使用Lucene实现一个简单的布尔搜索功能
什么是lucene
Lucene是apache软件基金会jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
Lucene是一个全文搜索框架,而不是应用产品。因此它并不像www.baidu.com 或者google Desktop那么拿来就能用,它只是提供了一种工具让你能实现这些产品。
在布尔查询的对象中,包含一个子句的集合,各个子句间都是如“与”、“或”这样的布尔逻辑。Lucene中所遇到的各种复杂查询,最终都可以表示成布尔型的查询。下面代码就是实现了一个简单的布尔查询。
package LuceneSearch;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.BooleanClause;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.Hits;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.TermQuery;
/**
* 布尔搜索测试
* @author sdu20
*
*/
public class BooleanQueryTest {
static final String INDEX_STORE_PATH = "E:\\编程局\\Java编程处\\Index\\";
public static void main(String[] args) {
// TODO Auto-generated method stub
try{
IndexWriter writer = new IndexWriter(INDEX_STORE_PATH,new StandardAnalyzer(),true);
writer.setUseCompoundFile(false);
//创建8个文档
Document doc1 = new Document();
Document doc2 = new Document();
Document doc3 = new Document();
Document doc4 = new Document();
Document doc5 = new Document();
Document doc6 = new Document();
Document doc7 = new Document();
Document doc8 = new Document();
Field f1 = new Field("bookname","钢铁是怎样炼成的",Field.Store.YES,Field.Index.TOKENIZED);
Field f2 = new Field("bookname","英雄儿女",Field.Store.YES,Field.Index.TOKENIZED);
Field f3 = new Field("bookname","浮生六记",Field.Store.YES,Field.Index.TOKENIZED);
Field f4 = new Field("bookname","太平广记",Field.Store.YES,Field.Index.TOKENIZED);
Field f5 = new Field("bookname","文化苦旅",Field.Store.YES,Field.Index.TOKENIZED);
Field f6 = new Field("bookname","白夜行",Field.Store.YES,Field.Index.TOKENIZED);
Field f7 = new Field("bookname","白毛女",Field.Store.YES,Field.Index.TOKENIZED);
Field f8 = new Field("bookname","子不语",Field.Store.YES,Field.Index.TOKENIZED);
doc1.add(f1);
doc2.add(f2);
doc3.add(f3);
doc4.add(f4);
doc5.add(f5);
doc6.add(f6);
doc7.add(f7);
doc8.add(f8);
writer.addDocument(doc1);
writer.addDocument(doc2);
writer.addDocument(doc3);
writer.addDocument(doc4);
writer.addDocument(doc5);
writer.addDocument(doc6);
writer.addDocument(doc7);
writer.addDocument(doc8);
writer.close();
System.out.println("创建索引成功");
IndexSearcher searcher = new IndexSearcher(INDEX_STORE_PATH);
//创建两个词条对象
Term t1 = new Term("bookname","生");
Term t2 = new Term("bookname","记");
TermQuery q1 = new TermQuery(t1);
TermQuery q2 = new TermQuery(t2);
BooleanQuery query = new BooleanQuery();
query.add(q1,BooleanClause.Occur.MUST);
