14个用Python实现的Excel常用操作总结
目录
- 前言
- 一、关联公式:Vlookup
- 二、数据透视表
- 三、对比两列差异
- 四、去除重复值
- 五、缺失值处理
- 六、多条件筛选
- 七、 模糊筛选数据
- 八、分类汇总
- 九、条件计算
- 十、删除数据间的空格
- 十一、数据分列
- 十二、异常值替换
- 十三、分组
- 十四、根据业务逻辑定义标签
前言
自从学了Python后就逼迫自己不用Excel,所有操作用Python实现。目的是巩固Python,与增强数据处理能力。
这也是我写这篇文章的初衷。废话不说了,直接进入正题。
数据是网上找到的销售数据,长这样:
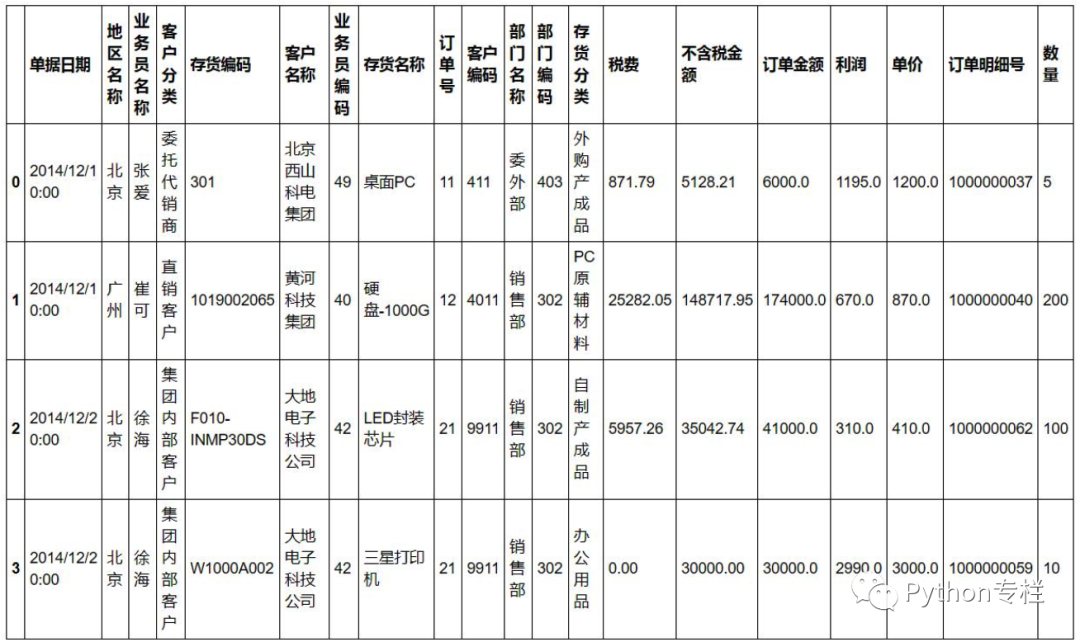
一、关联公式:Vlookup
vlookup是excel几乎最常用的公式,一般用于两个表的关联查询等。所以我先把这张表分为两个表。
df1=sale[['订单明细号','单据日期','地区名称', '业务员名称','客户分类', '存货编码', '客户名称', '业务员编码', '存货名称', '订单号', '客户编码', '部门名称', '部门编码']] df2=sale[['订单明细号','存货分类', '税费', '不含税金额', '订单金额', '利润', '单价','数量']]
需求:想知道df1的每一个订单对应的利润是多少。
利润一列存在于df2的表格中,所以想知道df1的每一个订单对应的利润是多少。用excel的话首先确认订单明细号是唯一值,然后在df1新增一列写:=vlookup(a2,df2!a:h,6,0) ,然后往下拉就ok了。(剩下13个我就不写excel啦)
那用python是如何实现的呢?
