GoFrame gmap遍历hashmap listmap treemap使用技巧
目录
- 先说结论
- map类型
- 使用技巧
- 基础概念
- 对比sync.Map
- 基础使用
- 合并 merge
- 序列化
- 过滤空值
- 键值对反转 Flip
- 出栈(随机出栈)
- 总结
文章比较硬核,爆肝2千多字,除了hashmap、listmap、treemap使用技巧阅读还有使用gmap的踩坑之旅,阅读大约需要5~10分钟。
先说结论
map类型
一图胜千言:
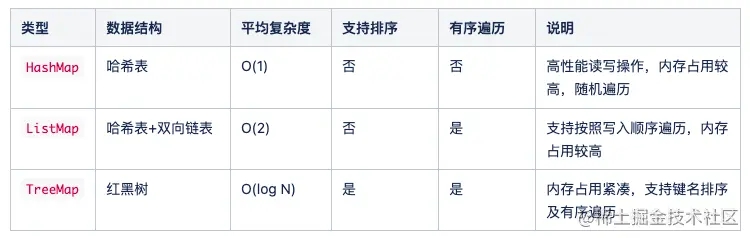
实例化示例:
hashMap := gmap.New(true) listMap := gmap.NewListMap(true) treeMap := gmap.NewTreeMap(gutil.ComparatorInt, true)
使用技巧
当我们对返回顺序有要求时不能使用hashmap,因为hashmap返回的是无序列表;
当需要按输入顺序返回结果时使用listmap;
当需要让返回结果自然升序排列时使用treemap
package main
import (
"fmt"
"github.com/gogf/gf/container/gmap"
"github.com/gogf/gf/frame/g"
"github.com/gogf/gf/util/gutil"
)
func main() {
array := g.Slice{5, 1, 2, 7, 3, 9, 0}
hashMap := gmap.New(true)
listMap := gmap.NewListMap(true)
treeMap := gmap.NewTreeMap(gutil.ComparatorInt, true)
// 赋值
for _, v := range array {
hashMap.Set(v, v)
listMap.Set(v, v)
treeMap.Set(v, v)
}
//打印结果
fmt.Println("hashMap.Keys() :", hashMap.Keys())
fmt.Println("hashMap.Values():", hashMap.Values())
//从打印结果可知hashmap的键列表和值列表返回值的顺序没有规律,随机返回
fmt.Println("listMap.Keys() :", listMap.Keys())
fmt.Println("listMap.Values():", listMap.Values())
//listmap键列表和值列表有序返回,且顺序和写入顺序一致
fmt.Println("treeMap.Keys() :", treeMap.Keys())
fmt.Println("treeMap.Values():", treeMap.Values())
//treemap键列表和值列表也有序返回,但是不和写入顺序一致,按自然数升序返回
}
打印结果
hashMap.Keys() : [5 1 2 7 3 9 0] hashMap.Values(): [2 7 3 9 0 5 1] listMap.Keys() : [5 1 2 7 3 9 0] listMap.Values(): [5 1 2 7 3 9 0] treeMap.Keys() : [0 1 2 3 5 7 9] treeMap.Values(): [0 1 2 3 5 7 9]
为了让大家更好的理解gmap,下面介绍一下gmap的基础使用和一些进阶技巧。
基础概念
GoFrame框架(下文简称gf)提供的数据类型,比如:字典gmap、数组garray、集合gset、队列gqueue、树形结构gtree、链表glist都是支持设置并发安全开关的。
支持设置并发安全开关这也是gf提供的常用数据类型和原生数据类型非常重要的区别
今天和大家分享gf框架中gmap相关知识点
对比sync.Map
go语言提供的原生map不是并发安全的map类型
go语言从1.9版本开始引入了并发安全的sync.Map,但gmap比较于标准库的sync.Map性能更加优异,并且功能更加丰富。
基础使用
- gmap.New(true) 在初始化的时候开启并发安全开关
- 通过 Set() 方法赋值,通过 Sets() 方法批量赋值
- 通过 Size() 方法获取map大小
- 通过 Get() 根据key获取value值
- ...