query.add(q2,BooleanClause.Occur.MUST);
Hits hits = searcher.search(query);
for(int i = 0;i<hits.length();i++){
System.out.println(hits.doc(i));
}
System.out.println("搜索成功");
}catch(Exception e){
System.out.println(e.getStackTrace());
}
}
}
BooleanClause.Occur类主要有3种表示,即MUST、MUST_NOT和SHOULD。MUST与MUST_NOT不难理解,一看名字就知道是什么意思,而SHOULD是一个比较特殊的约束,当它与MUST联用时,它将失去意义。检索的结果为MUST子句的检索结果。当它与MUST_NOT联用时,SHOULD的功能就与MUST一样,就退变为MUST和MUST_NOT的查询结果。当SHOULD与SHOULD联用时,它们就表示一种“或”关系。最终检索结果为所有检索子句的检索结果的并集。
上面代码就是查询索引中有“生”字和“记”字的文档,程序运行结果截图如下
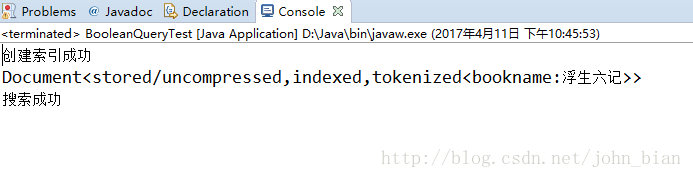
索引目录文件夹下截图如下
以上所述是小编给大家介绍的使用Lucene实现一个简单的布尔搜索功能,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-

使用Java的Lucene搜索工具对检索结果进行分组和分页
使用GroupingSearch对搜索结果进行分组 Package org.apache.lucene.search.grouping Description 这个模块可以对Lucene的搜索结果进行分组,指定的单值域被聚集到一起.比如,根据"author"域进行分组,"author"域值相同的的文档分成一个组. 进行分组的时候需要输入一些必要的信息: 1.groupField:根据这个域进行分组.比如,如果你使用"author"域进行分组,那么
-
基于ASP.NET的lucene.net全文搜索实现步骤
在做项目的时候,需求添加全文搜索,选择了lucene.net方向,调研了一下,基本实现了需求,现在将它分享给大家.理解不深请多多包涵. 在完成需求的时候,查看的大量的资料,本文不介绍详细的lucene.net工程建立,只介绍如何对文档进行全文搜索.对于如何建立lucene.net的工程请大家访问 使用lucene.net搜索分为两个部分,首先是创建索引,创建文本内容的索引,其次是根据创建的索引进行搜索.那么如何对文档进行索引呢,主要是对文档的内容进行索引,关键是提取出文档的内容,按照常规实现,由
-
使用Lucene.NET实现站内搜索
导入Lucene.NET 开发包 Lucene 是apache软件基金会一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎.Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎.Lucene.Net 是 .NET 版的Lucene. 你可以在这里下载到最新的Lucene.NET 创建索引.更新索引.删除索引 搜索,根据索引查找 IndexHelper
-
基于Lucene的Java搜索服务器Elasticsearch安装使用教程
一.安装Elasticsearch Elasticsearch下载地址:http://www.elasticsearch.org/download/ ·下载后直接解压,进入目录下的bin,在cmd下运行elasticsearch.bat 即可启动Elasticsearch ·用浏览器访问: http://localhost:9200/ ,如果出现类似如下结果则说明安装成功: { "name" : "Benedict Kine", "cluster_na
-
Java实现lucene搜索功能的方法(推荐)
直接上代码: package com.sand.mpa.sousuo; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; import java.io.PrintWriter; import java.sql.Connection; import java.sql.DriverMa
-
Lucene.Net实现搜索结果分类统计功能(中小型网站)
最近我们搜易站内搜索系统的一个客户需要一个无限级分类和分类统计功能,要实现的效果如下: 但由于搜易站内搜索系统是基于Lucene.net 2.0开发的,并没有内置的分类统计搜索功能,于是乎只能自己实现了,考虑到客户的总数据量和搜索量不是特别大,于是用了简单有效的方式来实现: 因为涉及到分类的操作,但是每个站点的分类体系还是有些不一样的,本文主要提供思路和部分演示代码,给有需要的童鞋参考: 思路: 首先想到Lucene搜索出来的结果是一个Hits对象,Hits其实就是一个搜索结果文档的集合对象,那
-
使用Lucene实现一个简单的布尔搜索功能
什么是lucene Lucene是apache软件基金会jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言). Lucene是一个全文搜索框架,而不是应用产品.因此它并不像www.baidu.com 或者google Desktop那么拿来就能用,它只是提供了一种工具让你能实现这些产品. 在布尔查询的对象中,包含一个子句的集合,各个子句间都是如
