详解Python如何实现尾递归优化
目录
- 一般递归与尾递归
- 一般递归
- 尾递归
- C中尾递归的优化
- Python开启尾递归优化
一般递归与尾递归
一般递归
def normal_recursion(n):
if n == 1:
return 1
else:
return n + normal_recursion(n-1)
执行:
normal_recursion(5)
5 + normal_recursion(4)
5 + 4 + normal_recursion(3)
5 + 4 + 3 + normal_recursion(2)
5 + 4 + 3 + 2 + normal_recursion(1)
5 + 4 + 3 + 3
5 + 4 + 6
5 + 10
15
可以看到, 一般递归, 每一级递归都产生了新的局部变量, 必须创建新的调用栈, 随着递归深度的增加, 创建的栈越来越多, 造成爆栈?
尾递归
尾递归基于函数的尾调用, 每一级调用直接返回递归函数更新调用栈, 没有新局部变量的产生, 类似迭代的实现:
def tail_recursion(n, total=0):
if n == 0:
return total
else:
return tail_recursion(n-1, total+n)
执行:
tail_recursion(5, 0)
tail_recursion(4, 5)
tail_recursion(3, 9)
tail_recursion(2, 12)
tail_recursion(1, 14)
tail_recursion(0, 15)
15
可以看到, 尾递归每一级递归函数的调用变成"线性"的形式. 这时, 我们可以思考, 虽然尾递归调用也会创建新的栈, 但是我们可以优化使得尾递归的每一级调用共用一个栈!, 如此便可解决爆栈和递归深度限制的问题!
C中尾递归的优化
gcc使用-O2参数开启尾递归优化:
int tail_recursion(int n, int total) {
if (n == 0) {
return total;
}
else {
return tail_recursion(n-1, total+n);
}
}
int main(void) {
int total = 0, n = 4;
tail_recursion(n, total);
return 0;
}
反汇编
$ gcc -S tail_recursion.c -o normal_recursion.S
$ gcc -S -O2 tail_recursion.c -o tail_recursion.S gcc开启尾递归优化
对比反汇编代码如下(AT&T语法, 左图为优化后)

可以看到, 开启尾递归优化前, 使用call调用函数, 创建了新的调用栈(LBB0_3); 而开启尾递归优化后, 就没有新的调用栈生成了, 而是直接pop bp指向的_tail_recursion函数的地址(pushq %rbp)然后返回, 仍旧用的是同一个调用栈!
Python开启尾递归优化
cpython本身不支持尾递归优化, 但是一个牛人想出的解决办法:实现一个 tail_call_optimized 装饰器
#!/usr/bin/env python2.4
# This program shows off a python decorator(
# which implements tail call optimization. It
# does this by throwing an exception if it is
# it's own grandparent, and catching such
# exceptions to recall the stack.
import sys
class TailRecurseException:
def __init__(self, args, kwargs):
self.args = args
self.kwargs = kwargs
def tail_call_optimized(g):
"""
This function decorates a function with tail call
optimization. It does this by throwing an exception
if it is it's own grandparent, and catching such
exceptions to fake the tail call optimization.
This function fails if the decorated
function recurses in a non-tail context.
"""
def func(*args, **kwargs):
f = sys._getframe()
if f.f_back and f.f_back.f_back \
and f.f_back.f_back.f_code == f.f_code:
# 抛出异常
raise TailRecurseException(args, kwargs)
else:
while 1:
try:
return g(*args, **kwargs)
except TailRecurseException, e:
args = e.args
kwargs = e.kwargs
func.__doc__ = g.__doc__
return func
@tail_call_optimized
def factorial(n, acc=1):
"calculate a factorial"
if n == 0:
return acc
return factorial(n-1, n*acc)
print factorial(10000)
这里解释一下sys._getframe()函数:
sys._getframe([depth]):Return a frame object from the call stack.
If optional integer depth is given, return the frame object that many calls below the top of the stack.
If that is deeper than the call stack, ValueEfror is raised. The default for depth is zero,
returning the frame at the top of the call stack.
