pytorch中.numpy()、.item()、.cpu()、.detach()以及.data的使用方法
目录
- .numpy()
- .item()
- .cpu()
- .detach()和.data(重点)
- 补充:关于.data和.cpu().data的各种操作
- 总结
.numpy()
Tensor.numpy()将Tensor转化为ndarray,这里的Tensor可以是标量或者向量(与item()不同)转换前后的dtype不会改变
a = torch.tensor([[1.,2.]]) a_numpy = a.numpy() #[[1., 2.]]
.item()
将一个Tensor变量转换为python标量(int float等)常用于用于深度学习训练时,将loss值转换为标量并加,以及进行分类任务,计算准确值值时需要
optimizer.zero_grad()
outputs = model(data)
loss = F.cross_entropy(outputs, label)
#计算这一个batch的准确率
acc = (outputs.argmax(dim=1) == label).sum().cpu().item() / len(labels) #这里也用到了.item()
loss.backward()
optimizer.step()
train_loss += loss.item() #这里用到了.item()
train_acc += acc
.cpu()
将数据的处理设备从其他设备(如.cuda()拿到cpu上),不会改变变量类型,转换后仍然是Tensor变量。
.detach()和.data(重点)
.detach()就是返回一个新的tensor,并且这个tensor是从当前的计算图中分离出来的。但是返回的tensor和原来的tensor是共享内存空间的。
举个例子来说明一下detach有什么用。 如果A网络的输出被喂给B网络作为输入, 如果我们希望在梯度反传的时候只更新B中参数的值,而不更新A中的参数值,这时候就可以使用detach()
a = A(input) a = a.deatch() # 或者a.detach_()进行in_place操作 out = B(a) loss = criterion(out, labels) loss.backward()
Tensor.data和Tensor.detach()一样, 都会返回一个新的Tensor, 这个Tensor和原来的Tensor共享内存空间,一个改变,另一个也会随着改变,且都会设置新的Tensor的requires_grad属性为False。这两个方法只取出原来Tensor的tensor数据, 丢弃了grad、grad_fn等额外的信息。
tensor.data是不安全的, 因为 x.data 不能被 autograd 追踪求微分
这是为什么呢?我们对.data进行进一步探究
import torch
a = torch.tensor([4., 5., 6.], requires_grad=True)
print("a", a)
out = a.sigmoid()
print("out", out)
print(out.requires_grad) #在进行.data前仍为true
result = out.data #共享变量,同时将requires_grad设置为false
result.zero_() # 改变c的值,原来的out也会改变
print("result", result)
print("out", out)
out.sum().backward() # 对原来的out求导,
print(a.grad) # 不会报错,但是结果却并不正确
'''运行结果为:
a tensor([4., 5., 6.], requires_grad=True)
out tensor([0.9820, 0.9933, 0.9975], grad_fn=<SigmoidBackward0>)
True
result tensor([0., 0., 0.])
out tensor([0., 0., 0.], grad_fn=<SigmoidBackward0>)
tensor([0., 0., 0.])
'''
由于更改分离之后的变量值result,导致原来的张量out的值也跟着改变了,但是这种改变对于autograd是没有察觉的,它依然按照求导规则来求导,导致得出完全错误的导数值却浑然不知。
那么我们继续看看.detach()
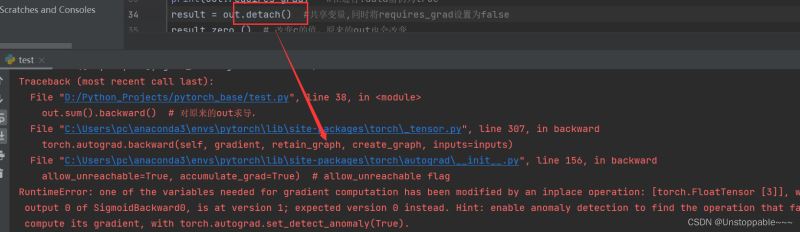
可以看到将.data改为.detach()后程序立马报错,阻止了非法的修改,安全性很高
我们需要记住的就是:
- .data 是一个属性,二.detach()是一个方法;
- .data 是不安全的,.detach()是安全的。
补充:关于.data和.cpu().data的各种操作
先上图

仔细分析:
1.首先a是一个放在GPU上的Variable,a.data是把Variable里的tensor取出来,
可以看出与a的差别是:缺少了第一行(Variable containing)
2.a.cpu()和a.data.cpu()是分别把a和a.data放在cpu上,其他的没区别,另外:a.data.cpu()和a.cpu().data一样
3.a.data[0] | a.cpu().data[0] | a.data.cpu()[0]是一样的,都是把第一个值取出来,类型均为float
4.a.data.cpu().numpy()把tensor转换成numpy的格式
总结
到此这篇关于pytorch中.numpy()、.item()、.cpu()、.detach()以及.data使用的文章就介绍到这了,更多相关pytorch .numpy()、.item()、.cpu()、.detach()及.data内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pytorch .detach() .detach_() 和 .data用于切断反向传播的实现
当我们再训练网络的时候可能希望保持一部分的网络参数不变,只对其中一部分的参数进行调整:或者值训练部分分支网络,并不让其梯度对主网络的梯度造成影响,这时候我们就需要使用detach()函数来切断一些分支的反向传播 1 detach()[source] 返回一个新的Variable,从当前计算图中分离下来的,但是仍指向原变量的存放位置,不同之处只是requires_grad为false,得到的这个Variable永远不需要计算其梯度,不具有grad. 即使之后重新将它的requires_grad
-
