一次OOM问题排查过程实战记录
上周运维反馈线上程序出现了OOM,程序日志中的输出为
Exception in thread "http-nio-8080-exec-1027" java.lang.OutOfMemoryError: Java heap space Exception in thread "http-nio-8080-exec-1031" java.lang.OutOfMemoryError: Java heap space
看线程名称应该是tomcat的nio工作线程,线程在处理程序的时候因为无法在堆中分配更多内存出现了OOM,幸好JVM启动参数配置了-XX:+HeapDumpOnOutOfMemoryError,使用MAT打开拿到的hprof文件进行分析。
第一步就是打开Histogram看看占用内存最大的是什么对象:

可以看到byte数组占用了接近JVM配置的最大堆的大小也就是8GB,显然这是OOM的原因。
第二步看一下究竟是哪些byte数组,数组是啥内容:

可以看到很明显这和HTTP请求相关,一个数组大概是10M的大小。
第三步通过查看GC根查看谁持有了数组的引用:

这符合之前的猜测,是tomcat的线程在处理过程中分配了10M的buffer在堆上。至此,马上可以想到一定是什么参数设置的不合理导致了这种情况,一般而言tomcat不可能为每一个请求分配如此大的buffer。
第四步就是检查代码里是否有tomcat或服务器相关配置,看到有这么一个配置:
max-http-header-size: 10000000
至此,基本已经确定了八九不离十就是这个不合理的最大http请求头参数导致的问题。
到这里还有3个疑问:
- 即使一个请求分配10M内存,堆有8GB,难道当时有这么多并发吗?800个tomcat线程?
- 参数只是设置了最大请求头10M,为什么tomcat就会一次性分配这么大的buffer呢?
- 为什么会有如此多的tomcat线程?感觉程序没这么多并发。
先来看问题1,这个可以通过MAT在dump中继续寻找答案。
可以打开线程视图,搜索一下tomcat的工作线程,发现线程数量的确很多有401个,但是也只是800的一半:

再回到那些大数组的清单,按照堆分配大小排序,往下看:

可以发现除了有10008192字节的数组还有10000000字节的数组,查看引用路径可以看到这个正好是10M的数组是output buffer,区别于之前看到的input buffer:

好吧,这就对了,一个线程分配了输入输出两个buffer,占用20M内存,一共401个线程,占用8GB,所以OOM了。
还引申出一个问题为啥有这么多工作线程,
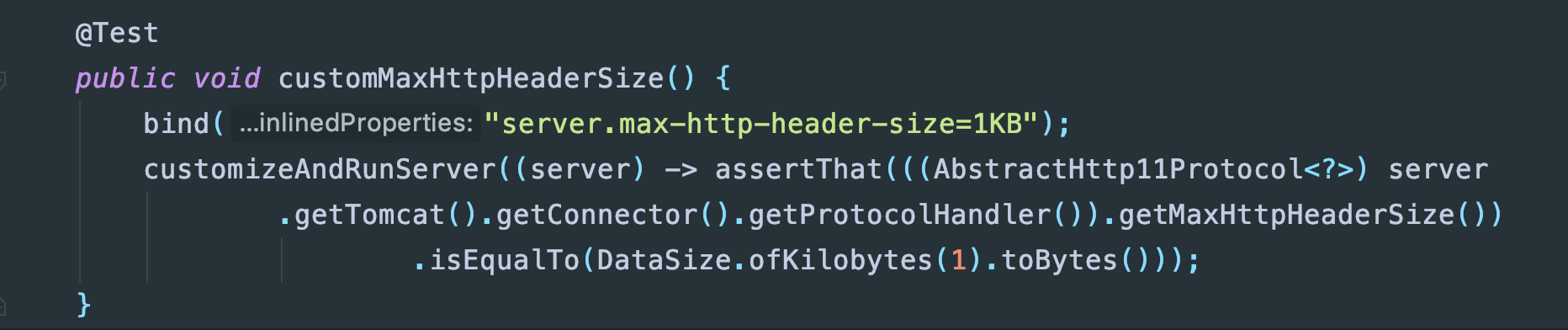
再来看看问题2,这就需要来找一下源码了,首先max-http-header-size是springboot定义的参数,查看springboot代码可以看到这个参数对于tomcat设置的是MaxHttpHeaderSize:
然后来看看tomcat源码:

进一步看一下input buffer:

buffer大小是MaxHttpHeaderSize+ReadBuffer大小,这个默认是8192字节:
<attribute name="socket.appReadBufSize" required="false"> <p>(int)Each connection that is opened up in Tomcat get associated with a read ByteBuffer. This attribute controls the size of this buffer. By default this read buffer is sized at <code>8192</code> bytes. For lower concurrency, you can increase this to buffer more data. For an extreme amount of keep alive connections, decrease this number or increase your heap size.</p> </attribute>
这也就是为什么之前看到大量的buffer是10008192字节的。至于为什么分配的buffer需要是MaxHttpHeaderSize+ReadBuffer。显然还有一批内容是空的10000000字节的buffer应该是output buffer,源码可以印证这点:

