纯用NumPy实现神经网络的示例代码
摘要: 纯NumPy代码从头实现简单的神经网络。
Keras、TensorFlow以及PyTorch都是高级别的深度学习框架,可用于快速构建复杂模型。前不久,我曾写过一篇文章,对神经网络是如何工作的进行了简单的讲解。该文章侧重于对神经网络中运用到的数学理论知识进行详解。本文将利用NumPy实现简单的神经网络,在实战中对其进行深层次剖析。最后,我们会利用分类问题对模型进行测试,并与Keras所构建的神经网络模型进行性能的比较。
Note:源码可在我的GitHub中查看。
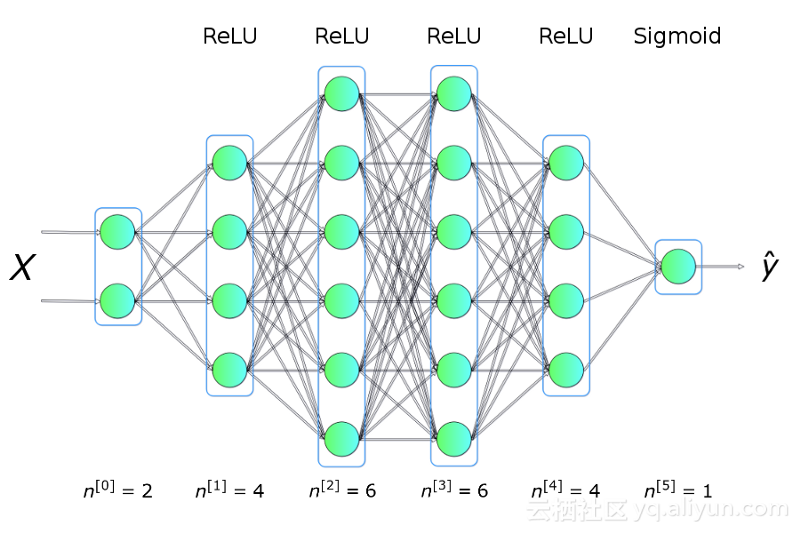
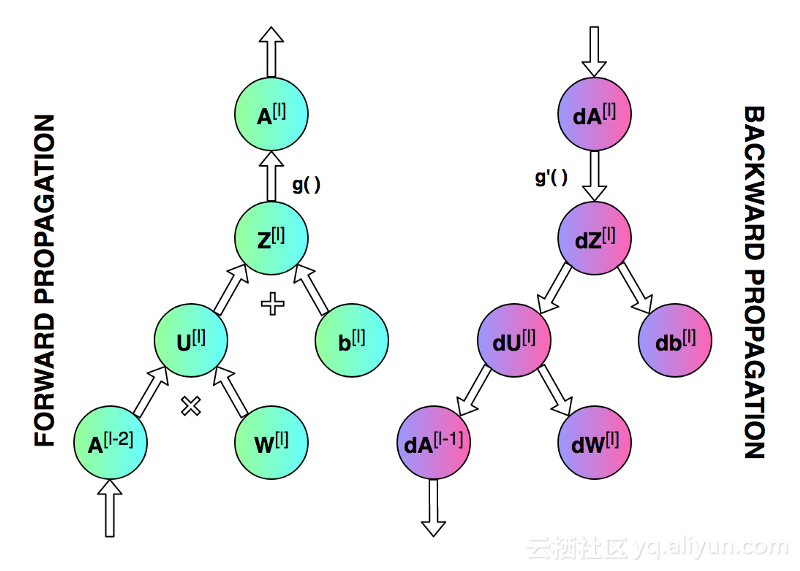
在正式开始之前,需要先对所做实验进行构思。我们想要编写一个程序,使其能够创建一个具有指定架构(层的数量、大小以及激活函数)的神经网络,如图一所示。总之,我们需要预先对网络进行训练,然后利用它进行预测。
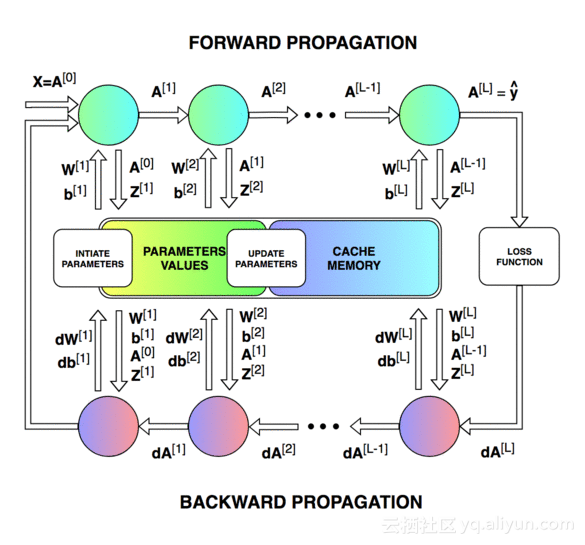
上图展示了神经网络在被训练时的工作流程。从中我们可以清楚的需要更新的参数数量以及单次迭代的不同状态。构建并管理正确的数据架构是其中最困难的一环。由于时间限制,图中所示的参数不会一一详解,有兴趣可点击此处进行了解。
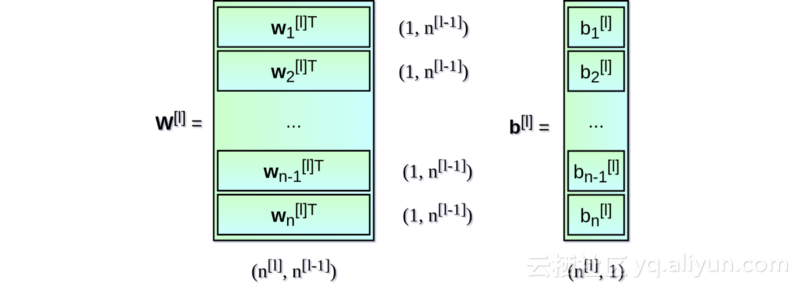
神经网络层的初始化
首先,对每一层的权重矩阵W及偏置向量b进行初始化。在上图中,上标[l]表示目前是第几层(从1开始),n的值表示一层中的神经元数量。描述神经网络架构的信息类似于Snippet 1中所列内容。每一项都描述了单层神经网络的基本参数:input_dim,即输入层神经元维度;output_dim,即输出层神经元维度;activation,即使用的激活函数。
nn_architecture = [
{"input_dim": 2, "output_dim": 4, "activation": "relu"},
{"input_dim": 4, "output_dim": 6, "activation": "relu"},
{"input_dim": 6, "output_dim": 6, "activation": "relu"},
{"input_dim": 6, "output_dim": 4, "activation": "relu"},
{"input_dim": 4, "output_dim": 1, "activation": "sigmoid"},
]
Snippet 1.
从Snippet 1可看出,每一层输出神经元的维度等于下一层的输入维度。对权重矩阵W及偏置向量b进行初始化的代码如下:
def init_layers(nn_architecture, seed = 99):
np.random.seed(seed)
number_of_layers = len(nn_architecture)
params_values = {}
for idx, layer in enumerate(nn_architecture):
layer_idx = idx + 1
layer_input_size = layer["input_dim"]
layer_output_size = layer["output_dim"]
params_values['W' + str(layer_idx)] = np.random.randn(
layer_output_size, layer_input_size) * 0.1
params_values['b' + str(layer_idx)] = np.random.randn(
layer_output_size, 1) * 0.1
return params_values
Snippet 2.
