图解Java排序算法之堆排序
目录
- 预备知识
- 堆排序
- 堆
- 堆排序基本思想及步骤
- 再简单总结下堆排序的基本思路:
- 总结
预备知识
堆排序
堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。首先简单了解下堆结构。
堆
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。如下图:
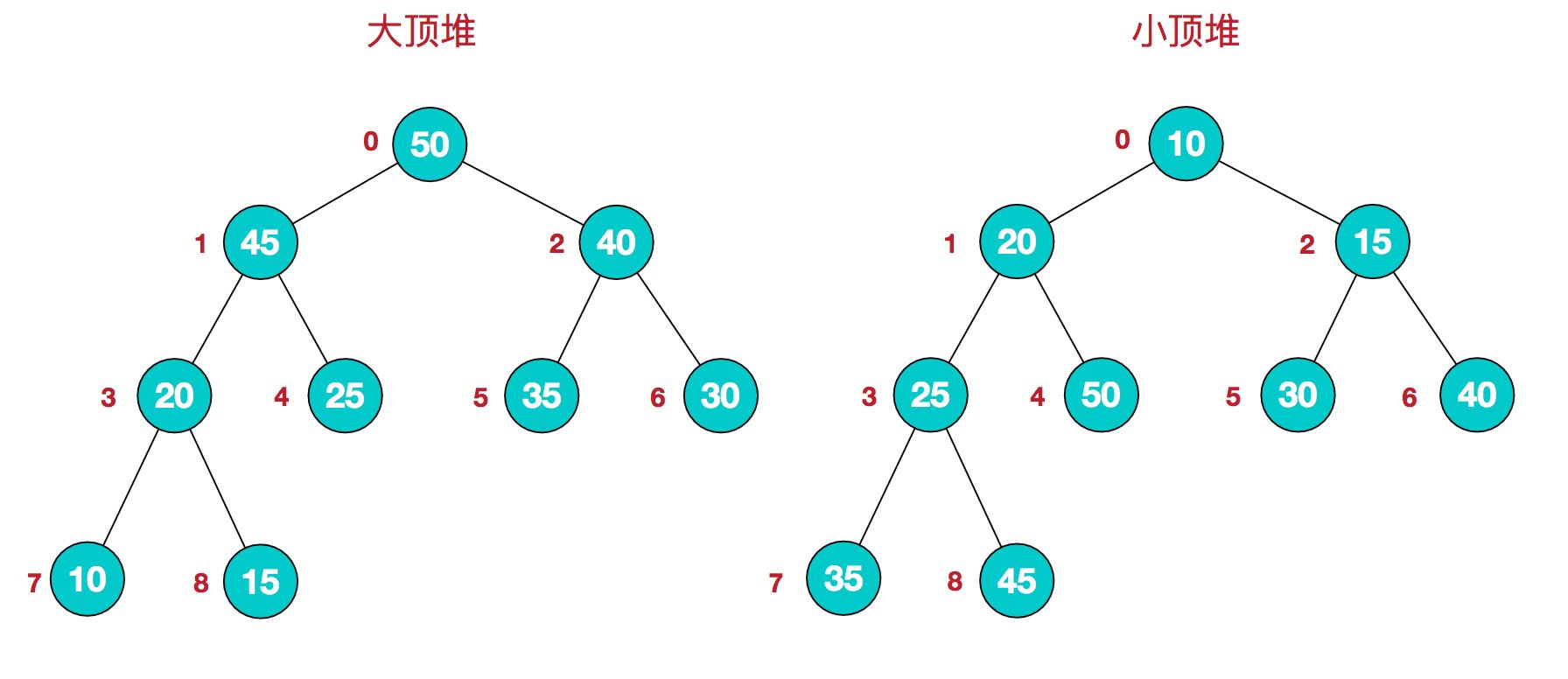
同时,我们对堆中的结点按层进行编号,将这种逻辑结构映射到数组中就是下面这个样子

该数组从逻辑上讲就是一个堆结构,我们用简单的公式来描述一下堆的定义就是:
大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
ok,了解了这些定义。接下来,我们来看看堆排序的基本思想及基本步骤:
堆排序基本思想及步骤
堆排序的基本思想是:将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了
步骤一.构造初始堆。将给定无序序列构造成一个大顶堆(一般升序采用大顶堆,降序采用小顶堆)。
a.假设给定无序序列结构如下
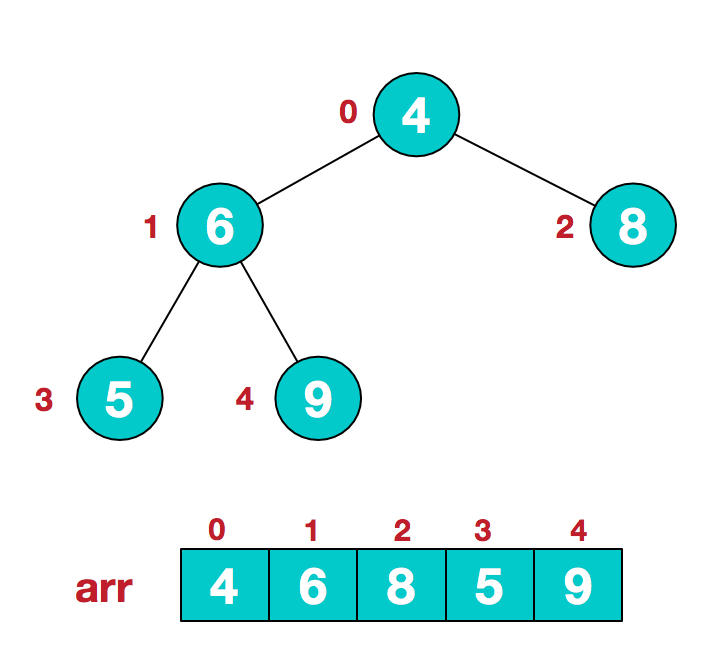
1.此时我们从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点 arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整。

2.找到第二个非叶节点4,由于[4,9,8]中9元素最大,4和9交换。
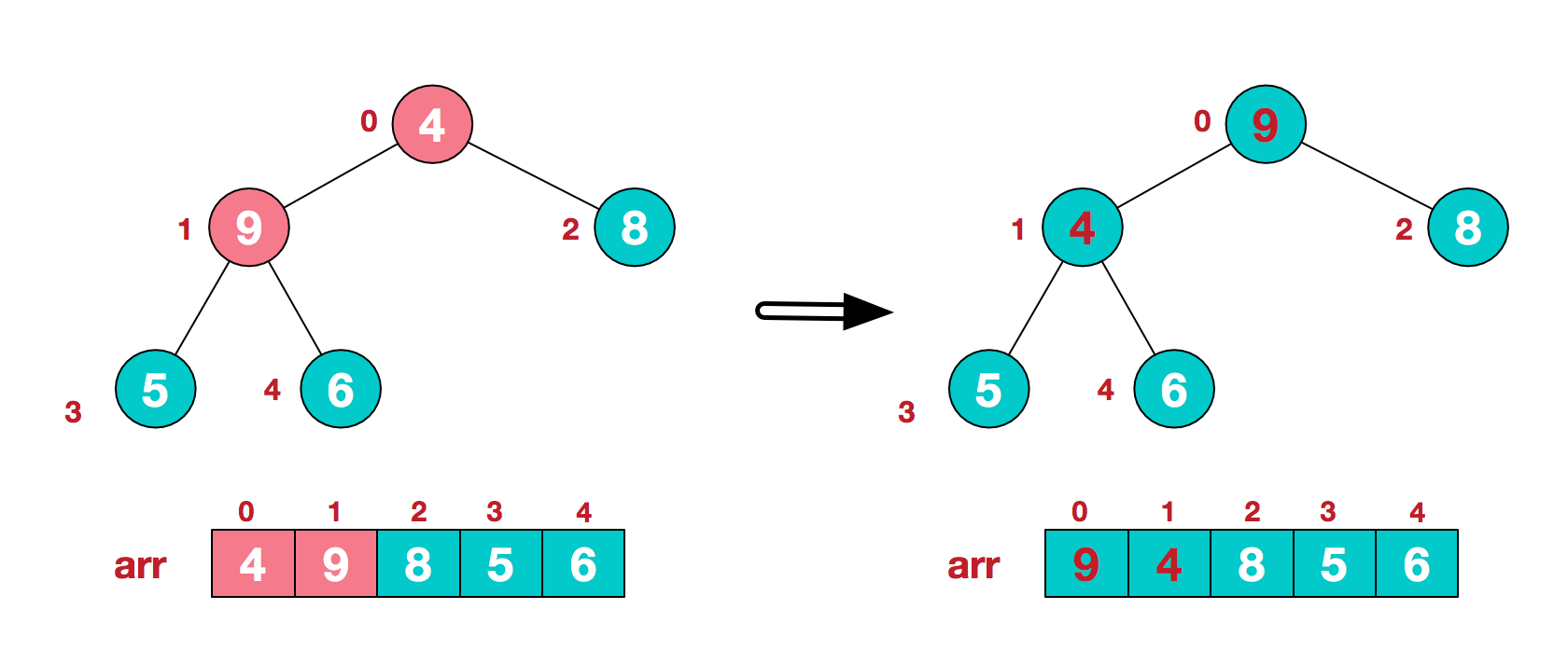
这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。

此时,我们就将一个无需序列构造成了一个大顶堆。
步骤二. 将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。
a.将堆顶元素9和末尾元素4进行交换
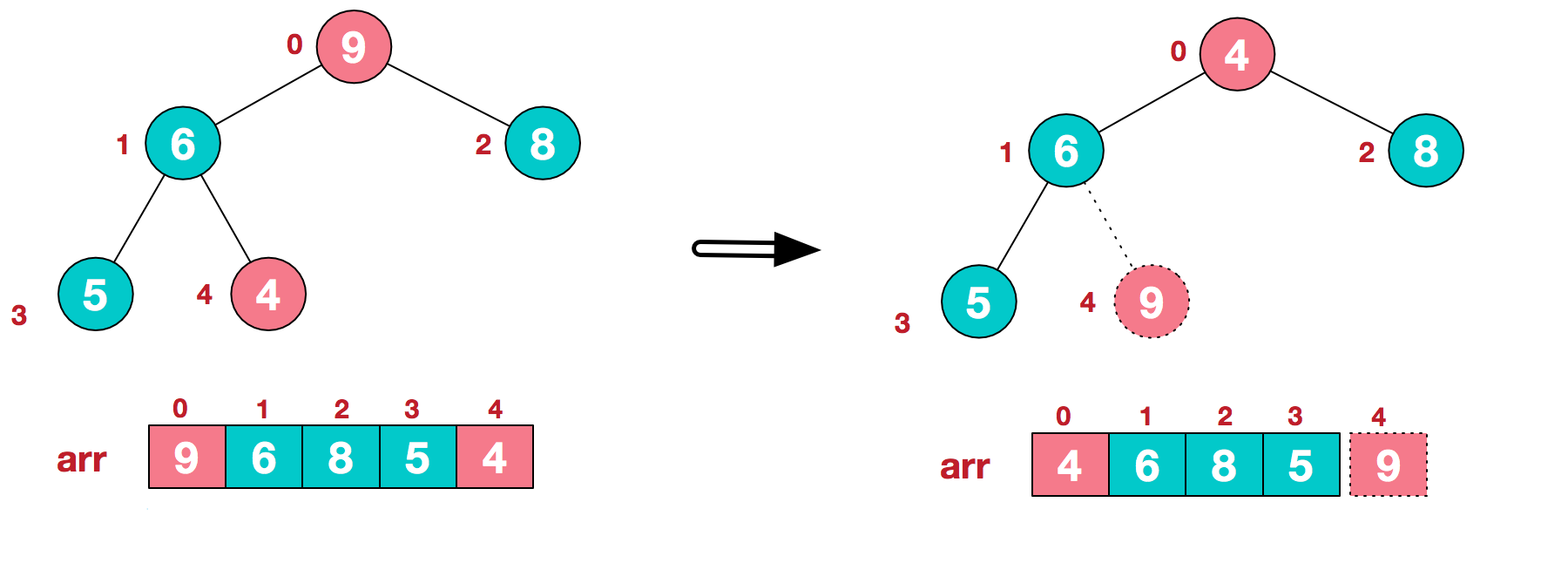
b.重新调整结构,使其继续满足堆定义
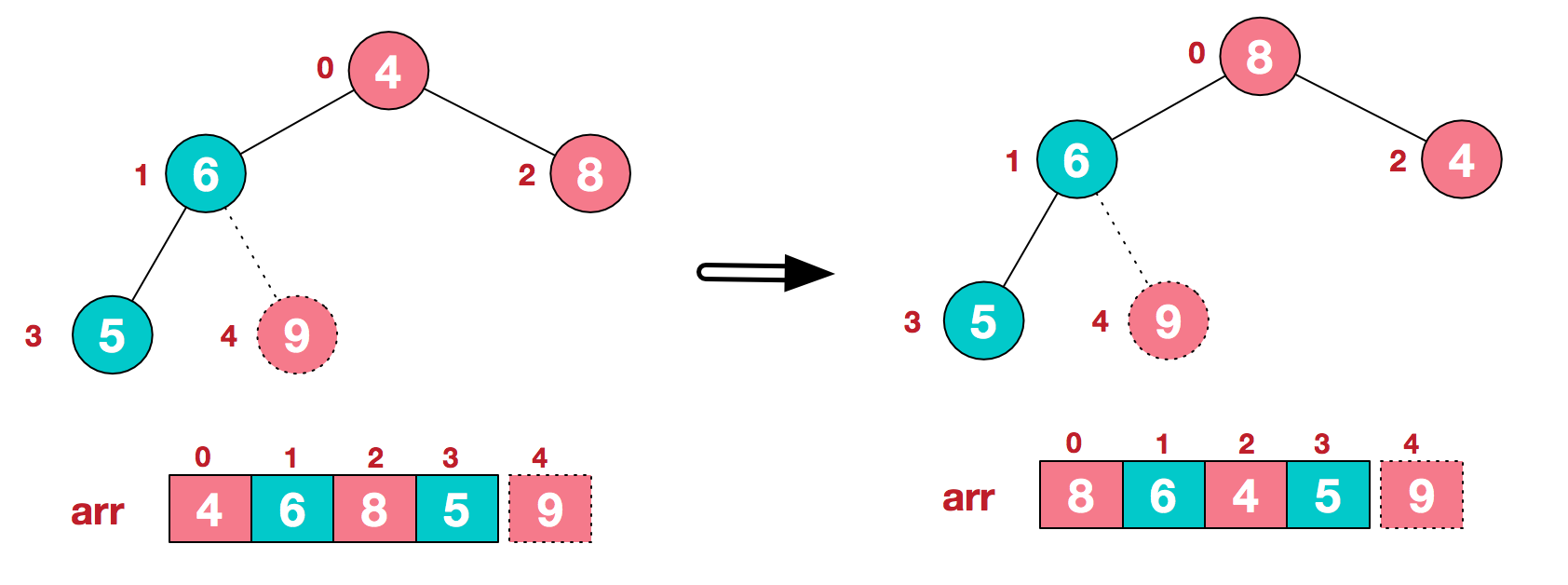
c.再将堆顶元素8与末尾元素5进行交换,得到第二大元素8.