即返回depth深度调用的栈帧对象.
import sys
def get_cur_info():
print sys._getframe().f_code.co_filename # 当前文件名
print sys._getframe().f_code.co_name # 当前函数名
print sys._getframe().f_lineno # 当前行号
print sys._getframe().f_back # 调用者的帧
说一下tail_call_optimized实现尾递归优化的原理: 当递归函数被该装饰器修饰后, 递归调用在装饰器while循环内部进行, 每当产生新的递归调用栈帧时: f.f_back.f_back.f_code == f.f_code:, 就捕获当前尾调用函数的参数, 并抛出异常, 从而销毁递归栈并使用捕获的参数手动调用递归函数. 所以递归的过程中始终只存在一个栈帧对象, 达到优化的目的.
为了更清晰的展示开启尾递归优化前、后调用栈的变化和tail_call_optimized装饰器抛异常退出递归调用栈的作用, 我这里利用pudb调试工具做了动图:
开启尾递归优化前的调用

开启尾递归优化后(tail_call_optimized装饰器)的调用
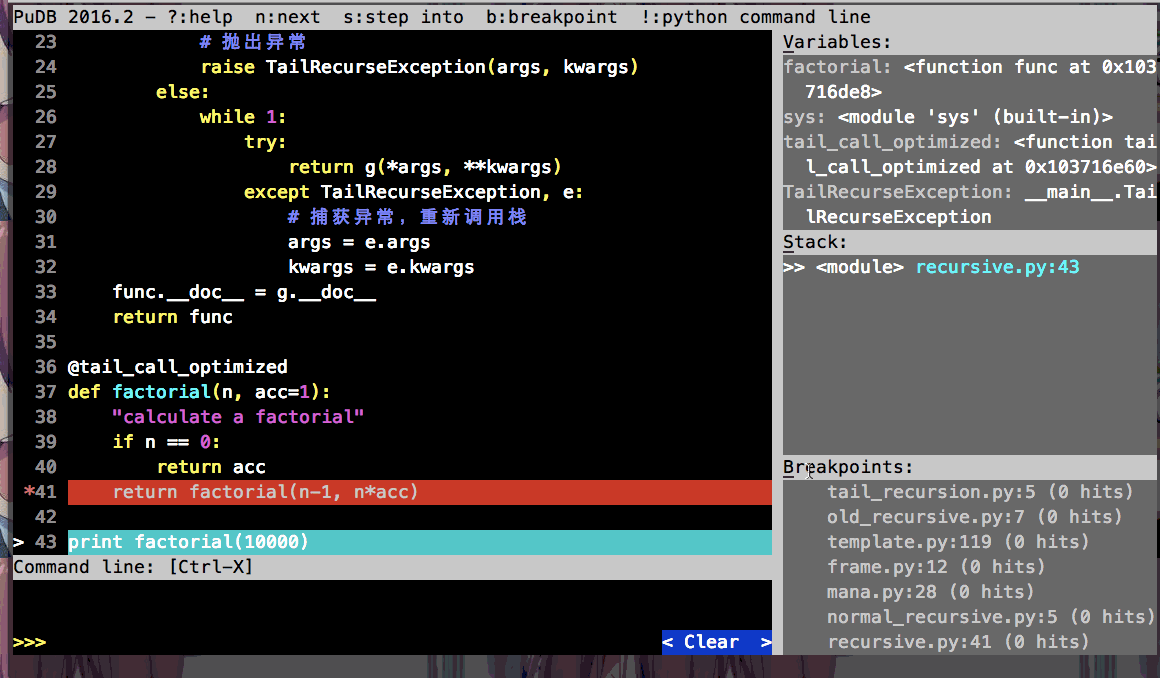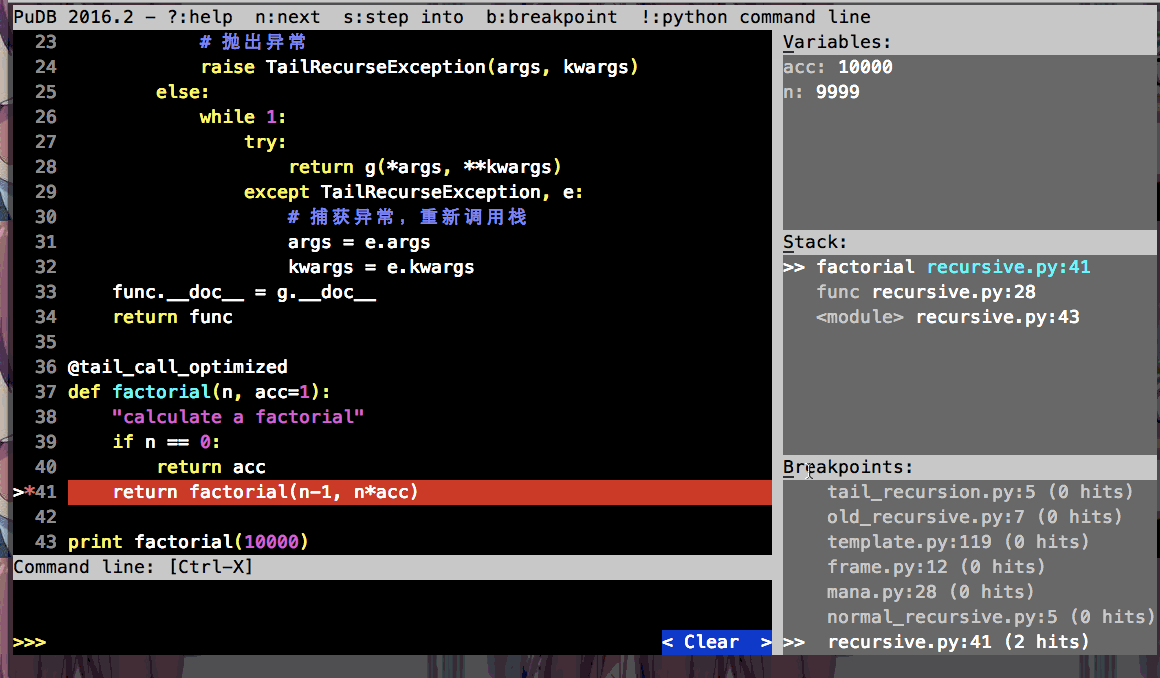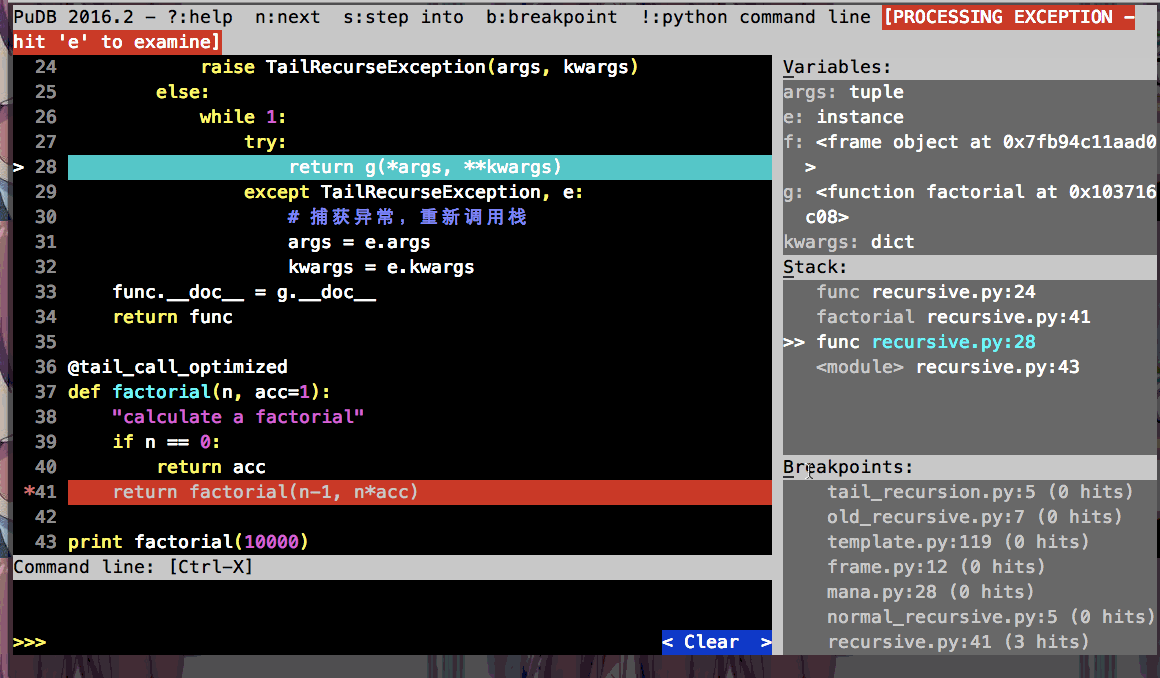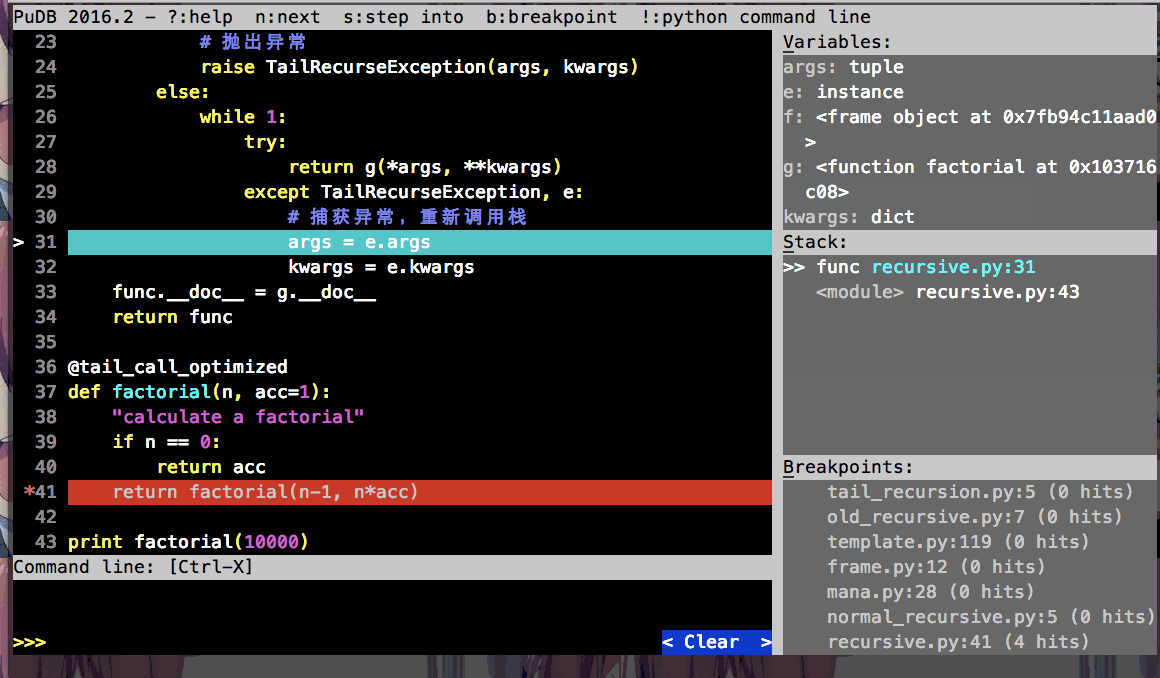
通过pudb右边栏的stack, 可以很清晰的看到调用栈的变化.
因为实现了尾递归优化, 所以factorial(10000)都不害怕递归深度限制报错啦!
