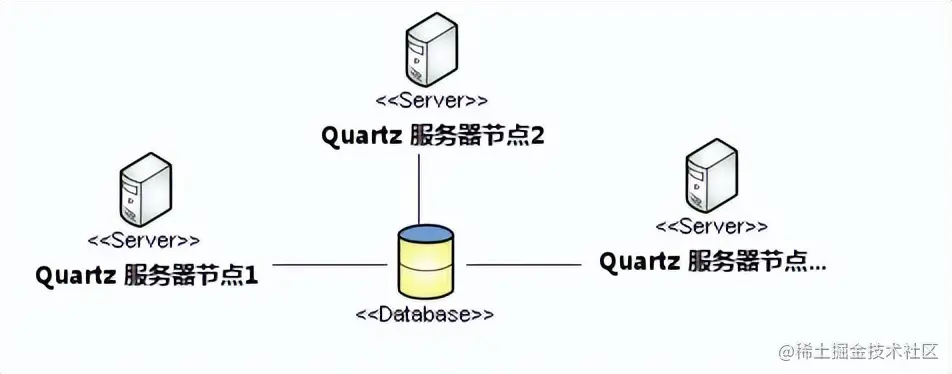
Quartz 支持任务幂等执行,其实理论上还是抢 DB 锁,我们看下 quartz 的表结构:
其中,QRTZ_LOCKS 就是 Quartz 集群实现同步机制的行锁表,其表结构如下:
--QRTZ_LOCKS表结构 CREATE TABLE `QRTZ_LOCKS` ( `LOCK_NAME` varchar(40) NOT NULL, PRIMARY KEY (`LOCK_NAME`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; --QRTZ_LOCKS记录 +-----------------+ | LOCK_NAME | +-----------------+ | CALENDAR_ACCESS | | JOB_ACCESS | | MISFIRE_ACCESS | | STATE_ACCESS | | TRIGGER_ACCESS | +-----------------+
可以看出 QRTZ_LOCKS 中有 5 条记录,代表 5 把锁,分别用于实现多个 Quartz Node 对 Job、Trigger、Calendar 访问的同步控制。
开源任务调度中间件
上面提到的解决方案,在架构上都有一个问题,那就是每次调度都需要抢锁,特别是使用 DB 和 Zookeeper 抢锁,性能会比较差,一旦任务量增加到一定的量,就会有比较明显的调度延时。还有一个痛点,就是业务想要修改调度配置,或者增加一个任务,得修改代码重新发布应用。
于是开源社区涌现了一堆任务调度中间件,通过任务调度系统进行任务的创建、修改和调度,这其中国内最火的就是 XXL-JOB 和 ElasticJob。
ElasticJob
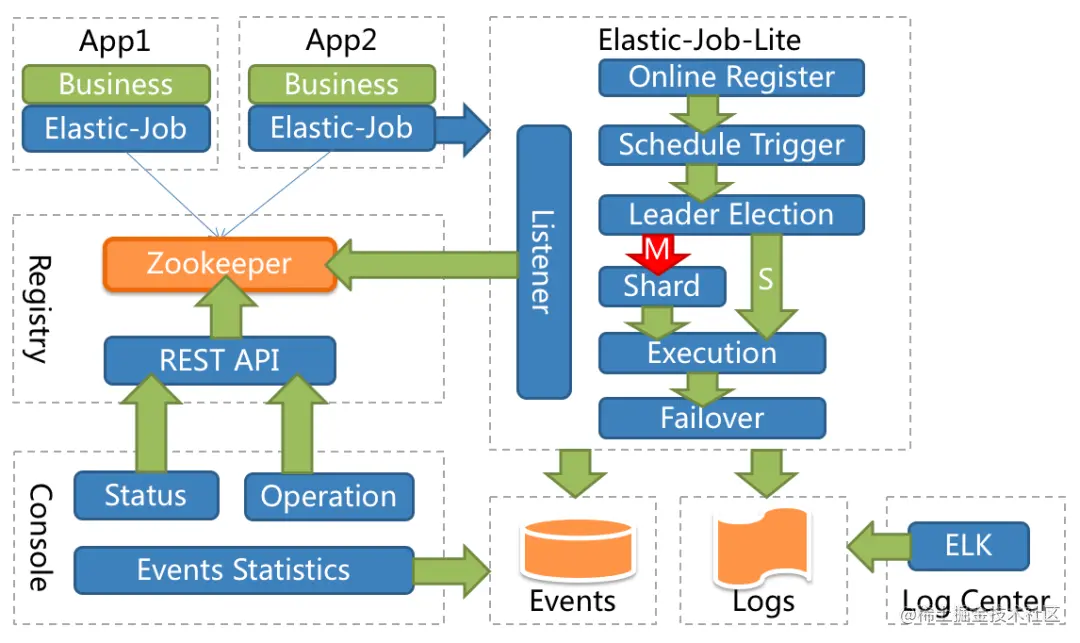
ElasticJob**[2]** 是一款基于 Quartz 开发,依赖 Zookeeper 作为注册中心、轻量级、无中心化的分布式任务调度框架,目前已经通过 Apache 开源。
ElasticJob 相对于 Quartz 来说,从功能上最大的区别就是支持分片,可以将一个任务分片参数分发给不同的机器执行。架构上最大的区别就是使用 Zookeeper 作为注册中心,不同的任务分配给不同的节点调度,不需要抢锁触发,性能上比 Quartz 上强大很多,架构图如下:
开发上也比较简单,和 springboot 结合比较好,可以在配置文件定义任务如下:
elasticjob:
regCenter:
serverLists: localhost:2181
namespace: elasticjob-lite-springboot
jobs:
simpleJob:
elasticJobClass: org.apache.shardingsphere.elasticjob.lite.example.job.SpringBootSimpleJob
cron: 0/5 * * * * ?