在本节中,我们利用NumPy将权重矩阵W及偏置向量b初始化为小的随机数。特别注意的是,初始化权重值不能相同,否则网络会变为对称的。也就是说,如果权重初始化为同一值,则对于任何输入X,每个隐藏层对应的每个神经元的输出都是相同的,这样即使梯度下降训练,无论训练多少次,这些神经元都是对称的,无论隐藏层内有多少个结点,都相当于在训练同一个函数。
初始化的值较小能够使得算法第一次迭代的时候效率更高。Sigmoid函数图像如下图所示,它对中央区的信号增益较大,对两侧区的信号增益小。
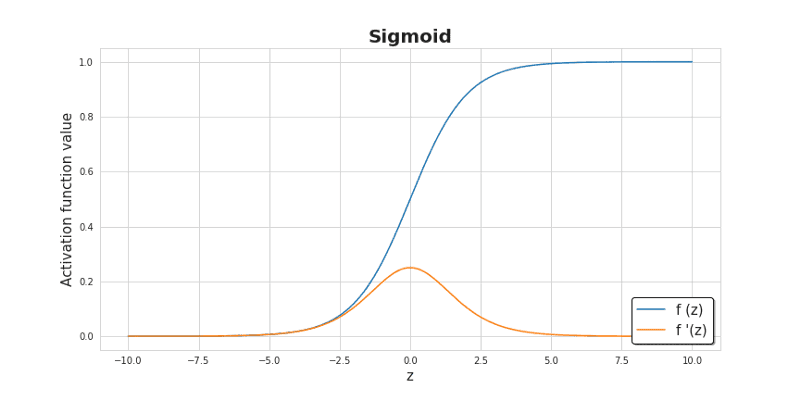
激活函数(Activation functions)
激活函数在神经网络中至关重要,其原理简单但功能强大,给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,从而应用于众多的非线性模型。“如果没有激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。”激活函数种类众多,本文选取了最常用的两种——ReLU及Sigmoid函数,代码如下:
def sigmoid(Z): return 1/(1+np.exp(-Z)) def relu(Z): return np.maximum(0,Z) def sigmoid_backward(dA, Z): sig = sigmoid(Z) return dA * sig * (1 - sig) def relu_backward(dA, Z): dZ = np.array(dA, copy = True) dZ[Z <= 0] = 0; return dZ;
Snippet 3.
前向传播算法(Forward propagation)
本文所设计的神经网络结构简单,信息流只有一个方向:以X矩阵的形式传递,穿过所有隐藏层单元,最终输出预测结构Y_hat。
def single_layer_forward_propagation(A_prev, W_curr, b_curr, activation="relu"):
Z_curr = np.dot(W_curr, A_prev) + b_curr
if activation is "relu":
activation_func = relu
elif activation is "sigmoid":
activation_func = sigmoid
else:
raise Exception('Non-supported activation function')
return activation_func(Z_curr), Z_curr
Snippet 4.
前向传播就是上层处理完的数据作为下一层的输入数据,然后进行处理(权重),再传给下一层,这样逐层处理,最后输出。给定上一层的输入信号,计算仿射变换(affine transformation)Z,然后应用选定的激活函数。
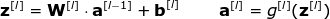
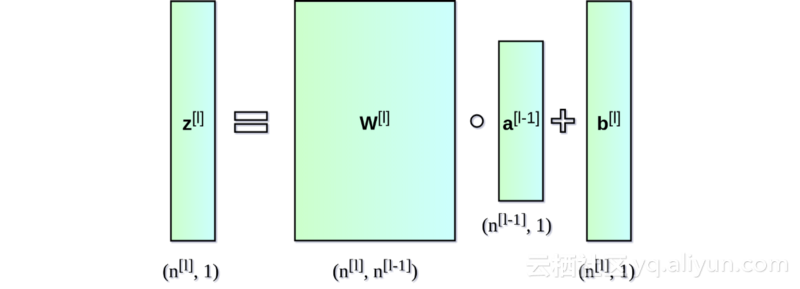
前向传播算法代码如下,该函数不仅进行预测计算,还存储中间层A和Z矩阵的值:
def full_forward_propagation(X, params_values, nn_architecture):
memory = {}
A_curr = X
for idx, layer in enumerate(nn_architecture):
layer_idx = idx + 1
A_prev = A_curr
activ_function_curr = layer["activation"]
W_curr = params_values["W" + str(layer_idx)]
b_curr = params_values["b" + str(layer_idx)]
A_curr, Z_curr = single_layer_forward_propagation(A_prev, W_curr, b_curr, activ_function_curr)
memory["A" + str(idx)] = A_prev
memory["Z" + str(layer_idx)] = Z_curr
return A_curr, memory
Snippet 5.
