Python3 读、写Excel文件的操作方法
首先,简单介绍一下EXECL中工作簿和工作表的区别:
工作簿的英文是BOOK(WORKBOOK),工作表的英文是SHEET(WORKSHEET)。
•一个工作簿就是一个独立的文件
•一个工作簿里面可以有1个或者多个工作表
•工作簿是工作表的集合
1:使用python实现对Excel文件的读写,首先需要安装专用的模块(可以自己编写)xlrd,xlwt模块
2:读取excel数据(注意事项:sheet编号,行号,列号都是从索引0开始)
import xlrd
# 设置路径
path = 'E:/input.xlsx'
# 打开execl
workbook = xlrd.open_workbook(path)
# 输出Excel文件中所有sheet的名字
print(workbook.sheet_names())
# 根据sheet索引或者名称获取sheet内容
Data_sheet = workbook.sheets()[0] # 通过索引获取
# Data_sheet = workbook.sheet_by_index(0) # 通过索引获取
# Data_sheet = workbook.sheet_by_name(u'名称') # 通过名称获取
print(Data_sheet.name) # 获取sheet名称
rowNum = Data_sheet.nrows # sheet行数
colNum = Data_sheet.ncols # sheet列数
# 获取所有单元格的内容
list = []
for i in range(rowNum):
rowlist = []
for j in range(colNum):
rowlist.append(Data_sheet.cell_value(i, j))
list.append(rowlist)
# 输出所有单元格的内容
for i in range(rowNum):
for j in range(colNum):
print(list[i][j], '\t\t', end="")
print()
# 获取整行和整列的值(列表)
rows = Data_sheet.row_values(0) # 获取第一行内容
cols = Data_sheet.col_values(1) # 获取第二列内容
# print (rows)
# print (cols)
# 获取单元格内容
cell_A1 = Data_sheet.cell(0, 0).value
cell_B1 = Data_sheet.row(0)[1].value # 使用行索引
cell_C1 = Data_sheet.cell(0, 2).value
cell_D2 = Data_sheet.col(3)[1].value # 使用列索引
print(cell_A1, cell_B1, cell_C1, cell_D2)
# 获取单元格内容的数据类型
# ctype:0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
print('cell(0,0)数据类型:', Data_sheet.cell(0, 0).ctype)
print('cell(1,0)数据类型:', Data_sheet.cell(1, 0).ctype)
print('cell(1,1)数据类型:', Data_sheet.cell(1, 1).ctype)
print('cell(1,2)数据类型:', Data_sheet.cell(1, 2).ctype)
# 获取单元格内容为日期的数据
date_value = xlrd.xldate_as_tuple(Data_sheet.cell_value(1,0),workbook.datemode)
print(type(date_value), date_value)
print('%d:%d:%d' % (date_value[0:3]))
3:创建excel并写入数据
import xlwt
def set_style(name, height, bold=False):
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = name
font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style
def write_excel(path):
# 创建工作簿
workbook = xlwt.Workbook(encoding='utf-8')
# 创建sheet
data_sheet = workbook.add_sheet('demo')
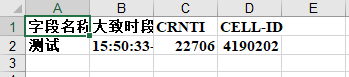
row0 = [u'字段名称', u'大致时段', 'CRNTI', 'CELL-ID']
row1 = [u'测试', '15:50:33-15:52:14', 22706, 4190202]
# 生成第一行和第二行
for i in range(len(row0)):
data_sheet.write(0, i, row0[i], set_style('Times New Roman', 220, True))
data_sheet.write(1, i, row1[i], set_style('Times New Roman', 220, True))
# 保存文件
# workbook.save('demo.xls')
workbook.save(path)
if __name__ == '__main__':
# 设置路径
path = 'E:/demo.xls'
write_excel(path)
print(u'创建demo.xls文件成功')
再看一个例子:
转载:Ryan in C++
基本的write函数接口很简单:
•新建一个excel文件: file = xlwt.Workbook() (注意这里的Workbook首字母是大写)
•新建一个sheet: table = file.add_sheet('sheet_name')
•写入数据table.write(行,列,value): table.write(0,0,'test')
•如果是写入中文,则要用u'汉字'的形式。比如: table.write(0,0, u'汉字')
