使用正则表达式找出不包含特定字符串的条目
做日志分析工作的经常需要跟成千上万的日志条目打交道,为了在庞大的数据量中找到特定模式的数据,常常需要编写很多复杂的正则表达式。例如枚举出日志文件中不包含某个特定字符串的条目,找出不以某个特定字符串打头的条目,等等。
使用否定式前瞻
正则表达式中有前瞻(Lookahead)和后顾(Lookbehind)的概念,这两个术语非常形象的描述了正则引擎的匹配行为。需要注意一点,正则表达式中的前和后和我们一般理解的前后有点不同。一段文本,我们一般习惯把文本开头的方向称作“前面”,文本末尾方向称为“后面”。但是对于正则表达式引擎来说,因为它是从文本头部向尾部开始解析的(可以通过正则选项控制解析方向),因此对于文本尾部方向,称为“前”,因为这个时候,正则引擎还没走到那块,而对文本头部方向,则称为“后”,因为正则引擎已经走过了那一块地方。如下图所示:
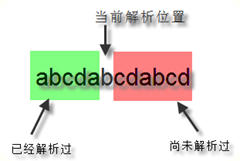
所谓的前瞻就是在正则表达式匹配到某个字符的时候,往“尚未解析过的文本”预先看一下,看是不是符合/不符合匹配模式,而后顾,就是在正则引擎已经匹配过的文本看看是不是符合/不符合匹配模式。符合和不符合特定匹配模式我们又称为肯定式匹配和否定式匹配。
现代高级正则表达式引擎一般都支持都支持前瞻,对于后顾支持并不是很广泛,因此我们这里采用否定式前瞻来实现我们的需求。
实现
测试数据:
2009-07-07 04:38:44 127.0.0.1 GET /robots.txt
2009-07-07 04:38:44 127.0.0.1 GET /posts/robotfile.txt
2009-07-08 04:38:44 127.0.0.1 GET /
例如上面这几条简单的日志条目,我们想实现两个目标:
1. 把8号的数据过滤掉
2. 把那些不包含robots.txt字符串的条目给找出来(只要Url中包含robots.txt的都给过滤掉)。
前瞻的语法是:
(?!匹配模式)我们先来实现第一个目标——匹配不以特定字符串开头的条目。
这里我们因为要排除一段连续的字符串,因此匹配模式非常简单,就是2009-07-08。实现如下:
^(?!2009-07-08).*?$
用Expresso我们可以看到结果确实过滤掉8号的数据。
接下来,我们来实现第二个目标——排除包含特定字符串的条目。
按照我们上面写法,我照葫芦画瓢了一下:
^.*?(?!robots\.txt).*?$
这段正则用大白话描述就是:开头任意字符,然后后面不要跟着robots.txt连续字符串,然后再跟着任意个字符,字符串结尾。
运行测试,结果发现:
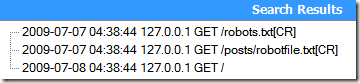
没有达到我们想要的效果。这是为什么呢?我们给上面的正则表达式加上两个捕获分组调试一下:
^(.*?)(?!robots\.txt)(.*?)$
测试结果:
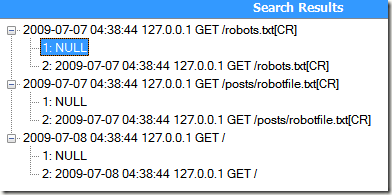
我们看到,第一个分组啥都没有匹配到,而第二个分组却匹配了整个字符串。再回过头来好好分析一下刚才那个正则表达式。实际上,当正则引擎解析到A区域的时候,就已经开始执行B区域的前瞻工作。这个时候发现当A区域为Null的时候匹配成功——.*本来就允许匹配空字符,前瞻条件又满足,A区域后面紧跟着的是“2009”字符串,而并不是robots。因此整个匹配过程成功匹配到所有条目。
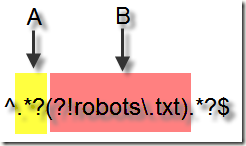
分析出原因之后我们对上述的正则进行修正,将.*?移入前瞻表达式,如下:
^(?!.*?robots).*$
测试结果:

完成
php中用正则实现不包括某个字符串的实现方法
preg_match("/^((?!abc).)*$/is", $str);
完整代码示例
$str = "dfadfadf765577abc55fd";
$pattern_url = "/^((?!abc).)*$/is";
if (preg_match($pattern_url, $str))
{
echo "不含有abc!";
}
else
{
echo "含有abc!";
}
结果为:false,含有abc!
