python模块之time模块(实例讲解)
time
表示时间的三种形式
时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
格式化的时间字符串(Format String): ‘1999-12-06'
时间格式化符号
''' %y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身 '''
元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等
元组元素意
""" 索引(Index)属性(Attribute) 值(Values) tm_year(年) 比如2011 tm_mon(月) 1 - 12 tm_mday(日) 1 - 31 tm_hour(时) 0 - 23 tm_min(分) 0 - 59 tm_sec(秒) 0 - 61 tm_wday(weekday) 0 - 6(0表示周日) tm_yday(一年中的第几天) 1 - 366 tm_isdst(是否是夏令时) 默认为-1 """
python中表示时间的几种格式
#导入时间模块
>>>import time
#时间戳
>>>time.time()
1500875844.800804
#时间字符串
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 13:54:37'
>>>time.strftime("%Y-%m-%d %H-%M-%S")
'2017-07-24 13-55-04'
#时间元组:localtime将一个时间戳转换为当前时区的struct_time
time.gmtime()
time.localtime()
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24,
tm_hour=13, tm_min=59, tm_sec=37,
tm_wday=0, tm_yday=205, tm_isdst=0)
# 小结:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间
各种格式化时间之间的转换
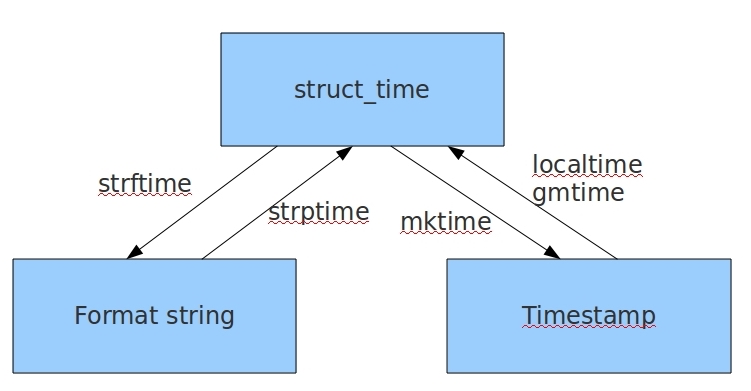
#时间戳-->结构化时间 #time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致 #time.localtime(时间戳) #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间 >>>time.gmtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) >>>time.localtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) #结构化时间-->时间戳 #time.mktime(结构化时间) >>>time_tuple = time.localtime(1500000000) >>>time.mktime(time_tuple) 1500000000.0
#结构化时间-->字符串时间
#time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则现实当前时间
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 14:55:36'
>>>time.strftime("%Y-%m-%d",time.localtime(1500000000))
'2017-07-14'
#字符串时间-->结构化时间
#time.strptime(时间字符串,字符串对应格式)
>>>time.strptime("2017-03-16","%Y-%m-%d")
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1)
>>>time.strptime("07/24/2017","%m/%d/%Y")
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
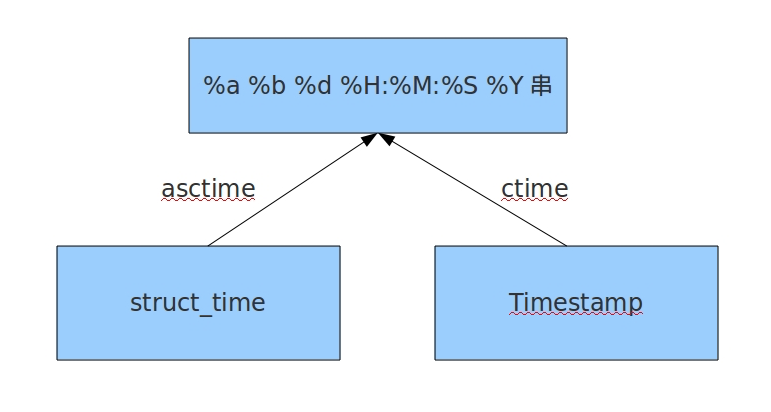
#结构化时间 --> %a %b %d %H:%M:%S %Y串 #time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串 >>>time.asctime(time.localtime(1500000000)) 'Fri Jul 14 10:40:00 2017' >>>time.asctime() 'Mon Jul 24 15:18:33 2017' #%a %d %d %H:%M:%S %Y串 --> 结构化时间 #time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串 >>>time.ctime() 'Mon Jul 24 15:19:07 2017' >>>time.ctime(1500000000) 'Fri Jul 14 10:40:00 2017'
计算时间差
import time
true_time=time.mktime(time.strptime('2017-09-11 08:30:00','%Y-%m-%d %H:%M:%S'))
time_now=time.mktime(time.strptime('2017-09-12 11:00:00','%Y-%m-%d %H:%M:%S'))
