C语言二叉排序树的创建,插入和删除
目录
- 一、二叉排序树(二叉查找树)的概念
- 二、二叉排序树的判别
- 三、二叉排序树的创建(creat、insert)
- 四、二叉排序树的插入
- 五、二插排序树的删除
- 六、完整代码(可以运行)
- 总结
一、二叉排序树(二叉查找树)的概念
(1)若左子树非空,则左子树上所有结点的值均小于根节点的值
(2)若右子树非空,则右子树上所有结点的值均大于根节点的值
(3)左右子树分别也是一棵二叉排序树
tip:可以是一棵空树
二、二叉排序树的判别
(1)因为二叉排序树的中序遍历是一个有序递增序列,可以对已经建立的二叉树进行中序遍历,如果满足则判断是
三、二叉排序树的创建(creat、insert)
树结点的结构体:
struct tree{
int data;
struct tree* lchild;
struct tree* rchild;
};
//递归创建结点
void Creat(int a,tree* &T){
if(T==NULL){
T=new tree;
T->data=a;
T->lchild=NULL;
T->rchild=NULL;
}
else if(a>T->data){
Creat(a,T->rchild);
}
else{
Creat(a,T->lchild);
}
}
//传入数组,一次性插入
void Insert(tree* &T,int A[],int len){
for(int i=0;i<=len;i++){
Creat(A[i],T);
}
}
四、二叉排序树的插入
//查找指定结点(输出当前结点是否存在),如果没有就插入
void find(tree* &T,int a){
tree* K=T; //T指针指向二叉排序树的根节点,K为工作指针
tree* pre; //pre指向当前工作指针的上一个结点,用于插入确定插入位置
while(K!=NULL&&a!=K->data){
if(a>K->data){
pre=K;
K=K->rchild;
}else{
pre=K;
K=K->lchild;
}
}
if(K==NULL){
tree* P; //工作指针
P=new tree;
P->data=a;
if(P->data>pre->data){
pre->rchild=P;
P->lchild=NULL;
P->rchild=NULL;
}
else{
pre->lchild=P;
P->lchild=NULL;
P->rchild=NULL;
}
cout<<"不存在,已插入 "<<a<<" 这个结点"<<endl;
}else{
cout<<"存在"<<endl;
}
}
五、二插排序树的删除
//删除某一结点,若不存在则提示
//①当该结点是叶子结点时,直接删除
//②当该结点有一个左孩子或者一个右孩子时,让其孩子结点代替他的位置
//③当左右孩子都存在时找中序遍历的下一个(或上一个)结点代替其位置
void delect(tree* &T,int a){
//首先找到要删除的结点
tree* Pre;
tree* P=T; //定义工作指针
while(P!=NULL&&a!=P->data){ //这两个判定条件不能颠倒
if(a>P->data){
Pre=P;
P=P->rchild;
}else{
Pre=P;
P=P->lchild;
}
}
if(P==NULL){
cout<<"要删除的结点不存在"<<endl;
}else{
// ①当该结点是叶子结点时,直接删除
if(P->lchild==NULL&&P->rchild==NULL){
if(P->data>Pre->data){
Pre->rchild=NULL;
}else{
Pre->lchild=NULL;
}
cout<<"已删除 "<<a<<endl;
}
//②当该结点有一个左孩子或者一个右孩子时,让其孩子结点代替他的位置
if((P->lchild!=NULL&&P->rchild==NULL)||(P->rchild!=NULL&&P->lchild==NULL)){