损失函数(Loss function)
损失函数是用来估量模型的预测值与真实值的不一致程度,它是一个非负实值函数。损失函数由我们想要解决的问题所决定。在本文中,我们想要测试神经网络模型区分两个类别的能力,所以选择了交叉熵损失函数(binary_crossentropy),其定义如下:

为了更加清楚的了解学习过程,我增添了一个用于计算精度的函数:
def get_cost_value(Y_hat, Y): m = Y_hat.shape[1] cost = -1 / m * (np.dot(Y, np.log(Y_hat).T) + np.dot(1 - Y, np.log(1 - Y_hat).T)) return np.squeeze(cost) def get_accuracy_value(Y_hat, Y): Y_hat_ = convert_prob_into_class(Y_hat) return (Y_hat_ == Y).all(axis=0).mean()
Snippet 6.
反向传播算法(Backward propagation)
许多缺乏经验的深度学习爱好者认为反向传播是一种复杂且难以理解的算法。
def single_layer_backward_propagation(dA_curr, W_curr, b_curr, Z_curr, A_prev, activation="relu"):
m = A_prev.shape[1]
if activation is "relu":
backward_activation_func = relu_backward
elif activation is "sigmoid":
backward_activation_func = sigmoid_backward
else:
raise Exception('Non-supported activation function')
dZ_curr = backward_activation_func(dA_curr, Z_curr)
dW_curr = np.dot(dZ_curr, A_prev.T) / m
db_curr = np.sum(dZ_curr, axis=1, keepdims=True) / m
dA_prev = np.dot(W_curr.T, dZ_curr)
return dA_prev, dW_curr, db_curr
Snippet 7.
其实,他们困惑的也就是反向传播算法中的梯度下降问题,但二者并不可混为一谈。前者旨在有效地计算梯度,而后者是利用计算得到的梯度进行优化。梯度下降可以应对带有明确求导函数的情况,我们可以把它看作没有隐藏层的网络;但对于多隐藏层的神经网络,应先将误差反向传播至隐藏层,然后再应用梯度下降,其中将误差从最末层往前传递的过程需要链式法则,反向传播算法可以说是梯度下降在链式法则中的应用。对于单层的神经网络,该过程如下所示:
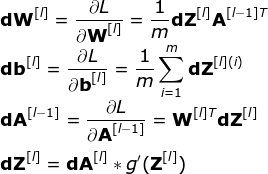
本文省略的推导过程,但从上面的公式仍可看出A和Z矩阵值的重要性。
Snippet 7中所示代码仅编写了神经网络中某层的反向传播算法,Snippet 8将展示神经网络中完整的反向传播算法。
def full_backward_propagation(Y_hat, Y, memory, params_values, nn_architecture):
grads_values = {}
m = Y.shape[1]
Y = Y.reshape(Y_hat.shape)
dA_prev = - (np.divide(Y, Y_hat) - np.divide(1 - Y, 1 - Y_hat));
for layer_idx_prev, layer in reversed(list(enumerate(nn_architecture))):
layer_idx_curr = layer_idx_prev + 1
activ_function_curr = layer["activation"]
dA_curr = dA_prev
A_prev = memory["A" + str(layer_idx_prev)]
Z_curr = memory["Z" + str(layer_idx_curr)]
W_curr = params_values["W" + str(layer_idx_curr)]
b_curr = params_values["b" + str(layer_idx_curr)]
dA_prev, dW_curr, db_curr = single_layer_backward_propagation(
dA_curr, W_curr, b_curr, Z_curr, A_prev, activ_function_curr)
grads_values["dW" + str(layer_idx_curr)] = dW_curr
grads_values["db" + str(layer_idx_curr)] = db_curr
return grads_values
Snippet 8.