dif_time=time_now-true_time
struct_time=time.gmtime(dif_time)
print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(struct_time.tm_year-1970,struct_time.tm_mon-1,
struct_time.tm_mday-1,struct_time.tm_hour,
struct_time.tm_min,struct_time.tm_sec))
以上这篇python模块之time模块(实例讲解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python创建对称矩阵的方法示例【基于numpy模块】
本文实例讲述了Python创建对称矩阵的方法.分享给大家供大家参考,具体如下: 对称(实对称)矩阵也即: step 1:创建一个方阵 >>> import numpy as np >>> X = np.random.rand(5**2).reshape(5, 5) >>> X array([[ 0.26984148, 0.25408384, 0.12428487, 0.0194565 , 0.91287708], [ 0.31837673, 0.354
-
基于python select.select模块通信的实例讲解
要理解select.select模块其实主要就是要理解它的参数, 以及其三个返回值. select()方法接收并监控3个通信列表, 第一个是所有的输入的data,就是指外部发过来的数据,第2个是监控和接收所有要发出去的data(outgoing data),第3个监控错误信息在网上一直在找这个select.select的参数解释, 但实在是没有, 哎...自己硬着头皮分析了一下. readable, writable, exceptional = select.select(inputs, ou
-
python中hashlib模块用法示例
我们以前介绍过一篇Python加密的文章:Python 加密的实例详解.今天我们看看python中hashlib模块用法示例,具体如下. hashlib hashlib主要提供字符加密功能,将md5和sha模块整合到了一起,支持md5,sha1, sha224, sha256, sha384, sha512等算法 具体应用 #!/usr/bin/env python # -*- coding: UTF-8 -*- #pyversion:python3.5 #owner:fuzj import h
-
Python基于time模块求程序运行时间的方法
本文实例讲述了Python基于time模块求程序运行时间的方法.分享给大家供大家参考,具体如下: 要记录程序的运行时间可以利用Unix系统中,1970.1.1到现在的时间的毫秒数,这个时间戳轻松完成. 方法是程序开始的时候取一次存入一个变量,在程序结束之后取一次再存入一个变量,与程序开始的时间戳相减则可以求出. Python中取这个时间戳的方法为引入time类之后,使用time.time();就能够拿出来.也就是Java中的System.currentTimeMillis(). 由于Python
-
python3使用requests模块爬取页面内容的实战演练
1.安装pip 我的个人桌面系统用的linuxmint,系统默认没有安装pip,考虑到后面安装requests模块使用pip,所以我这里第一步先安装pip. $ sudo apt install python-pip 安装成功,查看PIP版本: $ pip -V 2.安装requests模块 这里我是通过pip方式进行安装: $ pip install requests 运行import requests,如果没提示错误,那说明已经安装成功了! 检验是否安装成功 3.安装beautifulsou
-
Python使用文件锁实现进程间同步功能【基于fcntl模块】
本文实例讲述了Python使用文件锁实现进程间同步功能.分享给大家供大家参考,具体如下: 简介 在实际应用中,会出现这种应用场景:希望shell下执行的脚本对某些竞争资源提供保护,避免出现冲突.本文将通过fcntl模块的文件整体上锁机制来实现这种进程间同步功能. fcntl系统函数介绍 Linux系统提供了文件整体上锁(flock)和更细粒度的记录上锁(fcntl)功能,底层功能均可由fcntl函数实现. 首先来了解记录上锁.记录上锁是读写锁的一种扩展类型,它可用于有亲缘关系或无亲缘关系的进程间
-
Python中使用hashlib模块处理算法的教程
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等. 什么是摘要算法呢?摘要算法又称哈希算法.散列算法.它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示). 举个例子,你写了一篇文章,内容是一个字符串'how to use python hashlib - by Michael',并附上这篇文章的摘要是'2d73d4f15c0db7f5ecb321b6a65e5d6d'.如果有人篡改了你的文章,并发表为'how to use pytho
-
基于node.js的fs核心模块读写文件操作(实例讲解)
node.js 里fs模块 常用的功能 实现文件的读写 目录的操作 - 同步和异步共存 ,有异步不用同步 - fs.readFile 都不能读取比运行内存大的文件,如果文件偏大也不会使用readFile方法 - 文件大分流读取,stream - 引入fs模块 - let fs=require('fs') 同步读取文件 -fs.readFileSync('路径',utf8); let result=fs.readFileSync('./1.txt','utf8'); 异步读取文件,用参数err捕获
