解决Python网页爬虫之中文乱码问题
Python是个好工具,但是也有其固有的一些缺点。最近在学习网页爬虫时就遇到了这样一种问题,中文网站爬取下来的内容往往中文显示乱码。看过我之前博客的同学可能知道,之前爬取的一个学校网页就出现了这个问题,但是当时并没有解决,这着实成了我一个心病。这不,刚刚一解决就将这个方法公布与众,大家一同分享。
首先,我说一下Python中文乱码的原因,Python中文乱码是由于Python在解析网页时默认用Unicode去解析,而大多数网站是utf-8格式的,并且解析出来之后,python竟然再以Unicode字符格式输出,会与系统编码格式不同,导致中文输出乱码,知道原因后我们就好解决了。下面上代码,实验对象仍是被人上了无数遍的百度主页~
# -*- coding: utf-8 -*-
import urllib2
import re
import requests
import sys
import urllib
#设置编码
reload(sys)
sys.setdefaultencoding('utf-8')
#获得系统编码格式
type = sys.getfilesystemencoding()
r = urllib.urlopen("http://www.baidu.com")
#将网页以utf-8格式解析然后转换为系统默认格式
a = r.read().decode('utf-8').encode(type)
print a
最后输出效果,中文完美输出
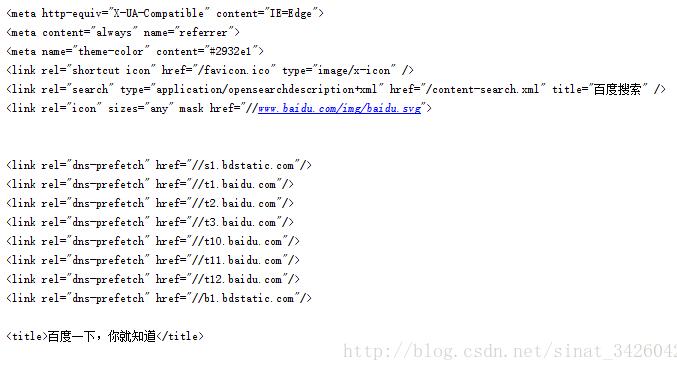
以上这篇解决Python网页爬虫之中文乱码问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python实现爬虫从网络上下载文档的实例代码
最近在学习Python,自然接触到了爬虫,写了一个小型爬虫软件,从初始Url解析网页,使用正则获取待爬取链接,使用beautifulsoup解析获取文本,使用自己写的输出器可以将文本输出保存,具体代码如下: Spider_main.py # coding:utf8 from baike_spider import url_manager, html_downloader, html_parser, html_outputer class SpiderMain(object): def __ini
-
python爬虫 使用真实浏览器打开网页的两种方法总结
1.使用系统自带库 os 这种方法的优点是,任何浏览器都能够使用, 缺点不能自如的打开一个又一个的网页 import os os.system('"C:/Program Files/Internet Explorer/iexplore.exe" http://www.baidu.com') 2.使用python 集成的库 webbroswer python的webbrowser模块支持对浏览器进行一些操作,主要有以下三个方法: import webbrowser webbrowser.