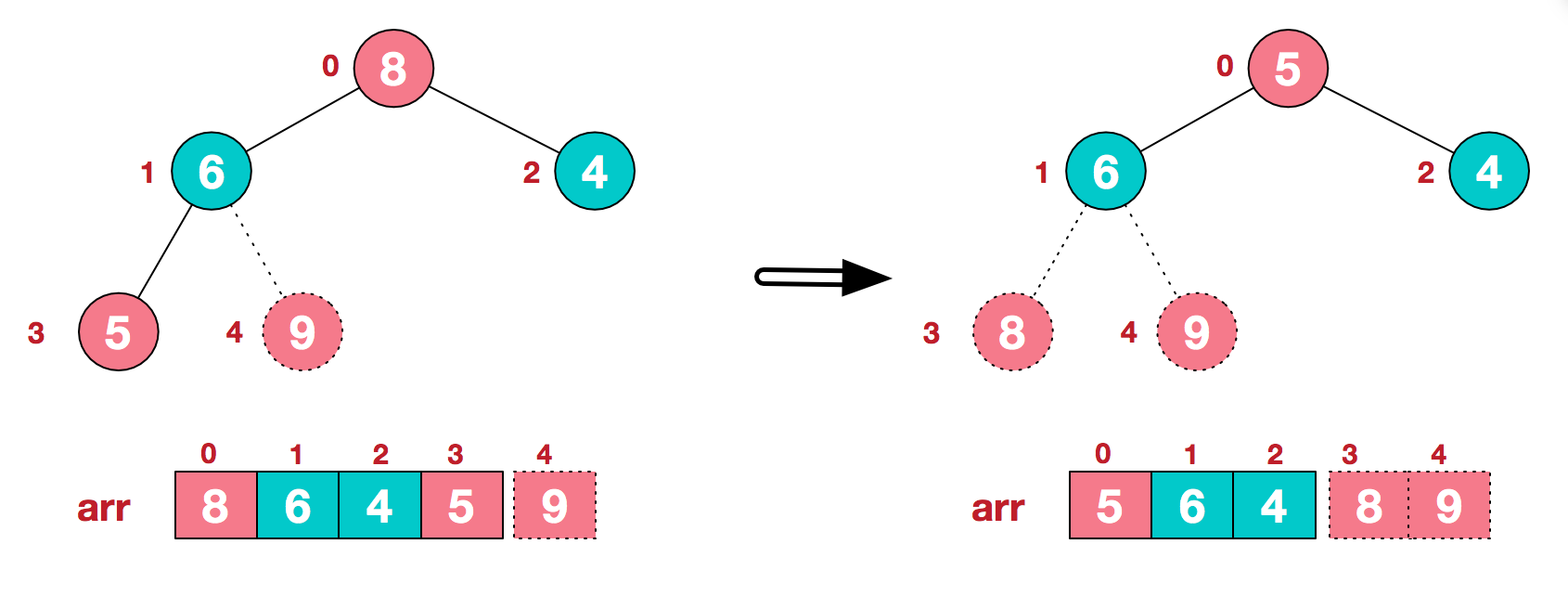
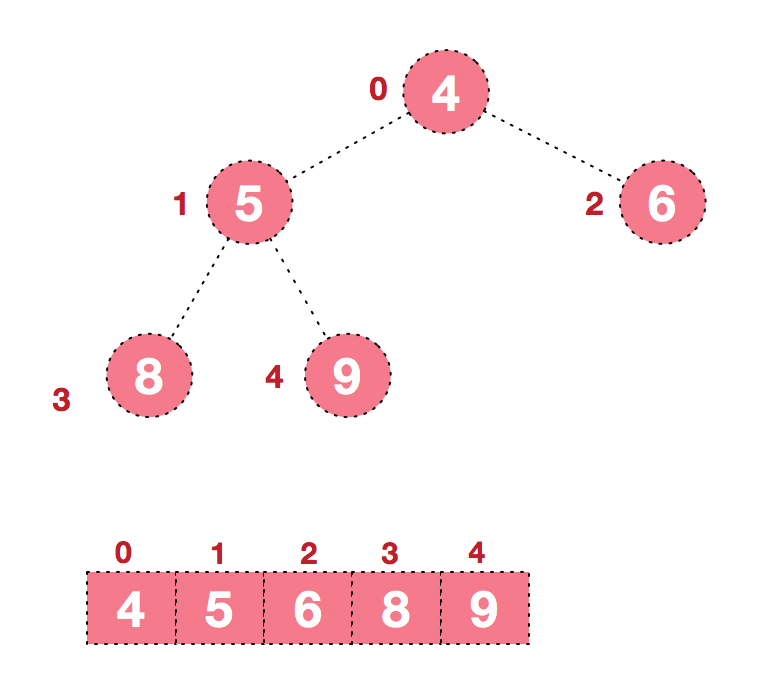
后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序
再简单总结下堆排序的基本思路:
a.将无需序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆;
b.将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
c.重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。
代码实现
package sortdemo;
import java.util.Arrays;
/**
* Created by chengxiao on 2016/12/17.