-
Python数据处理numpy.median的实例讲解
numpy模块下的median作用为: 计算沿指定轴的中位数 返回数组元素的中位数 其函数接口为: median(a, axis=None, out=None, overwrite_input=False, keepdims=False) 其中各参数为: a:输入的数组: axis:计算哪个轴上的中位数,比如输入是二维数组,那么axis=0对应行,axis=1对应列: out:用于放置求取中位数后的数组. 它必须具有与预期输出相同的形状和缓冲区长度: overwrite_input:一个bool
-
celery在python爬虫中定时操作实例讲解
使用定时功能对于我们想要快速获取某个数据来说,是一个非常好的方法.这样我们就不用苦苦守在电脑屏幕前,只为蹲到某个想要的东西.在之前我们已经讲过time函数进行定时操作,这算是time函数的比较基础的一个用法了.其实定时功能同样可以用celery实现,具体的方法我们往下看: 爬虫由于其特殊性,可能需要定时做增量抓取,也可能需要定时做模拟登陆,以防止cookie过期,而celery恰恰就实现了定时任务的功能.在上述基础上,我们将`tasks.py`文件改成如下内容 from celery impor
-
python进行二次方程式计算的实例讲解
算法,是一种执行步骤,如果我们想要要做一件事情,就会规划好行动步骤.而算法,就是我们所编程序的执行步骤.算法在编程使用过程中至关重要.二次方程式大家很熟悉,是一种整式方程,其未知项的最高次数是2.根的判定是利用判别式判定,可以进行计算复杂数学运算.下面我们就来拿二次方程练练手,在python中求取二次方程. 示例:计算二次方程式 ax**2 + bx + c = 0 注意:首先要导入 math模块 代码: import math import unicodedata def is_number(
-
requests在python中发送请求的实例讲解
当我们想给服务器发送一些请求时,可以选择requests库来实现.相较于其它库而言,这种库的使用还是非常适合新手使用的.本篇要讲的是requests.get请求方法,这里需要先对get请求时的一些参数进行学习,在掌握了基本的用法后,可以就下面的requests.get请求实例进一步的探究. 1.get请求的部分参数 (1) url(请求的url地址,必需 ) import requests url="http://www.baidu.com" resp=requests.get(url
-
python数据结构之链表的实例讲解
在程序中,经常需要将⼀组(通常是同为某个类型的)数据元素作为整体 管理和使⽤,需要创建这种元素组,⽤变量记录它们,传进传出函数等. ⼀组数据中包含的元素个数可能发⽣变化(可以增加或删除元素). 对于这种需求,最简单的解决⽅案便是将这样⼀组元素看成⼀个序列,⽤ 元素在序列⾥的位置和顺序,表示实际应⽤中的某种有意义的信息,或者 表示数据之间的某种关系. 这样的⼀组序列元素的组织形式,我们可以将其抽象为线性表.⼀个线性 表是某类元素的⼀个集合,还记录着元素之间的⼀种顺序关系.线性表是 最基本的数据结构
-
Python网络爬虫与信息提取(实例讲解)
课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解析HTML页面 4.Re框架:正则框架,提取页面关键信息 5.Scrapy框架:网络爬虫原理介绍,专业爬虫框架介绍 理念:The Website is the API ... Python语言常用的IDE工具 文本工具类IDE: IDLE.Notepad++.Sublime Text.Vim & Emacs.Atom.Komodo E
-
python增加矩阵维度的实例讲解
numpy.expand_dims(a, axis) Examples >>> x = np.array([1,2]) >>> x.shape (2,) >>> y = np.expand_dims(x, axis=0) >>> y array([[1, 2]]) >>> y.shape (1, 2) >>> y = np.expand_dims(x, axis=1) # Equivalent to
-
对Python 网络设备巡检脚本的实例讲解
1.基本信息 我公司之前采用的是人工巡检,但奈何有大量网络设备,往往巡检需要花掉一上午(还是手速快的话),浪费时间浪费生命. 这段时间正好在学 Python ,于是乎想(其)要(实)解(就)放(是)双(懒)手. 好了,脚本很长又比较挫,有耐心就看看吧. 需要巡检的设备如下: 设备清单 设备型号 防火墙 华为 E8000E H3C M9006 飞塔 FG3950B 交换机 华为 S9306 H3C S12508 Cisco N7K 路由器 华为 NE40E 负载 Radware RD5412 Ra
-
对python 矩阵转置transpose的实例讲解
在读图片时,会用到这么的一段代码: image_vector_len = np.prod(image_size)#总元素大小,3*55*47 img = Image.open(path) arr_img = np.asarray(img, dtype='float64') arr_img = arr_img.transpose(2,0,1).reshape((image_vector_len, ))# 47行,55列,每个点有3个元素rgb.再把这些元素一字排开 transpose是什么意识呢?