timeZone: GMT+08:00
shardingTotalCount: 3
shardingItemParameters: 0=Beijing,1=Shanghai,2=Guangzhou
scriptJob:
elasticJobType: SCRIPT
cron: 0/10 * * * * ?
shardingTotalCount: 3
props:
script.command.line: "echo SCRIPT Job: "
manualScriptJob:
elasticJobType: SCRIPT
jobBootstrapBeanName: manualScriptJobBean
shardingTotalCount: 9
props:
script.command.line: "echo Manual SCRIPT Job: "
实现任务接口如下:
@Component
public class SpringBootShardingJob implements SimpleJob {
@Override
public void execute(ShardingContext context) {
System.out.println("分片总数="+context.getShardingTotalCount() + ", 分片号="+context.getShardingItem()
+ ", 分片参数="+context.getShardingParameter());
}
运行结果如下:
分片总数=3, 分片号=0, 分片参数=Beijing
分片总数=3, 分片号=1, 分片参数=Shanghai
分片总数=3, 分片号=2, 分片参数=Guangzhou
同时,ElasticJob 还提供了一个简单的 UI,可以查看任务的列表,同时支持修改、触发、停止、生效、失效操作。
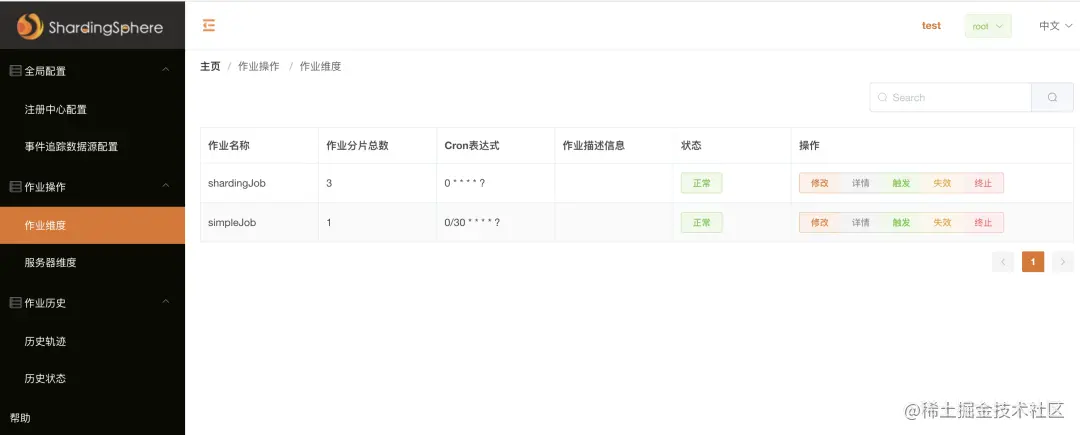
遗憾的是,ElasticJob 暂不支持动态创建任务。
XXL-JOB
XXL-JOB**[3]** 是一个开箱即用的轻量级分布式任务调度系统,其核心设计目标是开发迅速、学习简单、轻量级、易扩展,在开源社区广泛流行。
XXL-JOB 是 Master-Slave 架构,Master 负责任务的调度,Slave 负责任务的执行,架构图如下:
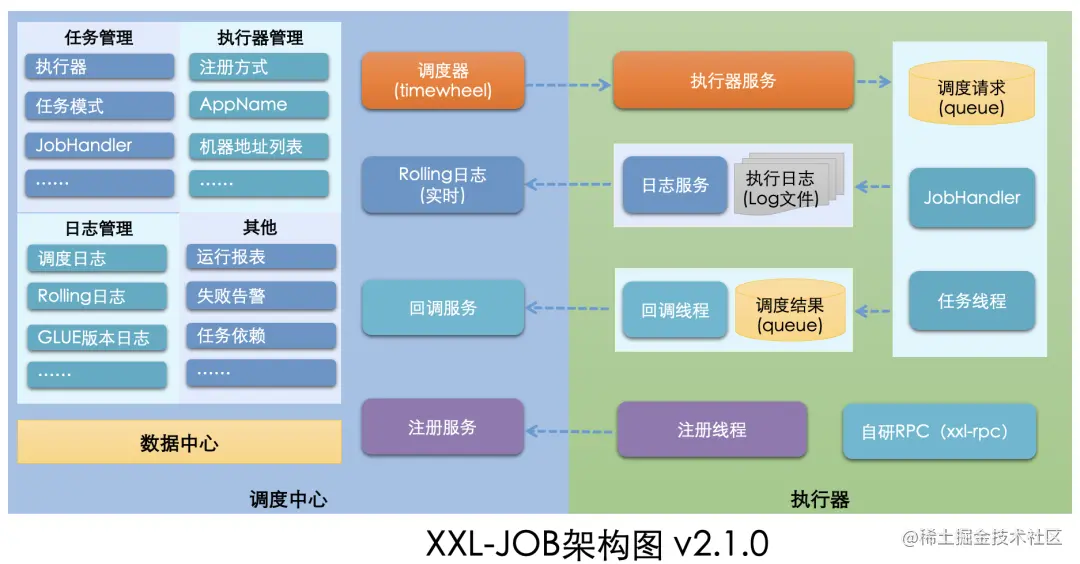
XXL-JOB 接入也很方便,不同于 ElasticJob 定义任务实现类,是通过@XxlJob 注解定义 JobHandler。
@Component
public class SampleXxlJob {
private static Logger logger = LoggerFactory.getLogger(SampleXxlJob.class);
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("demoJobHandler")
public ReturnT<String> demoJobHandler(String param) throws Exception {
XxlJobLogger.log("XXL-JOB, Hello World.");