为了方便大家更好的查看效果,在下方代码段中标明了打印结果
package main
import (
"fmt"
"github.com/gogf/gf/container/gmap"
)
func main() {
m := gmap.New(true)
// 设置键值对
for i := 0; i < 10; i++ {
m.Set(i, i)
}
fmt.Println("查询map大小:", m.Size())
//批量设置键值对
m.Sets(map[interface{}]interface{}{
10: 10,
11: 11,
})
// 目前map的值
fmt.Println("目前map的值:", m)
fmt.Println("查询是否存在键值对:", m.Contains(1))
fmt.Println("根据key获得value:", m.Get(1))
fmt.Println("删除数据", m.Remove(1))
//删除多组数据
fmt.Println("删除前的map大小:", m.Size())
m.Removes([]interface{}{2, 3})
fmt.Println("删除后的map大小:", m.Size())
//当前键名列表
fmt.Println("键名列表:", m.Keys()) //我们发现是无序列表
fmt.Println("键值列表:", m.Values()) //我们发现也是无序列表
//查询键名,当键值不存在时写入默认值
fmt.Println(m.GetOrSet(20, 20)) //返回值是20
fmt.Println(m.GetOrSet(20, "二十")) //返回值仍然是20,因为key对应的值存在
m.Remove(20)
fmt.Println(m.GetOrSet(20, "二十")) //返回值是二十,因为key对应的值不存在
// 遍历map
m.Iterator(func(k interface{}, v interface{}) bool {
fmt.Printf("%v:%v \n", k, v)
return true
})
//自定义写锁操作
m.LockFunc(func(m map[interface{}]interface{}) {
m[88] = 88
})
// 自定义读锁操作
m.RLockFunc(func(m map[interface{}]interface{}) {
fmt.Println("m[88]:", m[88])
})
// 清空map
m.Clear()
//判断map是否为空
fmt.Println("m.IsEmpty():", m.IsEmpty())
}
运行结果

上面介绍的基础使用比较简单,下面介绍进阶使用。
合并 merge
注意:Merge()的参数需要是map的引用类型,也就是传map的取址符。
package main
import (
"fmt"
"github.com/gogf/gf/container/gmap"
)
func main() {
var m1, m2 gmap.Map
m1.Set("k1", "v1")
m2.Set("k2", "v2")
m1.Merge(&m2)
