python模块导入的细节详解
python模块导入细节
本文主要介绍了关于python模块导入的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧
官方手册:https://docs.python.org/3/tutorial/modules.html
可执行文件和模块
python源代码文件按照功能可以分为两种类型:
- 用于执行的可执行程序文件
- 不用与执行,仅用于被其它python源码文件导入的模块文件
例如文件a.py和b.py在同一目录下,它们的内容分别是:
# b.py x="var x in module b" y=5 # a.py: import b import sys print(b.x) print(b.y)
a.py导入其它文件(b.py)后,就可以使用b.py文件中的属性(如变量、函数等)。这里,a.py就是可执行文件,b.py就是模块文件,但模块名为b,而非b.py。
python提供了一些标准库,是预定义好的模块文件,例如上面的sys模块。
在此有几个注意点,在后面会详细解释:
- 模块b的文件名为b.py,但import导入的时候,使用的名称为b,而非b.py
- a.py和b.py是在同一个目录下的,如果不在同目录下能否导入?
- 在a.py中访问b.py模块中的属性时,使用的是
b.x、b.y - 上面都是直接以模块名导入的,python还支持更复杂的包导入方式,例如导入abc/b.py时,使用
import abc.b。下一篇文章会详细解释包的导入方式
python模块搜索路径
在a.py中导入模块b的时候,python会做一系列的模块文件路径搜索操作:b.py在哪里?只有找到它才能读取、运行(装载)该模块。
在任何一个python程序启动时,都会将模块的搜索路径收集到sys模块的path属性中(sys.path)。当python需要搜索模块文件在何处时,首先搜索内置模块,如果不是内置模块,则搜索sys.path中的路径列表,搜索时会从该属性列出的路径中按照从前向后的顺序进行搜索,并且只要找到就立即停止搜索该模块文件(也就是说不会后搜索的同名模块覆盖先搜索的同名模块)。
例如,在a.py文件中输出一下这个属性的内容:
# a.py: import sys print(sys.path)
结果:
['G:\\pycode', 'C:\\Program Files (x86)\\Python36-32\\python36.zip', 'C:\\Program Files (x86)\\Python36-32\\DLLs', 'C:\\Program Files (x86)\\Python36-32\\lib', 'C:\\Program Files (x86)\\Python36-32', 'C:\\Users\\malong\\AppData\\Roaming\\Python\\Python36\\site-packages', 'C:\\Program Files (x86)\\Python36-32\\lib\\site-packages']
python模块的搜索路径包括几个方面,按照如下顺序搜索:
- 程序文件(a.py)所在目录,即
G:\\pycode - 环境变量
PYTHONPATH所设置的路径(如果定义了该环境变量,则从左向右的顺序搜索) - 标准库路径
- .pth文件中定义的路径
需要注意,上面sys.path的结果中,除了.zip是一个文件外,其它的搜索路径全都是目录,也就是从这些目录中搜索模块X的文件X.py是否存在。
程序所在目录
这个目录是最先搜索的,且是python自动搜索的,无需对此进行任何设置。从交互式python程序终输出sys.path的结果:
>>> sys.path ['', 'C:\\WINDOWS\\system32', 'C:\\Program Files (x86)\\Python36-32\\Lib\\idlelib', 'C:\\Program Files (x86)\\Python36-32\\python36.zip', 'C:\\Program Files (x86)\\Python36-32\\DLLs', 'C:\\Program Files (x86)\\Python36-32\\lib', 'C:\\Program Files (x86)\\Python36-32', 'C:\\Users\\malong\\AppData\\Roaming\\Python\\Python36\\site-packages', 'C:\\Program Files (x86)\\Python36-32\\lib\\site-packages']