for (int i = 0; i < 5; i++) {
XxlJobLogger.log("beat at:" + i);
TimeUnit.SECONDS.sleep(2);
}
return ReturnT.SUCCESS;
}
/**
* 2、分片广播任务
*/
@XxlJob("shardingJobHandler")
public ReturnT<String> shardingJobHandler(String param) throws Exception {
// 分片参数
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
XxlJobLogger.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardingVO.getIndex(), shardingVO.getTotal());
// 业务逻辑
for (int i = 0; i < shardingVO.getTotal(); i++) {
if (i == shardingVO.getIndex()) {
XxlJobLogger.log("第 {} 片, 命中分片开始处理", i);
} else {
XxlJobLogger.log("第 {} 片, 忽略", i);
}
}
return ReturnT.SUCCESS;
}
}
XXL-JOB 相较于 ElasticJob,最大的特点就是功能比较丰富,可运维能力比较强,不但支持控制台动态创建任务,还有调度日志、运行报表等功能。

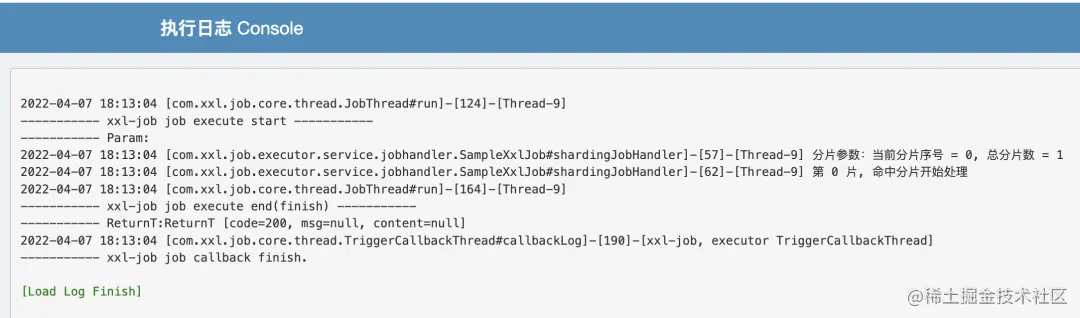
XXL-JOB 的历史记录、运行报表和调度日志,都是基于数据库实现的:
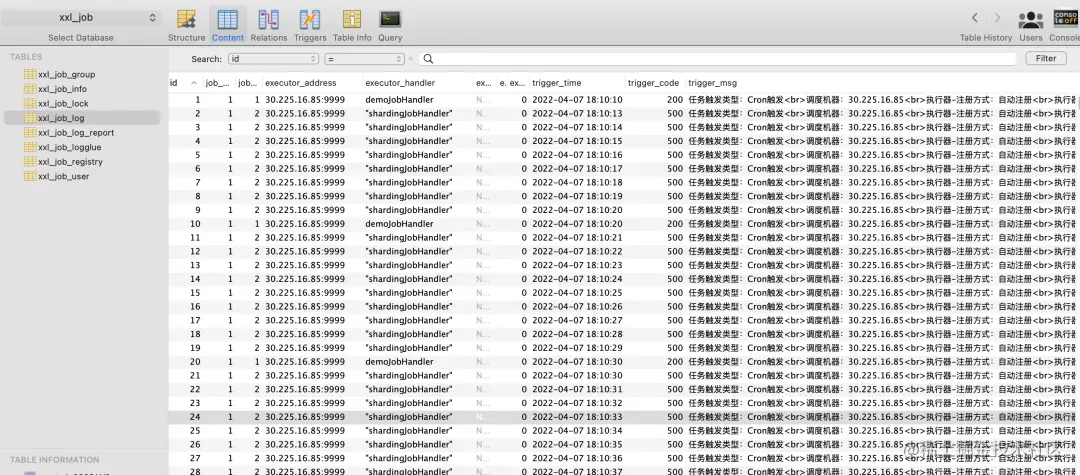
由此可以看出,XXL-JOB 所有功能都依赖数据库,且调度中心不支持分布式架构,在任务量和调度量比较大的情况下,会有性能瓶颈。不过如果对任务量级、高可用、监控报警、可视化等没有过高要求的话,XXL-JOB 基本可以满足定时任务的需求。
企业级解决方案
开源软件只能提供基础的调度能力,在监管控上的能力一般都比较弱。比如日志服务,业界往往使用 ELK 解决方案;短信报警,需要有短信平台;监控大盘,现在主流的解决方案是 Prometheus;等等。企业想要有这些能力,不但需要额外的开发成本,还需要昂贵的资源成本。
另外使用开源软件也伴随着稳定性的风险,就是出了问题没人能处理,想要反馈到社区等社区处理,这个链路太长了,早就产生故障了。
阿里云任务调度 SchedulerX**[4]** 是阿里巴巴自研的基于 Akka 架构的一站式任务调度平台,兼容开源 XXL-JOB、ElasticJob、Quartz(规划中),支持 Cron 定时、一次性任务、任务编排、分布式跑批,具有高可用、可视化、可运维、低延时等能力,自带企业级监控大盘、日志服务、短信报警等服务。
优势
安全防护
- 多层次安全防护:支持 HTTPS 和 VPC 访问,同时还有阿里云的多层安全防护,防止恶意攻击。
- 多租户隔离机制:支持多地域、命名空间和应用级别的隔离。
