解决python Markdown模块乱码的问题
有个需求需要把markdown转成html模块,查询了一下刚好有这个模块
安装 pip install amrkdown
安装完成直接转换并保存为html时,发现出现中文乱码的情况

用编辑器打开发现是缺少utf8编码
所以只需要在头增加一行<meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> 即可
查询Markdown包安装地址
pip install markdown 已经安装过会直接报给你安装地址

因为调用的是markdown.markdown()方法
所以查询一下def markdown方法,在core.py中找到
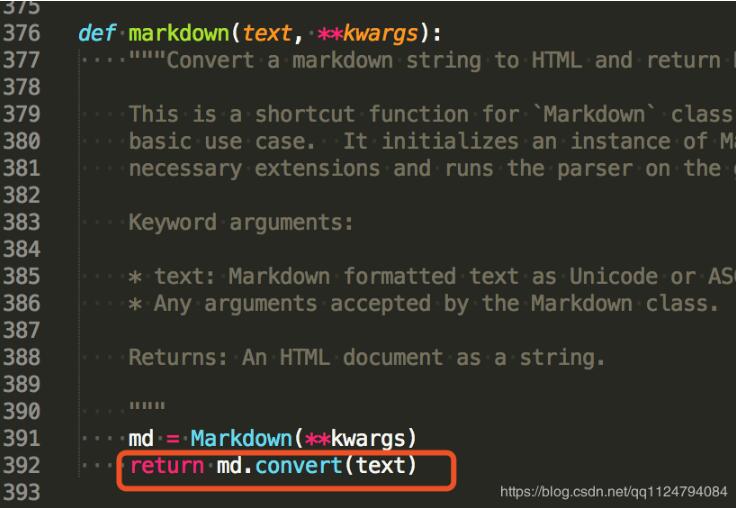
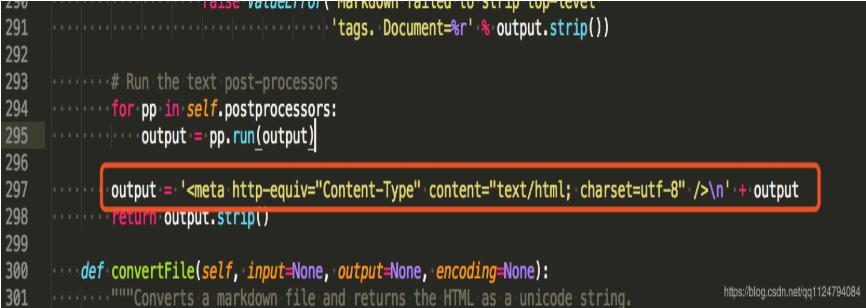
因为调用的是convert方法,再跟踪
找到输出output 增加一行 output = '<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />\n' + output
重新运行生成文件看看:

问题解决!
以上这篇解决python Markdown模块乱码的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