其中第一个''表示的就是程序所在目录。
注意程序所在目录和当前目录是不同的。例如,在/tmp/目录下执行/pycode中的a.py文件
cd /tmp python /pycode/a.py
其中/tmp为当前目录,而/pycode是程序文件a.py所在的目录。如果a.py中导入b.py,那么将首先搜索/pycode,而不是/tmp。
环境变量PYTHONPATH
这个变量中可以自定义一系列的模块搜索路径列表,这样可以跨目录搜索(另一种方式是设置.pth文件)。但默认情况下这个环境变量是未设置的。
在windows下,设置PYTHONPATH环境变量的方式:命令行中输入:SystemPropertiesAdvanced-->环境变量-->系统环境变量新建

如果是多个路径,则使用英文格式的分号分隔。以下是临时设置当前命令行窗口的PYTHONPATH:
set PYTHONPATH='D:\pypath; d:\pypath1'
在unix下,设置PYTHONPATH环境变量的方式,使用冒号分隔多个路径:另外,必须得export导出为环境变量
export PYTHONPATH=/tmp/pypath1:/tmp/pypath2
如果要永久生效,则写入配置文件中:
echo 'export PYTHONPATH=/tmp/pypath1:/tmp/pypath2' >/etc/profile.d/pypth.sh chmod +x /etc/profile.d/pypth.sh source /etc/profile.d/pypth.sh
标准库路径
在Linux下,标准库的路径一般是在/usr/lib/pythonXXX/下(XXX表示python版本号),此目录下有些分了子目录。
例如:
['', '/usr/lib/python35.zip', '/usr/lib/python3.5', '/usr/lib/python3.5/plat-x86_64-linux-gnu', '/usr/lib/python3.5/lib-dynload', '/usr/local/lib/python3.5/dist-packages', '/usr/lib/python3/dist-packages']
其中/usr/lib/python3.5和其内的几个子目录都是标准库的搜索路径。
注意其中/usr/lib/python35.zip,它是ZIP文件组件,当定义此文件为搜索路径时,将自动解压缩该文件,并从此文件中搜索模块。
Windows下根据python安装位置的不同,标准库的路径不同。如果以默认路径方式安装的python,则标准库路径为C:\\Program Files (x86)\\Python36-32及其分类的子目录。
.pth文件自定义路径
可以将自定义的搜索路径放进一个.pth文件中,每行一个搜索路径。然后将.pth文件放在python安装目录或某个标准库路径内的sitepackages目录下即可。
这是一种替换PYTHONPATH的友好方式,因为不同操作系统设置环境变量的方式不一样,而以文件的方式记录是所有操作系统都通用的。
例如,windows下,在python安装目录C:\\Program Files (x86)\\Python36-32下新增一个mypath.pth文件,内容如下:
d:\pypath1 d:\pypath2
再去输出sys.path,将可以看到这两个路径已经放进了搜索列表中。
修改搜索路径
除了上面环境变量和.pth文件,还可以直接修改sys.path或者site.getsitepackages()的结果。
例如,在import导入sys模块之后,可以修改sys.path,向这个列表中添加其它搜索路径,这样之后导入其它模块的时候,也会搜索该路径。
例如:
import sys
sys.path.append('d:\\pypath3')
print(sys.path)
sys.path的最后一项将是新添加的路径。
导入模块的细节
导入模块时的过程
python的import是在程序运行期间执行的,并非像其它很多语言一样是在编译期间执行。也就是说,import可以出现在任何地方,只有执行到这个import行时,才会执行导入操作。且在import某个模块之前,无法访问这个模块的属性。
python在import导入模块时,首先搜索模块的路径,然后编译并执行这个模块文件。虽然概括起来只有两个过程,但实际上很复杂。
前文已经解释了import的模块搜索过程,所以这里大概介绍import的其它细节。
以前面的a.py中导入模块文件b.py为例:
import b
import导入模块时,搜索到模块文件b.py后:
1.首先在内存中为每个待导入的模块构建module类的实例:模块对象。这个模块对象目前是空对象,这个对象的名称为全局变量b。
注意细节:module类的对象,变量b。
输出下它们就知道:
print(b) print(type(b))
输出结果:
<module 'b' from 'g:\\pycode\\b.py'>
<class 'module'>
因为b是全局变量,所以当前程序文件a.py中不能重新对全局变量b进行赋值,这会使导入的模块b被丢弃。例如,下面是错误的:
import b b=3 print(b.x) # 已经没有模块b了
另外,因为import导入时是将模块对象赋值给模块变量,所以模块变量名不能是python中的一些关键字,比如if、for等,这时会报错。虽然模块文件名可以为list、keys等这样的内置函数名,但这会导致这些内置函数不可用,因为根据变量查找的作用域规则,首先查找全局变量,再查找内置作用域。也就是说,模块文件的文件名不能是这些关键字、也不应该是这些内置函数名。
File "g:/pycode/new.py", line 11 import if ^ SyntaxError: invalid syntax
2.构造空模块实例后,将编译、执行模块文件b.py,并按照一定的规则将一些结果放进这个模块对象中。
注意细节,编译、执行b.py、将结果保存到模块对象中。
模块第一次被导入的时候,会进行编译,并生成.pyc字节码文件,然后python执行这个pyc文件。当模块被再次导入时,如果检查到pyc文件的存在,且和源代码文件的上一次修改时间戳mtime完全对应(也就是说,编译后源代码没有进行过修改),则直接装载这个pyc文件并执行,不会再进行额外的编译过程。当然,如果修改过源代码,将会重新编译得到新的pyc文件。
注意,并非所有的py文件都会生成编译得到的pyc文件,对于那些只执行一次的程序文件,会将内存中的编译结果在执行完成后直接丢弃(多数时候如此,但仍有例外,比如使用compileall模块可以强制编译成pyc文件),但模块会将内存中的编译结果持久化到pyc文件中。另外,运行字节码pyc文件并不会比直接运行py文件更快,执行它也一样是一行行地解释、执行,唯一快的地方在于导入装载的时候无需重新编译而已。
执行模块文件(已完成编译)的时候,按照一般的执行流程执行:一行一行地、以代码块为单元执行。一般地,模块文件中只用来声明变量、函数等属性,以便提供给导入它的模块使用,而不应该有其他任何操作性的行为,比如print()操作不应该出现在模块文件中,但这并非强制。
总之,执行完模块文件后,这个模块文件将有一个自己的全局名称空间,在此模块文件中定义的变量、函数等属性,都会记录在此名称空间中。
最后,模块的这些属性都会保存到模块对象中。由于这个模块对象赋值给了模块变量b,所以通过变量b可以访问到这个对象中的属性(比如变量、函数等),也就是模块文件内定义的全局属性。
只导入一次
假设a.py中导入了模块b和模块sys,在b.py中也导入了模块sys,但python默认对某个模块只会导入一次,如果a.py中先导入sys,再导入b,那么导入b并执行b.py的时候,会发现sys已经导入了,不会再去导入sys。
实际上,python执行程序的时候,会将所有已经导入的模块放进sys.module属性中,这是一个dict,可以通过下面的方式查看已导入的模块名:
>>> import sys >>> list(sys.module.keys())
如果某个程序文件中多次使用import(或from)导入同一个模块,虽然不会报错,但实际上还是直接使用内存中已装载好的模块对象。
例如,b.py中x=3,导入它之后修改该值,然后再次导入,发现b.x并不会发生改变:
import b print(b.x) # 3 b.x=33 print(b.x) # 33 import b print(b.x) # 33
但是python提供了reload进行多次重复导入的方法,见后文。
使用别名
import导入时,可以使用as关键字指定一个别名作为模块对象的变量,例如:
import b as bb bb.x=3 print(bb.x)
这时候模块对象将赋值给变量bb,而不是b,b此时不再是模块对象变量,而仅仅只是模块名。使用别名并不会影响性能,因为它仅仅只是一个赋值过程,只不过是从原来的赋值对象变量b变为变量bb而已。
from导入部分属性
import语句是导入模块中的所有属性,并且访问时需要使用模块变量来引用。例如:
import b print(b.x)
除了import,还有一个from语句,表示从模块中导入部分指定的属性,且使得可以直接使用这些属性的名称来引用这些属性,而不需要加上模块变量名。例如原来import导入时访问变量x使用b.x,from导入时只需使用x即可。实际上,from导入更应该称为属性的再次赋值(拷贝)。
例如,b.py中定义了变量x、y、z,同时定义了函数f()和g(),在a.py中导入这个模块文件,但只导入x变量和f函数:
# a.py文件内容:
from b import x,f
print(x)
f()
# b.py文件内容:
x=3
y=4
z=5
def f():
print("function f in b.py")
def g():
print("function g in b.py")
注意上面a.py中引用模块b中属性的方式没有加上b.X,而是直接使用x和f()来引用。这和import是不一样的。至于from和import导入时的变量名称细节,在下面的内容中会详细解释。
虽然from语句只导入模块的部分属性,但实际上仍然会完整地执行整个模块文件。
同样的,from语句也可以指定导入属性的变量别名,例如,将b.py中的属性x赋值给xx,将y赋值给yy:
from b import x as xx,y as yy print(xx) print(yy)
from语句还有一个特殊导入统配符号*,它表示导入模块中的所有属性。
# a.py文件: from b import * print(x,y,z) f() g()
多数时候,不应该使用from *的方式,因为我们可能会忘记某个模块中有哪些属性拷贝到了当前文件,特别是多个from *时可能会出现属性覆盖的问题。
重载模块:imp.reload()
无论时import还是from,都只导入一次模块,但使用reload()可以强制重新装载模块。
reload()是imp模块中的一个函数,所以要使用imp.reload()之前,必须先导入imp。
from imp import reload reload(b)
reload()是一个函数,它的参数是一个已经成功被导入过的模块变量(如果使用了别名,则应该使用别名作为reload的参数),也就是说该模块必须在内存中已经有自己的模块对象。
reload()会重新执行模块文件,并将执行得到的属性完全覆盖到原有的模块对象中。也就是说,reload()会重新执行模块文件,但不会在内存中建立新的模块对象,所以原有模块对象中的属性可能会被修改。
例如,模块文件b.py中x=3,导入b模块,修改其值为33,然后reload这个模块,会发现值重新变回了3。
import b print(b.x) # 3 b.x=33 print(b.x) # 33 from imp import reload reload(b) print(b.x) # 3
有时候reload()很有用,可以让程序无需重启就执行新的代码。例如,在python的交互式模式下导入模块b,然后修改python源码,再reload导入:
>>> import b >>> b.x 3 # 不要关掉交互式解释器,直接修改源代码中的b=3333 >>> from imp import reload >>> reload(b) <module 'b' from 'G:\\pycode\\b.py'> >>> b.x 3333
但正因为reload()重载模块会改变原始的值,这可能是很危险的行为,一定要清楚地知道它是在干什么。
导入模块时的变量名称细节
import导入的变量
import导入时,模块对象中的属性有自己的名称空间,然后将整个模块对象赋值给模块变量。
例如,在a.py中导入b:
import b print(b.x)
这个过程唯一和当前文件a.py作用域有关的就是模块对象变量b,b.py中声明的属性和当前文件无任何关系。无论是访问还是修改,都是直接修改这个模块对象自身作用域中的值。所以,只要模块变量b不出现冲突问题,可以放心地修改模块b中的属性。
另一方面,因为每个进程都有自己的内存空间,所以在a.py、c.py中都导入b时,a.py中修改b的属性值不会影响c.py中导入的属性,a.py和c.py中模块对象所保存的属性都是执行b.py后得到的,它们相互独立。
from导入的变量
from导入模块时,会先执行完模块文件,然后将指定的部分属性重新赋值给当前程序文件的同名全局变量。
例如,在模块文件b.py中定义了x、y、z变量和f()、g()函数:
# b.py:
x=3
y=4
b=5
def f():
print("function f in b.py")
def g():
print("function g in b.py")