嗯这是一个header buffer,所以正好是10000000字节。
至于问题3,显然我们的应用程序是配置过最大线程的(查看配置后发现的确,我们配置为了2000,好吧有点大),否则也不会有401个工作线程(默认150),如果当时并发并不大的话就一种可能,请求很慢,虽然并发不大,但是因为请求执行的慢就需要更多线程,比如TPS是100,但是平均RT是4s的话,就是400线程了。这个问题的答案还是可以通过MAT去找,随便看几个线程可以发现很多线程都在等待一个外部服务的返回,这说明外部服务比较慢,去搜索当时的程序日志可以发现有很多"feign.RetryableException: Read timed out executing的日志"。。。。追杀下游去!慢点,我们的feign的timeout也需要再去设置一下,别被外部服务拖死了。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对我们的支持。
相关推荐
-
五步掌握OOM框架AutoMapper基本使用
写在前面 OOM顾名思义,Object-Object-Mapping实体间相互转换,AutoMapper也是个老生常谈了,其意义在于帮助你无需手动的转换简单而又麻烦的实体间关系,比如ViewModel和entity的转换,SearchModel和Entity的转换,我这篇分享的意义在于,网上大多数的分享都是几年前的,很多方法已经被废弃,到了编译器里会告诉你该方法已经过时,废弃的,不建议使用的,比如Mapper.CreateMap等方法,当然老司机大多数直接就去github看文档了,或者googl
-
Java内存各部分OOM出现原因及解决方法(必看)
一,jvm内存区域 1,程序计数器 一块很小的内存空间,作用是当前线程所执行的字节码的行号指示器. 2,java栈 与程序计数器一样,java栈(虚拟机栈)也是线程私有的,其生命周期与线程相同.通常存放基本数据类型,对象引用(一个指向对象起始地址的引用指针或一个代表对象的句柄),reeturnAddress类型(指向一条字节码指令的地址) 栈区域有两种异常类型:如果线程请求的栈深度大于虚拟机所允许的深度,将抛StrackOverflowError异常:如果虚拟机栈可以动态扩展(大部分虚拟机都可动
-
Android利用软引用和弱引用避免OOM的方法
想必很多朋友对OOM(OutOfMemory)这个错误不会陌生,而当遇到这种错误如何有效地解决这个问题呢?今天我们就来说一下如何利用软引用和弱引用来有效地解决程序中出现的OOM问题. 一.了解 强引用.软引用.弱引用.虚引用的概念 在Java中,虽然不需要程序员手动去管理对象的生命周期,但是如果希望某些对象具备一定的生命周期的话(比如内存不足时JVM就会自动回收某些对象从而避免OutOfMemory的错误)就需要用到软引用和弱引用了. 从Java SE2开始,就提供了四种类型的引用:强引用.软引
-

