通过源代码分析Mybatis的功能流程详解
SQL解析
Mybatis在初始化的时候,会读取xml中的SQL,解析后会生成SqlSource对象,SqlSource对象分为两种。
DynamicSqlSource,动态SQL,获取SQL(getBoundSQL方法中)的时候生成参数化SQL。RawSqlSource,原始SQL,创建对象时直接生成参数化SQL。
因为RawSqlSource不会重复去生成参数化SQL,调用的时候直接传入参数并执行,而DynamicSqlSource则是每次执行的时候参数化SQL,所以RawSqlSource是DynamicSqlSource的性能要好的。
解析的时候会先解析include标签和selectkey标签,然后判断是否是动态SQL,判断取决于以下两个条件:
- SQL中有动态拼接字符串,简单来说就是是否使用了
${}表达式。注意这种方式存在SQL注入,谨慎使用。 - SQL中有
trim、where、set、foreach、if、choose、when、otherwise、bind标签
相关代码如下:
protected MixedSqlNode parseDynamicTags(XNode node) {
// 创建 SqlNode 数组
List<SqlNode> contents = new ArrayList<>();
// 遍历 SQL 节点的所有子节点
NodeList children = node.getNode().getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
// 当前子节点
XNode child = node.newXNode(children.item(i));
// 如果类型是 Node.CDATA_SECTION_NODE 或者 Node.TEXT_NODE 时
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
// 获得内容
String data = child.getStringBody("");
// 创建 TextSqlNode 对象
TextSqlNode textSqlNode = new TextSqlNode(data);
// 如果是动态的 TextSqlNode 对象(是否使用了${}表达式)
if (textSqlNode.isDynamic()) {
// 添加到 contents 中
contents.add(textSqlNode);
// 标记为动态 SQL
isDynamic = true;
// 如果是非动态的 TextSqlNode 对象
} else {
// 创建 StaticTextSqlNode 添加到 contents 中
contents.add(new StaticTextSqlNode(data));
}
// 如果类型是 Node.ELEMENT_NODE,其实就是XMl中<where>等那些动态标签
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
// 根据子节点的标签,获得对应的 NodeHandler 对象
String nodeName = child.getNode().getNodeName();
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler == null) { // 获得不到,说明是未知的标签,抛出 BuilderException 异常
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
// 执行 NodeHandler 处理
handler.handleNode(child, contents);
// 标记为动态 SQL
isDynamic = true;
}
}
// 创建 MixedSqlNode 对象
return new MixedSqlNode(contents);
}
参数解析
Mybais中用于解析Mapper方法的参数的类是ParamNameResolver,它主要做了这些事情:
- 每个Mapper方法第一次运行时会去创建
ParamNameResolver,之后会缓存 - 创建时会根据方法签名,解析出参数名,解析的规则顺序是
如果参数类型是RowBounds或者ResultHandler类型或者他们的子类,则不处理。
如果参数中有Param注解,则使用Param中的值作为参数名
如果配置项useActualParamName=true,argn(n>=0)标作为参数名,如果你是Java8以上并且开启了-parameters`,则是实际的参数名
如果配置项useActualParamName=false,则使用n(n>=0)作为参数名
相关源代码:
public ParamNameResolver(Configuration config, Method method) {
final Class<?>[] paramTypes = method.getParameterTypes();
final Annotation[][] paramAnnotations = method.getParameterAnnotations();
final SortedMap<Integer, String> map = new TreeMap<Integer, String>();
int paramCount = paramAnnotations.length;
// 获取方法中每个参数在SQL中的参数名
for (int paramIndex = 0; paramIndex < paramCount; paramIndex++) {
// 跳过RowBounds、ResultHandler类型
if (isSpecialParameter(paramTypes[paramIndex])) {
continue;
}
String name = null;
// 遍历参数上面的所有注解,如果有Param注解,使用它的值作为参数名
for (Annotation annotation : paramAnnotations[paramIndex]) {
if (annotation instanceof Param) {
hasParamAnnotation = true;
name = ((Param) annotation).value();
break;
}
}
// 如果没有指定注解
if (name == null) {
// 如果开启了useActualParamName配置,则参数名为argn(n>=0),如果是Java8以上并且开启-parameters,则为实际的参数名
if (config.isUseActualParamName()) {
name = getActualParamName(method, paramIndex);
}
// 否则为下标
if (name == null) {
name = String.valueOf(map.size());
}
}
map.put(paramIndex, name);
}
names = Collections.unmodifiableSortedMap(map);
}
而在使用这个names构建xml中参数对象和值的映射时,还进行了进一步的处理。
public Object getNamedParams(Object[] args) {
final int paramCount = names.size();
// 无参数,直接返回null
if (args == null || paramCount == 0) {
return null;
} else if (!hasParamAnnotation && paramCount == 1) {
// 一个参数,并且没有注解,直接返回这个对象
return args[names.firstKey()];
} else {
// 其他情况则返回一个Map对象
final Map<String, Object> param = new ParamMap<Object>();
int i = 0;
for (Map.Entry<Integer, String> entry : names.entrySet()) {
// 先直接放入name的键和对应位置的参数值,其实就是构造函数中存入的值
param.put(entry.getValue(), args[entry.getKey()]);
// add generic param names (param1, param2, ...)