参数更新(Updating parameters values)
该部分旨在利用计算得到梯度更新网络中的参数,同时最小化目标函数。我们会使用到params_values,它存放当前的参数值,以及grads_values,它存放存储关于这些参数的损失函数的导数。现在只需要在神经网络的每层应用如下公式即可:
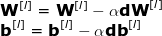
def update(params_values, grads_values, nn_architecture, learning_rate):
for layer_idx, layer in enumerate(nn_architecture):
params_values["W" + str(layer_idx)] -= learning_rate * grads_values["dW" + str(layer_idx)]
params_values["b" + str(layer_idx)] -= learning_rate * grads_values["db" + str(layer_idx)]
return params_values;
Snippet 9.
整合(Putting things together)
现在我们只需将准备好的函数按照正确的顺序整合到一起,若对正确的顺序有疑问请参见图2。
def train(X, Y, nn_architecture, epochs, learning_rate):
params_values = init_layers(nn_architecture, 2)
cost_history = []
accuracy_history = []
for i in range(epochs):
Y_hat, cashe = full_forward_propagation(X, params_values, nn_architecture)
cost = get_cost_value(Y_hat, Y)
cost_history.append(cost)
accuracy = get_accuracy_value(Y_hat, Y)
accuracy_history.append(accuracy)
grads_values = full_backward_propagation(Y_hat, Y, cashe, params_values, nn_architecture)