-
python爬虫_实现校园网自动重连脚本的教程
一.背景 最近学校校园网不知道是什么情况,总出现掉线的情况.每次掉线都需要我手动打开web浏览器重新进行账号密码输入,重新进行登录.系统的问题我没办法解决,但是可以写一个简单的python脚本用于自动登录校园网.每次掉线后,再打开任意网页就是这个页面. 二.实现代码 #-*- coding:utf-8 -*- __author__ = 'pf' import time import requests class Login: #初始化 def __init__(self): #检测间隔时间,单位
-

Python爬取成语接龙类网站
介绍 本文将展示如何利用Python爬虫来实现诗歌接龙. 该项目的思路如下: 利用爬虫爬取诗歌,制作诗歌语料库: 将诗歌分句,形成字典:键(key)为该句首字的拼音,值(value)为该拼音对应的诗句,并将字典保存为pickle文件: 读取pickle文件,编写程序,以exe文件形式运行该程序. 该项目实现的诗歌接龙,规则为下一句的首字与上一句的尾字的拼音(包括声调)一致.下面将分步讲述该项目的实现过程. 诗歌语料库 首先,我们利用Python爬虫来爬取诗歌,制作语料库.爬取的网址为:https
-
python2.7实现爬虫网页数据
最近刚学习Python,做了个简单的爬虫,作为一个简单的demo希望帮助和我一样的初学者. 代码使用python2.7做的爬虫 抓取51job上面的职位名,公司名,薪资,发布时间等等. 直接上代码,代码中注释还算比较清楚 ,没有安装mysql需要屏蔽掉相关代码: #!/usr/bin/python # -*- coding: UTF-8 -*- from bs4 import BeautifulSoup import urllib import urllib2 import codecs im
-
Python3.x爬虫下载网页图片的实例讲解
一.选取网址进行爬虫 本次我们选取pixabay图片网站 url=https://pixabay.com/ 二.选择图片右键选择查看元素来寻找图片链接的规则 通过查看多个图片路径我们发现取src路径都含有 https://cdn.pixabay.com/photo/ 公共部分且图片格式都为.jpg 因此正则表达式为 re.compile(r'^https://cdn.pixabay.com/photo/.*?jpg$') 通过以上的分析我们可以开始写程序了 #-*- coding:utf-8 -
-
Python爬虫之网页图片抓取的方法
一.引入 这段时间一直在学习Python的东西,以前就听说Python爬虫多厉害,正好现在学到这里,跟着小甲鱼的Python视频写了一个爬虫程序,能实现简单的网页图片下载. 二.代码 __author__ = "JentZhang" import urllib.request import os import random import re def url_open(url): ''' 打开网页 :param url: :return: ''' req = urllib.reques
-
Python 网络爬虫--关于简单的模拟登录实例讲解
和获取网页上的信息不同,想要进行模拟登录还需要向服务器发送一些信息,如账号.密码等等. 模拟登录一个网站大致分为这么几步: 1.先将登录网站的隐藏信息找到,并将其内容先进行保存(由于我这里登录的网站并没有额外信息,所以这里没有进行信息筛选保存) 2.将信息进行提交 3.获取登录后的信息 先给上源码 <span style="font-size: 14px;"># -*- coding: utf-8 -*- import requests def login(): sessi
-
Python使用爬虫爬取静态网页图片的方法详解
本文实例讲述了Python使用爬虫爬取静态网页图片的方法.分享给大家供大家参考,具体如下: 爬虫理论基础 其实爬虫没有大家想象的那么复杂,有时候也就是几行代码的事儿,千万不要把自己吓倒了.这篇就清晰地讲解一下利用Python爬虫的理论基础. 首先说明爬虫分为三个步骤,也就需要用到三个工具. ① 利用网页下载器将网页的源码等资源下载. ② 利用URL管理器管理下载下来的URL ③ 利用网页解析器解析需要的URL,进而进行匹配. 网页下载器 网页下载器常用的有两个.一个是Python自带的urlli
-
解决Python网页爬虫之中文乱码问题
Python是个好工具,但是也有其固有的一些缺点.最近在学习网页爬虫时就遇到了这样一种问题,中文网站爬取下来的内容往往中文显示乱码.看过我之前博客的同学可能知道,之前爬取的一个学校网页就出现了这个问题,但是当时并没有解决,这着实成了我一个心病.这不,刚刚一解决就将这个方法公布与众,大家一同分享. 首先,我说一下Python中文乱码的原因,Python中文乱码是由于Python在解析网页时默认用Unicode去解析,而大多数网站是utf-8格式的,并且解析出来之后,python竟然再以Unicod
-
解决vscode python print 输出窗口中文乱码的问题