final String genericParamName = GENERIC_NAME_PREFIX + String.valueOf(i + 1);
// 防止覆盖 @Param 的参数值
if (!names.containsValue(genericParamName)) {
// 然后放入GENERIC_NAME_PREFIX + index + 1,其实就是param1,params2,paramn
param.put(genericParamName, args[entry.getKey()]);
}
i++;
}
return param;
}
}
另外值得一提的是,对于集合类型,最后还有一个特殊处理
private Object wrapCollection(final Object object) {
// 如果对象是集合属性
if (object instanceof Collection) {
StrictMap<Object> map = new StrictMap<Object>();
// 加入一个collection参数
map.put("collection", object);
// 如果是一个List集合
if (object instanceof List) {
// 额外加入一个list属性使用
map.put("list", object);
}
return map;
} else if (object != null && object.getClass().isArray()) {
// 数组使用array
StrictMap<Object> map = new StrictMap<Object>();
map.put("array", object);
return map;
}
return object;
}
由此我们可以得出使用参数的结论:
- 如果参数加了
@Param注解,则使用注解的值作为参数 - 如果只有一个参数,并且不是集合类型和数组,且没有加注解,则使用对象的属性名作为参数如果只有一个参数,并且是集合类型,则使用
collection参数,如果是List对象,可以额外使用list参数。 - 如果只有一个参数,并且是数组,则可以使用
array参数如果有多个参数,没有加@Param注解的可以使用argn或者n(n>=0,取决于useActualParamName配置项)作为参数,加了注解的使用注解的值。 - 如果有多个参数,任意参数只要不是和
@Param中的值覆盖,都可以使用paramn(n>=1)
延迟加载
Mybatis是支持延迟加载的,具体的实现方式根据resultMap创建返回对象时,发现fetchType=“lazy”,则使用代理对象,默认使用Javassist(MyBatis 3.3 以上,可以修改为使用CgLib)。代码处理逻辑在处理返回结果集时,具体代码调用关系如下:
PreparedStatementHandler.query=> handleResultSets =>handleResultSet=>handleRowValues=>handleRowValuesForNestedResultMap=>getRowValue
在getRowValue中,有一个方法createResultObject创建返回对象,其中的关键代码创建了代理对象:
if (propertyMapping.getNestedQueryId() != null && propertyMapping.isLazy()) {
resultObject = configuration.getProxyFactory().createProxy(resultObject, lazyLoader, configuration, objectFactory, constructorArgTypes, constructorArgs);
}
另一方面,getRowValue会调用applyPropertyMappings方法,其内部会调用getPropertyMappingValue,继续追踪到getNestedQueryMappingValue方法,在这里,有几行关键代码:
// 如果要求延迟加载,则延迟加载
if (propertyMapping.isLazy()) {
// 如果该属性配置了延迟加载,则将其添加到 `ResultLoader.loaderMap` 中,等待真正使用时再执行嵌套查询并得到结果对象。
lazyLoader.addLoader(property, metaResultObject, resultLoader);
// 返回已定义
value = DEFERED;
// 如果不要求延迟加载,则直接执行加载对应的值
} else {
value = resultLoader.loadResult();
}
这几行的目的是跳过属性值的加载,等真正需要值的时候,再获取值。
Executor
Executor是一个接口,其直接实现的类是BaseExecutor和CachingExecutor,BaseExecutor又派生了BatchExecutor、ReuseExecutor、SimpleExecutor、ClosedExecutor。其继承结构如图:
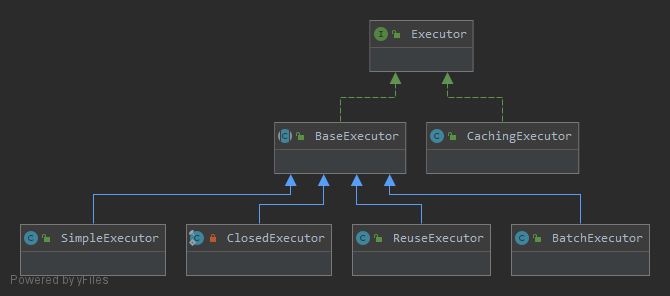
其中ClosedExecutor是一个私有类,用户不直接使用它。
BaseExecutor:模板类,里面有各个Executor的公用的方法。SimpleExecutor:最常用的Executor,默认是使用它去连接数据库,执行SQL语句,没有特殊行为。ReuseExecutor:SQL语句执行后会进行缓存,不会关闭Statement,下次执行时会复用,缓存的key值是BoundSql解析后SQL,清空缓存使用doFlushStatements。其他与SimpleExecutor相同。BatchExecutor:当有连续的Insert、Update、Delete的操作语句,并且语句的BoundSql相同,则这些语句会批量执行。使用doFlushStatements方法获取批量操作的返回值。CachingExecutor:当你开启二级缓存的时候,会使用CachingExecutor装饰SimpleExecutor、ReuseExecutor和BatchExecutor,Mybatis通过CachingExecutor来实现二级缓存。
缓存
一级缓存
