大数据量时提高分页的效率
如我们在之前的教程里讨论的那样,分页可以通过两种方法来实现:
- 默认分页– 你仅仅只用选中data Web control的 智能标签的Enable Paging ; 然而,当你浏览页面的时候,虽然你看到的只是一小部分数据,ObjectDataSource 还是会每次都读取所有数据
- 自定义分页– 通过只从数据库读取用户需要浏览的那部分数据,提高了性能. 显然这种方法需要你做更多的工作.
默认的分页功能非常吸引人,因为你只需要选中一个checkbox就可以完成了.但是它每次都读取所有的数据,这种方式在大数据量或者并发用户多的情况下就不合适.在这样的情况下,我们必须通过自定义分页来使系统达到更好的性能.
自定义分页的一个重点是要写一个返回仅仅需要的数据的查询语句.幸运的,Microsoft SQL Server 2005 提供了一个新的keyword,通过它我们可以写出读取需要的数据的查询.在本教程里,我们将学习在GridView里如何使用Microsoft SQL Server 2005 的这个新的keyword来实现自定义分页.自定义分页和默认分页的界面看起来一样,但是当你从一页转到另一页时,在效率上差了几个数量级.
注意:自定义分页带来的性能提升程序取决于数据的总量和数据库的负载.在本教程的最后我们会用数据来说明自定义分页带来的性能方面的好处.
第一步: 理解自定义分页的过程
给数据分页的时候,页面显示的数据取决于请求的是哪一页和每页显示多少条.比如,想象以下我们给81个product分页,每页显示10条.当我们浏览第一页时,我们需要的是product 1 到 product 10.当浏览第二页时,我们需要的是product 11 到 product 20,以次类推.
对于需要读取什么数据和分页的页面怎么显示,有三个相关的变量:
- Start Row Index – 页面里显示数据的第一行的索引; 这个值可以通过页的索引乘每页显示的记录的条数加1得到. 例如, 如果一页显示10条数据, 那么对第一页来说(第一页的索引为0), 第一行的索引为0 * 10 + 1, or 1; 对第二页来说(索引为1), 第一行的索引为1 * 10 + 1, 即 11.
- Maximum Rows – 每页显示的最多记录的条数. 之所以称为“maximum” rows 是由于最后一页显示的数据可能会比page size要小. 比如, 当以每页10条记录来显示81条时, 最后一页也就是第九页只包含一条记录. 没有页面显示的记录条数会大于Maximum Rows 的值.
- Total Record Count – 显示数据的总条数. 不需要知道页面显示什么数据,但是记录总数会影响到分页. 比如, 如果对81条product记录分页,每页10条,那么总页数为9.
对默认分页来说,Start Row Index是由页索引和每页的记录数加1得到,Maximum Rows 就是每页的记录数.使用默认分页时,不管是呈现哪页的数据,都是要读取全部的数据,所有每行的索引都是已知的,这样获取Start Row Index变的没有价值.而且,记录的总条数是可以通过DataTable的总条数来获取的.
自定义分页只返回从Start Row Index 开始的Maximum Rows条记录.在这里有两个要注意的地方:
- 我们必须把整个要分页的数据和一个row index关联起来,这样才能从指定的Start Row Index 开始返回需要的数据.
- 我们需要提供用来分页的数据的总条数.
在后面的两步里我们将写出和上面两点相关的SQL.除此之外,我们还将在DAL和BLL里完成相应的方法.
第二步: 返回需要分页的记录的总条数
在我们学习如何返回显示页面需要的数据之前,我们先来看看怎么获取数据的总条数.因为在配置界面的时候需要用到这个信息.我们使用SQL的COUNT aggregate function来实现这个.比如,返回Products表的总记录条数,我们可以用如下的语句:
| SQL | |
1 | SELECT COUNT(*) |
我们在DAL里添加一个方法来返回这个信息.这个方法名为TotalNumberOfProducts() ,它会执行上面的SQL语句.
