深入理解Python虚拟机中整型(int)的实现原理及源码剖析
目录
- 数据结构
- 深入分析 PyLongObject 字段的语意
- 小整数池
- 整数的加法实现
- 总结
数据结构
在 cpython 内部的 int 类型的实现数据结构如下所示:
typedef struct _longobject PyLongObject;
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
#define PyObject_VAR_HEAD PyVarObject ob_base;
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;
上面的数据结构用图的方式表示出来如下图所示:

- ob_refcnt,表示对象的引用记数的个数,这个对于垃圾回收很有用处,后面我们分析虚拟机中垃圾回收部分在深入分析。
- ob_type,表示这个对象的数据类型是什么,在 python 当中有时候需要对数据的数据类型进行判断比如 isinstance, type 这两个关键字就会使用到这个字段。
- ob_size,这个字段表示这个整型对象数组 ob_digit 当中一共有多少个元素。
- digit 类型其实就是 uint32_t 类型的一个 宏定义,表示 32 位的整型数据。
深入分析 PyLongObject 字段的语意
首先我们知道在 python 当中的整数是不会溢出的,这正是 PyLongObject 使用数组的原因。在 cpython 内部的实现当中,整数有 0 、正数、负数,对于这一点在 cpython 当中有以下几个规定:
- ob_size,保存的是数组的长度,ob_size 大于 0 时保存的是正数,当 ob_size 小于 0 时保存的是负数。
- ob_digit,保存的是整数的绝对值。在前面我们谈到了,ob_digit 是一个 32 位的数据,但是在 cpython 内部只会使用其中的前 30 位,这只为了避免溢出的问题。
我们下面使用几个例子来深入理解一下上面的规则:
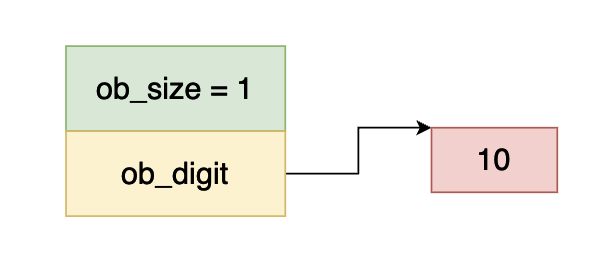
在上图当中 ob_size 大于 0 ,说明这个数是一个正数,而 ob_digit 指向一个 int32 的数据,数的值等于 10,因此上面这个数表示整数 10 。
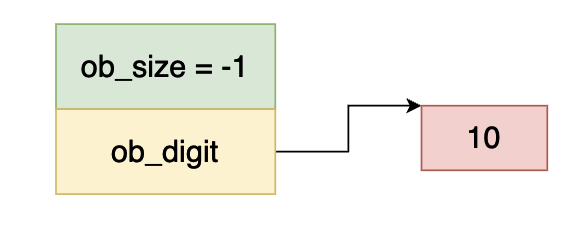
同理 ob_size 小于 0,而 ob_digit 等于 10,因此上图当中的数据表示 -10 。

上面是一个 ob_digit 数组长度为 2 的例子,上面所表示数据如下所示:
1⋅20+1⋅21+1⋅22+...+1⋅229+0⋅230+0⋅231+1⋅232
因为对于每一个数组元素来说我们只使用前 30 位,因此到第二个整型数据的时候正好对应着 230,大家可以对应着上面的结果了解整个计算过程。

上面也就很简单了:
−(1⋅20+1⋅21+1⋅22+...+1⋅229+0⋅230+0⋅231+1⋅232)
小整数池
为了避免频繁的创建一些常用的整数,加快程序执行的速度,我们可以将一些常用的整数先缓存起来,如果需要的话就直接将这个数据返回即可。在 cpython 当中相关的代码如下所示:(小整数池当中缓存数据的区间为[-5, 256])
#define NSMALLPOSINTS 257 #define NSMALLNEGINTS 5 static PyLongObject small_ints[NSMALLNEGINTS + NSMALLPOSINTS];

我们使用下面的代码进行测试,看是否使用了小整数池当中的数据,如果使用的话,对于使用小整数池当中的数据,他们的 id() 返回值是一样的,id 这个内嵌函数返回的是 python 对象的内存地址。
>>> a = 1 >>> b = 2 >>> c = 1 >>> id(a), id(c) (4343136496, 4343136496) >>> a = -6 >>> c = -6 >>> id(a), id(c) (4346020624, 4346021072) >>> a = 257 >>> b = 257 >>> id(a), id(c) (4346021104, 4346021072) >>>
从上面的结果我们可以看到的是,对于区间[-5, 256]当中的值,id 的返回值确实是一样的,不在这个区间之内的返回值就是不一样的。
我们还可以这个特性实现一个小的 trick,就是求一个 PyLongObject 对象所占的内存空间大小,因为我们可以使用 -5 和 256 这两个数据的内存首地址,然后将这个地址相减就可以得到 261 个 PyLongObject 所占的内存空间大小(注意虽然小整数池当中一共有 262 个数据,但是最后一个数据是内存首地址,并不是尾地址,因此只有 261 个数据),这样我们就可以求一个 PyLongObject 对象的内存大小。
>>> a = -5 >>> b = 256 >>> (id(b) - id(a)) / 261 32.0 >>>
从上面的输出结果我们可以看到一个 PyLongObject 对象占 32 个字节。我们可以使用下面的 C 程序查看一个 PyLongObject 真实所占的内存空间大小。
#include "Python.h"
#include <stdio.h>
int main()
{