Mybatis一级缓存的实现主要是在BaseExecutor中,在它的查询方法里,会优先查询缓存中的值,如果不存在,再查询数据库,查询部分的代码如下,关键代码在17-24行:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
// 已经关闭,则抛出 ExecutorException 异常
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 清空本地缓存,如果 queryStack 为零,并且要求清空本地缓存。
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
// queryStack + 1
queryStack++;
// 从一级缓存中,获取查询结果
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
// 获取到,则进行处理
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
// 获得不到,则从数据库中查询
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
// queryStack - 1
queryStack--;
}
if (queryStack == 0) {
// 执行延迟加载
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
// 清空 deferredLoads
deferredLoads.clear();
// 如果缓存级别是 LocalCacheScope.STATEMENT ,则进行清理
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
而在queryFromDatabase中,则会将查询出来的结果放到缓存中。
// 从数据库中读取操作
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 在缓存中,添加占位对象。此处的占位符,和延迟加载有关,可见 `DeferredLoad#canLoad()` 方法
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 执行读操作
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// 从缓存中,移除占位对象
localCache.removeObject(key);
}
// 添加到缓存中
localCache.putObject(key, list);
// 暂时忽略,存储过程相关
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
而一级缓存的Key,从方法的参数可以看出,与调用方法、参数、rowBounds分页参数、最终生成的sql有关。
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 创建 CacheKey 对象
CacheKey cacheKey = new CacheKey();
// 设置 id、offset、limit、sql 到 CacheKey 对象中
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
cacheKey.update(boundSql.getSql());
// 设置 ParameterMapping 数组的元素对应的每个 value 到 CacheKey 对象中
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic 这块逻辑,和 DefaultParameterHandler 获取 value 是一致的。
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
// 设置 Environment.id 到 CacheKey 对象中
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
}
通过查看一级缓存类的实现,可以看出一级缓存是通过HashMap结构存储的:
/**
* 一级缓存的实现类,部分源代码
*/
public class PerpetualCache implements Cache {
/**
* 缓存容器
*/
private Map<Object, Object> cache = new HashMap<>();
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
@Override
public Object getObject(Object key) {
return cache.get(key);
}
@Override
public Object removeObject(Object key) {
return cache.remove(key);
}
}
通过配置项,我们可以控制一级缓存的使用范围,默认是Session级别的,也就是SqlSession的范围内有效。也可以配制成Statement级别,当本次查询结束后立即清除缓存。
当进行插入、更新、删除操作时,也会在执行SQL之前清空以及缓存。
二级缓存
Mybatis二级缓存的实现是依靠CachingExecutor装饰其他的Executor实现。原理是在查询的时候先根据CacheKey查询缓存中是否存在值,如果存在则返回缓存的值,没有则查询数据库。
在CachingExecutor中query方法中,就有缓存的使用:
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
// 如果需要清空缓存,则进行清空
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
// 暂时忽略,存储过程相关
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
// 从二级缓存中,获取结果
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 如果不存在,则从数据库中查询
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 缓存结果到二级缓存中
tcm.putObject(cache, key, list); // issue #578 and #116