同时匹配,包含字符串 "abc",而且不包含字符串 "xyz"的正则表达式:
preg_match("/(abc)[^((?!xyz).)*$]/is", $str);
该方法有效,本人使用方法如下:
(?:(?!<\/div>).|\n)*? //匹配不含</div>的一个字符串
但最终使用中结果是发现,该方法效率极其低下,在处理非常短文字(要匹配该正则式的相同部分的有十几个字,或者最多几十个)时间可以考虑使用,但当用于大篇幅文章解析或多处需要改种匹配时间应不使用,考虑用其他方法替代(如:先解析出要匹配该段正则式的文字,然后验证其中是否存在某段文字),正则表达式对于匹配不含特定字符串的文字段时并不是非常有效的方法.
相关推荐
-
正则表达式截取字符串的方法技巧
有这么一段字符串: [数字]字符串 结果 取 a=数字 b=字符串 截取方法1: int a = Convert.ToInt32(txt1.Text.Trim().Replace('[', ']').Split(']')[1]); string b = txt1.Text.Trim().Replace('[', ']').Split(']')[2]; 截取方法2: string str = "[数字]字符串"; Regex reg = new Regex(@" ([^]+)
-
利用正则表达式将字符串分组示例代码
前言 最近工作中遇到一个问题,需求是碰到'122333<<<<'这种字符串,要将其连贯的部分取出,得出['1', '22', '333', '<<<<']这样的列表,能想到的常规办法,遍历字符串,后一个与前一个逐个比较,这样真的很麻烦!又想到了另外两种方法,话不多说了,来一起看看详细的示例代码: 一.实际上可以借助itertools模块的groupby()方法来处理: import itertools Str = '122333<<<<
-

正则表达式匹配不包含某些字符串的技巧
经常我们会遇到想找出不包含某个字符串的文本,程序员最容易想到的是在正则表达式里使用,^(hede)来过滤"hede"字串,但这种写法是错误的.我们可以这样写:[^hede],但这样的正则表达式完全是另外一个意思,它的意思是字符串里不能包含'h','e','d'三个但字符.那什么样的正则表达式能过滤出不包含完整"hello"字串的信息呢? 事实上,说正则表达式里不支持逆向匹配并不是百分之百的正确.就像这个问题,我们就可以使用否定式查找来模拟出逆向匹配,从而解决我们的问
-
JS正则表达式提取字符串中所有汉字的脚本
在网上发现有人用vbscript正则表达式实现了这个功能,但代码很厂,偶改成js的了,很短的一段代码: var str="怎样从一个Html页面中提取所有汉字呢?不能有其它Html代码."; alert(str.replace(/[^\u4e00-\u9fa5]/gi,"")); [Ctrl+A 全选 注:如需引入外部Js需刷新才能执行] 这里的关键是汉字escape后的编码范围是\u4e00-\u9fa5,知道这个问题就好解决了.
-
使用正则表达式找出不包含特定字符串的条目
做日志分析工作的经常需要跟成千上万的日志条目打交道,为了在庞大的数据量中找到特定模式的数据,常常需要编写很多复杂的正则表达式.例如枚举出日志文件中不包含某个特定字符串的条目,找出不以某个特定字符串打头的条目,等等. 使用否定式前瞻 正则表达式中有前瞻(Lookahead)和后顾(Lookbehind)的概念,这两个术语非常形象的描述了正则引擎的匹配行为.需要注意一点,正则表达式中的前和后和我们一般理解的前后有点不同.一段文本,我们一般习惯把文本开头的方向称作"前面",文本末尾方向称为&
-
Pandas过滤dataframe中包含特定字符串的数据方法
假如有一列全是字符串的dataframe,希望提取包含特定字符的所有数据,该如何提取呢? 因为之前尝试使用filter,发现行不通,最终找到这个行得通的方法. 举例说明: 我希望提取所有包含'Mr.'的人名 1.首先将他们进行字符串化,并得到其对应的布尔值: >>> bool = df.str.contains('Mr\.') #不要忘记正则表达式的写法,'.'在里面要用'\.'表示 >>> print('bool : \n', bool) 2.通过dataframe的
-
PHP检查URL包含特定字符串实例方法
方法一:查找.匹配字符串中的子字符串 strpos()函数 strpos()函数用于查找字符串中第一次出现的子字符串.如果子字符串存在,则该函数返回子字符串的起始索引,否则如果在字符串(URL)中找不到子字符串,则返回False. 注:strpos() 函数对大小写敏感,区分大小写. 示例:使用strpos()函数在URL中查找特定字符串. <?php header("content-type:text/html;charset=utf-8"); // 在URL中查找特定的子字符
-
JS使用正则表达式找出最长连续子串长度
废话不多说了,直接给大家贴代码了,具体代码如下所示: function maxLenStr(str){ var len = 0, max_len = 0; var reg = new RegExp("(.)\\1{1,}","g"); var res = reg.exec(str); while(res != null){ len = res[0].length; if(max_len < len){ max_len = len; } res = reg.ex
-
华为面试题答案找出最大长度子字符串
复制代码 代码如下: int findMaxSubstring(char* str){ int maxLength = 0; int maxStartIndex = 0; int curLength = 0; int curStartIndex = 0; bool isFind = 0; for(unsigned int i = 0;i<strlen(str);i++) { if(str[i] >= 'a' && str[
-
php 正则 不包含某字符串的正则表达式
常见函数 strstr($str, "abc"); 正则匹配 preg_match("/(abc)?/is", $str); 但是要匹配一个字符串中,不包含某字符串,用正则就比较麻烦了 如果不用正则 !strstr($str, "abc"); 就可以解决问题了 但是用正则呢,就只有这样了,"/^((?!abc).)*$/is" //------------------------------------------------
-
用正则删除不包含某个字符串的行的代码
先说一下这个可疑的ip,58.63.144.170,据说是一个弱智的蜘蛛,上帝保佑它下地狱. 看过apache日志的朋友应该知道,apache的访问日志的每一行是以访问者的ip开始的.因为日志比较大,所以我是用ultraedit来看的.用ultraedit的时候需要注意,它的正则一共有两种,一种是符合perl规范的,而默认的是ut自带的一种,写法比较特殊.本文中用到的正则表达式都是perl兼容的,ut中这个选项可以在"高级->配置->搜索->正则表达式引擎"中进行修改
-
Replace关键字的妙用查询是否包含某个特定字符串
在sql server中Replace关键字主要是用来将字符串中的某个字符替换成别的字符,今天要逆向思维,它还可以用来查询是否包含某个特定字符串,例如给定下面数据集 期望从这个数据集中获取包含"aaa"字符的记录,注意第2条数据不是包含"aaa",而是包含"aaaa".期望的""结果如下: 传统的思维肯定是想如何查出包含有3个a的字符串,有的人会像用like,但这样会连同4个a也查出来.这里我们就思考用Replace替换掉
-
Java使用正则表达式实现找出数字功能示例
本文实例讲述了Java使用正则表达式实现找出数字功能.分享给大家供大家参考,具体如下: 1.问题: String str = "fjd789klsd908434jk#$$%%^38488545",从中找出78990843438488545,请找到解决办法 2.实现代码: /** * */ package com.you.model; /** * @author YouHaidong * */ public class FindNumber { /** * 字符串str */ publi