* 堆排序demo
*/
public class HeapSort {
public static void main(String []args){
int []arr = {9,8,7,6,5,4,3,2,1};
sort(arr);
System.out.println(Arrays.toString(arr));
}
public static void sort(int []arr){
//1.构建大顶堆
for(int i=arr.length/2-1;i>=0;i--){
//从第一个非叶子结点从下至上,从右至左调整结构
adjustHeap(arr,i,arr.length);
}
//2.调整堆结构+交换堆顶元素与末尾元素
for(int j=arr.length-1;j>0;j--){
swap(arr,0,j);//将堆顶元素与末尾元素进行交换
adjustHeap(arr,0,j);//重新对堆进行调整
}
}
/**
* 调整大顶堆(仅是调整过程,建立在大顶堆已构建的基础上)
* @param arr
* @param i
* @param length
*/
public static void adjustHeap(int []arr,int i,int length){
int temp = arr[i];//先取出当前元素i
for(int k=i*2+1;k<length;k=k*2+1){//从i结点的左子结点开始,也就是2i+1处开始
if(k+1<length && arr[k]<arr[k+1]){//如果左子结点小于右子结点,k指向右子结点
k++;
}
if(arr[k] >temp){//如果子节点大于父节点,将子节点值赋给父节点(不用进行交换)
arr[i] = arr[k];
i = k;
}else{
break;
}
}
arr[i] = temp;//将temp值放到最终的位置
}
/**
* 交换元素
* @param arr
* @param a
* @param b
*/
public static void swap(int []arr,int a ,int b){
int temp=arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
}
结果
[1, 2, 3, 4, 5, 6, 7, 8, 9]
总结
堆排序是一种选择排序,整体主要由构建初始堆+交换堆顶元素和末尾元素并重建堆两部分组成。其中构建初始堆经推导复杂度为O(n),在交换并重建堆的过程中,需交换n-1次,而重建堆的过程中,根据完全二叉树的性质,[log2(n-1),log2(n-2)...1]逐步递减,近似为nlogn。所以堆排序时间复杂度一般认为就是O(nlogn)级。
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
JAVA堆排序算法的讲解
预备知识 堆排序 堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序.首先简单了解下堆结构. 堆 堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆:或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆.如下图: 同时,我们对堆中的结点按层进行编号,将这种逻辑结构映射到数组中就是下面这个样子 该数组从逻辑上讲就是一个堆结构,我们用简单的公式来描述一下堆的定义就是: 大顶
-

Java 归并排序算法、堆排序算法实例详解
基本思想: 归并(Merge)排序法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的.然后再把有序子序列合并为整体有序序列. 归并排序示例: 合并方法: 设r[i-n]由两个有序子表r[i-m]和r[m+1-n]组成,两个子表长度分别为n-i +1.n-m. j=m+1:k=i:i=i; //置两个子表的起始下标及辅助数组的起始下标 若i>m 或j>n,转⑷ //其中一个子表已合并完,比较选取结束 //选取r[i]和r[j]较小的存入辅助数组
-
详解堆排序算法原理及Java版的代码实现