if(P->data>Pre->data){
if(P->lchild!=NULL){
Pre->rchild=P->lchild;
}else{
Pre->rchild=P->rchild;
}
}
if(P->data<Pre->data){
if(P->lchild!=NULL){
Pre->lchild=P->lchild;
}else{
Pre->lchild=P->rchild;
}
}
cout<<"已删除 "<<a<<endl;
}
//③当左右孩子都存在时找中序遍历的下一个(或上一个结点)结点代替其位置 (讨巧一点用前驱的最后一个结点)
if(P->lchild!=NULL&&P->rchild!=NULL){
tree* q;
tree* s;
q=P;
s=P->lchild;
while(s->rchild) //在结点p的左子树中继续查找其前驱结点,即最右下结点
{
q=s;
s=s->rchild; //向右到尽头
}
P->data=s->data; //结点s中的数据顶替被删结点p中的
if(q!=P) //重新连接结点q的右子树
q->rchild=s->lchild;
else //重新连接结点q的左子树
q->lchild=s->lchild;
delete(s); //释放s
}
cout<<"已删除 "<<a<<endl;
}
}
六、完整代码(可以运行)
#include<iostream>
using namespace std;
struct tree{
int data;
struct tree* lchild;
struct tree* rchild;
};
//建立创建,传入一个完整的数组
void Creat(int a,tree* &T){
if(T==NULL){
T=new tree;
T->data=a;
T->lchild=NULL;
T->rchild=NULL;
}
else if(a>T->data){
Creat(a,T->rchild);
}
else{
Creat(a,T->lchild);
}
}
//传入数组,一次性插入
void Insert(tree* &T,int A[],int len){
for(int i=0;i<=len;i++){
Creat(A[i],T);
}
}
//中序遍历
void midorder(tree* T){
if(T!=NULL){
midorder(T->lchild);
cout<<T->data<<" ";
midorder(T->rchild);
}
}
//查找指定结点(输出当前结点是否存在),如果没有就插入
void find(tree* &T,int a){
tree* K=T; //T指针指向二叉排序树的根节点,K为工作指针
tree* pre; //pre指向当前工作指针的上一个结点,用于插入确定插入位置
while(K!=NULL&&a!=K->data){
if(a>K->data){
pre=K;
K=K->rchild;
}else{
pre=K;
K=K->lchild;
}
}
if(K==NULL){
tree* P; //工作指针
P=new tree;
P->data=a;
if(P->data>pre->data){
pre->rchild=P;
P->lchild=NULL;
P->rchild=NULL;
}
else{
pre->lchild=P;
P->lchild=NULL;
P->rchild=NULL;
}
cout<<"不存在,已插入 "<<a<<" 这个结点"<<endl;
}else{
cout<<"存在"<<endl;
}
}
//删除某一结点,若不存在则提示
//①当该结点是叶子结点时,直接删除
//②当该结点有一个左孩子或者一个右孩子时,让其孩子结点代替他的位置
//③当左右孩子都存在时找中序遍历的下一个(或上一个)结点代替其位置
void delect(tree* &T,int a){
//首先找到要删除的结点
tree* Pre;
tree* P=T; //定义工作指针
while(P!=NULL&&a!=P->data){ //这两个判定条件不能颠倒
if(a>P->data){
Pre=P;
P=P->rchild;
}else{
Pre=P;
P=P->lchild;
}
}
if(P==NULL){
cout<<"要删除的结点不存在"<<endl;
}else{
// ①当该结点是叶子结点时,直接删除
if(P->lchild==NULL&&P->rchild==NULL){
if(P->data>Pre->data){
Pre->rchild=NULL;
}else{
Pre->lchild=NULL;
}
cout<<"已删除 "<<a<<endl;
}
//②当该结点有一个左孩子或者一个右孩子时,让其孩子结点代替他的位置
if((P->lchild!=NULL&&P->rchild==NULL)||(P->rchild!=NULL&&P->lchild==NULL)){
if(P->data>Pre->data){
if(P->lchild!=NULL){
Pre->rchild=P->lchild;
}else{
Pre->rchild=P->rchild;
}
}
if(P->data<Pre->data){
if(P->lchild!=NULL){
Pre->lchild=P->lchild;
}else{
Pre->lchild=P->rchild;
}
}
cout<<"已删除 "<<a<<endl;
}
//③当左右孩子都存在时找中序遍历的下一个(或上一个结点)结点代替其位置 (讨巧一点用前驱的最后一个结点)
if(P->lchild!=NULL&&P->rchild!=NULL){
tree* q;
tree* s;
q=P;
s=P->lchild;
while(s->rchild) //在结点p的左子树中继续查找其前驱结点,即最右下结点
{
q=s;
s=s->rchild; //向右到尽头
}
P->data=s->data; //结点s中的数据顶替被删结点p中的
if(q!=P) //重新连接结点q的右子树
q->rchild=s->lchild;
else //重新连接结点q的左子树
q->lchild=s->lchild;
delete(s); //释放s
}
cout<<"已删除 "<<a<<endl;
}
}
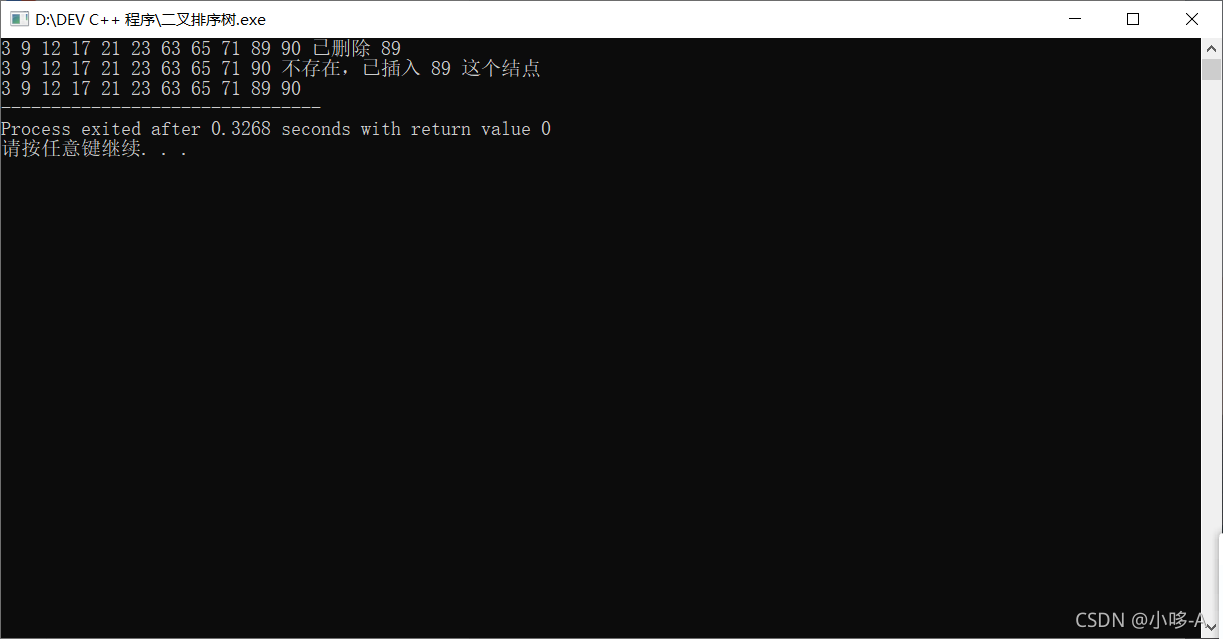
int main(){
tree* T=NULL;
int A[]={23,89,65,12,17,3,9,90,21,63,71};
Insert(T,A,10);
midorder(T);
delect(T,89);
midorder(T);
find(T,89);
midorder(T);
return 0;
}
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

c语言_构建一个静态二叉树实现方法
第一.树的构建 定义树结构 struct BTNode { char data; struct BTNode* pLChild; struct BTNode* pRChild; }; 静态方式创建一个简单的二叉树 struct BTNode* create_list() { struct BTNode* pA = (struct BTNode*)malloc(sizeof(BTNode)); struct BTNode* pB = (struct BTNode*)malloc(sizeof(BT
-
C语言实现二叉树的搜索及相关算法示例
本文实例讲述了C语言实现二叉树的搜索及相关算法.分享给大家供大家参考,具体如下: 二叉树(二叉查找树)是这样一类的树,父节点的左边孩子的key都小于它,右边孩子的key都大于它. 二叉树在查找和存储中通常能保持logn的查找.插入.删除,以及前驱.后继,最大值,最小值复杂度,并且不占用额外的空间. 这里演示二叉树的搜索及相关算法: #include<stack> #include<queue> using namespace std; class tree_node{ public