打开App_Code/DAL 文件夹里的 Northwind.xsd .然后在设计器里右键点ProductsTableAdapter ,选择Add Query.和我们在以前的教程里学习的那样,这样会允许我们添加一个新的DAL方法,这个方法被调用时会执行指定的SQL或存储过程.和前面的 TableAdapter 方法一样,为这个添加一个SQL statement.
图 1: 使用 SQL Statement
在下一个窗体我们可以指定创建哪种SQL .由于查询只返回一个值–Products表的总记录条数–我们选择“SELECT which returns a singe value”.

图 2: 使用 SELECT Statement that Returns a Single Value来配置SQL
下一步是写SQL语句.
图 3: 使用SELECT COUNT(*) FROM Products 语句
最后给这个方法命名为TotalNumberOfProducts.
图 4: 将方法命名为 TotalNumberOfProducts
点击结束后,DAL里添加了一个TotalNumberOfProducts方法.这个方法返回的值可为空,而Count语句总是返回一个非空的值.
我们还需要在BLL中加一个方法.打开ProductsBLL类文件,添加一个TotalNumberOfProducts方法,这个方法要做的只是调用DAL的TotalNumberOfProducts方法.
| C# | |
1 | public int TotalNumberOfProducts() |
DAL的TotalNumberOfProducts方法返回一个可空的整型,而需要ProductsBLL类的TotalNumberOfProducts方法返回一个标准的整型.调用GetValueOrDefault方法,如果可为空的整型为空,则返回默认值,0.
第三步: 返回需要的数据记录
下一步我们要在DAL和BLL里创建接受Start Row Index 和Maximum Rows 的方法,然后返回合适的记录.我们首先看看需要的SQL语句.我们面临的挑战是需要为整个分页的记录分配索引,用来返回从Start Row Index 开始的Maximum Records number of records条记录.
如果在数据库表里已经有一个列作为索引,那么一切会变的很简单.我们首先会想到Products表的ProductID字段可以满足这个条件,第一个 Product的ProductID为1,第二个为2,以此类推.然而当一个product被删除后,这个序列会留下间隔来,所以这个方法不行.
有两种可以把整个要分页的数据和一个row index关联起来的方法.
- 使用SQL Server 2005的ROW_NUMBER() Keyword – SQL Server 2005的新特性,它可以将记录根据一定的顺序排列,每条记录和一个等级相关 这个等级可以用来作为每条记录的row index.
- 使用SET ROWCOUNT – SQL Server的 SET ROWCOUNT statement 可以用来指定有多少记录需要处理; table variables 是可以存放表格式的T-SQL 变量, 和temporary tables类似. 这个方法在Microsoft SQL Server 2005 和SQL Server 2000都可以用 (ROW_NUMBER() 方法只能在SQL Server 2005里用).
这个思路是,为要分页的数据创建一个table变量,这个table变量里有一个作为主健的IDENTITY列.这样需要分页的每条记录在table变量里就和一个row index(通过IDENTITY列)关联起来了.一旦table变量产生,连接数据库表的SELECT语句就被执行,获取需要的记录.SET ROWCOUNT用来限制放到table变量里的记录的数量.
当SET ROWCOUNT的值指定为Start Row Index 加上Maximum Rows时,这个方法的效率取决于被请求的页数.对于比较前面的页来说– 比如开始几页的数据– 这种方法非常有效. 但是对接近尾部的页来说,这种方法的效率和默认分页时差不多.
本教程用ROW_NUMBER()来实现自定义分页.如果需要知道更多的关于table变量和SET ROWCOUNT的技术,请看 A More Efficient Method for Paging Through Large Result Sets.
以下语句用来使用ROW_NUMBER()将一个等级和返回的每条记录关联:
| SQL | |
1 | SELECT columnList, |
ROW_NUMBER()返回一个根据指定排序的表示每条记录的等级的值.比如,我们可以用以下居于查看根据价格来排序(降序)的每个product的等级:
| SQL | |
1 | SELECT ProductName, UnitPrice, |
图5 是在Visual Studio里运行以上代码的结果. 注意product根据价格排序,每行有一个等级.
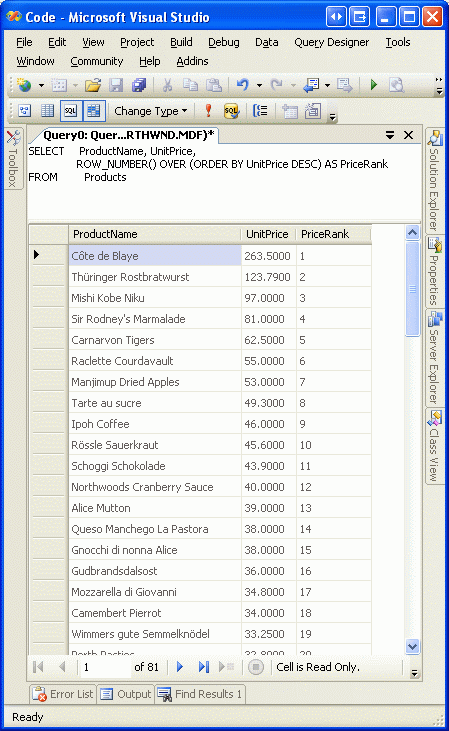
图 5: 返回的记录里每行有一个Price Rank
注意: ROW_NUMBER() 只是 SQL Server 2005里很多排级的功能中的一种. 想了解更多的ROW_NUMBER()的讨论,包括其它的排级功能,请看 Returning Ranked Results with Microsoft SQL Server 2005.
当使用OVER从句里的ORDER BY 列名(UnitPrice)来排级时,SQL Server会对结果排序.为了提升大数据量查询时的性能,可以为用来排序的列加上非聚集索引.更多的性能考虑参考Ranking Functions and Performance in SQL Server 2005.
ROW_NUMBER()返回的等级信息无法直接在WHERE从句中使用.而在From后面的Select里可以返回ROW_NUMBER(),并在 WHERE从句里使用.比如,下面的语句使用一个From后的Select返回ProductName,UnitPrice,和ROW_NUMBER() 的结果,然后使用一个WHERE从句来返回price rank在11到20之间的product.
| SQL | |
1 | SELECT PriceRank, ProductName, UnitPrice |
更进一步,我们可以根据这个方法返回给定Start Row Index 和Maximum Rows 的页的数据.
| SQL | |
1 | SELECT PriceRank, ProductName, UnitPrice |
注意:我们在本教程的后面会看到, ObjectDataSource 提供的StartRowIndex是从0开始的,而ROW_NUMBER()的值从1开始.因此,WHERE从句返回会严格返回PriceRank大于 StartRowIndex而小于StartRowIndex+MaximumRows的那些记录.
我们已经知道如何根据给定的Start Row Index 和Maximum Rows 用ROW_NUMBER()返回特定页的数据.现在我们需要在DAL和BLL里实现它.
我们首先要决定根据什么排序来分级.我们这里用product名字的字母顺序.这意味着我们还不能同时实现排序的功能.在后面的教程里,我们将学习如何实现这样的功能.
在前面我们使用SQL statement创建DAL方法.但是TableAdapter wizard 使用的Visual Stuido里的T-SQL 解析器不能识别带OVER语法的ROW_NUMBER()方法.因此我们要以存储过程来创建这个DAL方法.从view menu里选择server explorer(Ctrl+Alt+S),展开NORTHWND.MDF 的节点.右键点击存储过程,选择增加一个新的存储过程(见图6).
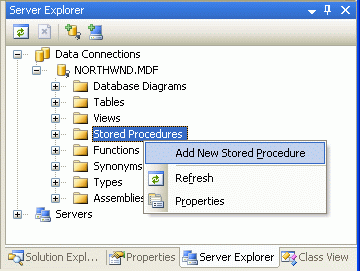
图 6: 为Products分页增加一个存储过程
这个存储过程带两个整型的输入参数- @startRowIndex和@maximumRows- 并用ROW_NUMBER()以ProductName字段排序,返回那些大于@startRowIndex并小于等于 @startRowIndex+@maximumRows的记录.将以下代码加到存储过程里,然后保存.
| SQL | |
1 | CREATE PROCEDURE dbo.GetProductsPaged |
创建完存储过程后,花点时间测试一下.右键在Server Explorer 点名为GetProductsPaged的存储过程,选择执行.Visual Studio 会让你输入参数, @startRowIndex和@maximumRows(见图7).输入不同的值查看一下结果是什么.
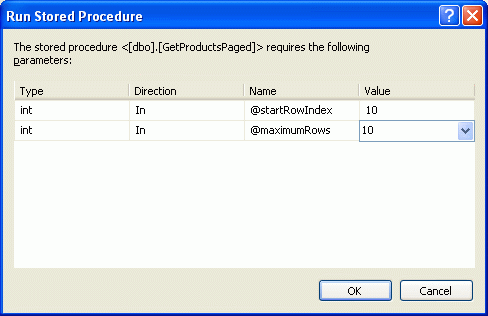
图 7: 为 @startRowIndex 和@maximumRows Parameters输入值
输入参数的值后,你会看到结果.图8的结果为两个参数的值都为10的结果.
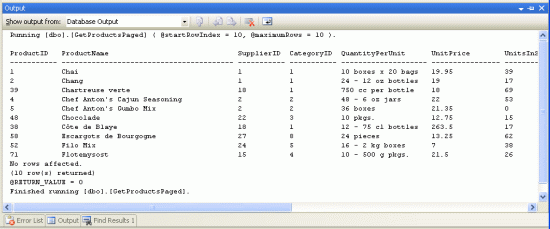
图 8: 将在第二页里显示的数据
完成存储过程后,我们可以创建ProductsTableAdapter 方法了.打开Northwind.xsd ,右键点ProductsTableAdapter,选择Add Query.选择使用已经存在的存储过程.
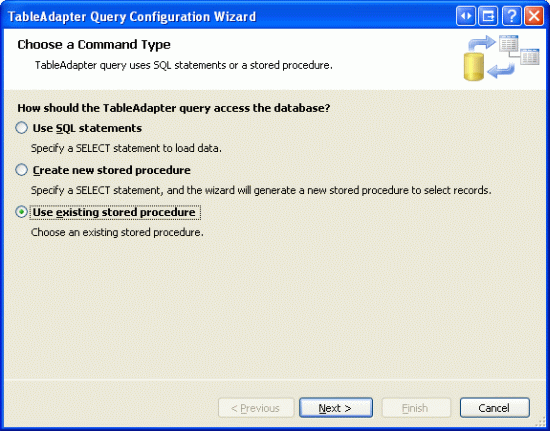
图 9: 使用已经存在的存储过程创建DAL Method
下一步会要我们选择要调用的存储过程.从下拉列表里选择GetProductsPaged .
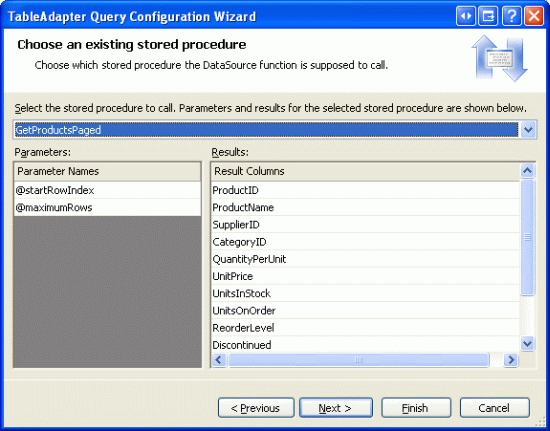
图10: 选择GetProductsPaged
下一步要选择存储过程返回的数据类型:表值,单一值,无值.由于GetProductsPaged 返回多条记录,所以选择表值.