#查看订单明细号是否重复,结果是没。 df1["订单明细号"].duplicated().value_counts() df2["订单明细号"].duplicated().value_counts() df_c=pd.merge(df1,df2,on="订单明细号",how="left")
二、数据透视表
需求:想知道每个地区的业务员分别赚取的利润总和与利润平均数。
pd.pivot_table(sale,index="地区名称",columns="业务员名称",values="利润",aggfunc=[np.sum,np.mean])
三、对比两列差异
因为这表每列数据维度都不一样,比较起来没啥意义,所以我先做了个订单明细号的差异再进行比较。
需求:比较订单明细号与订单明细号2的差异并显示出来。
sale["订单明细号2"]=sale["订单明细号"] #在订单明细号2里前10个都+1. sale["订单明细号2"][1:10]=sale["订单明细号2"][1:10]+1 #差异输出 result=sale.loc[sale["订单明细号"].isin(sale["订单明细号2"])==False]
四、去除重复值
需求:去除业务员编码的重复值
sale.drop_duplicates("业务员编码",inplace=True)
五、缺失值处理
先查看销售数据哪几列有缺失值。
#列的行数小于index的行数的说明有缺失值,这里客户名称329<335,说明有缺失值 sale.info()

需求:用0填充缺失值或则删除有客户编码缺失值的行。实际上缺失值处理的办法是很复杂的,这里只介绍简单的处理方法,若是数值变量,最常用平均数或中位数或众数处理,比较复杂的可以用随机森林模型根据其他维度去预测结果填充。若是分类变量,根据业务逻辑去填充准确性比较高。比如这里的需求填充客户名称缺失值:就可以根据存货分类出现频率最大的存货所对应的客户名称去填充。
这里我们用简单的处理办法:用0填充缺失值或则删除有客户编码缺失值的行。
#用0填充缺失值 sale["客户名称"]=sale["客户名称"].fillna(0) #删除有客户编码缺失值的行 sale.dropna(subset=["客户编码"])
六、多条件筛选
需求:想知道业务员张爱,在北京区域卖的商品订单金额大于6000的信息。
sale.loc[(sale["地区名称"]=="北京")&(sale["业务员名称"]=="张爱")&(sale["订单金额"]>5000)]
七、 模糊筛选数据
需求:筛选存货名称含有"三星"或则含有"索尼"的信息。
sale.loc[sale["存货名称"].str.contains("三星|索尼")]
八、分类汇总
需求:北京区域各业务员的利润总额。
sale.groupby(["地区名称","业务员名称"])["利润"].sum()
九、条件计算
需求:存货名称含“三星字眼”并且税费高于1000的订单有几个?这些订单的利润总和和平均利润是多少?(或者最小值,最大值,四分位数,标注差)
sale.loc[sale["存货名称"].str.contains("三星")&(sale["税费"]>=1000)][["订单明细号","利润"]].describe()

十、删除数据间的空格
需求:删除存货名称两边的空格。
sale["存货名称"].map(lambda s :s.strip(""))
十一、数据分列

需求:将日期与时间分列。
sale=pd.merge(sale,pd.DataFrame(sale["单据日期"].str.split(" ",expand=True)),how="inner",left_index=True,right_index=True)
十二、异常值替换
首先用describe()函数简单查看一下数据有无异常值。
#可看到销项税有负数,一般不会有这种情况,视它为异常值。 sale.describe()

需求:用0代替异常值。
sale["订单金额"]=sale["订单金额"].replace(min(sale["订单金额"]),0)
十三、分组
需求:根据利润数据分布把地区分组为:"较差","中等","较好","非常好"
首先,当然是查看利润的数据分布呀,这里我们采用四分位数去判断。
sale.groupby("地区名称")["利润"].sum().describe()

根据四分位数把地区总利润为[-9,7091]区间的分组为“较差”,(7091,10952]区间的分组为"中等" (10952,17656]分组为较好,(17656,37556]分组为非常好。
#先建立一个Dataframe
sale_area=pd.DataFrame(sale.groupby("地区名称")["利润"].sum()).reset_index()
#设置bins,和分组名称
bins=[-10,7091,10952,17656,37556]
groups=["较差","中等","较好","非常好"]
#使用cut分组
#sale_area["分组"]=pd.cut(sale_area["利润"],bins,labels=groups)
十四、根据业务逻辑定义标签
需求:销售利润率(即利润/订单金额)大于30%的商品信息并标记它为优质商品,小于5%为一般商品。
sale.loc[(sale["利润"]/sale["订单金额"])>0.3,"label"]="优质商品" sale.loc[(sale["利润"]/sale["订单金额"])<0.05,"label"]="一般商品"
其实excel常用的操作还有很多,我就列举了14个自己比较常用的,若还想实现哪些操作可以评论一起交流讨论,另外我自身也知道我写python不够精简,惯性使用loc。(其实query会比较精简)。若大家对这几个操作有更好的写法请务必评论告知我,感谢!