params_values = update(params_values, grads_values, nn_architecture, learning_rate)
return params_values, cost_history, accuracy_history
Snippet 10.
对比分析(David vs Goliath)
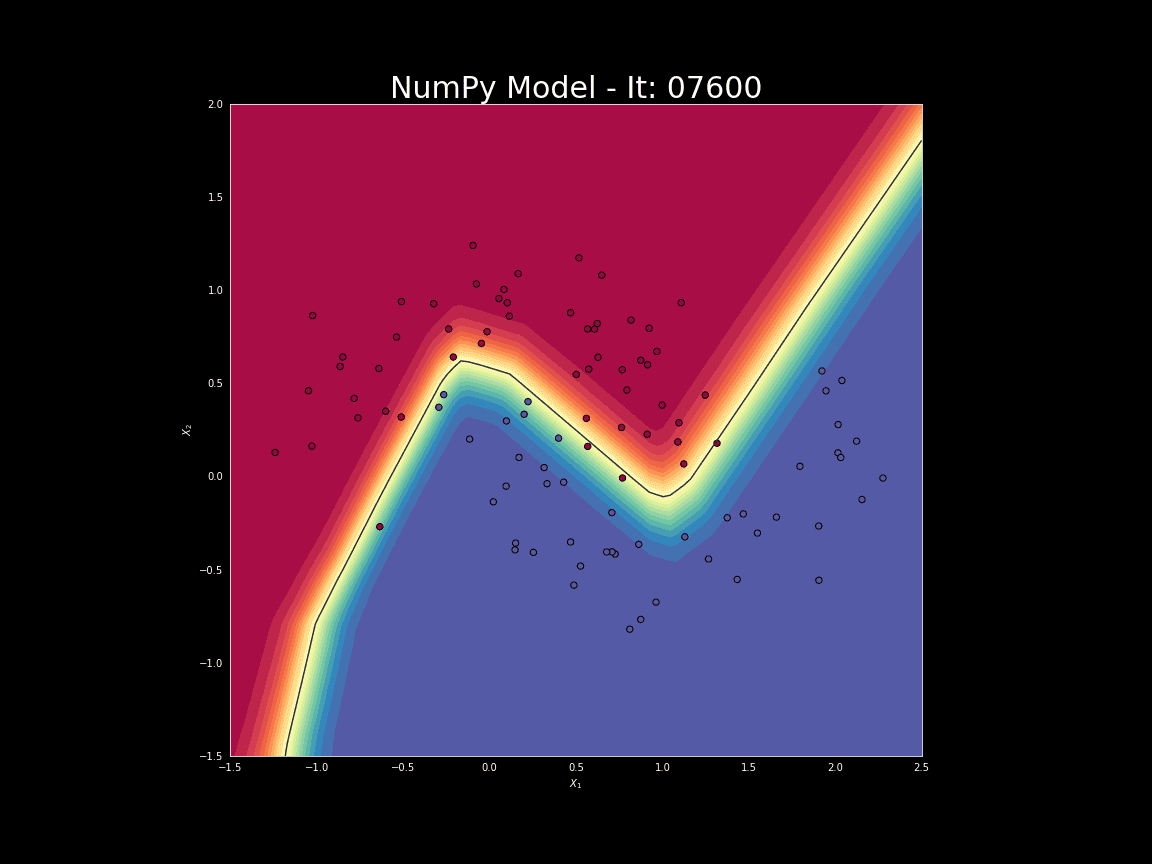
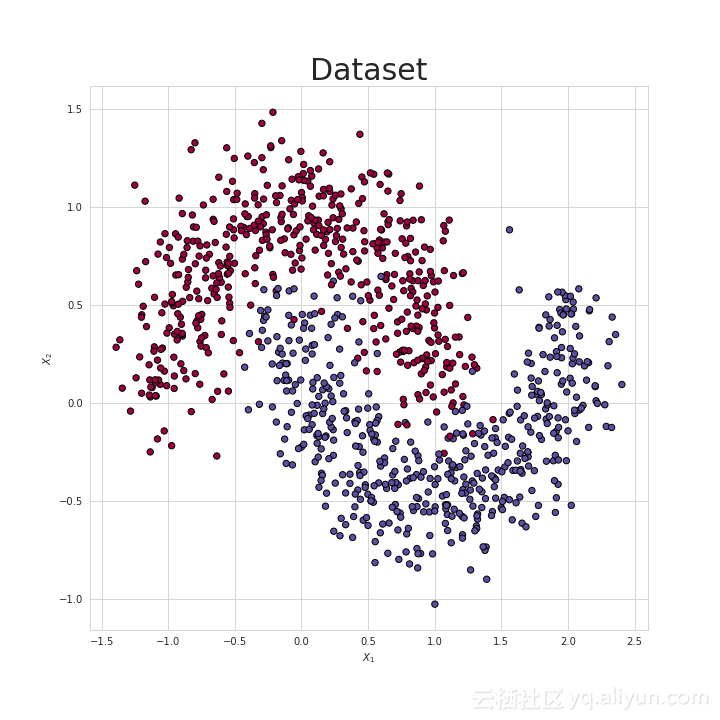
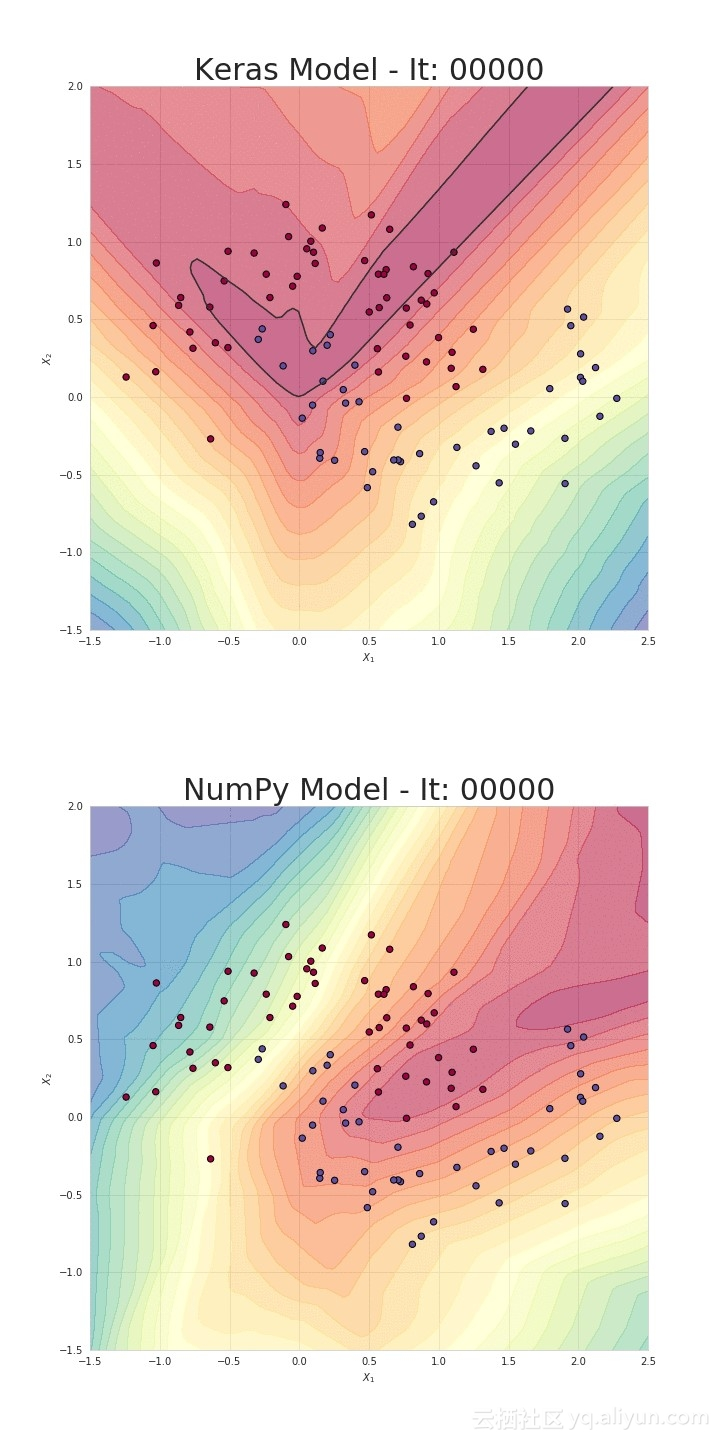
接下来,我们将利用所构建的模型解决简单的分类问题。如图7所示,本次实验使用的数据集包含两个类别。我们将训练模型对两个不同的类别进行区分。此外,我们还准备了一个由Keras所构建的神经网络模型以进行对比。两个模型具有相同的架构和学习速率。虽然我们的模型很简单,但结果表明,NumPy和Keras模型在测试集上均达到了95%的准确率。只是我们的模型耗费了更多的时间,未来工作可通过加强优化改善时间开销问题。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python机器学习之神经网络实现
神经网络在机器学习中有很大的应用,甚至涉及到方方面面.本文主要是简单介绍一下神经网络的基本理论概念和推算.同时也会介绍一下神经网络在数据分类方面的应用. 首先,当我们建立一个回归和分类模型的时候,无论是用最小二乘法(OLS)还是最大似然值(MLE)都用来使得残差达到最小.因此我们在建立模型的时候,都会有一个loss function. 而在神经网络里也不例外,也有个类似的loss function. 对回归而言: 对分类而言: 然后同样方法,对于W开始求导,求导为零就可以求出极值来. 关于式子中
-
PyTorch快速搭建神经网络及其保存提取方法详解
有时候我们训练了一个模型, 希望保存它下次直接使用,不需要下次再花时间去训练 ,本节我们来讲解一下PyTorch快速搭建神经网络及其保存提取方法详解 一.PyTorch快速搭建神经网络方法 先看实验代码: import torch import torch.nn.functional as F # 方法1,通过定义一个Net类来建立神经网络 class Net(torch.nn.Module): def __init__(self, n_feature, n_hidden, n_output):
-