到此这篇关于详解Python如何实现尾递归优化的文章就介绍到这了,更多相关Python尾递归优化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python中尾递归用法实例详解
本文实例讲述了python中尾递归用法.分享给大家供大家参考.具体分析如下: 如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的.当递归调用是整个函数体中最后执行的语句且它的返回值不属于表达式的一部分时,这个递归调用就是尾递归.尾递归函数的特点是在回归过程中不用做任何操作,这个特性很重要,因为大多数现代的编译器会利用这种特点自动生成优化的代码. 原理: 当编译器检测到一个函数调用是尾递归的时候,它就覆盖当前的活跃记录而不是在栈中去创建一个新的.编译器可以做到这点,因
-
Python尾递归优化实现代码及原理详解
在传统的递归中,典型的模式是,你执行第一个递归调用,然后接着调用下一个递归来计算结果.这种方式中途你是得不到计算结果,知道所有的递归调用都返回. 这样虽然很大程度上简洁了代码编写,但是让人很难它跟高效联系起来.因为随着递归的深入,之前的一些变量需要分配堆栈来保存. 尾递归相对传统递归,其是一种特例.在尾递归中,先执行某部分的计算,然后开始调用递归,所以你可以得到当前的计算结果,而这个结果也将作为参数传入下一次递归.这也就是说函数调用出现在调用者函数的尾部,因为是尾部,所以其有一个优越于传统递归之
-
详解python使用递归、尾递归、循环三种方式实现斐波那契数列
在最开始的时候所有的斐波那契代码都是使用递归的方式来写的,递归有很多的缺点,执行效率低下,浪费资源,还有可能会造成栈溢出,而递归的程序的优点也是很明显的,就是结构层次很清晰,易于理解 可以使用循环的方式来取代递归,当然也可以使用尾递归的方式来实现. 尾递归就是从最后开始计算, 每递归一次就算出相应的结果, 也就是说, 函数调用出现在调用者函数的尾部, 因为是尾部, 所以根本没有必要去保存任何局部变量. 直接让被调用的函数返回时越过调用者, 返回到调用者的调用者去.尾递归就是把当前的运算结果(或路
-
Python进阶之尾递归的用法实例
作者是一名沉迷于Python无法自拔的蛇友,为提高水平,把Python的重点和有趣的实例发在简书上. 尾递归 如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的.当递归调用是整个函数体中最后执行的语句且它的返回值不属于表达式的一部分时,这个递归调用就是尾递归.尾递归函数的特点是在回归过程中不用做任何操作,这个特性很重要,因为大多数现代的编译器会利用这种特点自动生成优化的代码. (来源于不说人话的某度) 下面是笔者的个人理解:把计算出的值存在函数内部(当然不止尾递归)
-
Python中使用装饰器来优化尾递归的示例
尾递归简介 尾递归是函数返回最后一个操作是递归调用,则该函数是尾递归. 递归是线性的比如factorial函数每一次调用都会创建一个新的栈(last-in-first-out)通过不断的压栈,来创建递归, 很容易导致栈的溢出.而尾递归则使用当前栈通过数据覆盖来优化递归函数. 阶乘函数factorial, 通过把计算值传递的方法完成了尾递归.但是python不支出编译器优化尾递归所以当递归多次的话还是会报错(学习用). eg: def factorial(n, x): if n == 0: ret
-
Python递归及尾递归优化操作实例分析
本文实例讲述了Python递归及尾递归优化操作.分享给大家供大家参考,具体如下: 1.递归介绍 递归简而言之就是自己调用自己.使用递归解决问题的核心就是分析出递归的模型,看这个问题能拆分出和自己类似的问题并且有一个递归出口.比如最简单的就5的阶乘,可以把它拆分成5*4!,然后求4!又可以调用自己,这种问题显然可以用递归解决,递归的出口就是求1!,可以直接返回1.用Python实现如下: def fact(n): if n==1: return n return n*fact(n - 1); pr
-

详解Python如何实现尾递归优化
目录 一般递归与尾递归 一般递归 尾递归 C中尾递归的优化 Python开启尾递归优化 一般递归与尾递归 一般递归 def normal_recursion(n): if n == 1: return 1 else: return n + normal_recursion(n-1) 执行: normal_recursion(5)5 + normal_recursion(4)5 + 4 + normal_recursion(3)5 + 4 + 3 + normal_recursion(2)5 +
-
详解python 内存优化
写在之前 围绕类的话题,说是说不完的,仅在特殊方法,除了我们在前面遇到过的 __init__(),__new__(),__str__() 等之外还有很多.虽然它们只是在某些特殊的场景中才会用到,但是学会它们却可以成为你熟悉这门语言路上的铺路石. 所以我会在试图介绍一些「黑魔法」,让大家多多感受一下 Python 的魅力所在,俗话说「艺多不压身」就是这个道理了. 内存优化 首先先让我们从复习前面的类属性和实例属性的知识来引出另一个特殊方法: >>> class Sample: ... na