当在a.py中导入b模块时,如果只导入x、y和f():
# a.py: from b import x, y, f
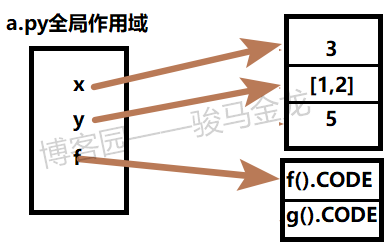
实际上的行为是构造模块对象后,将这个模块对象对应的名称空间中的属性x、y和f重新赋值给a.py中的变量x、y和f,然后丢弃整个模块对象以及整个名称空间。换句话说,b不再是一个有效的模块变量(所以和import不一样),来自b的x,y,z,f和g也都被丢弃。
这里有几个细节,需要详细解释清楚,只有理解了才能搞清楚它们是怎么生效的。
假设现在模块文件b.py的内容为,并且a.py中导入x,y,f属性:
# b.py:
x=3
y=[1,2]
z=5
def f():
print("function f in b.py")
def g():
print("function g in b.py")
# a.py:
from b import x,y,f
首先在执行模块文件b.py时,会构造好自己的模块对象,并且模块对象有自己的名称空间(作用域),模块对象构造完成后,它的名称空间大致如下:
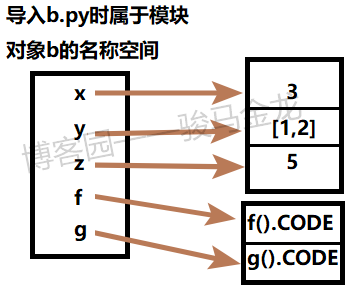
然后python会在a.py的全局作用域内创建和导入属性同名的全局变量x,y和f,并且通过赋值的方式将模块的属性赋值给这些全局变量,也就是:
x = b.x y = b.y f = b.f
上面的b只是用来演示,实际上变量b是不存在的。
赋值完成后,我们和构造的整个模块对象就失去联系了,因为没有变量b去引用这个对象。但需要注意,这个对象并没有被删除,仅仅只是我们无法通过b去找到它。
所以,现在的示意图如下:
因为是赋值的方式传值的,所以在a.py中修改这几个变量的值时,是直接在模块对象作用域内修改的:对于不可变对象,将在此作用域内创建新对象,对于可变对象,将直接修改原始对象的值。
另一方面,由于模块对象一直保留在内存中,下次继续导入时,将直接使用该模块对象。对于import和from,是直接使用该已存在的模块对象,对于reload,是覆盖此模块对象。
例如,在a.py中修改不可变对象x和可变对象y,之后import或from时,可变对象的值都会随之改变,因为它们使用的都是原来的模块对象:
from b import x,y x=33 y[0]=333 from b import x,y print((x,y)) # 输出(3, [333, 2]) import b print((b.x,b.y)) # 输出(3, [333, 2])
from导入时,由于b不再是模块变量,所以无法再使用reload(b)去重载对象。如果想要重载,只能先import,再reload:
from b import x,y ...CODE... # 想要重载b import b from imp import reload reload(b)
查看模块中的属性
内置函数dir可用于列出某模块中定义了哪些属性(全局名称空间)。完整的说明见help(dir)。
import b dir(b)
输出结果:
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'f', 'g', 'x', 'y', 'z']
可见,模块的属性中除了自己定义的属性外,还有一些内置的属性,比如上面以__开头和结尾的属性。
如果dir()不给任何参数,则输出当前环境下定义的名称属性:
>>> import b >>> x=3 >>> aaa=333 >>> dir() ['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'aaa', 'b', 'x']
每个属性都对应一个对象,例如x对应的是int对象,b对应的是module对象:
>>> type(x) <class 'int'> >>> type(b) <class 'module'>
既然是对象,那么它们都会有自己的属性。例如:
>>> dir(x) ['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__gt__', '__hash__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes']
所以,也可以直接dir某个模块内的属性:
import b dir(b.x) dir(b.__name__)
dir()不会列出内置的函数和变量,如果想要输出内置的函数和变量,可以去标准模块builtins中查看,因为它们定义在此模块中:
import builtins dir(buildins)
除了内置dir()函数可以获取属性列表(名称空间),对象的__dict__属性也可以获取对象的属性字典(名称空间),它们的结果不完全一样。详细说明参见dir()和__dict__属性区别。
总的来说,获取对象M中一个自定义的属性age,有以下几种方法:
M.age M.__dict__['age'] sys.modules['M'].age getattr(M,'age')
有妙用的__name__属性
前面说了,py文件分两种:用于执行的程序文件和用于导入的模块文件。当直接使用python a.py的时候表示a.py是用于执行的程序文件,通过import/from方式导入的py文件是模块文件。
__name__属性用来区分py文件是程序文件还是模块文件:
- 当文件是程序文件的时候,该属性被设置为
__main__ - 当文件是模块文件的时候(也就是被导入时),该属性被设置为自身模块名
换句话说,__main__表示的是当前执行程序文件的默认模块名,想必学过其他支持包功能的语言的人很容易理解:程序都需要一个入口,入口程序所在的包就是main包,在main包中导入其它包来组织整个程序。python也是如此,只不过它是隐式自动设置的。
对于python来说,因为隐式自动设置,该属性就有了特殊妙用:直接在模块文件中通过if __name__ == "__main__"来判断,然后写属于执行程序的代码,如果直接用python执行这个文件,说明这个文件是程序文件,于是会执行属于if代码块的代码,如果是被导入,则是模块文件,if代码块中的代码不会被执行。
显然,这是python中非常方便的单元测试方式。
例如,写一个模块文件,里面包含一个函数,用来求给定序列的最大值和最小值:
def minmax(func,*args): res = args[0] for arg in args[1:]: if func(arg,res): res = arg return res def lessthan(x,y): return x < y def greatethan(x,y): return x > y # 测试代码 if __name__ == "__main__": print(minmax(lessthan,3,6,2,1,4,5)) print(minmax(greatethan,3,6,2,1,4,5))
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对我们的支持。
相关推荐
-
Python3 导入上级目录中的模块实例
python导入同级别模块很方便: import xxx 要导入下级目录页挺方便,需要在下级目录中写一个__init__.py文件 from dirname import xxx 要导入上级目录,可以使用 sys.path 首先 sys.path 的作用是:当使用import语句导入模块时,解释器会搜索当前模块所在目录以及sys.path指定的路径去找需要import的模块 所以改变思路,直接把上级目录加到 sys.path 里 import sys sys.path.append('../')
-

Python3导入自定义模块的三种方法详解
前话 最近跟着廖雪峰的教程学到 模块 这一节.关于如何自定义一个模块,如果大家不懂的话先来看看基本的介绍: 模块 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式.在Python中,一个.py文件就称之为一个模块(Module). 使用模块有什么好处? 最大的好处是大大提高了代码的可维护性.其次,编写代码不必从零
-
Pycharm导入Python包,模块的图文教程
1.点击File->settings 2.选择Project Interpreter,点击右边绿色的加号添加包 3.输入你想添加的包名,点击Install Package 4.可以在Pycharm保存项目的目录下查看已经安装的包,路径D:\PycharmProjects\untitled\venv\Lib\site-packages 以上这篇Pycharm导入Python包,模块的图文教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
关于python导入模块import与常见的模块详解