- 权限管控:支持控制台读写的权限管理,客户端接入的鉴权。
企业级高可用
SchedulerX2.0 采用高可用架构,任务多备份机制,经历阿里集团多年双十一、容灾演练,可以做到任意一个机房挂了,任务调度都不会收到影响。
商业级报警运维
- 报警:支持邮件、钉钉、短信、电话,(其他报警方式在规划中)。支持任务失败、超时、无可用机器报警。报警内容可以直接看出任务失败的原因,以钉钉机器人为例。

- 运维操作:原地重跑、重刷数据、标记成功、查看堆栈、停止任务、指定机器等。
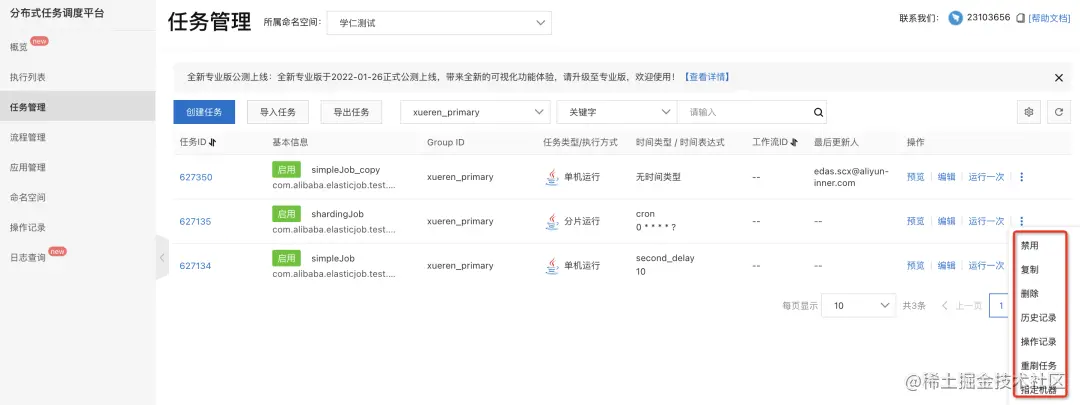
丰富的可视化
schedulerx 拥有丰富的可视化能力,比如:
用户大盘:
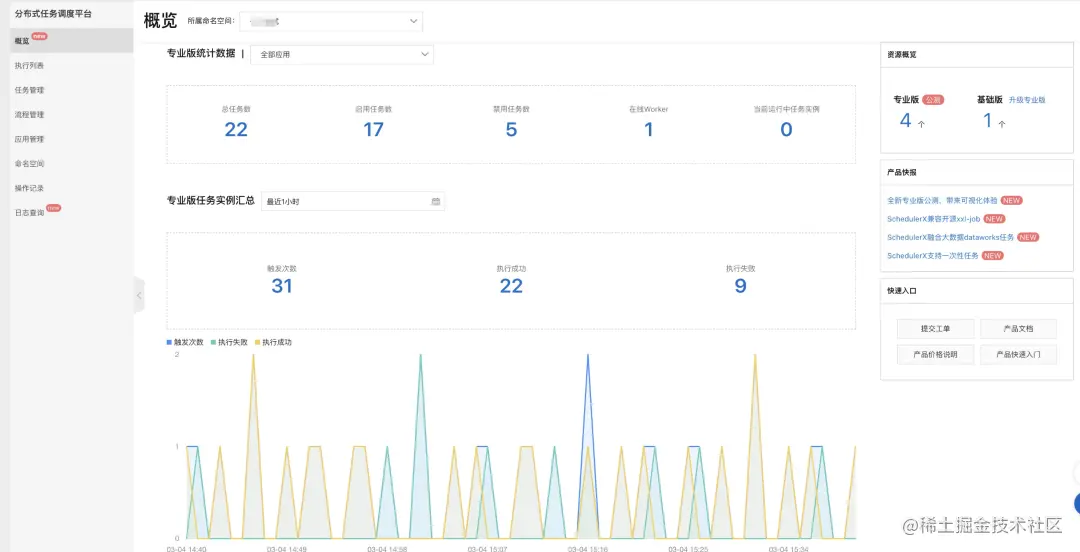
查看任务历史执行记录:
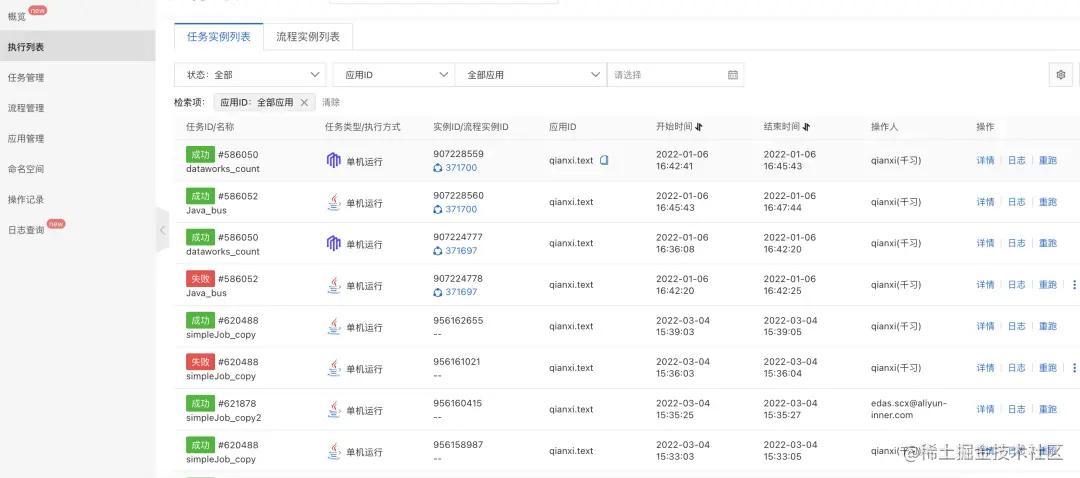
查看任务运行日志:
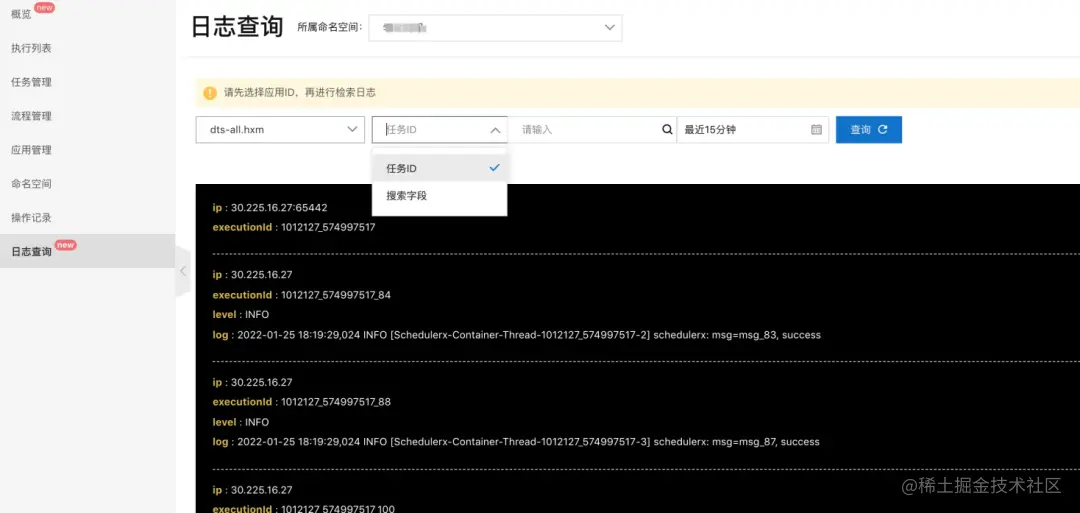
查看任务运行堆栈:
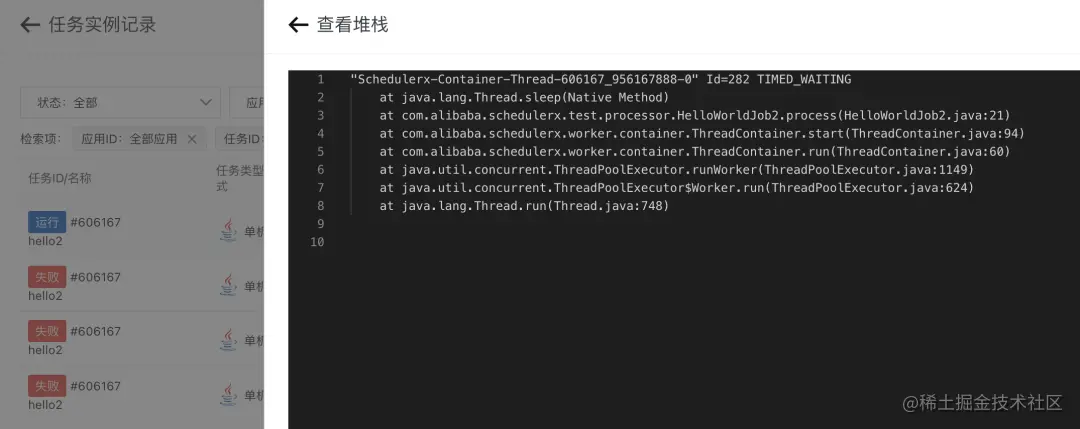
查看任务操作记录:
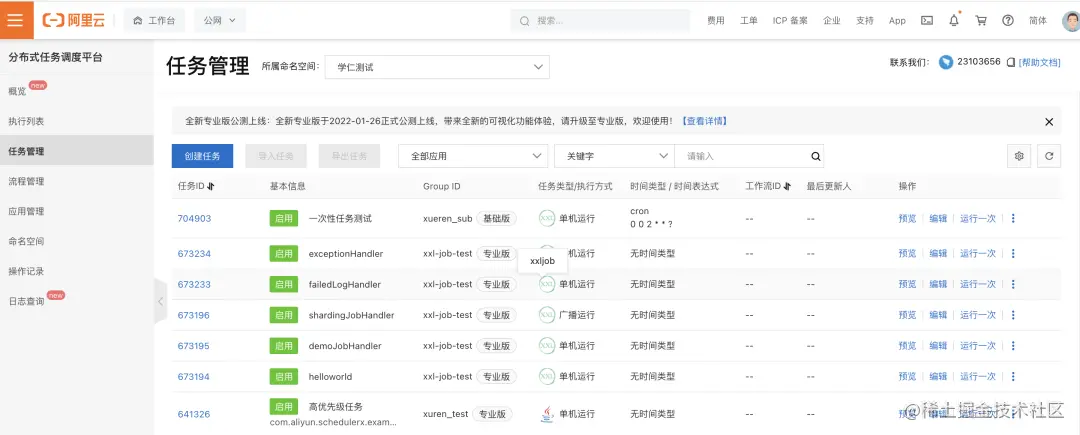
兼容开源
Schedulerx 兼容开源 XXL-JOB、ElasticJob、Quartz(规划中),业务不需要改一行代码,即可以将任务托管在 SchedulerX 调度平台,享有企业级可视化和报警的能力。
Spring 原生
SchedulerX 支持通过控制台和 API 动态创建任务,也支持 Spring 声明式任务定义,一份任务配置可以拿到任何环境一键启动,配置如下:
spring:
schedulerx2:
endpoint: acm.aliyun.com #请填写不同regin的endpoint
namespace: 433d8b23-06e9-xxxx-xxxx-90d4d1b9a4af #region内全局唯一,建议使用UUID生成
namespaceName: 学仁测试
appName: myTest
groupId: myTest.group #同一个命名空间下需要唯一
appKey: myTest123@alibaba #应用的key,不要太简单,注意保管好
regionId: public #填写对应的regionId
aliyunAccessKey: xxxxxxx #阿里云账号的ak
aliyunSecretKey: xxxxxxx #阿里云账号的sk
alarmChannel: sms,ding #报警通道:短信和钉钉
jobs:
simpleJob:
jobModel: standalone
className: com.aliyun.schedulerx.example.processor.SimpleJob
cron: 0/30 * * * * ? # cron表达式
jobParameter: hello
overwrite: true
shardingJob:
jobModel: sharding
className: ccom.aliyun.schedulerx.example.processor.ShardingJob