•合并单元格: table.write_merge(x, x + m, y, y + n, string, style)
•x表示行,y表示列,m表示跨行个数,n表示跨列个数,string表示要写入的单元格内容,style表示单元格样式
"""
设置单元格样式
"""
import xlwt
def set_style(font_name, font_height, bold=False):
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = font_name # 'Times New Roman'
font.bold = bold
font.color_index = 4
font.height = font_height
borders = xlwt.Borders()
borders.left = 6
borders.right = 6
borders.top = 6
borders.bottom = 6
style.font = font
style.borders = borders
return style
# 写excel
def write_excel(output_path):
f = xlwt.Workbook() # 创建工作簿
'''
创建第一个sheet:
sheet1
'''
sheet1 = f.add_sheet(u'sheet1',cell_overwrite_ok=True) # 创建sheet
row0 = [u'业务',u'状态',u'北京',u'上海',u'广州',u'深圳',u'状态小计',u'合计']
column0 = [u'机票',u'船票',u'火车票',u'汽车票',u'其它']
status = [u'预订',u'出票',u'退票',u'业务小计']
# 生成第一行
for i in range(0, len(row0)):
sheet1.write(0, i, row0[i], set_style('Times New Roman', 220, True))
# 生成第一列和最后一列(合并4行)
i, j = 1, 0
while i < 4*len(column0) and j < len(column0):
sheet1.write_merge(i, i+3, 0, 0, column0[j], set_style('Arial', 220, True)) # 第一列
sheet1.write_merge(i, i+3, 7, 7) # 最后一列"合计"
i += 4
j += 1
sheet1.write_merge(21,21,0,1,u'合计',set_style('Times New Roman',220,True))
# 生成第二列
i = 0
while i < 4*len(column0):
for j in range(0,len(status)):
sheet1.write(j+i+1, 1, status[j])
i += 4
f.save(output_path)
if __name__ == '__main__':
write_excel('E:/demo.xls') # 保存文件.这里如果是.xlsx的话会打不开。
注意:如果对一个单元格重复操作,会引发error。所以在打开时加cell_overwrite_ok=True解决
table = file.add_sheet('sheet name',cell_overwrite_ok=True)
生成的demo.xls效果如下:

总结
以上所述是小编给大家介绍的Python3 读、写Excel文件的操作方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
Python3 中文文件读写方法
字符串在Python内部的表示是Unicode编码,因此,在做编码转换时,通常需要以Unicode作为中间编码,即先将其他编码的字符串解码(decode)成Unicode,再从Unicode编码(encode)成另一种编码. 在新版本的python3中,取消了unicode类型,代替它的是使用unicode字符的字符串类型(str),字符串类型(str)成为基础类型如下所示,而编码后的变为了字节类型(bytes) 但是两个函数的使用方法不变: decode encode bytes ------
-
python3 读写文件换行符的方法
最近在处理文本文件时,遇到编码格式和换行符的问题. 基本上都是GBK 和 UTF-8 编码的文本文件,但是python3 中默认的都是按照 utf-8 来打开.用不正确的编码参数打开,在读取内容时,会抛出异常. open(dirpath + "\\" + file, mode = "r+", encoding = "gbk", newline = "") 捕获抛出的异常,关闭文件.使用另外一种编码格式打开文件再重新读取. 读取
-
Python3之文件读写操作的实例讲解
文件操作的步骤: 打开文件 -> 操作文件 -> 关闭文件 切记:最后要关闭文件(否则可能会有意想不到的结果) 打开文件 文件句柄 = open('文件路径', '模式') 指定文件编码 文件句柄= open('文件路径','模式',encoding='utf-8') 为了防止忘记关闭文件,可以使用上下文管理器来打开文件 with open('文件路径','模式') as 文件句柄: 打开文件的模式有: r,只读模式(默认). w,只写模式.[不可读:不存在则创建:存在则删除内容:] a,追加
-
Python3使用pandas模块读写excel操作示例
本文实例讲述了Python3使用pandas模块读写excel操作.分享给大家供大家参考,具体如下: 前言 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具,能使我们快速便捷地处理数据.本文介绍如何用pandas读写excel. 1. 读取excel 读取excel主要通过read_excel函数实现,除了pandas
-
Python3 读、写Excel文件的操作方法