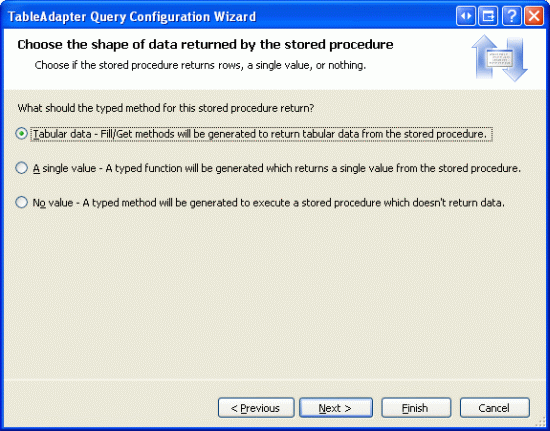
图 11: 为存储过程指定返回表值
最后给方法命名.象前面的方法一样,选择Fill a DataTable 和Return a DataTable,为第一个命名为FillPaged ,第二个为GetProductsPaged.
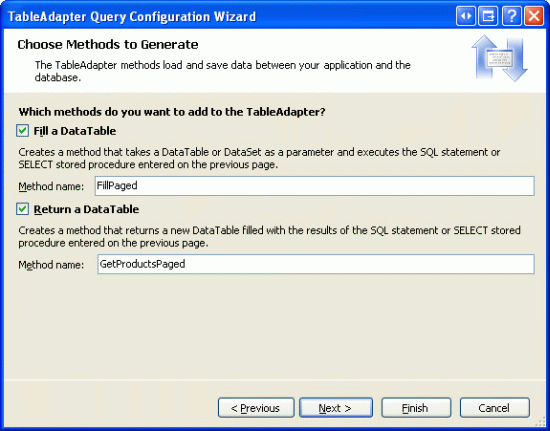
图 12: 命名方法为FillPaged 和GetProductsPaged
除了创建一个DAL方法返回特定页的products外,我们需要在BLL里也这样做.和DAL方法一样,BLL的GetProductsPaged 方法带两个整型的输入参数,分别为Start Row Index 和Maximum Rows,并返回在指定范围内的记录.在ProductsBLL 创建这个方法,仅仅调用DAL的GetProductsPaged 就可以了.
| C# | |
1 | [System.ComponentModel.DataObjectMethodAttribute(System.ComponentModel.DataObjectMethodType.Select, false)] |
你可以为BLL方法的参数取任何名字.但是我们马上会看到,选择用startRowIndex 和maximumRows 会让我们在配置ObjectDataSource 时方便很多.
相关推荐
-
数据库高并发情况下重复值写入的避免 字段组合约束
10线程同时操作,频繁出现插入同样数据的问题.虽然在插入数据的时候使用了: insert inti tablename(fields....) select @t1,@t2,@t3 from tablename where not exists (select id from tablename where t1=@t1,t2=@t2,t3=@t3) 当时还是在高并发的情况下无效.此语句也包含在存储过程中.(之前也尝试线判断有无记录再看是否写入,无效). 因此,对于此类情况还是需要从数据库的根本
-
mysql数据库sql优化原则(经验总结)
一.前提 这里的原则只是针对MySQL数据库,其他的数据库某些是殊途同归,某些还是存在差异.我总结的也是MySQL普遍的规则,对于某些特殊情况得特殊对待.在构造SQL语句的时候要养成良好的习惯. 二.原则总结 原则1.仅列出需要查询的字段,这对速度不会明显的影响,主要是考虑节省应用程序服务器的内存. 原来语句: select * from admin 优化为: select admin_id,admin_name,admin_password from admin 原则2.尽量避免在列上做运算,
-
关于数据库优化问题收集汇总
人们在使用SQL时往往会陷入一个误区,即太关注于所得的结果是否正确,而忽略了不同的实现方法之间可能存在的性能差异,这种性能差异在大型的或是复杂的数据库环境中(如联机事务处理OLTP或决策支持系统DSS)中表现得尤为明显. 笔者在工作实践中发现,不良的SQL往往来自于不恰当的索引设计.不充份的连接条件和不可优化的where子句. 在对它们进行适当的优化后,其运行速度有了明显地提高! 下面将从这三个方面分别进行总结: 为了更直观地说明问题,所有实例中的SQL运行时间均经过测试,不超过1秒的均表示为(
-
超大数据量存储常用数据库分表分库算法总结
当一个应用的数据量大的时候,我们用单表和单库来存储会严重影响操作速度,如mysql的myisam存储,我们经过测试,200w以下的时候,mysql的访问速度都很快,但是如果超过200w以上的数据,他的访问速度会急剧下降,影响到我们webapp的访问速度,而且数据量太大的话,如果用单表存储,就会使得系统相当的不稳定,mysql服务很容易挂掉.所以当数据量超过200w的时候,建议系统工程师还是考虑分表. 以下是几种常见的分表算法. 1.按自然时间来分表/分库; 如一个应用的数据在一年后数据量会达到2
-
oracle数据库sql的优化总结
一:使用where少使用having; 二:查两张以上表时,把记录少的放在右边: 三:减少对表的访问次数: 四:有where子查询时,子查询放在最前: 五:select语句中尽量避免使用*(执行时会把*依次转换为列名): 六:尽量多的使用commit: 七:Decode可以避免重复扫描相同的记录或重复连接相同的表: 八:通过内部函数也可提高sql效率: 九:连接多个表时,使用别名并把别名前缀于每个字段上: 十:用exists代替in 十一:not exists代替 not in(not in 字
-