printf("%ld\n", sizeof(PyLongObject));
return 0;
}
上面的程序的输出结果如下所示:

上面两个结果是相等的,因此也验证了我们的想法。
从小整数池当中获取数据的核心代码如下所示:
static PyObject *
get_small_int(sdigit ival)
{
PyObject *v;
assert(-NSMALLNEGINTS <= ival && ival < NSMALLPOSINTS);
v = (PyObject *)&small_ints[ival + NSMALLNEGINTS];
Py_INCREF(v);
return v;
}
整数的加法实现
关于 PyLongObject 的操作有很多,我们看一下加法的实现,见微知著,剩下的其他的方法我们就不介绍了,大家感兴趣可以去看具体的源代码。
如果你了解过大整数加法就能够知道,大整数加法的具体实现过程了,在 cpython 内部的实现方式其实也是一样的,就是不断的进行加法操作然后进行进位操作。
#define Py_ABS(x) ((x) < 0 ? -(x) : (x)) // 返回 x 的绝对值
#define PyLong_BASE ((digit)1 << PyLong_SHIFT)
#define PyLong_MASK ((digit)(PyLong_BASE - 1))
static PyLongObject *
x_add(PyLongObject *a, PyLongObject *b)
{
// 首先获得两个整型数据的 size
Py_ssize_t size_a = Py_ABS(Py_SIZE(a)), size_b = Py_ABS(Py_SIZE(b));
PyLongObject *z;
Py_ssize_t i;
digit carry = 0;
// 确保 a 保存的数据 size 是更大的
/* Ensure a is the larger of the two: */
if (size_a < size_b) {
{ PyLongObject *temp = a; a = b; b = temp; }
{ Py_ssize_t size_temp = size_a;
size_a = size_b;
size_b = size_temp; }
}
// 创建一个新的 PyLongObject 对象,而且数组的长度是 size_a + 1
z = _PyLong_New(size_a+1);
if (z == NULL)
return NULL;
// 下面就是整个加法操作的核心
for (i = 0; i < size_b; ++i) {
carry += a->ob_digit[i] + b->ob_digit[i];
// 将低 30 位的数据保存下来
z->ob_digit[i] = carry & PyLong_MASK;
// 将 carry 右移 30 位,如果上面的加法有进位的话 刚好可以在下一次加法当中使用(注意上面的 carry)
// 使用的是 += 而不是 =
carry >>= PyLong_SHIFT; // PyLong_SHIFT = 30
}
// 将剩下的长度保存 (因为 a 的 size 是比 b 大的)
for (; i < size_a; ++i) {
carry += a->ob_digit[i];
z->ob_digit[i] = carry & PyLong_MASK;
carry >>= PyLong_SHIFT;
}
// 最后保存高位的进位
z->ob_digit[i] = carry;
return long_normalize(z); // long_normalize 这个函数的主要功能是保证 ob_size 保存的是真正的数据的长度 因为可以是一个正数加上一个负数 size 还变小了
}
PyLongObject *
_PyLong_New(Py_ssize_t size)
{
PyLongObject *result;
/* Number of bytes needed is: offsetof(PyLongObject, ob_digit) +
sizeof(digit)*size. Previous incarnations of this code used
sizeof(PyVarObject) instead of the offsetof, but this risks being
incorrect in the presence of padding between the PyVarObject header
and the digits. */
if (size > (Py_ssize_t)MAX_LONG_DIGITS) {
PyErr_SetString(PyExc_OverflowError,
"too many digits in integer");
return NULL;
}
// offsetof 会调用 gcc 的一个内嵌函数 __builtin_offsetof
// offsetof(PyLongObject, ob_digit) 这个功能是得到 PyLongObject 对象 字段 ob_digit 之前的所有字段所占的内存空间的大小
result = PyObject_MALLOC(offsetof(PyLongObject, ob_digit) +