概述 堆排序是一种树形选择排序,是对直接选择排序的有效改进. 堆的定义如下:具有n个元素的序列(k1,k2,...,kn), 当且仅当满足: 时称之为堆.由堆的定义可以看出,堆顶元素(即第一个元素)必为最小项(小顶堆)或最大项(大顶堆). 若以一维数组存储一个堆,则堆对应一棵完全二叉树,且所有非叶结点(有子女的结点)的值均不大于(或不小于)其子女的值,根结点(堆顶元素)的值是最小(或最大)的. (a)大顶堆序列:(96, 83, 27, 38, 11, 09) (b)小顶堆序列:(12, 36,
-
JAVA十大排序算法之堆排序详解
目录 堆排序 知识补充 二叉树 满二叉树 完全二叉树 二叉堆 代码实现 时间复杂度 算法稳定性 思考 总结 堆排序 这里的堆并不是JVM中堆栈的堆,而是一种特殊的二叉树,通常也叫作二叉堆.它具有以下特点: 它是完全二叉树 堆中某个结点的值总是不大于或不小于其父结点的值 知识补充 二叉树 树中节点的子节点不超过2的有序树 满二叉树 二叉树中除了叶子节点,每个节点的子节点都为2,则此二叉树为满二叉树. 完全二叉树 如果对满二叉树的结点进行编号,约定编号从根结点起,自上而下,自左而右.则深度为k的,有
-
堆排序算法的讲解及Java版实现
堆是数据结构中的一种重要结构,了解了"堆"的概念和操作,可以快速掌握堆排序. 堆的概念 堆是一种特殊的完全二叉树(complete binary tree).如果一棵完全二叉树的所有节点的值都不小于其子节点,称之为大根堆(或大顶堆):所有节点的值都不大于其子节点,称之为小根堆(或小顶堆). 在数组(在0号下标存储根节点)中,容易得到下面的式子(这两个式子很重要): 1.下标为i的节点,父节点坐标为(i-1)/2: 2.下标为i的节点,左子节点坐标为2*i+1,右子节点为2*i+2. 堆
-
Java堆排序算法详解
堆是数据结构中的一种重要结构,了解"堆"的概念和操作,可以帮助我们快速地掌握堆排序. 堆的概念 堆是一种特殊的完全二叉树(complete binary tree).如果一棵完全二叉树的所有节点的值都不小于其子节点,称之为大根堆(或大顶堆):所有节点的值都不大于其子节点,称之为小根堆(或小顶堆). 在数组(在0号下标存储根节点)中,容易得到下面的式子(这两个式子很重要): 1.下标为i的节点,父节点坐标为(i-1)/2: 2.下标为i的节点,左子节点坐标为2*i+1,右子节点为2*i+
-
图解Java排序算法之堆排序
目录 预备知识 堆排序 堆 堆排序基本思想及步骤 再简单总结下堆排序的基本思路: 总结 预备知识 堆排序 堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序.首先简单了解下堆结构. 堆 堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆:或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆.如下图: 同时,我们对堆中的结点按层进行编号,将这种逻辑结构映射到数组中就是下面
-
图解Java排序算法之希尔排序
目录 基本思想 代码实现 总结 希尔排序是希尔(Donald Shell)于1959年提出的一种排序算法.希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,同时该算法是冲破O(n2)的第一批算法之一.本文会以图解的方式详细介绍希尔排序的基本思想及其代码实现. 基本思想 希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序:随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止. 简单插入排序很循规蹈
-
图解Java排序算法之归并排序
目录 基本思想 合并相邻有序子序列 代码实现 总结 基本思想 归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之). 分而治之 可以看到这种结构很像一棵完全二叉树,本文的归并排序我们采用递归去实现(也可采用迭代的方式去实现).分阶段可以理解为就是递归拆分子序列的过程,递归深
-
图解Java排序算法之3种简单排序