PyTorch中 tensor.detach() 和 tensor.data 的区别详解
PyTorch0.4中,.data 仍保留,但建议使用 .detach(), 区别在于 .data 返回和 x 的相同数据 tensor, 但不会加入到x的计算历史里,且require s_grad = False, 这样有些时候是不安全的, 因为 x.data 不能被 autograd 追踪求微分 . .detach() 返回相同数据的 tensor ,且 requires_grad=False ,但能通过 in-place 操作报告给 autograd 在进行反向传播的时候. 举例: ten
-

pytorch中.numpy()、.item()、.cpu()、.detach()以及.data的使用方法
目录 .numpy() .item() .cpu() .detach()和.data(重点) 补充:关于.data和.cpu().data的各种操作 总结 .numpy() Tensor.numpy()将Tensor转化为ndarray,这里的Tensor可以是标量或者向量(与item()不同)转换前后的dtype不会改变 a = torch.tensor([[1.,2.]]) a_numpy = a.numpy() #[[1., 2.]] .item() 将一个Tensor变量转换为pytho
-
pytorch中如何使用DataLoader对数据集进行批处理的方法
最近搞了搞minist手写数据集的神经网络搭建,一个数据集里面很多个数据,不能一次喂入,所以需要分成一小块一小块喂入搭建好的网络. pytorch中有很方便的dataloader函数来方便我们进行批处理,做了简单的例子,过程很简单,就像把大象装进冰箱里一共需要几步? 第一步:打开冰箱门. 我们要创建torch能够识别的数据集类型(pytorch中也有很多现成的数据集类型,以后再说). 首先我们建立两个向量X和Y,一个作为输入的数据,一个作为正确的结果: 随后我们需要把X和Y组成一个完整的数据集,
-
PyTorch中clone()、detach()及相关扩展详解
clone() 与 detach() 对比 Torch 为了提高速度,向量或是矩阵的赋值是指向同一内存的,这不同于 Matlab.如果需要保存旧的tensor即需要开辟新的存储地址而不是引用,可以用 clone() 进行深拷贝, 首先我们来打印出来clone()操作后的数据类型定义变化: (1). 简单打印类型 import torch a = torch.tensor(1.0, requires_grad=True) b = a.clone() c = a.detach() a.data *=
-
PyTorch中torch.utils.data.Dataset的介绍与实战
目录 一.前言 二.torch.utils.data.Dataset 是什么 1. 干什么用的? 2. 长什么样子? 三.通过继承 torch.utils.data.Dataset 定义自己的数据集类 四.为什么要定义自己的数据集类? 五.实战:torch.utils.data.Dataset + Dataloader 实现数据集读取和迭代 实例 1 实例 2:进阶 参考链接 总结 一.前言 训练模型一般都是先处理 数据的输入问题 和 预处理问题 .Pytorch提供了几个有用的工具:torch
-
PyTorch中torch.utils.data.DataLoader简单介绍与使用方法
目录 一.torch.utils.data.DataLoader 简介 二.实例 参考链接 总结 一.torch.utils.data.DataLoader 简介 作用:torch.utils.data.DataLoader 主要是对数据进行 batch 的划分. 数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集. 在训练模型时使用到此函数,用来 把训练数据分成多个小组 ,此函数 每次抛出一组数据 .直至把所有的数据都抛出.就是做一个数据的初始化. 好处: 使用DataLoade
-
pytorch中函数tensor.numpy()的数据类型解析
目录 函数tensor.numpy()的数据类型 tensor数据和numpy数据转换中注意的一个问题 函数tensor.numpy()的数据类型 今天写代码的时候,要统计一下标签数据里出现的类别总数和要分类的分类数是不是一致的. 我的做法是把tensor类型的数据转变成list,然后用Counter函数做统计. 代码如下: from collections import Counter List_counter = Counter(List1) #List1就是待统计的数据,是一维的列表.生成
-
Broadcast广播机制在Pytorch Tensor Numpy中的使用详解
目录 1.什么是广播机制 2.广播机制的规则 3.代码举例 4.原地操作 1.什么是广播机制 根据线性代数的运算规则我们知道,矩阵运算往往都是在两个矩阵维度相同或者相匹配时才能运算.比如加减法需要两个矩阵的维度相同,乘法需要前一个矩阵的列数与后一个矩阵的行数相等.那么在 numpy.tensor 里也是同样的道理,但是在机器学习的某些算法中会出现两个维度不相同也不匹配的矩阵进行运算,那么这时候就需要用广播机制来解决,通过广播机制,其tensor参数可以自动扩展为相等大小(不需要复制数据).下面我
-
详解Pytorch中的tensor数据结构
目录 torch.Tensor Tensor 数据类型 view 和 reshape 的区别 Tensor 与 ndarray 创建 Tensor 传入维度的方法 torch.Tensor torch.Tensor 是一种包含单一数据类型元素的多维矩阵,类似于 numpy 的 array.Tensor 可以使用 torch.tensor() 转换 Python 的 list 或序列数据生成,生成的是dtype 默认是 torch.FloatTensor. 注意 torch.tensor() 总是
-
PyTorch中的拷贝与就地操作详解
前言 PyTroch中我们经常使用到Numpy进行数据的处理,然后再转为Tensor,但是关系到数据的更改时我们要注意方法是否是共享地址,这关系到整个网络的更新.本篇就In-palce操作,拷贝操作中的注意点进行总结. In-place操作 pytorch中原地操作的后缀为_,如.add_()或.scatter_(),就地操作是直接更改给定Tensor的内容而不进行复制的操作,即不会为变量分配新的内存.Python操作类似+=或*=也是就地操作.(我加了我自己~) 为什么in-place操作可以