size*sizeof(digit));
if (!result) {
PyErr_NoMemory();
return NULL;
}
// 将对象的 result 的引用计数设置成 1
return (PyLongObject*)PyObject_INIT_VAR(result, &PyLong_Type, size);
}
static PyLongObject *
long_normalize(PyLongObject *v)
{
Py_ssize_t j = Py_ABS(Py_SIZE(v));
Py_ssize_t i = j;
while (i > 0 && v->ob_digit[i-1] == 0)
--i;
if (i != j)
Py_SIZE(v) = (Py_SIZE(v) < 0) ? -(i) : i;
return v;
}
总结
在本篇文章当中主要给大家介绍了 cpython 内部是如何实现整型数据 int 的,分析了 int 类型的表示方式和设计。int 内部使用 digit 来表示 32 位的整型数据,同时为了避免溢出的问题,只会使用其中的前 30 位。在 cpython 内部的实现当中,整数有 0 、正数、负数,对于这一点有以下几个规定:
- ob_size,保存的是数组的长度,ob_size 大于 0 时保存的是正数,当 ob_size 小于 0 时保存的是负数。
- ob_digit,保存的是整数的绝对值。
- 此外,为避免频繁创建一些常用的整数,cpython 使用了小整数池的技术,将一些常用的整数先缓存起来。最后,本文还介绍了整数的加法实现,即不断进行加法操作然后进行进位操作。
cpython 使用这种方式的主要原理就是大整数的加减乘除,本篇文章主要是介绍了加法操作,大家如果感兴趣可以自行阅读其他的源程序。
以上就是深入理解Python虚拟机中整型(int)的实现原理及源码剖析的详细内容,更多关于Python虚拟机整型的资料请关注我们其它相关文章!
相关推荐
-
深入理解Python虚拟机中复数(complex)的实现原理及源码剖析
目录 复数数据结构 复数的操作 复数加法 复数取反 Repr 函数 总结 复数数据结构 在 cpython 当中对于复数的数据结构实现如下所示: typedef struct { double real; double imag; } Py_complex; #define PyObject_HEAD PyObject ob_base; typedef struct { PyObject_HEAD Py_complex cval; } PyComplexObject; typedef struc
-
Python虚拟机栈帧对象及获取源码学习
目录 Python虚拟机 1. 栈帧对象 1.1 PyFrameObject 1.2 栈帧对象链 1.3 栈帧获取 2. 字节码执行 Python虚拟机 注:本篇是根据教程学习记录的笔记,部分内容与教程是相同的,因为转载需要填链接,但是没有,所以填的原创,如果侵权会直接删除.此外,本篇内容大部分都咨询了ChatGPT,为笔者解决了很多问题. 问题: 在Python 程序执行过程与字节码中,我们研究了Python程序的编译过程:通过Python解释器中的编译器对 Python 源码进行编译,最终获
-
深入理解Python虚拟机中字典(dict)的实现原理及源码剖析
目录 字典数据结构分析 创建新字典对象 哈希表扩容机制 字典插入数据 总结 字典数据结构分析 /* The ma_values pointer is NULL for a combined table * or points to an array of PyObject* for a split table */ typedef struct { PyObject_HEAD Py_ssize_t ma_used; PyDictKeysObject *ma_keys; PyObject **ma
-
深入理解Python虚拟机中元组(tuple)的实现原理及源码
目录 元组的结构 元组操作函数源码剖析 创建元组 查看元组的长度 元组当中是否包含数据 获取和设置元组中的数据 释放元组内存空间 总结 元组的结构 在这一小节当中主要介绍在 python 当中元组的数据结构: typedef struct { PyObject_VAR_HEAD PyObject *ob_item[1]; /* ob_item contains space for 'ob_size' elements. * Items must normally not be NULL, exc
-
Python 虚拟机集合set实现原理及源码解析
目录 深入理解 Python 虚拟机:集合(set)的实现原理及源码剖析 数据结构介绍 创建集合对象 往集合当中加入数据 哈希表数组扩容 从集合当中删除元素 pop 总结 深入理解 Python 虚拟机:集合(set)的实现原理及源码剖析 在本篇文章当中主要给大家介绍在 cpython 虚拟机当中的集合 set 的实现原理(哈希表)以及对应的源代码分析. 数据结构介绍 typedef struct { PyObject_HEAD Py_ssize_t fill; /* Number active
-
深入理解Python虚拟机中整型(int)的实现原理及源码剖析