oneTime: 2022-06-02 12:00:00 # 一次性任务表达式
jobParameter: 0=Beijing,1=Shanghai,2=Guangzhou
overwrite: true
broadcastJob: # 不填写cron和oneTime,表示api任务
jobModel: broadcast
className: com.aliyun.schedulerx.example.processor.BroadcastJob
jobParameter: hello
overwrite: true
mapReduceJob:
jobModel: mapreduce
className: com.aliyun.schedulerx.example.processor.MapReduceJob
cron: 0 * * * * ?
jobParameter: 100
overwrite: true
alarmUsers: #报警联系人
user1:
userName: 张三
userPhone: 12345678900
user2:
userName: 李四
ding: https://oapi.dingtalk.com/robot/send?access_token=xxxxx
分布式跑批
SchedulerX 提供了丰富的分布式模型,可以处理各种各样的分布式业务场景。包括单机、广播、分片、MapReduce**[5]** 等,架构如下:
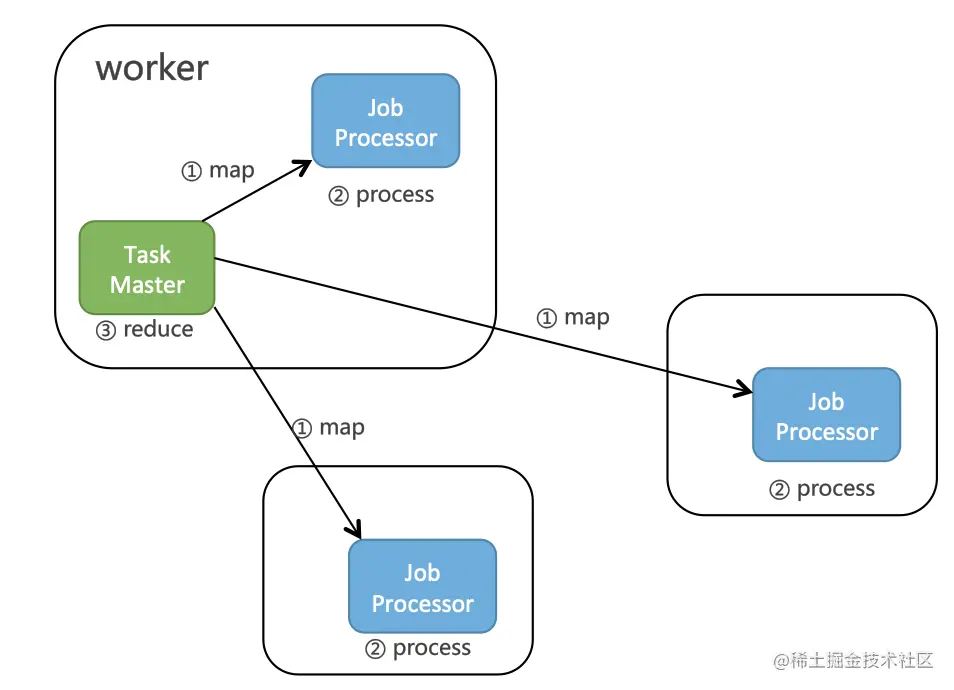
SchedulerX 的 MapReduce 模型,简单几行代码,就可以将海量任务分布式到多台机器跑批,相对于大数据跑批来说,具有速度快、数据安全、成本低、简单易学等特点。
任务编排
SchedulerX 通过工作流进行任务编排,并且提供了一个可视化的界面,操作简单,拖拖拽拽即可配置一个工作流。详细的任务状态图能一目了然看到下游任务为什么没跑,方便定位问题。
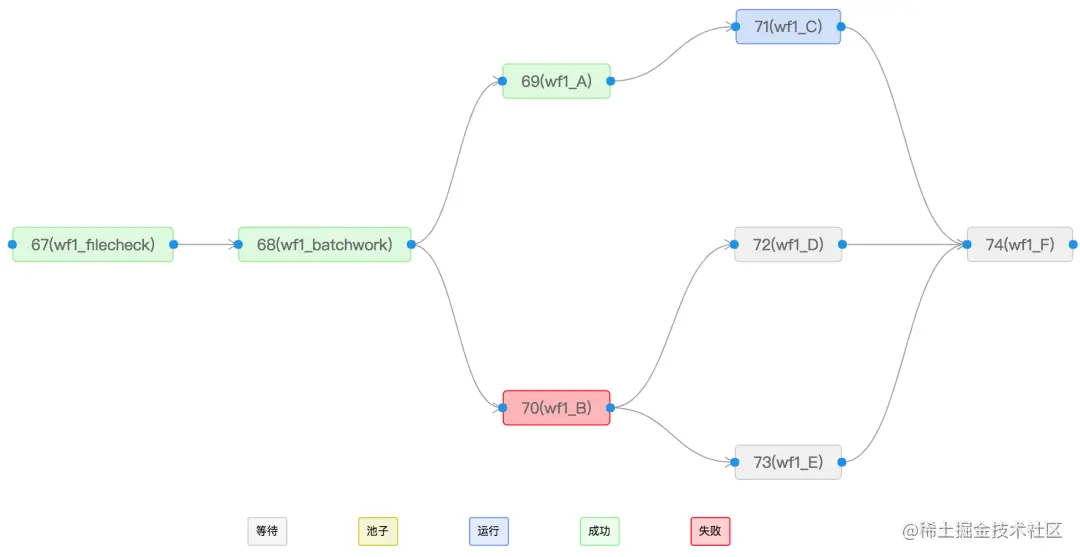
可抢占的任务优先级队列
常见场景是夜间离线报表业务,比如很多报表任务是晚上 1、2 点开始跑,要控制应用最大并发的任务数量(否则业务扛不住),达到并发上限的任务会在队列中等待。同时要求早上 9 点前必须把 KPI 报表跑出来,可以设置 KPI 任务高优先级,会抢占低优先级任务优先调度。
SchedulerX 支持可抢占的任务优先级队列,可以在控制台动态配置:

Q&A
Kubernetes 应用可以接入 SchedulerX 吗?
——可以的,无论是物理机、容器、还是 Kubernetes pod,都可以接入 SchedulerX。
我的应用不在阿里云上,可否使用 SchedulerX?
——可以的,任何云平台或者本地机器,只要能访问公网,都可以接入 SchedulerX。
——可以的,任何云平台或者本地机器,只要能访问公网,都可以接入 SchedulerX。
到此这篇关于Java 定时任务技术趋势详情的文章就介绍到这了,更多相关Java 定时任务内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java单机环境实现定时任务技术