0.什么是python模块?干什么的用的? Java中如果使用abs()函数,则需要需要导入Math包,同样python也是封装的,因为python提供的函数太多,所以根据函数的功能将其封装在不同的module模块中.就这样的话,pthon提供的module还是海量的,所以除非使用某个模块里的某个函数时才会将其导入程序中.所以你使用某个函数前,要先知道他在哪个module里,然后将这个模块导入当前程序,然后才能调用这个模块里的函数. 当然 python的模块分为用户自定义的和系统提供的.Pyth
-
通过字符串导入 Python 模块的方法详解
我们平时导入第三方模块的时候,一般使用的是 import 关键字,例如: import scrapy from scrapy.spider import Spider 但是如果各位同学看过 Scrapy 的 settings.py 文件,就会发现里面会通过字符串的方式来指定pipeline 和 middleware,例如: DOWNLOADER_MIDDLEWARES = { 'Test.middlewares.ExceptionRetryMiddleware': 545, 'Test.midd
-
Python在不同目录下导入模块的实现方法
python在不同层级目录import模块的方法 使用python进行程序编写时,经常会调用不同目录下的模块及函数.本篇博客针对常见的模块调用讲解导入模块的方法. 1. 同级目录下的调用 目录结构如下: – src |– mod1.py |– test1.py 若在程序test1.py中导入模块mod1, 则直接使用 2. 调用子 *import mod1*或from mod1 import *; 目录下的模块 目录结构如下: – src |– mod1.py |– lib | |– mod2.
-
Python使用import导入本地脚本及导入模块的技巧总结
本文实例讲述了Python使用import导入本地脚本及导入模块的技巧.分享给大家供大家参考,具体如下: 导入本地脚本 import 如果你要导入的 Python 脚本与当前脚本位于同一个目录下,只需输入 import,然后是文件名,无需扩展名 .py. 伪代码如下: import useful_functions useful_functions.add_five([1, 2, 3, 4]) 我们可以为导入模块添加别名,以使用不同的名称引用它. import useful_functions
-
浅谈python中requests模块导入的问题
今天使用Pycharm来抓取网页图片时候,要导入requests模块,但是在pycharm中import requests 时候报错. 原因: python中还没有安装requests库 解决办法: 1.先找到自己python安装目录下的pip 2.在自己的电脑里打开cmd窗口. 先点击开始栏,在搜索栏输入cmd,按Enter,打打开cmd窗口.在cmd里将目录切换到你的pip所在路径. 比如我的在C:\Python27\Scripts这个目录下,先切换到d盘,再进入这个路径. 具体命令:cd.
-
python模块导入的细节详解
python模块导入细节 本文主要介绍了关于python模块导入的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 官方手册:https://docs.python.org/3/tutorial/modules.html 可执行文件和模块 python源代码文件按照功能可以分为两种类型: 用于执行的可执行程序文件 不用与执行,仅用于被其它python源码文件导入的模块文件 例如文件a.py和b.py在同一目录下,它们的内容分别是: # b.py x="var x in m
-
Python模块搜索路径代码详解
简述 由于某些原因,在使用 import 时,Python 找不到相应的模块.这时,解释器就会发牢骚 - ImportError. 那么,Python 如何知道在哪里搜索模块的路径呢? 模块搜索路径 当导入名为 hello 的模块时,解释器首先搜索具有该名称的内置模块.如果没有找到,将在变量 sys.path 给出的目录列表中搜索名为 hello.py 的文件. sys.path 从这些位置初始化: 包含输入脚本的目录(或当前目录,当没有指定文件时) PYTHONPATH(目录名列表,与 she
-
python模块常用用法实例详解
1.time模块(※※※※) import time #导入时间模块 print(time.time()) #返回当前时间的时间戳,可用于计算程序运行时间 print(time.localtime()) #返回当地时间的结构化时间格式,参数默认为时间戳 print(time.gmtime) #返回UTC时间的结构化时间格式 print(time.mktime(time.localtime())) #将结构化时间转换为时间戳 print(time.strftime("%Y-%m-%d %X&quo