fmt.Println("m1.Map()", m1.Map()) //m1.Map() map[k1:v1 k2:v2]
fmt.Println("m2.Map()", m2.Map()) //m2.Map() map[k2:v2]
}
序列化
正如上一篇 GoFrame glist 基础使用和自定义遍历 介绍的,gf框架提供的数据类型不仅支持设置并发安全,也都支持序列化和反序列化。
json序列化和反序列化:序列化就是转成json格式,反序列化就是json转成其他格式类型(比如:map、数组、对象等)
package main
import (
"encoding/json"
"fmt"
"github.com/gogf/gf/container/gmap"
)
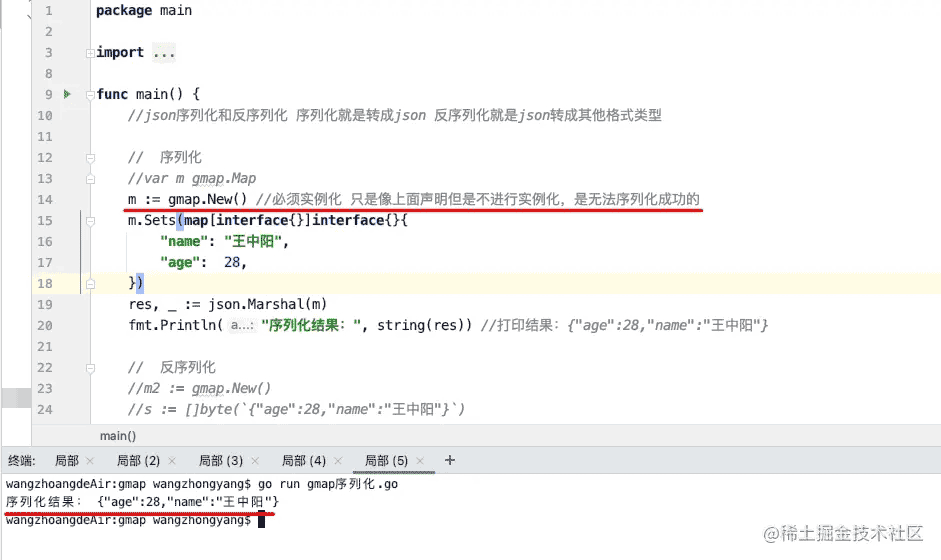
func main() {
// 序列化
//var m gmap.Map
m := gmap.New() //必须实例化 只是像上面声明但是不进行实例化,是无法序列化成功的
m.Sets(map[interface{}]interface{}{
"name": "王中阳",
"age": 28,
})
res, _ := json.Marshal(m)
fmt.Println("序列化结果:", res) //打印结果:{"age":28,"name":"王中阳"}
// 反序列化
m2 := gmap.New()
s := []byte(`{"age":28,"name":"王中阳"}`)
_ = json.Unmarshal(s, &m2)
fmt.Println("反序列化结果:", m2.Map()) //反序列化结果: map[age:28 name:王中阳]
}
踩坑
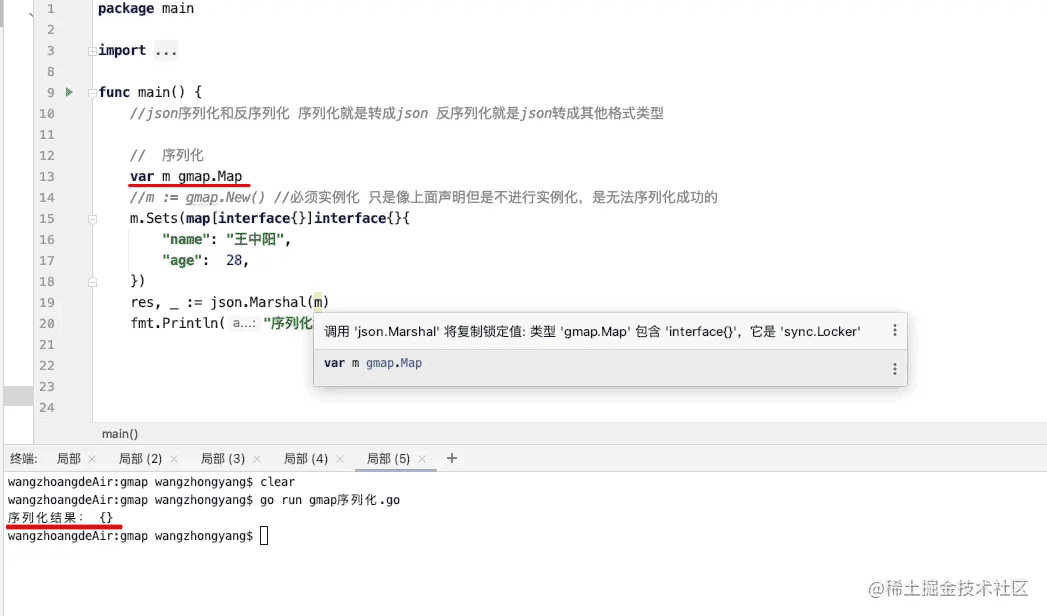
正如上面代码段中注释提到的:
在进行序列化操作时,必须实例化map
m := gmap.New()
只是声明map而不进行实例化,是无法序列化成功的
var m gmap.Map
过滤空值
package main
import (
"fmt"
"github.com/gogf/gf/container/gmap"
)
func main() {
//首先明确:空值和nil是不一样的,nil是未定义;而空值包括空字符串,false、0等
m1 := gmap.NewFrom(map[interface{}]interface{}{
"k1": "",
"k2": nil,
"k3": 0,
"k4": false,
"k5": 1,
})
m2 := gmap.NewFrom(map[interface{}]interface{}{
"k1": "",
"k2": nil,
"k3": 0,
"k4": false,
"k5": 1,
})
m1.FilterEmpty()
m2.FilterNil()
fmt.Println("m1.FilterEmpty():", m1) //预测结果: k5:1
fmt.Println("m2.FilterNil():", m2) //预测结果:除了k2,其他都返回
// 打印结果和预期的一致:
//m1.FilterEmpty(): {"k5":1}
//m2.FilterNil(): {"k1":"","k3":0,"k4":false,"k5":1}
}
打印结果
m1.FilterEmpty(): {"k5":1}
m2.FilterNil(): {"k1":"","k3":0,"k4":false,"k5":1}
键值对反转 Flip
package main
import (
"github.com/gogf/gf/container/gmap"
"github.com/gogf/gf/frame/g"
)
func main() {
// 键值对反转flip
var m gmap.Map
m.Sets(map[interface{}]interface{}{
"k1": "v1",
"k2": "v2",
})
fmt.Println("反转前:", m.Map())
m.Flip()
fmt.Println("反转后:", m.Map())
}
打印结果
反转前:{
"k1": "v1",
"k2": "v2"
}
反转后:{
"v1": "k1",
"v2": "k2"
}
出栈(随机出栈)
package main
import (
"fmt"
"github.com/gogf/gf/container/gmap"
)
func main() {
//pop pops map出栈(弹栈)
var m gmap.Map
m.Sets(map[interface{}]interface{}{
1: 1,
2: 2,
3: 3,
4: 4,
5: 5,
})
fmt.Println("m.Pop()之前:", m.Map())
key, value := m.Pop()
fmt.Println("key:", key)
fmt.Println("value:", value)
fmt.Println("m.Pop()之后:", m.Map()) //多次测试后发现是随机出栈,不能理所当然的认为按顺序出栈
res := m.Pops(2) //参数是出栈个数
fmt.Println("res:", res)
fmt.Println("m.Pops之后:", m.Map()) //多次测试之后发现也是随机出栈
}
运行结果

踩坑
注意:多次测试后发现是随机出栈,不能理所当然的认为按顺序出栈
总结
通过这篇文章,我们了解到:
重点消化一下map遍历时,不同map的特点:
- 1.1 当我们对返回顺序有要求时不能使用hashmap,因为hashmap返回的是无序列表;
- 1.2 当需要按输入顺序返回结果时使用listmap;
- 1.3 当需要让返回结果自然升序排列时使用treemap
gmap的基础使用和进阶使用技巧:反转map、序列化、合并map、出栈等。
gf框架提供的数据结构,比如:字典gmap、数组garray、集合gset、队列gqueue、树形结构gtree、链表glist 都是支持设置并发安全开关的;而且都支持序列化和反序列化,实现了标准库json数据格式的序列化/反序列化接口。
以上就是GoFrame gmap遍历hashmap listmap treemap使用技巧的详细内容,更多关于GoFrame gmap遍历的资料请关注我们其它相关文章!