目录 简单选择排序 代码实现 冒泡排序 代码实现 直接插入排序 代码实现 总结 排序是数据处理中十分常见且核心的操作,虽说实际项目开发中很小几率会需要我们手动实现,毕竟每种语言的类库中都有n多种关于排序算法的实现.但是了解这些精妙的思想对我们还是大有裨益的.本文简单温习下最基础的三类算法:选择,冒泡,插入. 先定义个交换数组元素的函数,供排序时调用 /** * 交换数组元素 * @param arr * @param a * @param b */ public static void swap
-
图解Java排序算法之快速排序的三数取中法
目录 基本步骤 三数取中 根据枢纽值进行分割 代码实现 总结 基本步骤 三数取中 在快排的过程中,每一次我们要取一个元素作为枢纽值,以这个数字来将序列划分为两部分.在此我们采用三数取中法,也就是取左端.中间.右端三个数,然后进行排序,将中间数作为枢纽值. 根据枢纽值进行分割 代码实现 package sortdemo; import java.util.Arrays; /** * Created by chengxiao on 2016/12/14. * 快速排序 */ public class
-
Java排序算法总结之堆排序
本文实例讲述了Java排序算法总结之堆排序.分享给大家供大家参考.具体分析如下: 1991年计算机先驱奖获得者.斯坦福大学计算机科学系教授罗伯特·弗洛伊德(Robert W.Floyd)和威廉姆斯(J.Williams)在1964年共同发明了著名的堆排序算法( Heap Sort ).本文主要介绍堆排序用Java来实现. 堆积排序(Heapsort)是指利用堆积树(堆)这种资料结构所设计的一种排序算法,可以利用数组的特点快速定位指定索引的元素.堆排序是不稳定的排序方法,辅助空间为O(1), 最坏
-
Java 十大排序算法之堆排序刨析
二叉堆是完全二叉树或者是近似完全二叉树. 二叉堆满足二个特性︰ 1.父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值. 2.每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆). 任意节点的值都大于其子节点的值--大顶堆(最后输出从小到大排) 任意节点的值都小于其子节点的值---小顶堆(最后输出从大到小排) 堆排序步骤 1.堆化,反向调整使得每个子树都是大顶或者小顶堆(建堆) 2.按序输出元素∶把堆顶和最末元素对调,然后调整堆顶元素(排序) 堆排序代码实现(大顶堆) publ
-
图解Java经典算法冒泡选择插入希尔排序的原理与实现
目录 一.冒泡排序 1.基本介绍 2.代码实现 二. 选择排序 1.基本介绍 2.代码实现 三.插入排序 1.基本介绍 2.代码实现 四.希尔排序 1.基本介绍 2.代码实现(交换排序) 3.代码实现(移位排序) 一.冒泡排序 1.基本介绍 冒泡排序是重复地走访要排序的元素,依次比较两个相邻的元素,如果它们的顺序与自己规定的不符合,则把两个元素的位置交换.走访元素重复地进行,直到没有相邻元素需要交换为止,完成整个排序过程. 算法原理 1.比较相邻元素,如果前一个元素大于后一个元素,则交换. 2.
-
图解Java经典算法希尔排序的原理与实现
目录 希尔排序 算法思想 图解 代码实现(Java) 希尔排序 希尔排序时插入排序的一种,也称缩小增量排序,是直接插入排序的一种更高效的改进版本.希尔排序是非稳定排序算法. 算法思想 希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序,随着增量逐渐减少,每组包含的数越来越多当增量减至1时,整个序列恰好被分成一组,算法完成. 我们以增序排序为例,希尔排序基本步骤:选择初始增量gap=length/2,缩小增量继续以gap=gap/2的方式进行,直到增量gap=1为止,增量的每次变
-
盘点几种常见的java排序算法
目录 1.插入排序 2.分治排序法,快速排序法 3.冒泡排序 low版 4.冒泡排序 bigger版 5.选择排序 6. 归并排序 8. 堆排序 9. 其他排序 10. 比较 总结 1.插入排序 这个打麻将或者打扑克的很好理解, 比如有左手有一副牌1,2,4,7 ,来一张3的牌, 是不是就是手拿着这张牌从右往左插到2,4之间 一次插入排序的操作过程: 将待插元素,依次与已排序好的子数列元素从后到前进行比较,如果当前元素值比待插元素值大,则将移位到与其相邻的后一个位置,否则直接将待插元素插入当前元