Oracle 数据库优化实战心得总结
1.优化应用程序和业务逻辑,这个是最重要的. 2.数据库设计阶段范式和反范式的灵活应用.一般情况下,对于频繁访问但是不频繁修改的数据,内部设计应当物理不规范化:对于频繁修改但并不频繁访问的数据,内部设计应当物理规范化. 3.充分利用内存,优化sga.pga等(11g已经实现了sga+pga自动化,但有的时候仍然需要手动进行调整),适当的将小表keep到cache中. 4.优化sql语句 1)减少对数据库的查询次数,即减少对系统资源的请求,使用快照和显形图等分布式数据库对象可以减少对数据库的查询次
-
MySQL数据库优化经验详谈(服务器普通配置)第1/3页
安装好mysql后,配制文件应该在/usr/local/mysql/share/mysql目录中,配制文件有几个,有my- huge.cnf my-medium.cnf my-large.cnf my-small.cnf,不同的流量的网站和不同配制的服务器环境,当然需要有不同的配制文件了. 一般的情况下,my-medium.cnf这个配制文件就能满足我们的大多需要:一般我们会把配置文件拷贝到/etc/my.cnf 只需要修改这个配置文件就可以了,使用mysqladmin variables ex
-
sql 百万级数据库优化方案分享
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:select id from t where num=0 3.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使
-
MySQL中实现高性能高并发计数器方案(例如文章点击数)
现在有很多的项目,对计数器的实现甚是随意,比如在实现网站文章点击数的时候,是这么设计数据表的,如:"article_id, article_name, article_content, article_author, article_view--在article_view中记录该文章的浏览量.诈一看似乎没有问题.对于小站,比如本博客,就是这么做的,因为小菜的博客难道会涉及并发问题吗?答案显而易见,一天没多少IP,而且以后不会很大. 言归正传,对文章资讯类为主的项目,在浏览一个页面的时候不但要进行
-
数据库性能优化三:程序操作优化提升性能
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第三部分 概述:程序访问优化也可以认为是访问SQL语句的优化,一个好的SQL语句是可以减少非常多的程序性能的,下面列出常用错误习惯,并且提出相应的解决方案 一.操作符优化 1. IN.NOT IN 操作符 IN和EXISTS 性能有外表和内表区分的,但是在大数据量的表中推荐用EXISTS 代替IN . Not IN 不走索引的是绝对不能用的,可以用NOT EXISTS 代替 2. IS NULL 或IS NOT NUL
-
大数据量,海量数据处理方法总结
下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法也基本可以处理绝大多数遇到的问题.下面的一些问题基本直接来源于公司的面试笔试题目,方法不一定最优,如果你有更好的处理方法,欢迎与我讨论. 1.Bloom filter 适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集 基本原理及要点: 对于原理来说很简单,位数组+k个独立hash函数.将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明
-
针对Sqlserver大数据量插入速度慢或丢失数据的解决方法
我的设备上每秒将2000条数据插入数据库,2个设备总共4000条,当在程序里面直接用insert语句插入时,两个设备同时插入大概总共能插入约2800条左右,数据丢失约1200条左右,测试了很多方法,整理出了两种效果比较明显的解决办法: 方法一:使用Sql Server函数: 1.将数据组合成字串,使用函数将数据插入内存表,后将内存表数据复制到要插入的表. 2.组合成的字符换格式:'111|222|333|456,7894,7458|0|1|2014-01-01 12:15:16;1111|222
-
sql 存储过程分页代码 支持亿万庞大数据量