目录 前言 定时任务框架 TimeTask ScheduledExecutorService Spring Task 结语 前言 开发的系统中过程,会有如下的需求: 凌晨生成订单统计报表 定时推送文章.发送邮件 每隔5分钟动态抓取数据更新 每晚定时计算用户当日收益情况并推送给用户 ..... 通常这些需求我们都是通过定时任务来实现,列举了java中一些常用的的定时任务框架. 定时任务框架 TimeTask 从我们开始学习java开始,最先实现定时任务的时候都是采用TimeTask, Timer内
-
Java中Quartz高可用定时任务快速入门
目录 定时任务使用指南 1.引入依赖 2.快速上手 3.手动触发定时任务 4.带参数任务 5.任务并发 6.持久化 定时任务使用指南 如果你想做定时任务,有高可用方面的需求,或者仅仅想入门快,上手简单,那么选用它准没错. 定时任务模块是对Quartz框架进一步封装,使用更加简洁. 1.引入依赖 <dependency> <groupId>xin.altitude.cms</groupId> <artifactId>ucode-cms-quartz</a
-
Java spring定时任务详解
目录 一.定时任务 1.cron表达式 2.cron示例 3.SpringBoot整合 总结 一.定时任务 1.cron表达式 语法:秒 分 时 日 月 周 年 (其中"年"Spring不支持,也就是说在spring定时任务中只能设置:秒 分 时 日 月 周) 2.cron示例 3.SpringBoot整合 @EnableScheduling @Scheduled 实例: package com.xunqi.gulimall.seckill.scheduled; import lomb
-
Java 实现定时任务的三种方法
是的,不用任何框架,用我们朴素的 Java 编程语言就能实现定时任务. 今天,栈长就介绍 3 种实现方法,教你如何使用 JDK 实现定时任务! 1. sleep 这也是我们最常用的 sleep 休眠大法,不只是当作休眠用,我们还可以利用它很轻松的能实现一个简单的定时任务. 实现逻辑: 新开一个线程,添加一个 for/ while 死循环,然后在死循环里面添加一个 sleep 休眠逻辑,让程序每隔 N 秒休眠再执行一次,这样就达到了一个简单定时任务的效果. 实现代码如下: private stat
-
浅析java中常用的定时任务框架-单体
目录 一.阅读收获 二.本章源码下载 三.Timer+TimerTask 四.ScheduledExecutorService 五.Spring Task 5.1 单线程串行执行-@Scheduled 5.2 多线程并发运行-@Scheduled+配置定时器的程池(推荐) 5.3 多线程并发执行-@Scheduled+@Async+配置异步线程池 5.4 @Scheduled参数解析 六.Quartz 6.1. 创建任务类 6.2. 配置任务描述和触发器 一.阅读收获 1. 了解常用的单体应用定
-
java使用@Scheduled注解执行定时任务