-
Python模块future用法原理详解
这篇文章主要介绍了Python模块future用法原理详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 计算机的知识太多了,很多东西就是一个使用过程中详细积累的过程.最近遇到了一个很久关于future的问题,踩了坑,这里就做个笔记,免得后续再犯类似错误. future的作用:把下一个新版本的特性导入到当前版本,于是我们就可以在当前版本中测试一些新版本的特性.说的通俗一点,就是你不用更新python的版本,直接加这个模块,就可以使用python
-
python模块之re正则表达式详解
一.简单介绍 正则表达式是一种小型的.高度专业化的编程语言,并不是python中特有的,是许多编程语言中基础而又重要的一部分.在python中,主要通过re模块来实现. 正则表达式模式被编译成一系列的字节码,然后由用c编写的匹配引擎执行.那么正则表达式通常有哪些使用场景呢? 比如为想要匹配的相应字符串集指定规则: 该字符串集可以是包含e-mail地址.Internet地址.电话号码,或是根据需求自定义的一些字符串集: 当然也可以去判断一个字符串集是否符合我们定义的匹配规则: 找到字符串中匹配该规
-
Python模块glob函数示例详解教程
目录 本文大纲 支持4个常用的通配符 1)glob()函数 2)iglob()函数 3)escape()函数 总结 本文大纲 glob模块也是Python标准库中一个重要的模块,主要用来查找符合特定规则的目录和文件,并将搜索的到的结果返回到一个列表中.使用这个模块最主要的原因就是,该模块支持几个特殊的正则通配符,用起来贼方便,这个将会在下方为大家进行详细讲解. 支持4个常用的通配符 使用glob模块能够快速查找我们想要的目录和文件,就是由于它支持*.**.? .[ ]这三个通配符,那么它们到底是
-
用python做游戏的细节详解
PyGame是一个Python的库,能够让你更容易的写出一个游戏.它提供的功能包括图片处理和声音重放的功能,并且它们能很容易的整合进你的游戏里.去官网点击这里下载适合你的PyGame安装包. 大家可以参阅:Python中pygame安装方法图文详解 我们就拿打飞机来做个例子 1 .创建游戏框架以及游戏背景 #这个模块放一些常用的工具和基础类和精灵类 #在其他模块调用 import pygame import random #设置游戏屏幕大小 这是一个常量 SCREEN_RECT = pygame
-
对Python模块导入时全局变量__all__的作用详解
Python中一个py文件就是一个模块,"__all__"变量是一个特殊的变量,可以在py文件中,也可以在包的__init__.py中出现. 1.在普通模块中使用时,表示一个模块中允许哪些属性可以被导入到别的模块中, 如:全局变量,函数,类.如下,test1.py和main.py test1.py __all__=["test"] def test(): print('----test-----') def test1(): print('----test1----
-
python中模块的__all__属性详解
python模块中的__all__属性,可用于模块导入时限制,如: from module import * 此时被导入模块若定义了__all__属性,则只有__all__内指定的属性.方法.类可被导入. 若没定义,则导入模块内的所有公有属性,方法和类 # kk.py class A(): def __init__(self,name,age): self.name=name self.age=age class B(): def __init__(self,name,id): self.nam
-
Python使用base64模块进行二进制数据编码详解
前言 昨天团队的学妹来问关于POP3协议的问题,所以今天稍稍研究了下POP3协议的格式和Python里面的poplib.而POP服务器往回传的数据里有一部分需要用到Base64进行解码,所以就顺便看了下Python里面的base64模块. 本篇先讲一下base64模块,该模块提供了关于Base16,Base32,Base64,Base85和Ascii85的编码和解码相关的函数.有关poplib模块的内容,会在后面发上来.嗯,又挖了一个坑,这辈子挖的坑填不完了... 以下内容摘自http://bb