解决Android解析图片的OOM问题的方法!!!
大家好,今天给大家分享的是解决解析图片的出现oom的问题,我们可以用BitmapFactory这里的各种Decode方法,如果图片很小的话,不会出现oom,但是当图片很大的时候 就要用BitmapFactory.Options这个东东了,Options里主要有两个参数比较重要. options.inJustDecodeBounds = false/true; //图片压缩比例. options.inSampleSize = ssize; 我们去解析一个图片,如果太大,就会OOM,我们可以设置压缩
-
一次OOM问题排查过程实战记录
上周运维反馈线上程序出现了OOM,程序日志中的输出为 Exception in thread "http-nio-8080-exec-1027" java.lang.OutOfMemoryError: Java heap space Exception in thread "http-nio-8080-exec-1031" java.lang.OutOfMemoryError: Java heap space 看线程名称应该是tomcat的nio工作线程,线程在处理
-
一次Jvm old过高的排查过程实战记录
前言 最近遇到一个Jvm old过高的案例,现象是一个站点的jvm old区过高,分析原因是,原来的设计方案有问题,给前端返回的数据里面包含了大量的html代码,从存储中拿数据的过程.拼接数据的过程过于漫长了,造成了大量对象的生命周期过长,对象被 标记到了old中,造成了old区过高,监控系统进行了报警,详细原因就不做详细分析了,主要分享一下问题排查的过程. 收到了监控系统的报警,在服务器上查询jvm内存情况 jstat -gcutil pid 时间间隔,可以按时间间隔打印jvm的内存情况,例如
-
一次关于Redis内存诡异增长的排查过程实战记录
一.现象 实例名:r-bp1cxxxxxxxxxd04(主从) 问题:一分钟内存上涨了2G,如下图所示: 键值规模:6000万左右 内存一分钟增长2G.png 二.Redis内存分析 1. 内存组成 上图中的内存统计的是Redis的info memory命令中的used_memory属性,例如: redis>infomemory#Memoryused_memory:9195978072used_memory_human:8.56Gused_memory_rss:9358786560used_me
-
一次线上websocket返回400问题排查的实战记录
目录 现象 抓包排查 问题定位 解决方案1 解决方案2 原因探讨 总结 现象 生产环境websocket无法正常连接,服务端返回400 bad request,开发及测试环境均正常. 抓包排查 src:nginx服务器 172.16.177.193 dst:imp应用服务器 172.16.177.218 问题定位 观察到header中的host值带有下划线,在一些中间件(如kafka.hadoop)中,对host中的特殊字符也有限制.由此猜测是header问题. 经排查,此header来自ngi
-
一次NodeJS内存泄漏排查的实战记录
目录 前言 案例一 故障现象 排查过程 案例二 故障现象 排查过程 问题原因 node-v9.x 以下的版本 node-v10.x 以上的版本 修复泄露 总结 前言 性能问题(内存.CPU 飙升导致服务重启.异常)排查一直是 Node.js 服务端开发的难点,去年在经过调研后,在我们项目的 Node.js 服务上都接入了 Easy-Monitor 来帮助排查生产环境遇到的性能问题.前段时间遇到了两例内存泄漏的案例,在这里做一个排查经过的整理. 案例一 故障现象 线上的某个服务发生了重启,经过观察
-
一次Spring项目打包问题排查的实战记录
一个 Spring 项目,打成 jar 包之后运行,在有网络的时候是正常的,但是一旦无网络就会报错,具体是怎么回事呢?这篇文章就来记录下这次问题排查经过. 背景介绍 一个图形化的界面,带本地数据库,要求可以在无网络环境下运行,我帮朋友用的 Java 写的图形化界面,虽然不是很美观,但是胜在熟悉 Java. 项目使用的是 idea 的「Build Artifacts」打包,打包之后运行正常,界面和数据库访问都正常,最开始报过几次错,后来就没出现了,也没找到原因,就先那样了. 后来发给别人了,完全打
-
一次现场mysql重复记录数据的排查处理实战记录
目录 前言 分析 数据总计 重复次数占比 where 和 having 的区别 总结 前言 我当时正好出差在客户现场部署调试软件,有一天客户突然找到我这里,说他们现场生产的数据出现了异常的情况,最直接的表现就是 同一个标签,出现在了多个物料上,需要我配合,看怎么排查问题 分析 客户当时直接一摞重复标签的盒子码在我面前,我慌得一匹,这怕不是捅娄子了 稍加思索,现在需要做的就是,在数据库中查询出重复的标签,即对一个标签进行统计,判断出计数> 1 的即可 emmm,语法错误,我记得还有个Having
-
Oracle数据库丢失表排查思路实战记录
目录 说明: 写在最后: 总结 说明: 由于系统采用ID取模分表法进行Oracle数据存储,某日发现Oracle数据库中缺少对应的几张业务数据表,遂进行相关问题查询,简单记录一下排查思路: 由于我们代码中实现思路是判断如果没有对应的表会自动创建,所以首先需要查询一下缺失数据库表的创建时间 SELECT * FROM dba_objects where OBJECT_NAME LIKE 'LOG_5%' AND owner = 'Geoff'; 通过查询Oracle执行SQL历史记录,数据库表的删
-
Centos7安装JDK1.8详细过程实战记录
目录 前言 一.OpenJDK1.8 详细步骤 1.检查当前机器是否有自带的JDK 2.如果没有 则跳至安装步骤,有的话 进行卸载 3.更新yum源 4.搜索yum中的软件包 5.安装OpenJDK 6.验证是否安装成功 7.其它常见问题: 二.OracleJDK1.8 详细步骤 1.查看java版本: 2.查看java相关: 3.删除openjdk—xxxx: 4.检查java版本: 5.下载jdk安装包: 6.切换到目录下解压 7.配置JDK 8.让环境变量生效: 9.检查是否配置成功 总结
-
NodeJs内存占用过高的排查实战记录
前言 一次线上容器扩容引发的排查,虽然最后查出并不是真正的 OOM 引起的,但还是总结记录一下其中的排查过程,整个过程像是破案,一步步寻找蛛丝马迹,一步步验证出结果. 做这件事的意义和必要性个人觉得有这么几个方面吧: 从程序员角度讲:追求代码极致,不放过问题,务必保证业务的稳定性这几个方面 从资源角度讲:就是为了降低无意义的资源开销 从公司角度讲:降低服务器成本,给公司省钱 环境:腾讯 Taf 平台上运行的 NodeJs 服务. 问题起因 最开始是因为一个定时功能上线后,线上的容器自动进行了扩容