-
C语言数据结构之线索二叉树及其遍历
C语言数据结构之线索二叉树及其遍历 遍历二叉树就是以一定的规则将二叉树中的节点排列成一个线性序列,从而得到二叉树节点的各种遍历序列,其实质是:对一个非线性的结构进行线性化.使得在这个访问序列中每一个节点都有一个直接前驱和直接后继.传统的链式结构只能体现一种父子关系,¥不能直接得到节点在遍历中的前驱和后继¥,而我们知道二叉链表表示的二叉树中有大量的空指针,当使用这些空的指针存放指向节点的前驱和后继的指针时,则可以更加方便的运用二叉树的某些操作.引入线索二叉树的目的是: 为了加快查找节点的前驱和后继
-
C语言二叉树的三种遍历方式的实现及原理
二叉树遍历分为三种:前序.中序.后序,其中序遍历最为重要.为啥叫这个名字?是根据根节点的顺序命名的. 比如上图正常的一个满节点,A:根节点.B:左节点.C:右节点,前序顺序是ABC(根节点排最先,然后同级先左后右):中序顺序是BAC(先左后根最后右):后序顺序是BCA(先左后右最后根). 比如上图二叉树遍历结果 前序遍历:ABCDEFGHK 中序遍历:BDCAEHGKF 后序遍历:DCBHKGFEA 分析中序遍历如下图,中序比较重要(java很多树排序是基于中序,后面讲解分析) 下面介绍一下,二
-
如何使用C语言实现平衡二叉树数据结构算法
目录 前言 一.平衡二叉树实现原理 二.平衡二叉树实现算法 三.全部代码 前言 对于一个二叉排序树而言 它们的结构都是根据了二叉树的特性从最左子树开始在回到该结点上继续往右结点走 通过该方式进行递归操作,并且该二叉排序树的结构也是从小到大依次显示 那么我们假设a[10]={ 3,2,1,4,5,6,7,10,9,8 };我们需要查找改列表中的某一个结点的值 那么我们通过二叉排序树的展示,会展示成如图: 可以发现,如果我们想通过二叉排序树这个深度为8的树来查找某个数 我们需要走到最后,这是最坏的打
-
C语言二叉排序树的创建,插入和删除
目录 一.二叉排序树(二叉查找树)的概念 二.二叉排序树的判别 三.二叉排序树的创建(creat.insert) 四.二叉排序树的插入 五.二插排序树的删除 六.完整代码(可以运行) 总结 一.二叉排序树(二叉查找树)的概念 (1)若左子树非空,则左子树上所有结点的值均小于根节点的值 (2)若右子树非空,则右子树上所有结点的值均大于根节点的值 (3)左右子树分别也是一棵二叉排序树 tip:可以是一棵空树 二.二叉排序树的判别 (1)因为二叉排序树的中序遍历是一个有序递增序列,可以对已经建立的二叉
-
C语言实现带头结点的链表的创建、查找、插入、删除操作
本文实例讲述了C语言实现带头结点的链表的创建.查找.插入.删除操作.是数据结构中链表部分的基础操作.分享给大家供大家参考.具体方法如下: #include <stdio.h> #include <stdlib.h> typedef struct node { int data; struct node* next;// 这个地方注意结构体变量的定义规则 } Node, *PNode; Node* createLinklist(int length) { int i = 0; PNo
-
C语言之单链表的插入、删除与查找
单链表是一种链式存取的数据结构,用一组地址任意的存储单元存放线性表中的数据元素.要实现对单链表中节点的插入.删除与查找的功能,就要先进行的单链表的初始化.创建和遍历,进而实现各功能,以下是对单链表节点的插入.删除.查找功能的具体实现: #include<stdio.h> #include<stdlib.h> #include<string.h> typedef int ElemType; /** *链表通用类型 *ElemType 代表自定义的数据类型 *struct
-
C++ 实现单链表创建、插入和删除