最后想说说,我觉得最好不要拿excel和python做对比,去研究哪个好用,其实都是工具,excel作为最为广泛的数据处理工具,垄断这么多年必定在数据处理方便也是相当优秀的,有些操作确实python会比较简单,但也有不少excel操作起来比python简单的。
比如一个很简单的操作:对各列求和并在最下一行显示出来,excel就是对一列总一个sum()函数,然后往左一拉就解决,而python则要定义一个函数(因为python要判断格式,若非数值型数据直接报错。)
以上就是14个用Python实现的Excel常用操作总结的详细内容,更多关于Python Excel操作的资料请关注我们其它相关文章!
相关推荐
-

利用Python操作excel表格的完美指南
目录 主旨 环境 安装模块 新建excel 单元格写入数据 合并单元格 居中显示 修改字体和颜色 总结 主旨 在日常工作中,我们会经常且频繁的使用excel表格,那么我们是否可以通过python来操作excel表格,让其自动化的来代替我们的工作呢?比如涉及到的居中.合并单元格.修改字体颜色等. 环境 linux 服务器一台,亦或者windows10电脑一台python3.7.1版本,python3.x的都可以 安装模块 操作excel需要用到的模块是“xlwt”,我们需要使用python中的pi
-
python办公自动化之excel的操作
准备 使用 Python 操作 Excel 文件,常见的方式如下: xlrd / xlwt openpyxl Pandas xlsxwriter xlwings pywin32 xlrd 和 xlwt 是操作 Excel 文件最多的两个依赖库 其中, xlrd 负责读取 Excel 文件,xlwt 可以写入数据到 Excel 文件 我们安装这两个依赖库 # 安装依赖库 pip3 install xlrd pip3 install xlwt xlrd 读取 Excel 使用 xlrd 中的 o
-
Python操作Excel的学习笔记
用 xlrd 模块读取 Excel xlrd 安装 cmd 中输入pip install xlrd 即可安装 xlrd 模块 若失败请自行百度"python配置环境变量" xlrd 常用函数 打开,加载工作簿 import xlrd data = xlrd.open_workbook("data1.xls") # 打开并加载,返回工作簿对象 print(data.sheet_loaded(0)) # 是否加载完成 data.unload_sheet(0) # 卸载
-
分享11个Python自动化操作Excel的方法
目录 一.openpyxl是什么 二.openpyxl安装 三.openpyxl操作指南 1.创建工作簿 2.写工作簿 3.插入图片 4.删除行和列 5.将工作表转换为数据框 6.2D区域图 7.雷达图 8.使用公式 9.给单元格设定字体颜色 10.设定字体和大小 11.设定单元格的边框.字体.颜色.大小和边框背景色 前言: 今天我教大家如何利用Python自动化操作Excel,包括:介绍操作Excel的工具包.安装方法及操作Excel具体方法.对于每天有大量重复性工作的同学来说,这款工具绝对是
-
Python对excel的基本操作方法
1. 前言 本文是通过Python的第三方库openpyxl, 该库根据官方介绍是支持Excel 2010 的 xlsx/xlsm/xltx/xltm格式文件,哪个版本的这些格式应该都可以支持. 作为网络攻城狮的我们,使用python对excel的基本操作技能就可以了,当然能够精通更好了. 那我们使用openpyxl有何作用?我是想后面跟大家分享一篇批量备份网络设备配置的文章,里面会涉及到对excel的操作,就提前给大家分享下如何操作基本的excel,顺便巩固下自己的知识. 来来来,先看下如下图
-
Python自动操作Excel文件的方法详解
目录 工具 读取Excel文件内容 写入Excel文件内容 Excel文件样式调整 设置表头的位置 设置单元格的宽高 总结 工具 python3.7 Pycharm Excel xlwt&xlrd 读取Excel文件内容 当前文件夹下有一个名为“股票数据.xlsx”的Excel文件,可以按照下列代码方式来操作它. import xlrd # 使用xlrd模块的open_workbook函数打开指定Excel文件并获得Book对象(工作簿) wb = xlrd.open_workbook('股票数
-
Python 操作 Excel 之 openpyxl 模块
目录 1.打开已有 Excel 文件 2.创建一个 Excel 文件,并修改 sheet 3.选择 sheet 的不同方式 4.Worksheet对象 5.Cell 对象 6.单元格插入图像 7.设置单元格样式 正式开始前依旧是模块的安装,使用如下命令即可实现: pip install openpyxl 官方对于该库的描述是: A Python library to read/write Excel 2010 xlsx/xlsm files 一款用于读写 Excel 2010 xlsx/xlsm
-
14个用Python实现的Excel常用操作总结