Tensorflow实现卷积神经网络的详细代码
本文实例为大家分享了Tensorflow实现卷积神经网络的具体代码,供大家参考,具体内容如下 1.概述 定义: 卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现.它包括卷积层(alternating convolutional layer)和池层(pooling layer). 卷积层(convolutional layer): 对输入数据应用若干过滤器,一个输入参数被
-
Tensorflow卷积神经网络实例
CNN最大的特点在于卷积的权值共享结构,可以大幅减少神经网络的参数量,防止过拟合的同时又降低了神经网络模型的复杂度.在CNN中,第一个卷积层会直接接受图像像素级的输入,每一个卷积操作只处理一小块图像,进行卷积变化后再传到后面的网络,每一层卷积都会提取数据中最有效的特征.这种方法可以提取到图像中最基础的特征,比如不同方向的边或者拐角,而后再进行组合和抽象形成更高阶的特征. 一般的卷积神经网络由多个卷积层构成,每个卷积层中通常会进行如下几个操作: 图像通过多个不同的卷积核的滤波,并加偏置(bias)
-
神经网络相关之基础概念的讲解
人工神经网络需要一定的数学基础,但是一般来说比较简单,简单的高数基础即可,这里整理了一些所需要的最基础的概念的理解,对于神经网络的入门,非常基础和重要,而且理解了之后,会发现介绍不需要在看,磨刀不误砍柴工,强烈建议理解清楚之后在去使用诸如tensorflow这样的利器. 自变量/因变量/函数 因为E文文档的阅读时不可避免的接触这些内容,一般将英文也列出来,尽量记住,阅读时会大大提高速度. 导数 作为高数最为基础的导数概念,这里不在赘述,简单烈一下内容能够大体理解即可, 借用一张图形来进行解释:
-
Tensorflow实现AlexNet卷积神经网络及运算时间评测
本文实例为大家分享了Tensorflow实现AlexNet卷积神经网络的具体实现代码,供大家参考,具体内容如下 之前已经介绍过了AlexNet的网络构建了,这次主要不是为了训练数据,而是为了对每个batch的前馈(Forward)和反馈(backward)的平均耗时进行计算.在设计网络的过程中,分类的结果很重要,但是运算速率也相当重要.尤其是在跟踪(Tracking)的任务中,如果使用的网络太深,那么也会导致实时性不好. from datetime import datetime import
-
PyTorch上搭建简单神经网络实现回归和分类的示例