一.搭建 python 环境 在 VSC 中点击 F1 键,弹出控制台,输入 ext install 界面左侧弹出扩展窗格,输入python,确认,开始搜索 下载发布者为Don Jayamanne 的 Python 插件 (下载过程中不要切换窗口,不要做其他任何操作,否则会中断下载,下载时间略长,耐心等待) 安装完毕 "文件"-"首选项"-"用户设置",打开用户配置文件settings.json,再其中大括号内输入计算机中 python.exe
-
完美解决Pycharm中matplotlib画图中文乱码问题
Matplotlib Matplotlib 是Python中类似 MATLAB 的绘图工具,熟悉 MATLAB 也可以很快的上手 Matplotlib. 这篇文章给大家介绍Pycharm matplotlib画图中文乱码的问题及解决方法,本文给大家介绍的非常详细,一起看看吧! 我用的MacOs系统,不过Windows也大同小异 首先去下载SimHei字体: https://github.com/StellarCN/scp_zh/blob/master/fonts/SimHei.ttf 然后直接双
-
解决URL地址中的中文乱码问题的办法
解决URL地址中的中文乱码问题的办法 引言: 在Restful类的服务设计中,经常会碰到需要在URL地址中使用中文作为的参数的情况,这种情况下,一般都需要正确的设置和编码中文字符信息.乱码问题就此产生了,该如何解决呢?且听本文详细道来. 1. 问题的引出 在Restful的服务设计中,查询某些信息的时候,一般的URL地址设计为: get /basic/service? keyword=历史 , 之类的URL地址. 但是,在实际的开发和使用中,确是有乱码情况的发生,在后台的读取keyword信息
-
完美解决Get和Post请求中文乱码的问题
对于Post请求,只需在Servlet或者jsp中写入如下代码就可以把解决从表单中传入的中文乱码问题 request.setCharacterEncoding("utf-8"); 而对于Get请求,因为请求参数会被附加到地址栏的URL之后,所以不能用上面的处理方法.应该这样: String str=request.getQueryString(); //使用URLDecoder解码字符串 String str1=java.net.URLDecoder.decode(str,"
-
解决IntelliJ IDEA 控制台输出中文乱码问题(史上最简单)
首先,找到 IntelliJ IDEA 的安装目录,进入bin目录下,定位到idea.vmoptions文件,如下图所示: 双击打开idea.vmoptions文件,如下图所示: 然后,在其中追加-Dfile.encoding=UTF-8代码,如下图所示: 最后,在 IntelliJ IDEA 中的"Run/Debug Configurations"中,修改虚拟机参数" VM options ",内容与在文件idea.vmoptions中追加的内容相同,皆为-Dfi
-
解决Python下json.loads()中文字符出错的问题
Python:2.7 IDE:Pycharm5.0.3 今天遇到一个问题,就是在使用json.load()时,中文字符被转化为Unicode码的问题,解决方案找了半天,无解.全部代码贴出,很简单的一个入门程序,抓的是有道翻译的,跟着小甲鱼的视频做的,但是他的版本是python3.4,所以有些地方还需要自己改,不多说,程序如下: import urllib#python2.7才需要两个urllib url="http://fanyi.youdao.com/translate?smartresult
-
解决python cv2.imread 读取中文路径的图片返回为None的问题
使用cv2读取图片时,输出图片形状大小时出现报错" 'NoneType' object has no attribute shape",后来排查发现读取图片的返回值image为None, 这就说明图片根本就没有被读取. 下面图片是问题问题解决后,为了更好的展示,写的代码展示,这是正常的因果关系,找错误排查时是从下往上推. 使用PIL读取图像,能够成功读取图片,借此了解图片的大小和格式,代码如下图所示: cv.imread函数能够成功读取非中文路径的图片,所以就想到是不是中文路径的问题,
-
解决tomcat 静态页面(html)中文乱码的解决终极篇
tomcat 中jsp不会乱码 但是html中文会乱码 原因有好几个: 没有设置页面编码 tomcat的配置不正确 文件保存的编码格式不是utf-8 等等 下面来讨论解决办法 html页面设置为 utf-8 在页面头部添加<meta>标签 tomcat的server.xml配置 (1) 添加 URIEncoding="UTF-8" <Connector port="8080" protocol="HTTP/1.1" connec
-
node.js解决客户端请求数据里面中文乱码的事件方法
node.js解决客户端请求数据里面中文乱码的事件 例如代码: var http = require('http'); var server = http.createServer(); server.on('request',function(req,res){ // res.end("hello world"); res.end("你好 世界"); }); server.listen(3000,function(){ console.log("Serv