}
// 如果存在,则直接返回结果
return list;
}
}
// 不使用缓存,则从数据库中查询
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
那么这个Cache是在哪里创建的呢?通过调用的追溯,可以找到它的创建:
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
// 创建 Cache 对象
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
// 添加到 configuration 的 caches 中
configuration.addCache(cache);
// 赋值给 currentCache
currentCache = cache;
return cache;
}
从方法的第一行可以看出,Cache对象的范围是namespace,同一个namespace下的所有mapper方法共享Cache对象,也就是说,共享这个缓存。
另一个创建方法是通过CacheRef里面的:
public Cache useCacheRef(String namespace) {
if (namespace == null) {
throw new BuilderException("cache-ref element requires a namespace attribute.");
}
try {
unresolvedCacheRef = true; // 标记未解决
// 获得 Cache 对象
Cache cache = configuration.getCache(namespace);
// 获得不到,抛出 IncompleteElementException 异常
if (cache == null) {
throw new IncompleteElementException("No cache for namespace '" + namespace + "' could be found.");
}
// 记录当前 Cache 对象
currentCache = cache;
unresolvedCacheRef = false; // 标记已解决
return cache;
} catch (IllegalArgumentException e) {
throw new IncompleteElementException("No cache for namespace '" + namespace + "' could be found.", e);
}
}
这里的话会通过CacheRef中的参数namespace,找到那个Cache对象,且这里使用了unresolvedCacheRef,因为Mapper文件的加载是有顺序的,可能当前加载时引用的那个namespace的Mapper文件还没有加载,所以用这个标记一下,延后加载。
二级缓存通过TransactionalCache来管理,内部使用的是一个HashMap。Key是Cache对象,默认的实现是PerpetualCache,一个namespace下共享这个对象。Value是另一个Cache的对象,默认实现是TransactionalCache,是前面那个Key值的装饰器,扩展了事务方面的功能。
通过查看TransactionalCache的源码我们可以知道,默认查询后添加的缓存保存在待提交对象里。
public void putObject(Object key, Object object) {
// 暂存 KV 到 entriesToAddOnCommit 中
entriesToAddOnCommit.put(key, object);
}
只有等到commit的时候才会去刷入缓存。
public void commit() {
// 如果 clearOnCommit 为 true ,则清空 delegate 缓存
if (clearOnCommit) {
delegate.clear();
}
// 将 entriesToAddOnCommit、entriesMissedInCache 刷入 delegate 中
flushPendingEntries();
// 重置
reset();
}
查看clear代码,只是做了标记,并没有真正释放对象。在查询时根据标记直接返回空,在commit才真正释放对象:
public void clear() {
// 标记 clearOnCommit 为 true
clearOnCommit = true;
// 清空 entriesToAddOnCommit
entriesToAddOnCommit.clear();
}
public Object getObject(Object key) {
// issue #116
// 从 delegate 中获取 key 对应的 value
Object object = delegate.getObject(key);
// 如果不存在,则添加到 entriesMissedInCache 中
if (object == null) {
entriesMissedInCache.add(key);
}
// issue #146
// 如果 clearOnCommit 为 true ,表示处于持续清空状态,则返回 null
if (clearOnCommit) {
return null;
// 返回 value
} else {
return object;
}
}
rollback会清空这些临时缓存:
public void rollback() {
// 从 delegate 移除出 entriesMissedInCache
unlockMissedEntries();
// 重置
reset();
}
private void reset() {
// 重置 clearOnCommit 为 false
clearOnCommit = false;
// 清空 entriesToAddOnCommit、entriesMissedInCache
entriesToAddOnCommit.clear();
entriesMissedInCache.clear();
}
根据二级缓存代码可以看出,二级缓存是基于namespace的,可以跨SqlSession。也正是因为基于namespace,如果在不同的namespace中修改了同一个表的数据,会导致脏读的问题。
插件