复制代码 代码如下: CREATE PROCEDURE page @tblName varchar(255), -- 表名 @strGetFields varchar(1000) = '*', -- 需要返回的列 @fldName varchar(255)='id', -- 排序的字段名 @PageSize int = 10, -- 页尺寸 @PageIndex int = 1, -- 页码 @doCount bit = 0, -- 返回记录总数, 非 0 值则返回 @OrderType bit
-
MySQL数据库优化详解
mysql表复制 复制表结构+复制表数据 mysql> create table t3 like t1; mysql> insert into t3 select * from t1; mysql索引 ALTER TABLE用来创建普通索引.UNIQUE索引或PRIMARY KEY索引 ALTER TABLE table_name ADD INDEX index_name (column_list) ALTER TABLE table_name ADD UNIQUE (column_list)
-

详解MySQL性能优化(一)
一.MySQL的主要适用场景 1.Web网站系统 2.日志记录系统 3.数据仓库系统 4.嵌入式系统 二.MySQL架构图: 三.MySQL存储引擎概述 1)MyISAM存储引擎 MyISAM存储引擎的表在数据库中,每一个表都被存放为三个以表名命名的物理文件.首先肯定会有任何存储引擎都不可缺少的存放表结构定义信息的.frm文件,另外还有.MYD和.MYI文件,分别存放了表的数据(.MYD)和索引数据(.MYI).每个表都有且仅有这样三个文件做为MyISAM存储类型的表的存储,也就是说不管这个表有
-
优化mysql数据库的经验总结
1.选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快.因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小.例如,在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间,甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很好的完成任务了.同样的,如果可以的话,我们应该使用MEDIUMINT而不是BIGIN来定义整型字段.另外一个提高效率的方法是在
-
sqlserver数据库优化解析(图文剖析)
下面通过图文并茂的方式展示如下: 一.SQL Profiler 事件类 Stored Procedures\RPC:Completed TSQL\SQL:BatchCompleted 事件关键字段 EventSequence.EventClass.SPID.DatabaseName.Error.StartTime.TextData. HostName.ClientProcessID.ApplicationName. CPU.Reads.Writes.Duration.RowCounts
-
优化Mysql数据库的8个方法
1.创建索引对于查询占主要的应用来说,索引显得尤为重要.很多时候性能问题很简单的就是因为我们忘了添加索引而造成的,或者说没有添加更为有效的索引导致.如果不加索引的话,那么查找任何哪怕只是一条特定的数据都会进行一次全表扫描,如果一张表的数据量很大而符合条件的结果又很少,那么不加索引会引起致命的性能下降.但是也不是什么情况都非得建索引不可,比如性别可能就只有两个值,建索引不仅没什么优势,还会影响到更新速度,这被称为过度索引.2.复合索引比如有一条语句是这样的:select * from users
-
数据库性能优化二:数据库表优化提升性能
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第二部分 优化①:设计规范化表,消除数据冗余 数据库范式是确保数据库结构合理,满足各种查询需要.避免数据库操作异常的数据库设计方式.满足范式要求的表,称为规范化表,范式产生于20世纪70年代初,一般表设计满足前三范式就可以,在这里简单介绍一下前三范式 先给大家看一下百度百科给出的定义: 第一范式(1NF)无重复的列 所谓第一范式(1NF)是指在关系模型中,对域添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每
-
大数据量高并发的数据库优化详解
如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. 一.数据库结构的设计 在一个系统分析.设计阶段,因为数据量较小,负荷较低.我们往往只注意到功能的实现,而很难注意到性能的薄弱之处,等到系统投入实际运行一段时间后,才发现系统的性能在降低,这时再来考虑提高系统性能则要花费更多的人力物力,而整个系统也不可避免的形成了一个打补丁工程. 所以在考虑整个系统的流程的时候,我们必须