本文介绍了PyTorch上搭建简单神经网络实现回归和分类的示例,分享给大家,具体如下: 一.PyTorch入门 1. 安装方法 登录PyTorch官网,http://pytorch.org,可以看到以下界面: 按上图的选项选择后即可得到Linux下conda指令: conda install pytorch torchvision -c soumith 目前PyTorch仅支持MacOS和Linux,暂不支持Windows.安装 PyTorch 会安装两个模块,一个是torch,一个 torch
-
Python实现的NN神经网络算法完整示例
本文实例讲述了Python实现的NN神经网络算法.分享给大家供大家参考,具体如下: 参考自Github开源代码:https://github.com/dennybritz/nn-from-scratch 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) sklearn(人工智能包,生成数据使用) 计算过程 输入样例 none 代码实现 # -*- coding:utf-8 -*- #!python3 __author__ = 'Wsine' im
-
BP神经网络原理及Python实现代码
本文主要讲如何不依赖TenserFlow等高级API实现一个简单的神经网络来做分类,所有的代码都在下面:在构造的数据(通过程序构造)上做了验证,经过1个小时的训练分类的准确率可以达到97%. 完整的结构化代码见于:链接地址 先来说说原理 网络构造 上面是一个简单的三层网络:输入层包含节点X1 , X2:隐层包含H1,H2:输出层包含O1. 输入节点的数量要等于输入数据的变量数目. 隐层节点的数量通过经验来确定. 如果只是做分类,输出层一般一个节点就够了. 从输入到输出的过程 1.输入节点的输出等
-
Tensorflow卷积神经网络实例进阶
在Tensorflow卷积神经网络实例这篇博客中,我们实现了一个简单的卷积神经网络,没有复杂的Trick.接下来,我们将使用CIFAR-10数据集进行训练. CIFAR-10是一个经典的数据集,包含60000张32*32的彩色图像,其中训练集50000张,测试集10000张.CIFAR-10如同其名字,一共标注为10类,每一类图片6000张. 本文实现了进阶的卷积神经网络来解决CIFAR-10分类问题,我们使用了一些新的技巧: 对weights进行了L2的正则化 对图片进行了翻转.随机剪切等数据