前言 在写项目的时候经常需要特定的时间做一些特定的操作,尤其是游戏服务器,维护线程之类的,这时候就需要用到定时器. 如果此时你刚好用的是spring的话,哪么@Scheduled注解是非常好用的. 使用spring @Scheduled注解执行定时任务: 1,在spring-MVC.xml文件中进行配置 2,直接在代码控制层使用即可 package xkhd.game.fix; import org.springframework.beans.factory.annotation.Autowir
-
Java中定时任务的6种实现方式
目录 1.线程等待实现 2.JDK自带Timer实现 2.1 核心方法 2.2使用示例 2.2.1指定延迟执行一次 2.2.2固定间隔执行 2.2.3固定速率执行 2.3 schedule与scheduleAtFixedRate区别 2.3.1schedule侧重保持间隔时间的稳定 2.3.2scheduleAtFixedRate保持执行频率的稳定 2.4 Timer的缺陷 3.JDK自带ScheduledExecutorService 3.1 scheduleAtFixedRate方法 3.2
-
Java 定时任务技术趋势详情
目录 Java 中自带的解决方案 Spring 中自带的解决方案 业务幂等解决方案 开源任务调度中间件 企业级解决方案 定时任务技术趋势简介:定时任务是每个业务常见的需求,比如每分钟扫描超时支付的订单,每小时清理一次数据库历史数据,每天统计前一天的数据并生成报表等等. Java 中自带的解决方案 使用 Timer 创建 java.util.TimerTask 任务,在 run 方法中实现业务逻辑.通过 java.util.Timer 进行调度,支持按照固定频率执行.所有的 TimerTask 是
-
Quartz实现JAVA定时任务的动态配置的方法
先说点无关本文的问题,这段时间特别的不爽,可能有些同学也遇到过.其实也可以说是小事一桩,但感觉也是不容忽视的.我刚毕业时的公司,每个人每次提交代码都有着严格的规范,像table和space的缩进都有严格的要求,可以说你不遵守开发规范就相当于线上bug问题,还是比较严重的.现在发现外面的公司真的是没那么重视这个不重要却又特别重要的问题啊,啊啊啊啊啊啊!!! 什么是动态配置定时任务? 回归正题,说下这次主题,动态配置.没接触过定时任务的同学可以先看下此篇:JAVA定时任务实现的几种方式 定时任务实现
-
解析Java定时任务的选型及改造问题
目录 [前言] [比一比&改一改] 一.项目目前定时任务现状 二.Java主流三大定时任务框架优缺点 三.xxl-job一些特性 四.项目中加入xxl-job结合 [总结] [前言] 项目中用到了定时任务,项目之初为了快速开发上线,当时直接采用最简单的Linux自带的crontab;项目逐渐维定下来时,针对定时任务自己进行了相关研究,并根据项目实际情况进行了对比以及相关改造. [比一比&改一改] 一.项目目前定时任务现状 1. 使用Linux系统的crontab直接调用Java服务 2.
-
总结十个实用但偏执的Java编程技术
前言 当在沉浸于编码一段时间以后(比如说我已经投入近20年左右的时间在程序上了),你会渐渐对这些东西习以为常.因为,你知道的--任何事情有可能出错,没错,的确如此. 这就是为什么我们要采用"防御性编程",即一些偏执习惯的原因.下面是我个人认为的10个最有用但偏执的Java编程技术.一起来看一看吧: 一.将String字符串放在最前面 为了防止偶发性的NullPointerException 异常,我们通常将String放置在equals()函数的左边来实现字符串比较,如下代码: //