漂亮的Django Markdown富文本app插件的实现
django-mdeditor Github地址:https://github.com/pylixm/django-mdeditor欢迎试用,star收藏! Django-mdeditor 是基于Editor.md的一个 django Markdown 文本编辑插件应用. Django-mdeditor 的灵感参考自伟大的项目django-ckeditor. 功能 支持 Editor.md 大部分功能 支持标准的Markdown 文本. CommonMark 和 GFM (GitHub Flav
-
利用Electron简单撸一个Markdown编辑器的方法
Markdown 是我们每一位开发者的必备技能,在写 Markdown 过程中,总是寻找了各种各样的编辑器,但每种编辑器都只能满足某一方面的需要,却不能都满足于日常写作的各种需求. 所以萌生出自己动手试试,利用 Electron 折腾一个 Markdown 编辑器出来. 下面罗列出我所理想的 Markdown 编辑器的痛点需求: 必须要有图床功能,而且还可以直接上传到自己的图片后台,如七牛: 样式必须是可以自定义的: 导出的 HTML 内容可以直接粘贴到公众号编辑器里,直接发布,而不会出现格式的
-
CommonMark 使用教程:将 Markdown 语法转成 Html
Markdown写作 从 2016年 开始写博客,我的写作方式一直在改变,准确的说一直在进步,因为效率越来越高. 最初在 CSDN 上写东西时非常蹩脚,在他们编辑器上写点然后调整格式,再写,碰到图片还得将图片插入进去,调整图片大小位置等等,调整完继续写. 效率非常低. 后面了解到 Markdown ,改用 MD 写东西,效率快很多.后面在 Markdown 基础上慢慢优化找到自己的写作方式. 一般我用 MD 语法写完后,得到的是一堆带 MD 符号的文字,以下简称 MD文本. 然后会通过工具转成对
-
vue-cli3项目展示本地Markdown文件的方法
[版本] vue-cli3 webpack@4.33.0 [步骤]1.安装插件vue-markdown-loader npm i vue-markdown-loader -D ps:这个插件是基于markdown-it的,不需要单独安装markdown-it. 2.修改vue.config.js配置文件(如果没有,在项目根目录新建一个): module.exports = { chainWebpack: config => { config.module.rule('md') .test(/\.
-
利用Vue实现一个markdown编辑器实例代码
前言 前段时间做项目的时候,需要一个Markdown编辑器,在网上找了一些开源的实现,但是都不满足需求 说实话,这些开源项目也很难满足需求公司项目的需求,与其实现一个大而全的项目,倒不如实现一个简单的,易于在源码上修改的项目,核心功能都有的,以供修改使用 本文的源码地址如下:https://github.com/jiulu313/HelloMarkDown(本地下载) 喜欢的朋友可以帮忙star一下,欢迎交流学习 先看一下本项目的效果图(图片经过压缩) 本文的目的就是实现一个有核心功能的,简单,
-
Django渲染Markdown文章目录的方法示例
对会读书的人来说,读一本书要做的第一件事,就是仔细阅读这本书的目录.阅读目录可以对整体内容有所了解,并清楚地知道感兴趣的部分在哪里,提高阅读质量. 博文也是同样的,好的目录对博主和读者都很有帮助.更进一步的是,还可以在目录中设置锚点,点击标题就立即前往该处,非常的方便. 文中的目录 之前我们已经为博文支持了Markdown语法,现在继续增强其功能. 有折腾代码高亮的痛苦经历之后,设置Markdown的目录扩展就显得特别轻松了. 修改文章详情视图: article/views.py ... # 文
-
vue中利用simplemde实现markdown编辑器(增加图片上传功能)
前言 最近在搭个人博客网站,需要一个 markdown 编辑器,来进行博客的编写 看了网上的教程,决定使用 simplemde 以为可以直接能拿来用的 不过实际运用的时候发现还是有要完善的地方 比如令人头疼的图片上传 最终效果 安装及初始化 npm install simplemde --save 在html中加入一个textarea <textarea id="simplemde"></textarea> 在vue的生命周期函数 mounted 中,添加 si
-
解决python Markdown模块乱码的问题
有个需求需要把markdown转成html模块,查询了一下刚好有这个模块 安装 pip install amrkdown 安装完成直接转换并保存为html时,发现出现中文乱码的情况 用编辑器打开发现是缺少utf8编码 所以只需要在头增加一行<meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> 即可 查询Markdown包安装地址 pip install markdown
-
解决Python logging模块无法正常输出日志的问题
废话少说,先上代码 File:logger.conf [formatters] keys=default [formatter_default] format=%(asctime)s - %(name)s - %(levelname)s - %(message)s class=logging.Formatter [handlers] keys=console, error_file [handler_console] class=logging.StreamHandler formatter=d
-
解决Python paramiko 模块远程执行ssh 命令 nohup 不生效的问题
Python - paramiko 模块远程执行ssh 命令 nohup 不生效的问题解决 1.使用 paramiko 模块ssh 登陆到 linux 执行nohup命令不生效 # 执行命令 def command(ssh_config, cmd, result_print=None, nohup=False): ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.con
-
解决python通过cx_Oracle模块连接Oracle乱码的问题
用python连接Oracle是总是乱码,最有可能的是oracle客户端的字符编码设置不对. 本人是在进行数据插入的时候总是报关键字"From"不存在,打印插入的Sql在pl/sql中进行插入,没有问题.所以,后来从字符集编码上去考虑和解决问题. 编写的python脚本中需要加入: import os os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8' 这样可以保证select出来的中文显示没有问题. 要能够正常的inser
-
解决Python命令行下退格,删除,方向键乱码(亲测有效)
一.出现原因:readline模块没有安装 二.解决方式: # 安装readline模块 yum -y install readline-devel # 进入Python安装目录 cd /usr/local/Python-2.7.12 # 重新执行Python的安装 configure make make install 以上这篇解决Python命令行下退格.删除.方向键乱码(亲测有效)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python 采集中文乱码问题的完美解决方法
近几日遇到采集某网页的时候大部分网页OK,少部分网页出现乱码的问题,调试了几日,终于发现了是含有一些非法字符造成的..特此记录 1. 在正常情况下..可以用 import chardet thischarset = chardet.detect(strs)["encoding"] 来获取该文件或页面的编码方式 或直接抓取页面的charset = xxxx 来获取 2. 遇到内容中有特殊字符时指定的编码一样会造成乱码..即内容中非法字符造成的,可以采用编码忽略非法字符的方式来处理. st
-
解决python使用open打开文件中文乱码的问题
代码如下: 先在D盘下新建一个html文档,然后在里面输入含有中文的Html字符如下图,然后我们首先使用中文格式对读取的字符进行解码再用utf-8的模式对字符进行进行编码,然后就能正确输出中文字符 # -*- coding: UTF-8 -*- file1 = open("D:/1.html", mode='rb+') data = file1.read().decode('gbk').encode('utf-8') print data 以上这篇解决python使用open打开文件中
-
Python安装模块的常见问题及解决方法
1.error: command 'x86_64-linux-gnu-gcc' failed with exit status 解决办法: # Python 3 $ sudo apt-get install python3 python-dev python3-dev \ build-essential libssl-dev libffi-dev \ libxml2-dev libxslt1-dev zlib1g-dev \ python-pip # Python 2 $ sudo apt-ge
-
解决Python网页爬虫之中文乱码问题
Python是个好工具,但是也有其固有的一些缺点.最近在学习网页爬虫时就遇到了这样一种问题,中文网站爬取下来的内容往往中文显示乱码.看过我之前博客的同学可能知道,之前爬取的一个学校网页就出现了这个问题,但是当时并没有解决,这着实成了我一个心病.这不,刚刚一解决就将这个方法公布与众,大家一同分享. 首先,我说一下Python中文乱码的原因,Python中文乱码是由于Python在解析网页时默认用Unicode去解析,而大多数网站是utf-8格式的,并且解析出来之后,python竟然再以Unicod
-
解决python中使用PYQT时中文乱码问题
如题,解决Python中用PyQt时中文乱码问题的解决方法: 在中文字符串前面加上u,如u'你好,世界',其他网上的方法没有多去探究,Python的版本也会影响解决方法,故这里只推荐这种. (有人说用toLocal8bit函数也可以,我试了下,貌似不行)请看例子: #coding=utf-8 from PyQt4 import QtGui, QtCore s = QtCore.QString(u'你好(hello)世界(world)') t = s.toLocal8Bit() u = unico