目录 前言 一.关联公式:Vlookup 二.数据透视表 三.对比两列差异 四.去除重复值 五.缺失值处理 六.多条件筛选 七. 模糊筛选数据 八.分类汇总 九.条件计算 十.删除数据间的空格 十一.数据分列 十二.异常值替换 十三.分组 十四.根据业务逻辑定义标签 前言 自从学了Python后就逼迫自己不用Excel,所有操作用Python实现.目的是巩固Python,与增强数据处理能力. 这也是我写这篇文章的初衷.废话不说了,直接进入正题. 数据是网上找到的销售数据,长这样: 一.关联公式:
-
python数据类型_字符串常用操作(详解)
这次主要介绍字符串常用操作方法及例子 1.python字符串 在python中声明一个字符串,通常有三种方法:在它的两边加上单引号.双引号或者三引号,如下: name = 'hello' name1 = "hello bei jing " name2 = '''hello shang hai haha''' python中的字符串一旦声明,是不能进行更改的,如下: #字符串为不可变变量,即不能通过对某一位置重新赋值改变内容 name = 'hello' name[0] = 'k' #通
-
Python pandas对excel的操作实现示例
最近经常看到各平台里都有Python的广告,都是对excel的操作,这里明哥收集整理了一下pandas对excel的操作方法和使用过程.本篇介绍 pandas 的 DataFrame 对列 (Column) 的处理方法.示例数据请通过明哥的gitee进行下载. 增加计算列 pandas 的 DataFrame,每一行或每一列都是一个序列 (Series).比如: import pandas as pd df1 = pd.read_excel('./excel-comp-data.xlsx');
-
python pymysql库的常用操作
批量插入 import pymysql def insert_to_mysql(to_db_list): mysql_db = pymysql.connect(host="HOST_IP", port=3306, user="username", password="password", database="db", charset="utf8") cursor = mysql_db.cursor() sq
-
Python学习之字符串常用操作详解
目录 1.查找字符串 2.分割字符串 3.连接字符串 4.替换字符串 5.移除字符串的首尾字符 6.转换字符串的大小写 7.检测字符串(后续还会更新) 1.查找字符串 除了使用index()方法在字符串中查找指定元素,还可以使用find()方法在一个较长的字符串中查找子串.如果找到子串,返回子串所在位置的最左端索引,否则返回-1. 语法格式: str.find(sub[,start[,end]]) 其中,str表示被查找的字符串.sub表示查找的子串.start表示开始索引,缺省时为0.end表
-
Python中列表的常用操作详解
目录 打印出列表的数据 一.列表的循环遍历 1.for循环遍历 2.while循环遍历 二.列表的添加操作 1.append() 2.extend() 3.insert() 三.列表的修改操作 四.列表的查找 1.in 2.not in 3.index 4.count 五.列表中的删除 1.del 2.pop 3.remove 六.列表的排序操作 1.排序sort() 2.reverse方法是将内容顺序反转 总结 列表的格式:变量A的类型为列表 namesList = ['xiaoWang','
-
python中字典dict常用操作方法实例总结
本文实例总结了python中字典dict常用操作方法.分享给大家供大家参考.具体如下: 下面的python代码展示python中字典的常用操作,字典在python开发中有着举足轻重的地位,掌握字典操作相当重要 #创建一空字典 x = {} #创建包含三个项目的字典 x = {"one":1, "two":2, "three":3} #访问其中的一个元素 x['two'] #返回字典中的所有键列表 x.keys() #返回字典中的所有值列表 x.v
-
Python中快速掌握Data Frame的常用操作
掌握Data Frame的常用操作 一. 查看DataFrame的常用属性 DataFrame基础属性有:values(元素).index(索引).columns(列名) .dtypes(类型).size(元素个数).ndim(维度数)和 shape(形状大小尺寸),还有使用T属性 进行转置 import pandas as pd detail=pd.read_excel('E:\data\meal_order_detail.xlsx') #读取数据,使用read_excel 函数调用 # pr
-
Python 自动化常用操作大全
目录 1. OS模块 2. shutil模块 3. globa模块 glob的几种用法 本文摘自微信公众号 GitPython:十个 Python 自动化常用操作.如有侵权,联系必删. 1. OS模块 导入:import os 1. 遍历文件夹 批量操作的前提就是对文件夹进行遍历,os.walk遍历文件夹后产生三个参数: 当前文件夹路径 包含文件夹的名称(列表形式) 包含文件名称(列表形式) 代码如下(按需求更改目标路径即可): for dirpath, dirnames, filenames