目录 C++单链表创建.插入和删除 1.头节点插入和删除结果 2.中间节点插入和删除结果 3.尾结点插入和删除结果 C++单链表(带头结点) 总结归纳 代码实现 C++单链表创建.插入和删除 这里仅提供一种思路. #include <iostream> #include <stdio.h> #include <string> #include <conio.h> /** * cstdio是将stdio.h的内容用C++头文件的形式表示出来. *stdio.h
-
MySQL数据库操作DML 插入数据,删除数据,更新数据
目录 DML介绍 数据插入 数据修改 数据删除 DML介绍 DML是指数据操作语言,英文全称是Data Manipulation Language,用来对数据库中表的数据记录进行更新. 关键字: 插入insert 删除delete 更新update 数据插入 insert into 表 (列名1,列名2,列名3...) values (值1,值2,值3...): //向表中插入某些 insert into 表 values (值1,值2,值3...); //向表中插入所有列 这里的两种方式,第一
-
JavaScript之DOM插入更新删除_动力节点Java学院整理
JavaScript之DOM插入更新删除,供大家参考,具体内容如下 更新 拿到一个DOM节点后,我们可以对它进行更新. 可以直接修改节点的文本,方法有两种: 一种是修改innerHTML属性,这个方式非常强大,不但可以修改一个DOM节点的文本内容,还可以直接通过HTML片段修改DOM节点内部的子树: // 获取<p id="p-id">...</p> var p = document.getElementById('p-id'); // 设置文本为abc: p.
-
JDBC连接MySql数据库步骤 以及查询、插入、删除、更新等
主要内容: JDBC连接数据库步骤. 一个简单详细的查询数据的例子. 封装连接数据库,释放数据库连接方法. 实现查询,插入,删除,更新等十一个处理数据库信息的功能.(包括事务处理,批量更新等) 把十一个功能都放在一起. 安装下载的数据库驱动程序jar包,不同的数据库需要不同的驱动程序(这本该是第一步,但是由于属于安装类,所以我们放在最后) 一.JDBC连接数据库(编辑)步骤(主要有六个步骤) 1.注册驱动: Class.forName("com.mysql.jdbc.Driver");
-
C#中实现插入、删除Excel分页符的方法
引言 大家应该都知道,对Excel表格设置分页对我们预览.打印文档时是很方便的,特别是一些包含很多复杂数据的.不规则的表格,为保证打印时每一页的排版美观性或者数据的前后连接的完整性,此时的分页符就发挥了极大的作用.因此,本文将介绍C#设置Excel分页的方法. 当然,对于Excel表格中已有的分页符,如果我们也可以根据需要自行删除分页. 下面话不多说了,来一起看看详细的介绍吧. 示例要点梳理 1. 插入分页 1.1 插入横向分页 1.2 插入纵向分页 2. 删除分页 2.1 删除全部分页 2.2
-
ORCAL 临时创建表与删除表
目录 一.Orcal临时表分类 1.会话级临时表 2.事务级临时表 二.临时表创建 1.会话级临时表 2.事务级临时表 三.删除临时表 四.删除时报错 1.清空表,然后删除表 2.杀掉进程,然后删除 一.Orcal临时表分类 1.会话级临时表 1).保存一个会话Session的数据. 2).当会话退出时,临时表数据自动清空.表结构与元数据还存储在用户数据字典. 总结:会话级临时表是指临时表中的数据只在会话生命周期之中存在,当用户退出会话结束的时候,Oracle自动清除临时表中数据. 2.事务级临
-
Java实现二叉搜索树的插入、删除功能
二叉树的结构 public class TreeNode { int val; TreeNode left; TreeNode right; TreeNode() { } TreeNode(int val) { this.val = val; } } 中序遍历 中序遍历:从根节点开始遍历,遍历顺序是:左子树->当前节点->右子树,在中序遍历中,对每个节点来说: 只有当它的左子树都被遍历过了(或者没有左子树),它才会被遍历到.在遍历右子树之前,一定会先遍历当前节点. 中序遍历得到的第一个节点是没