首先,简单介绍一下EXECL中工作簿和工作表的区别: 工作簿的英文是BOOK(WORKBOOK),工作表的英文是SHEET(WORKSHEET). •一个工作簿就是一个独立的文件 •一个工作簿里面可以有1个或者多个工作表 •工作簿是工作表的集合 1:使用python实现对Excel文件的读写,首先需要安装专用的模块(可以自己编写)xlrd,xlwt模块 2:读取excel数据(注意事项:sheet编号,行号,列号都是从索引0开始) import xlrd # 设置路径 path = 'E:/in
-
python3 循环读取excel文件并写入json操作
文件内容: excel内容: 代码: import xlrd import json import operator def read_xlsx(filename): # 打开excel文件 data1 = xlrd.open_workbook(filename) # 读取第一个工作表 table = data1.sheets()[0] # 统计行数 n_rows = table.nrows data = [] # 微信文章属性:wechat_name wechat_id title abstr
-
Java使用jxl包写Excel文件适合列宽实现
注意,这个只是基本可以实现,基本针对中文电子报表. 1.实现思路(1)一般的中文汉字占位长度是英文字母的2倍,"方块字"很统一.(2)对于要写入Excel中的数据统计每一列的最大列宽,最后直接将这一列的列宽设置为这个列的最大值即可. 2.实现代码 复制代码 代码如下: import java.io.File;import java.util.ArrayList;import java.util.List;import java.util.regex.Matcher;import jav
-
Python3操作Excel文件(读写)的简单实例
安装 读Excel文件通过模块xlrd 写Excel文件同过模块xlwt(可惜的是只支持Python2.3到Python2.7版本) xlwt-future模块,支持Python3.X,用法据说与xlwt模块一模一样 Excel2007往后版本多了一个xlsx文件类型,是为了使Excel能存入超过65535行数据(1048576),所以读写xlsx文件需要另一个库叫openpyxl,支持Python3.x pip install xlrd,还能更简单点吗? 使用参考:xlrd官网 安装的版本为0
-
使用Python和xlwt向Excel文件中写入中文的实例
Python等工具确实是不错的工具,但是有时候不管是基础的Python还是Python的软件包都让我觉得对中文不是很亲近.时不时地遇到一点问题很正常,刚刚在写Excel文件的时候就又遇到了这样的问题. 为了能够说明情况,假设我想把当前文件夹中所有的文件名称全都写入到Excel文件中. 当前的目录信息如下: grey@DESKTOP-3T80NPQ:/mnt/e/01_workspace/01_docs/02_blog/2017年/08月$ ls -l total 1464 -rwxrwxrwx
-

Python3读写Excel文件(使用xlrd,xlsxwriter,openpyxl3种方式读写实例与优劣)
Python中几种常用包比较 2.用xlrd包读取Excel文件 引用包 import xlrd 打开文件 xlrd.open_workbook(r'/root/excel/chat.xls') 获取你要打开的sheet文件 # 获取所有sheet sheet_name = workbook.sheet_names()[0] # 根据sheet索引或者名称获取sheet内容 sheet = workbook.sheet_by_index(0) # sheet索引从0开始 获取指定单元格里面的值
-
python中使用xlrd读excel使用xlwt写excel的实例代码
在数据分析和运营的过程中,有非常多的时候需要提供给别人使用,提供的形式有很多种,最经常使用的是Excel, 而 数据的统计和分析采用的是 python, 使用 python 把数据存在Excel 也是常见的事情,也有很多的库帮我们做了很多引擎的事情,比如说xlrd 和xlwt, 分别为读excel和写excel. 安装xlrd和xlwt python中安装第三方模块都较为简单,同样的使用pip 命令就可以: pip install xlrd pip install xlwt 在这里准备上一份Ex
-
python3读取excel文件只提取某些行某些列的值方法
今天有一位同学给了我一个excel文件,要求读取某些行,某些列,然后我试着做了一个demo,这里分享出来,希望能帮到大家: 首先安装xlrd: pip3 install xlrd 然后上代码: import numpy as np import xlrd data = xlrd.open_workbook('LifeTable_16.xlsx') table = data.sheets()[0] # print(table) # nrows = table.nrows #行数 # ncols =
-
Python3.6+selenium2.53.6自动化测试_读取excel文件的方法
环境: 编辑工具: 浏览器: 安装xlrd 安装DDT 一 分析 1 目录结构 2 导入包 二 代码 import xlrd class ExcelUtil(): def __init__(self,excelPath,sheetName="Sheet1"): self.data = xlrd.open_workbook(excelPath) self.table = self.data.sheet_by_name(sheetName) #获取第一行作为key值 self.keys =
-
Python3并发写文件与Python对比
这篇文章主要介绍了Python3并发写文件原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 使用python2在进行并发写的时候,发现文件会乱掉,就是某一行中间会插入其他行的内容. 但是在使用python3进行并发写的时候,无论是多进程,还是多线程,都没有出现这个问题,难道是python3的特性吗? import time import os import multiprocessing from multiprocessing.dumm