Mybatis的插件是通过代理对象实现的,可以代理的对象有:
Executor:执行器,执行器是执行过程中第一个代理对象,它内部调用StatementHandler返回SQL结果。StatementHandler:语句处理器,执行SQL前调用ParameterHandler处理参数,执行SQL后调用ResultSetHandler处理返回结果ParameterHandler:参数处理器ResultSetHandler:返回对象处理器
这四个对象的接口的所有方法都可以用插件拦截。
插件的实现代码如下:
// 创建 ParameterHandler 对象
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
// 创建 ParameterHandler 对象
ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql);
// 应用插件
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
return parameterHandler;
}
// 创建 ResultSetHandler 对象
public ResultSetHandler newResultSetHandler(Executor executor, MappedStatement mappedStatement, RowBounds rowBounds, ParameterHandler parameterHandler,
ResultHandler resultHandler, BoundSql boundSql) {
// 创建 DefaultResultSetHandler 对象
ResultSetHandler resultSetHandler = new DefaultResultSetHandler(executor, mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds);
// 应用插件
resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler);
return resultSetHandler;
}
// 创建 StatementHandler 对象
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 创建 RoutingStatementHandler 对象
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
// 应用插件
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
/**
* 创建 Executor 对象
*
* @param transaction 事务对象
* @param executorType 执行器类型
* @return Executor 对象
*/
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
// 获得执行器类型
executorType = executorType == null ? defaultExecutorType : executorType; // 使用默认
executorType = executorType == null ? ExecutorType.SIMPLE : executorType; // 使用 ExecutorType.SIMPLE
// 创建对应实现的 Executor 对象
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
// 如果开启缓存,创建 CachingExecutor 对象,进行包装
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
// 应用插件
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
可以很明显的看到,四个方法内都有interceptorChain.pluginAll()方法的调用,继续查看这个方法:
/**
* 应用所有插件
*
* @param target 目标对象
* @return 应用结果
*/
public Object pluginAll(Object target) {
for (Interceptor interceptor : interceptors) {
target = interceptor.plugin(target);
}
return target;
}
这个方法比较简单,就是遍历interceptors列表,然后调用器plugin方法。interceptors是在解析XML配置文件是通过反射创建的,而创建后会立即调用setProperties方法
我们通常配置插件时,会在interceptor.plugin调用Plugin.wrap,这里面通过Java的动态代理,拦截方法的实现:
/**
* 创建目标类的代理对象
*
* @param target 目标类
* @param interceptor 拦截器对象
* @return 代理对象
*/
public static Object wrap(Object target, Interceptor interceptor) {
// 获得拦截的方法映射
Map<Class<?>, Set<Method>> signatureMap = getSignatureMap(interceptor);
// 获得目标类的类型
Class<?> type = target.getClass();
// 获得目标类的接口集合
Class<?>[] interfaces = getAllInterfaces(type, signatureMap);
// 若有接口,则创建目标对象的 JDK Proxy 对象
if (interfaces.length > 0) {
return Proxy.newProxyInstance(
type.getClassLoader(),
interfaces,
new Plugin(target, interceptor, signatureMap)); // 因为 Plugin 实现了 InvocationHandler 接口,所以可以作为 JDK 动态代理的调用处理器
}
// 如果没有,则返回原始的目标对象