目录 数据结构 深入分析 PyLongObject 字段的语意 小整数池 整数的加法实现 总结 数据结构 在 cpython 内部的 int 类型的实现数据结构如下所示: typedef struct _longobject PyLongObject; struct _longobject { PyObject_VAR_HEAD digit ob_digit[1]; }; #define PyObject_VAR_HEAD PyVarObject ob_base; typedef struct
-
浅析Python 中整型对象存储的位置
在 Python 整型对象所存储的位置是不同的, 有一些是一直存储在某个存储里面, 而其它的, 则在使用时开辟出空间. 说这句话的理由, 可以看看如下代码: a = 5 b = 5 a is b # True a = 500 b = 500 a is b # False 由上面的代码可知, 整型 5 是一直存在的, 而整型 500 不是一直存在的. 那么有哪些整数是一直存储的呢? a, b, c = 0, 0, 0 while a is b: i += 1 a, b = int(str(i)),
-
C#中把字符串String转换为整型Int的小例子
本文介绍如何在使用C#开发程序时,将一个字符串String变量的值转换为一个整型Int变量. 比如,我们在C#中定义一个字符串变量,用它来获取一个xml中的值.小编这里并不是故意要用一个字符串去获取xml节点的值,而是使用InnerText的方式获取的值必须是字符串String类型的. 复制代码 代码如下: string tmpValue = ""; tmpValue = xml.DocumentElement["expirydays"].InnerText.Tri
-

Java如何将字符串String转换为整型Int
目录 用法 注意点 性能比较 用法 在java中经常会遇到需要对数据进行类型转换的场景,String类型的数据转为Int类型属于比较常见的场景,主要有两种转换方法: 1. 使用Integer.parseInt(String)方法 2. 使用Integer.valueOf(String)方法 具体demo如下: public void convert() { // 1.使用Integer.parseInt(String) String str1 = "31"; Integer num1
-
python源码剖析之PyObject详解
一.Python中的对象 Python中一切皆是对象. ----Guido van Rossum(1989) 这句话只要你学过python,你就很有可能在你的Python学习之旅的前30分钟就已经见过了,但是这句话具体是什么意思呢? 一句话来说,就是面向对象中的"类"和"对象"在Python中都是对象.类似于int对象的类型对象,实现了"类的概念",对类型对象"实例化"得到的实例对象实现了"对象"这个概念.
-
java中string.trim()函数的作用实例及源码
trim()的作用:去掉字符串首尾的空格. public static void main(String arg[]){ String a=" hello world "; String b="hello world"; System.out.println(b.equals(a)); a=a.trim(); //去掉字符串首尾的空格 System.out.println(a.equals(b)); } 执行结果: a: hello world ,false a:h
-
使用Python给头像加上圣诞帽或圣诞老人小图标附源码
随着圣诞的到来,想给给自己的头像加上一顶圣诞帽.如果不是头像,就加一个圣诞老人陪伴. 用Python给头像加上圣诞帽,看了下大概也都是来自2017年大神的文章:https://zhuanlan.zhihu.com/p/32283641 主要流程 素材准备 人脸检测与人脸关键点检测 调整大小,添加帽子 用dlib的正脸检测器进行人脸检测,用dlib提供的模型提取人脸的五个关键点 调整帽子大小,带帽 选取两个眼角的点,求中心作为放置帽子的x方向的参考坐标,y方向的坐标用人脸框上线的y坐标表示.然后我
-
深入理解框架背后的原理及源码分析
目录 问题1 问题2 总结 近期团队中同学遇到几个问题,想在这儿跟大家分享一波,虽说不是很有难度,但是背后也折射出一些问题,值得思考. 开始之前先简单介绍一下我所在团队的技术栈,基于这个背景再展开后面将提到的几个问题,将会有更深刻的体会. 控制层基于SpringMvc,数据持久层基于JdbcTemplate自己封装了一套类MyBatis的Dao框架,视图层基于Velocity模板技术,其余组件基于SpringCloud全家桶. 问题1 某应用发布以后开始报数据库连接池不够用异常,日志如下: co
-
Python编写一个验证码图片数据标注GUI程序附源码
做验证码图片的识别,不论是使用传统的ORC技术,还是使用统计机器学习或者是使用深度学习神经网络,都少不了从网络上采集大量相关的验证码图片做数据集样本来进行训练. 采集验证码图片,可以直接使用Python进行批量下载,下载完之后,就需要对下载下来的验证码图片进行标注.一般情况下,一个验证码图片的文件名就是图片中验证码的实际字符串. 在不借助工具的情况下,我们对验证码图片进行上述标注的流程是: 1.打开图片所在的文件夹: 2.选择一个图片: 3.鼠标右键重命名: 4.输入正确的字符串: 5.保存 州