-
自己封装的一个简单的倒计时功能实例
因为平常工作中很常用到该功能,所以就利用这次国庆假期,重新梳理与对原有代码进行改善,再集成一个常用的功能,最终封装出这个"简单倒计时"功能. 该倒计时方法具有以下该功能: 1. 根据指定日期与当前的电脑时间进行匹配 2. 通过指定一个数组参数,来设置在每一天内不同的时间段进行倒计时. * 该方法还未通过实际工作的检测,稳定性未知(如果实际工作通过,会删除这段话) function countDown(date,target,filter){ var setTime = new Date
-
vue实现一个简单的分页功能实例详解
这是一个简单的分页功能,只能够前端使用,数据不能通过后台服务器进行更改,能容已经写死了. 下面的内容我是在做一个关于婚纱项目中用到的,当时好久没用vue了,就上网区找了别人的博客来看,发现只有关于element_ui的,基本全是,对自己没用什么用,就自己写了一个,效果如下: 点击相应的按钮切换到对应的内容内容: 下面我只发核心代码,css样式就不发了,自己想怎么写怎么写 <!-- 分页内容 --> <ul class="blog-lists-box"> <
-
jQuery实现一个简单的验证码功能
在学习jQuery过程中,写的一个简单的验证码的小例子,记载下来,方便以后借鉴补充,源码如下: <!DOCTYPE html> <html> <head> <title></title> <style type="text/css"> div{ background-color:blue; width:200px; height:100px; font-size:35px; } </style> <
-
nodejs实现的一个简单聊天室功能分享
今天我来实现一个简单的聊天室,后台用nodejs, 客户端与服务端通信用socket.io,这是一个比较成熟的websocket框架. 初始工作 1.安装express, 用这个来托管socket.io,以及静态页面,命令npm install express --save,--save可以使包添加到package.json文件里. 2.安装socket.io,命令npm install socket.io --save. 编写服务端代码 首先我们通过express来托管网站,并附加到socke
-
PHP实现一个简单url路由功能实例
什么是php的路由机制 1.路由机制就是把某一个特定形式的URL结构中提炼出来系统对应的参数.举个例子,如:http://main.test.com/article/1 其中:/article/1 -> ?_m=article&id=1. 2.然后将拥有对应参数的URL转换成特定形式的URL结构,是上面的过程的逆向过程. 如果一个页面的内容呈现,需要根据url上传递的参数来进行渲染.很多时候可能是这样子写:xxx.com/xx?c=x&m=x&t=..,而我们看到的url
-
Angularjs制作简单的路由功能demo
从官网下载了最新版本的Angularjs 版本号:1.3.15 做一个简单的路由功能demo 首页:index.html <!DOCTYPE html > <html> <head> <meta charset="utf-8" /> <title>测试</title> <script src="./js/angular.min.js"></script> <scri
-
React Native实现简单的登录功能(推荐)
React Native 简介: React Native 结合了 Web 应用和 Native 应用的优势,可以使用 JavaScript 来开发 iOS 和 Android 原生应用.在 JavaScript 中用 React 抽象操作系统原生的 UI 组件,代替 DOM 元素来渲染等. React Native 使你能够使用基于 JavaScript 和 React 一致的开发体验在本地平台上构建世界一流的应用程序体验.React Native 把重点放在所有开发人员关心的平台的开发效率上
-
使用MongoDB和JSP实现一个简单的购物车系统实例
本文介绍了JSP编程技术实现一个简单的购物车程序,具体如下: 1 问题描述 利用JSP编程技术实现一个简单的购物车程序,具体要求如下. (1)用JSP编写一个登录页面,登录信息中有用户名和密码,分别用两个按钮来提交和重置登录信息. (2)编写一个JSP程序来获取用户提交的登录信息并查询数据库,如果用户名为本小组成员的名字且密码为对应的学号时,采用JSP内置对象的方法跳转到订购页面(显示店中商品的种类和单价等目录信息):否则采用JSP动作提示用户重新登录(注:此页面上要包含前面的登录界面). (3
-
Python实现简单生成验证码功能【基于random模块】
本文实例讲述了Python实现简单生成验证码功能.分享给大家供大家参考,具体如下: 验证码一般用来验证登陆.交易等行为,减少对端为机器操作的概率,python中可以使用random模块,char()内置函数来实现一个简单的验证码功能. import random def veri_code(): li = [] for i in range(6): #循环6次,生成6个字符 r = random.randrange(0, 5) #随机生成0-4之间的数字 if r == 1 or r == 4: