pytorch SENet实现案例
我就废话不多说了,大家还是直接看代码吧~
from torch import nn class SELayer(nn.Module): def __init__(self, channel, reduction=16): super(SELayer, self).__init__() //返回1X1大小的特征图,通道数不变 self.avg_pool = nn.AdaptiveAvgPool2d(1) self.fc = nn.Sequential( nn.Linear(channel, channel // reduction, bias=False), nn.ReLU(inplace=True), nn.Linear(channel // reduction, channel, bias=False), nn.Sigmoid() ) def forward(self, x): b, c, _, _ = x.size() //全局平均池化,batch和channel和原来一样保持不变 y = self.avg_pool(x).view(b, c) //全连接层+池化 y = self.fc(y).view(b, c, 1, 1) //和原特征图相乘 return x * y.expand_as(x)
补充知识:pytorch 实现 SE Block
论文模块图
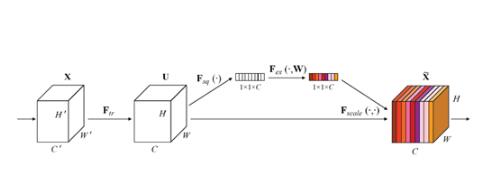
代码
import torch.nn as nn class SE_Block(nn.Module): def __init__(self, ch_in, reduction=16): super(SE_Block, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局自适应池化 self.fc = nn.Sequential( nn.Linear(ch_in, ch_in // reduction, bias=False), nn.ReLU(inplace=True), nn.Linear(ch_in // reduction, ch_in, bias=False), nn.Sigmoid() ) def forward(self, x): b, c, _, _ = x.size() y = self.avg_pool(x).view(b, c) y = self.fc(y).view(b, c, 1, 1) return x * y.expand_as(x)
现在还有许多关于SE的变形,但大都大同小异
以上这篇pytorch SENet实现案例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
在Pytorch中使用Mask R-CNN进行实例分割操作
在这篇文章中,我们将讨论mask R-CNN背后的一些理论,以及如何在PyTorch中使用预训练的mask R-CNN模型. 1.语义分割.目标检测和实例分割 之前已经介绍过: 1.语义分割:在语义分割中,我们分配一个类标签(例如.狗.猫.人.背景等)对图像中的每个像素. 2.目标检测:在目标检测中,我们将类标签分配给包含对象的包围框. 一个非常自然的想法是把两者结合起来.我们只想在一个对象周围识别一个包围框,并且找到包围框中的哪些像素属于对象. 换句话说,我们想要一个掩码,它指示(使用颜色或灰
-
Pytorch mask-rcnn 实现细节分享
DataLoader Dataset不能满足需求需自定义继承torch.utils.data.Dataset时需要override __init__, __getitem__, __len__ ,否则DataLoader导入自定义Dataset时缺少上述函数会导致NotImplementedError错误 Numpy 广播机制: 让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分都通过在前面加1补齐 输出数组的shape是输入数组shape的各个轴上的最大值 如果输入数组的某
-
PyTorch中model.zero_grad()和optimizer.zero_grad()用法
废话不多说,直接上代码吧~ model.zero_grad() optimizer.zero_grad() 首先,这两种方式都是把模型中参数的梯度设为0 当optimizer = optim.Optimizer(net.parameters())时,二者等效,其中Optimizer可以是Adam.SGD等优化器 def zero_grad(self): """Sets gradients of all model parameters to zero.""