-
详解Python中4种超参自动优化算法的实现
目录 一.网格搜索(Grid Search) 二.随机搜索(Randomized Search) 三.贝叶斯优化(Bayesian Optimization) 四.Hyperband 总结 大家好,要想模型效果好,每个算法工程师都应该了解的流行超参数调优技术. 今天我给大家总结超参自动优化方法:网格搜索.随机搜索.贝叶斯优化 和 Hyperband,并附有相关的样例代码供大家学习. 一.网格搜索(Grid Search) 网格搜索是暴力搜索,在给定超参搜索空间内,尝试所有超参组合,最后搜索出最优
-
详解Python中递归函数的原理与使用
目录 什么是递归函数 递归函数的条件 定义一个简单的递归函数 代码解析 内存栈区堆区 死递归 尾递归 实例 什么是递归函数 如果一个函数,可以自己调用自己,那么这个函数就是一个递归函数. 递归,递就是去,归就是回,递归就是一去一回的过程. 递归函数的条件 一般来说,递归需要边界条件,整个递归的结构中要有递归前进段和递归返回段.当边界条件不满足,递归前进,反之递归返回.就是说递归函数一定需要有边界条件来控制递归函数的前进和返回. 定义一个简单的递归函数 # 定义一个函数 def recursion
-
详解Python文本操作相关模块
详解Python文本操作相关模块 linecache--通过使用缓存在内部尝试优化以达到高效从任何文件中读出任何行. 主要方法: linecache.getline(filename, lineno[, module_globals]):获取指定行的内容 linecache.clearcache():清除缓存 linecache.checkcache([filename]):检查缓存的有效性 dircache--定义了一个函数,使用缓存读取目录列表.使用目录的mtime来实现缓存失效.此外还定义
-
详解Python自建logging模块
简单使用 最开始,我们用最短的代码体验一下logging的基本功能. import logging logger = logging.getLogger() logging.basicConfig() logger.setLevel('DEBUG') logger.debug('logsomething') #输出 out>>DEBG:root:logsomething 第一步,通过logging.getLogger函数,获取一个loger对象,但这个对象暂时是无法使用的. 第二步,loggi
-
详解Python中import机制
Python语言中import的使用很简单,直接使用import module_name语句导入即可.这里我主要写一下"import"的本质. Python官方定义: Python code in one module gains access to the code in another module by the process of importing it. 1.定义: 模块(module):用来从逻辑(实现一个功能)上组织Python代码(变量.函数.类),本质就是*.py文
-
详解python 支持向量机(SVM)算法
相比于逻辑回归,在很多情况下,SVM算法能够对数据计算从而产生更好的精度.而传统的SVM只能适用于二分类操作,不过却可以通过核技巧(核函数),使得SVM可以应用于多分类的任务中. 本篇文章只是介绍SVM的原理以及核技巧究竟是怎么一回事,最后会介绍sklearn svm各个参数作用和一个demo实战的内容,尽量通俗易懂.至于公式推导方面,网上关于这方面的文章太多了,这里就不多进行展开了~ 1.SVM简介 支持向量机,能在N维平面中,找到最明显得对数据进行分类的一个超平面!看下面这幅图: 如上图中,
-
详解python的super()的作用和原理
Python中对象方法的定义很怪异,第一个参数一般都命名为self(相当于其它语言的this),用于传递对象本身,而在调用的时候则不必显式传递,系统会自动传递. 今天我们介绍的主角是super(), 在类的继承里面super()非常常用, 它解决了子类调用父类方法的一些问题, 父类多次被调用时只执行一次, 优化了执行逻辑,下面我们就来详细看一下. 举一个例子: class Foo: def bar(self, message): print(message) >>> Foo(
-
详解Python 3.10 中的新功能和变化
随着最后一个alpha版发布,Python 3.10 的功能更改全面敲定! 现在,正是体验Python 3.10 新功能的理想时间!正如标题所言,本文将给大家分享Python 3.10中所有重要的功能和更改. 新功能1:联合运算符 在过去, |符号用于 "算术或"运算,例如: print(0 | 0) print(0 | 1) print({1, 2} | {2, 3}) 输出: 0 1 {1, 2, 3} 在Python 3.10中, |符号有的新语法,可以表示x类型 或 Y类型,以