return target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// 获得目标方法是否被拦截
Set<Method> methods = signatureMap.get(method.getDeclaringClass());
if (methods != null && methods.contains(method)) {
// 如果是,则拦截处理该方法
return interceptor.intercept(new Invocation(target, method, args));
}
// 如果不是,则调用原方法
return method.invoke(target, args);
} catch (Exception e) {
throw ExceptionUtil.unwrapThrowable(e);
}
}
而拦截的参数传了Plugin对象,Plugin本身是实现了InvocationHandler接口,其invoke方法里面调用了interceptor.intercept,这个方法就是我们实现拦截处理的地方。
注意到里面有个getSignatureMap方法,这个方法实现的是查找我们自定义拦截器的注解,通过注解确定哪些方法需要被拦截:
private static Map<Class<?>, Set<Method>> getSignatureMap(Interceptor interceptor) {
Intercepts interceptsAnnotation = interceptor.getClass().getAnnotation(Intercepts.class);
// issue #251
if (interceptsAnnotation == null) {
throw new PluginException("No @Intercepts annotation was found in interceptor " + interceptor.getClass().getName());
}
Signature[] sigs = interceptsAnnotation.value();
Map<Class<?>, Set<Method>> signatureMap = new HashMap<>();
for (Signature sig : sigs) {
Set<Method> methods = signatureMap.computeIfAbsent(sig.type(), k -> new HashSet<>());
try {
Method method = sig.type().getMethod(sig.method(), sig.args());
methods.add(method);
} catch (NoSuchMethodException e) {
throw new PluginException("Could not find method on " + sig.type() + " named " + sig.method() + ". Cause: " + e, e);
}
}
return signatureMap;
}
通过源代码我们可以知道,创建一个插件需要做以下事情:
- 创建一个类,实现
Interceptor接口。 - 这个类必须使用
@Intercepts、@Signature来表明要拦截哪个对象的哪些方法。 - 这个类的
plugin方法中调用Plugin.wrap(target, this)。 - (可选)这个类的
setProperties方法设置一些参数。 - XML中
<plugins>节点配置<plugin interceptor="你的自定义类的全名称"></plugin>。
可以在第三点中根据具体的业务情况不进行本次SQL操作的代理,毕竟动态代理还是有性能损耗的。
到此这篇关于通过源代码分析Mybatis的功能的文章就介绍到这了,更多相关源代码分析Mybatis内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

springmvc+spring+mybatis实现用户登录功能(下)
昨天介绍了mybatis与spring的整合,今天我们完成剩下的springmvc的整合工作. 要整合springmvc首先得在web.xml中配置springmvc的前端控制器DispatcherServlet,它是springmvc的核心,为springmvc提供集中访问点,springmvc对页面的分派与调度功能主要靠它完成. 在我们之前配置的web.xml中加入以下springmvc的配置: web.xml <!-- Spring MVC 核心控制器 DispatcherServlet
-
Spring MVC+mybatis实现注册登录功能
本文实例为大家分享了Spring MVC mybatis实现注册登录功能的具体代码,供大家参考,具体内容如下 前期准备: 如下图所示,准备好所需要的包 新建工程,导入所需要的包,在web.xml中配置好所需要的,如下 <?xml version="1.0" encoding="UTF-8"?> <web-app version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee&q
-
springmvc+spring+mybatis实现用户登录功能(上)
由于本人愚钝,整合ssm框架真是费劲了全身的力气,所以打算写下这篇文章,一来是对整个过程进行一个回顾,二来是方便有像我一样的笨鸟看过这篇文章后对其有所帮助,如果本文中有不对的地方,也请大神们指教. 一.代码结构 整个项目的代码结构如图所示: controller为控制层,主要用于对业务模块的流程控制. dao为数据接入层,主要用于与数据库进行连接,访问数据库进行操作,这里定义了各种操作数据库的接口. mapper中存放mybatis的数据库映射配置.可以通过查看mybatis相关教程了解 mod
-
Spring MVC+MyBatis+MySQL实现分页功能实例
前言 最近因为工作的原因,在使用SSM框架实现一个商品信息展示的功能,商品的数据较多,不免用到分页,查了一番MyBatis分页的做法,终于是实现了,在这里记录下来分享给大家,下面来一起看看详细的介绍: 方法如下: 首先写一个分页的工具类,定义当前页数,总页数,每页显示多少等属性. /** * 分页 工具类 */ public class Page implements Serializable { private static final long serialVersionUID = -22