-
利用PyTorch实现VGG16教程
我就废话不多说了,大家还是直接看代码吧~ import torch import torch.nn as nn import torch.nn.functional as F class VGG16(nn.Module): def __init__(self): super(VGG16, self).__init__() # 3 * 224 * 224 self.conv1_1 = nn.Conv2d(3, 64, 3) # 64 * 222 * 222 self.conv1_2 = nn.Co
-
pytorch SENet实现案例
我就废话不多说了,大家还是直接看代码吧~ from torch import nn class SELayer(nn.Module): def __init__(self, channel, reduction=16): super(SELayer, self).__init__() //返回1X1大小的特征图,通道数不变 self.avg_pool = nn.AdaptiveAvgPool2d(1) self.fc = nn.Sequential( nn.Linear(channel, cha
-
Pytorch实现LSTM案例总结学习
目录 前言 模型构建部分主要工作 1.构建网络层.前向传播forward() 2.实例化网络,定义损失函数和优化器 3.训练模型.反向传播backward() 4.测试模型 前言 关键步骤主要分为数据准备和模型构建两大部分,其中, 数据准备主要工作: 1.训练集和测试集的划分 2.训练数据的归一化 3.规范输入数据的格式 模型构建部分主要工作 1.构建网络层.前向传播forward() class LSTM(nn.Module):#注意Module首字母需要大写 def __init__(sel
-

pytorch dataset实战案例之读取数据集的代码
目录 概述 项目结构与代码 总结 参考资料 概述 最近在跑一篇图像修复论文的代码,配置好环境之后开始运行,发现数据一直加载不进去.害,还是得看人家代码咋写的,一句一句看逻辑,准能找出问题.通读dataset后,发现了问题所在,终于成功加载了数据集. 项目结构与代码 项目结构 主要的目的就是从数据集中读取到彩色图像和掩码图像.代码代码中涉及到torch.transforms.合并路径等知识点,我在代码中都进行了详细的注释,路径要对照着项目结构,如果自己用的话要根据项目结构去将相对路径改过来.dat
-
PyTorch实现重写/改写Dataset并载入Dataloader
前言 众所周知,Dataset和Dataloder是pytorch中进行数据载入的部件.必须将数据载入后,再进行深度学习模型的训练.在pytorch的一些案例教学中,常使用torchvision.datasets自带的MNIST.CIFAR-10数据集,一般流程为: # 下载并存放数据集 train_dataset = torchvision.datasets.CIFAR10(root="数据集存放位置",download=True) # load数据 train_loader = t
-
pytorch之inception_v3的实现案例
如下所示: from __future__ import print_function from __future__ import division import torch import torch.nn as nn import torch.optim as optim import numpy as np import torchvision from torchvision import datasets, models, transforms import matplotlib.py
-
pytorch单维筛选 相乘的案例
m需要和筛选的结果维度相同 >0.5运行的结果与原来维度相同,结果是 0 1,0代不符合,1代表符合. import torch m=torch.Tensor([0.1,0.2,0.3]).cuda() iou=torch.Tensor([0.5,0.6,0.7]) x= m * ((iou > 0.5).type(torch.cuda.FloatTensor)) print(x) 下面是把第一条与第二条变成了2: import torch m=torch.Tensor([0.1,0.2,0.
-
PyTorch中的squeeze()和unsqueeze()解析与应用案例
目录 1.torch.squeeze 2.torch.unsqueeze 3.例子 附上官网地址: https://pytorch.org/docs/stable/index.html 1.torch.squeeze squeeze的用法主要就是对数据的维度进行压缩或者解压. 先看torch.squeeze() 这个函数主要对数据的维度进行压缩,去掉维数为1的的维度,比如是一行或者一列这种,一个一行三列(1,3)的数去掉第一个维数为一的维度之后就变成(3)行.squeeze(a)就是将a中所有为
-
pytorch Dataset,DataLoader产生自定义的训练数据案例
1. torch.utils.data.Dataset datasets这是一个pytorch定义的dataset的源码集合.下面是一个自定义Datasets的基本框架,初始化放在__init__()中,其中__getitem__()和__len__()两个方法是必须重写的. __getitem__()返回训练数据,如图片和label,而__len__()返回数据长度. class CustomDataset(data.Dataset):#需要继承data.Dataset def __init_
-
运用PyTorch动手搭建一个共享单车预测器
本文摘自 <深度学习原理与PyTorch实战> 我们将从预测某地的共享单车数量这个实际问题出发,带领读者走进神经网络的殿堂,运用PyTorch动手搭建一个共享单车预测器,在实战过程中掌握神经元.神经网络.激活函数.机器学习等基本概念,以及数据预处理的方法.此外,还会揭秘神经网络这个"黑箱",看看它如何工作,哪个神经元起到了关键作用,从而让读者对神经网络的运作原理有更深入的了解. 3.1 共享单车的烦恼 大约从2016年起,我们的身边出现了很多共享单车.五颜六色.各式各样的共
-
详解PyTorch手写数字识别(MNIST数据集)
MNIST 手写数字识别是一个比较简单的入门项目,相当于深度学习中的 Hello World,可以让我们快速了解构建神经网络的大致过程.虽然网上的案例比较多,但还是要自己实现一遍.代码采用 PyTorch 1.0 编写并运行. 导入相关库 import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, t