-
Java绘图技术的详解及实例
Java绘图技术的详解及实例 简单实例 public class Demo1 extends JFrame{ MyPanel mp=null; public static void main(String[] args){ Demo1 demo=new Demo1(); } public Demo1(){ mp=new MyPanel(); this.add(mp); this.setSize(400,300); this.setDefaultCloseOperation(JFrame.EXIT
-
详解java定时任务
在我们编程过程中如果需要执行一些简单的定时任务,无须做复杂的控制,我们可以考虑使用JDK中的Timer定时任务来实现.下面LZ就其原理.实例以及Timer缺陷三个方面来解析java Timer定时器. 一.简介 在java中一个完整定时任务需要由Timer.TimerTask两个类来配合完成. API中是这样定义他们的,Timer:一种工具,线程用其安排以后在后台线程中执行的任务.可安排任务执行一次,或者定期重复执行.由TimerTask:Timer 安排为一次执行或重复执行的任务.
-
Java绘图技术基础(实例讲解)
如下所示: public class Demo1 extends JFrame{ MyPanel mp=null; public static void main(String[] args){ Demo1 demo=new Demo1(); } public Demo1(){ mp=new MyPanel(); this.add(mp); this.setSize(400,300); this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); th
-
Java动态追踪技术探究之从JSP到Arthas
从JSP说起 对于大多数Java程序员来说,早期的时候,都会接触到一个叫做JSP(Java Server Pages)的技术.虽然这种技术,在前后端代码分离.前后端逻辑分离.前后端组织架构分离的今天来看,已经过时了,但是其中还是有一些有意思的东西,值得拿出来说一说. 当时刚刚处于Java入门时期的我们,大多数精力似乎都放在了JSP的页面展示效果上了: "这个表格显示的行数不对" "原来是for循环写的有问题,改一下,刷新页面再试一遍" "嗯,好了,表格显示
-
Java反射技术原理与用法实例分析
本文实例讲述了Java反射技术原理与用法.分享给大家供大家参考,具体如下: 本文内容: 产生反射技术的需求 反射技术的使用 一个小示例 首发日期:2018-05-10 产生反射技术的需求: 项目完成以后,发现需要增加功能,并且希望增加功能并不需要停止项目运行. 在希望不关停项目运行的情况下,于是考虑到将功能都放到一个单独的项目之外的模块中,每一个功能实现都从这个模块中获取[实际上这个考虑应该是项目开始前就考虑,这个例子可能不是很好].于是就有了反射的产生.(这种思想有点类似工厂模式,如果学过设计