相关推荐
-

GoFrame框架Scan类型转换实例
目录 前言 方法定义 自动识别转换Struct结构体 示例代码 运行结果 自动识别转换Struct数组 示例代码 运行结果 自动识别转换Map 示例代码 运行结果 自动识别转换Map数组 示例代码 运行结果 总结 前言 Scan转换方法可以实现对任意参数到struct/struct数组/map/map数组的转换,并且根据开发者输入的转换目标参数自动识别执行转换. 方法定义 // Scan automatically calls MapToMap, MapToMaps, Struct or Str
-
GoFrame通用类型变量gvar与interface基本使用对比
目录 前言摘要 通用变量 gvar 使用场景 看源码学编程 如何设置并发安全开关呢? 基本使用 打印结果 序列化示例 打印结果 总结 前言摘要 这篇文章将介绍 GoFrame 通用类型变量gvar的概念,对比 interface{}的特点:以及如何设置gvar的并发安全开关等基础使用:介绍序列化示例代码. 通用变量 gvar gvar 通用动态变量,支持各种内置的数据类型转换,可以作为interface{}类型的替代数据类型,并且该类型支持并发安全开关. 使用场景 所有需要使用interface
-
GoFrame框架garray并发安全数组使用开箱体验
目录 前言 普通数组 Append At Chunk Clear Clone PopLefts 总结 前言 今天在搞一个需求,从三方获得有信息变更的商品,更新自己的数据库,再推送给下游进行商品更新. 期间有更新商品数量不确定,为了保证程序稳定性,每组向下游推送20个商品id. 查了garray的文档,发现支持Chunk()方法,灰常好用. func commonSendMessage(goodsIds *garray.IntArray, messageType int) { goodsIdsCh
-
GoFrame glist 基础使用和自定义遍历
目录 join 序列化和反序列化 基础概念 GoFrame框架(下文简称gf)提供的数据类型,比如:字典gmap.数组garray.集合gset.队列gqueue.树形结构gtree.链表glist都是支持设置并发安全开关的. 支持设置并发安全开关这也是gf提供的常用数据类型和原生数据类型非常重要的区别 今天和大家分享gf框架的glist详解: 基本使用 glist的使用场景是:双向链表 通过PushBack向链表尾部插入数据 通过PushFront向链表头部插入数据 通过InsertBefor
-
GoFrame ORM原生方法操作示例
目录 前言 常用方法 SQL操作方法,返回原生的标准库sql对象 数据表记录查询: 数据单条操作 数据修改/删除 总结 前言 最近一直在用GoFrame(下文简称gf)来开发项目,在熟悉业务逻辑之后就是马不停蹄的撸代码了. 之前整理过结构体和json转换的文章:GoFrame必知必会之Scan:类型转换,今天整理同样比较重要的ORM相关的文章. gf是支持ORM原生操作的,在ORM链式操作执行不了太过于复杂的SQL操作时,可以交给方法操作来处理. 这篇文章整理原生操作的常用方法,下篇文章根据整理
-
Go Frame gtree树形结构的使用技巧示例
目录 树形结构 一图胜千言 查询源码 使用场景 使用入门 常用方法 示例代码 打印结果 技巧 树形结构 树形结构gtree具有以下特点: 支持排序,支持有序遍历 内存占用低 复杂度稳定 适合大数据量存储 一图胜千言 查询源码 使用场景 关联数组场景 大数据量内存CRUD 排序键值对(后面的示例就是前序遍历和后序遍历) 使用入门 我们以实例化红黑树为例(实例化B树.高度平衡树也是一样的方式) 常用方法 Set() 赋值 Keys() 获得键列表 Values() 获得值列表 Contains()
-
goFrame的队列gqueue对比channel使用详解
目录 channel gqueue 概念 使用场景: 代码演示 打印结果 优势 底层实现 阻止进程销毁 运行结果 总结 channel 首先明确一下channel的作用:用于go协程间的通信. go语言最大的特点就是支持高并发:goroutine和channel是支持高并发的重要组成部分. 单纯地将函数并发执行是没有意义的.函数与函数间需要交换数据才能体现并发执行函数的意义. 如果说 goroutine 是Go程序并发的执行体,channel就是它们之间的连接.channel是可以让一个 gor
-
GoFrame gmap遍历hashmap listmap treemap使用技巧
目录 先说结论 map类型 使用技巧 基础概念 对比sync.Map 基础使用 合并 merge 序列化 过滤空值 键值对反转 Flip 出栈(随机出栈) 总结 文章比较硬核,爆肝2千多字,除了hashmap.listmap.treemap使用技巧阅读还有使用gmap的踩坑之旅,阅读大约需要5~10分钟. 先说结论 map类型 一图胜千言: 实例化示例: hashMap := gmap.New(true) listMap := gmap.NewListMap(true) treeMap := g
-
在Java中如何决定使用 HashMap 还是 TreeMap