-
通过源代码分析Mybatis的功能流程详解
SQL解析 Mybatis在初始化的时候,会读取xml中的SQL,解析后会生成SqlSource对象,SqlSource对象分为两种. DynamicSqlSource,动态SQL,获取SQL(getBoundSQL方法中)的时候生成参数化SQL. RawSqlSource,原始SQL,创建对象时直接生成参数化SQL. 因为RawSqlSource不会重复去生成参数化SQL,调用的时候直接传入参数并执行,而DynamicSqlSource则是每次执行的时候参数化SQL,所以RawSqlSourc
-
C++调用libcurl开源库实现邮件的发送功能流程详解
目录 1.为啥要选择libcurl库去实现邮件的发送 2.调用libcurl库的API接口实现邮件发送 3.构造待发送的邮件内容 4.开通163发送邮件账号的SMTP服务 5.排查接收的邮件内容为空的问题 libcurl中封装了支持这些协议的网络通信模块,支持跨平台,支持Windows,Unix,Linux等多个操作系统.libcurl提供了一套统一样式的API接口,我们不用关注各种协议下网络通信的实现细节,只需要调用这些API就能轻松地实现基于这些协议的数据通信.本文将简单地讲述一下使用lib
-
MyBatis集成Spring流程详解
目录 一.Mybatis与spring集成 1. 导入pom依赖 2. 编写配置文件 3. 使用注解开发 4. 测试 5. 管理数据源 二.Aop整合pagehelper插件 要解决的问题 一.Mybatis与spring集成 1. 导入pom依赖 <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8
-
在IDEA中maven配置MyBatis的流程详解
一.MyBatis简介 1)MyBatis 是一款优秀的持久层框架 2)MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集的过程 3)MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 实体类 [Plain Old Java Objects,普通的 Java对象]映射成数据库中的记录. 如果想了解maven请转到我的上一篇文章中: 二.MyBatis获取 1)在这个网址下获取MyBatis:https://mvnrepositor
-
springboot整合mybatis流程详解
目录 1.mybatis是什么 2.整合 2.1 导入依赖 2.2 创建包和类 2.3 在application.yaml配置mybatis 3.使用注解版mybaits 4.实战过程 1.mybatis是什么 MyBatis 是一款优秀的持久层框架,它支持自定义 SQL.存储过程以及高级映射.MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作.MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型.接口和 Java POJO(Plain Old Java
-
Vue登录功能的实现流程详解
目录 Vue项目中实现登录大致思路 安装插件 创建store 封装axios qs vue 插件 api.js的作用 路由拦截 登录页面实际使用 Vue项目中实现登录大致思路 1.第一次登录的时候,前端调后端的登陆接口,发送用户名和密码 2.后端收到请求,验证用户名和密码,验证成功,就给前端返回一个token 3.前端拿到token,将token存储到localStorage和vuex中,并跳转路由页面 4.前端每次跳转路由,就判断 localStroage 中有无 token ,没有就跳转到登
-
SpringBoot整合Mybatis与druid实现流程详解
目录 SpringBoot整合junit SpringBoot整合junit SpringBoot整合junit的classes SpringBoot整合Mybatis 整合前的准备 整合Mybatis SpringBoot 整合druid 配置前置知识小点 整合druid SpringBoot整合junit SpringBoot整合junit ①还是一样,我们首先创建一个SpringBoot模块. 由于我们并不测试前端,而只是整合junit,所以不用选择模板,选择其中的web即可. 完成以后我
-
SpringBoot整合junit与Mybatis流程详解
目录 SpringBoot整合junit 环境准备 编写测试类 SpringBoot整合mybatis 回顾Spring整合Mybatis SpringBoot整合mybatis 创建模块 定义实体类 定义dao接口 定义测试类 编写配置 测试 使用Druid数据源 SpringBoot整合junit 回顾 Spring 整合 junit @RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(classes = SpringC
-
SpringMvc框架的简介与执行流程详解
目录 一.SpringMvc框架简介 1.Mvc设计理念 2.SpringMvc简介 二.SpringMvc执行流程 1.流程图解 2.步骤描述 3.核心组件 三.整合Spring框架配置 1.spring-mvc配置 2.Web.xml配置 3.测试接口 4.常用注解说明 四.常见参数映射 1.普通映射 2.指定参数名 3.数组参数 4.Map参数 5.包装参数 6.Rest风格参数 五.源代码地址 一.SpringMvc框架简介 1.Mvc设计理念 M:代表模型Model 模型就是数据,应用
-
Springboot实现动态定时任务流程详解
目录 一.静态 二.动态 1.基本代码 2.方案详解 2.1 初始化 2.2 单次执行 2.3 停止任务 2.4 启用任务 三.小结 一.静态 静态的定时任务可以直接使用注解@Scheduled,并在启动类上配置@EnableScheduling即可 @PostMapping("/list/test1") @Async @Scheduled(cron = "0 * * * * ?") public void test1() throws Exception { Ob