-
大数据量分页存储过程效率测试附测试代码与结果
测试环境 硬件:CPU 酷睿双核T5750 内存:2G 软件:Windows server 2003 + sql server 2005 OK,我们首先创建一数据库:data_Test,并在此数据库中创建一表:tb_TestTable 复制代码 代码如下: create database data_Test --创建数据库 data_Test GO use data_Test GO create table tb_TestTable --创建表 (id int identity(1,1) pr
-
mysql数据库优化总结(心得)
1. 优化你的MySQL查询缓存在MySQL服务器上进行查询,可以启用高速查询缓存.让数据库引擎在后台悄悄的处理是提高性能的最有效方法之一.当同一个查询被执行多次时,如果结果是从缓存中提取,那是相当快的.但主要的问题是,它是那么容易被隐藏起来以至于我们大多数程序员会忽略它.在有些处理任务中,我们实际上是可以阻止查询缓存工作的. 复制代码 代码如下: // query cache does NOT work$r = mysql_query("SELECT username FROM user W
-
19个MySQL性能优化要点解析
以下就是跟大家分享的19个MySQL性能优化主要要点,一起学习学习. 1.为查询优化你的查询 大多数的MySQL服务器都开启了查询缓存.这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的.当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了. 这里最主要的问题是,对于程序员来说,这个事情是很容易被忽略的.因为,我们某些查询语句会让MySQL不使用缓存.请看下面的示例: // 查询缓存不开启 $r = mysq
-
详解MySQL性能优化(二)
接着上一篇学习:http://www.jb51.net/article/70528.htm 七.MySQL数据库Schema设计的性能优化 高效的模型设计 适度冗余-让Query尽两减少Join 大字段垂直分拆-summary表优化 大表水平分拆-基于类型的分拆优化 统计表-准实时优化 合适的数据类型 时间存储格式总类并不是太多,我们常用的主要就是DATETIME,DATE和TIMESTAMP这三种了.从存储空间来看TIMESTAMP最少,四个字节,而其他两种数据类型都是八个字节,多了一倍.而T
-
MySQL数据库十大优化技巧
1.优化你的MySQL查询缓存 在MySQL服务器上进行查询,可以启用高速查询缓存.让数据库引擎在后台悄悄的处理是提高性能的最有效方法之一.当同一个查询被执行多次时,如果结果是从缓存中提取,那是相当快的. 但主要的问题是,它是那么容易被隐藏起来以至于我们大多数程序员会忽略它.在有些处理任务中,我们实际上是可以阻止查询缓存工作的. 复制代码 代码如下: // query cache does NOT work $r = mysql_query("SELECT username FROM user
-
SQL Server数据库的高性能优化经验总结
本文主要向大家介绍的是正确优化SQL Server数据库的经验总结,其中包括在对其进行优化的实际操作中值得大家注意的地方描述,以及对SQL语句进行优化的最基本原则,以下就是文章的主要内容描述. 优化数据库的注意事项: 1.关键字段建立索引. 2.使用存储过程,它使SQL变得更加灵活和高效. 3.备份数据库和清除垃圾数据. 4.SQL语句语法的优化.(可以用Sybase的SQL Expert,可惜我没找到unexpired的序列号) 5.清理删除日志. SQL语句优化的基本原则: 1.使用索引来更
-
数据库性能优化一:数据库自身优化提升性能
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第一部分 优化①:增加次数据文件,设置文件自动增长(粗略数据分区) 1.1:增加次数据文件 从SQLSERVER2005开始,数据库不默认生成NDF数据文件,一般情况下有一个主数据文件(MDF)就够了,但是有些大型的数据库,由于信息很多,而且查询频繁,所以为了提高查询速度,可以把一些表或者一些表中的部分记录分开存储在不同的数据文件里 由于CPU和内存的速度远大于硬盘的读写速度,所以可以把不同的数据文件放在不同的物理硬盘