HashMap简单总结: 1.HashMap 是链式数组(存储链表的数组)实现查询速度可以,而且能快速的获取key对应的value: 2.查询速度的影响因素有 容量和负载因子,容量大负载因子小查询速度快但浪费空间,反之则相反: 3.数组的index值是(key 关键字, hashcode为key的哈希值, len 数组的大小):hashcode%len的值来确定,如果容量大负载因子小则index相同(index相同也就是指向了同一个桶)的概率小,链表长度小则查询速度快,反之index相同的概率大
-
Java 详解Map集合之HashMap和TreeMap
目录 HashMap 创建HashMap 添加元素 访问元素 删除元素 TreeMap 创建TreeMap 添加元素 访问元素 删除元素 HashMap.TreeMap区别 Map接口储存一组成对的键-值对象,提供key(键)到value(值)的映射,Map中的key不要求有序,不允许重复.value同样不要求有序,但可以重复.最常见的Map实现类是HashMap,他的储存方式是哈希表,优点是查询指定元素效率高. Map接口被HashMap和TreeMap两个类实现. HashMap HashM
-
java遍历HashMap简单的方法
本文实例讲述了java遍历HashMap简单的方法.分享给大家供大家参考.具体实现方法如下: import java.util.HashMap; import java.util.Iterator; import java.util.Set; public class HashSetTest { public static void main(String[] args) { HashMap map = new HashMap(); map.put("a", "aa"
-
使用多种方式实现遍历HashMap的方法
今天讲解的主要是使用多种方式来实现遍历HashMap取出Key和value,首先在java中如果想让一个集合能够用for增强来实现迭代,那么此接口或类必须实现Iterable接口,那么Iterable究竟是如何来实现迭代的,在这里将不做讲解,下面主要讲解一下遍历过程. //定义一个泛型集合 Map<String, String> map = new HashMap<String, String>(); //通过Map的put方法向集合中添加数据 map.put("001&
-
HashMap vs TreeMap vs Hashtable vs LinkedHashMap
Map是一个重要的数据结构,本篇文章将介绍如何使用不同的Map,如HashMap,TreeMap,HashTable和LinkedHashMap. Map概览 Java中有四种常见的Map实现,HashMap,TreeMap,HashTable和LinkedHashMap,我们可以使用一句话来描述各个Map,如下: HashMap:基于散列表实现,是无序的:TreeMap:基于红黑树实现,按Key排序:LinkedHashMap:保存了插入顺序:Hashtable:是同步的,与HashMap类似
-
Java5种遍历HashMap数据的写法
本文介绍了最好的Java5种遍历HashMap数据的写法,分享给大家,也给自己留一个笔记,具体如下: 通过EntrySet的迭代器遍历 Iterator < Entry < Integer, String >> iterator = coursesMap.entrySet().iterator(); while (iterator.hasNext()) { Entry < Integer, String > entry = iterator.next(); System
-
Java中HashMap和TreeMap的区别深入理解
首先介绍一下什么是Map.在数组中我们是通过数组下标来对其内容索引的,而在Map中我们通过对象来对对象进行索引,用来索引的对象叫做key,其对应的对象叫做value.这就是我们平时说的键值对. HashMap通过hashcode对其内容进行快速查找,而 TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的). HashMap 非线程安全 TreeMap 非线程安全 线程安全 在Java里,线程安全一般体
-
Java HashMap 如何正确遍历并删除元素的方法小结
(一)HashMap的遍历 HashMap的遍历主要有两种方式: 第一种采用的是foreach模式,适用于不需要修改HashMap内元素的遍历,只需要获取元素的键/值的情况. HashMap<K, V> myHashMap; for (Map.entry<K, V> item : myHashMap.entrySet()){ K key = item.getKey(); V val = item.getValue(); //todo with key and val //WARNI
-
java HashMap,TreeMap与LinkedHashMap的详解
java HashMap,TreeMap与LinkedHashMap的详解 今天上午面试的时候 问到了Java,Map相关的事情,我记错了HashMap和TreeMap相关的内容,回来赶紧尝试了几个demo理解下 package Map; import java.util.*; public class HashMaps { public static void main(String[] args) { Map map = new HashMap(); map.put("a", &