老生常谈计算机中的编码问题(必看篇)
计算机中的编码问题
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
一、目前常用的编码
ASCII编码:由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
GB系列编码:但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。进而全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。GB系列编码是我国的国标编码,用来存储汉字,分为GB2312,GBK,GB18030,基本都能向前兼容,其中GBK是目前最通用的。
Unicode编码:Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。不过他只规定了字符的编码,却没有规定字符以何种方式存储或者传输。所以UTF系列编码规定了Unicode编码的存储和传输方式。
UTF编码系列:目前最常用的UTF编码分为3种,UTF-8,UTF-16和UTF-32,我们知道计算机是以8位为一个字节来存储数据的,而UTF-16,UTF-32分别用2字节和4字节来表示一个字符,所以这里就涉及到字节的存储顺序,是低位在前还是高位在前,这样,BOM就产生了。
BOM是文本文件开头的一个特殊标记,用一组特殊数字来标记文本文件的字节序。虽然UTF-8字节顺序是固定的,但为了兼容UTF-16和UTF-32也规定了UTF-8的BOM,用于标记UTF-8编码。不过UTF-8的BOM在不同平台的规定不同,要小心使用。
BOM规定如下:
UTF-8 EF BB BF
UTF-16(LE) FF FE
UTF-16(BE) FE FF
UTF-32(LE) FF FE 00 00
UTF-32(BE) 00 00 FE FF
UTF-8编码:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | X | 01001110 00101101 | 11100100 10111000 10101101 |
二、计算机系统中的编码应用
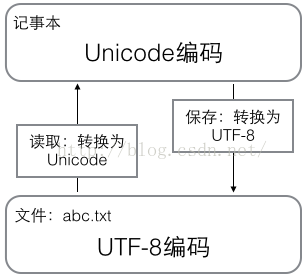
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码;用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
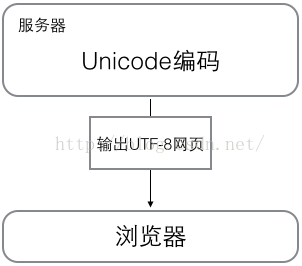
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
三、Java中的编码问题
直接写一个demo来看看eclipse中java项目的编码是怎么样的吧。
1、字符串转为字节序列
public class EncodeDemo {
public static void main(String[] args) {
// TODO Auto-generated method stub
String s="云开de立夏";
byte[] bytes1=s.getBytes();//这是把字符串转换成字符数组,转换成的字节序列用的是项目默认的编码
for(byte b: bytes1)
//toHexString这个函数是把字节(转换成了Int)以16进制的方式显示
System.out.print(Integer.toHexString(b & 0xff)+" ");// & 0xff是为了把前面的24个0去掉只留下后八位
}
}
运行结果:

分析:可以看到这个java项目的默认编码中,汉字用2个字节表示,英文用一个字节表示。
通过查看项目的默认编码为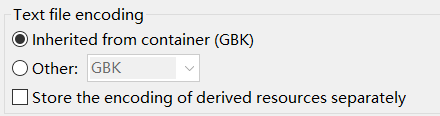 GBK。
GBK。
如果不想用项目默认的编码格式,可以用下面这种方法指定字符串转化为想要的编码格式:
byte[] bytes2=s.getBytes("utf-8");//转换成utf-8编码
for(byte b: bytes2)
//toHexString这个函数是把字节(转换成了Int)以16进制的方式显示
System.out.print(Integer.toHexString(b & 0xff)+" ");// & 0xff是为了把前面的24个0去掉只留下后八位
System.out.println();
byte[] bytes3=s.getBytes("utf-16be");//转换成java双字节编码,utf-16be编码
for(byte b: bytes3)
//toHexString这个函数是把字节(转换成了Int)以16进制的方式显示
System.out.print(Integer.toHexString(b & 0xff)+" ");// & 0xff是为了把前面的24个0去掉只留下后八位
运行结果:

分析:两个结果对比可以得出,
gbk编码: 中文占用两个字节,英文占用一个字节。
utf-8编码:中文占用三个字节,英文占用一个字节。
utf-16be编码:中文占用两个字节,英文占用两个字节。
注意:java是双字节编码,是utf-16be编码。即java中的一个字符(char)占用两个字节!
2、字节序列转为字符串
当你的字节序列是某种编码时,这个时候想把字节序列变成字符串,也需要用这种编码方式,否则会出现乱码。
String str1=new String(bytes1);//这时会使用项目默认的编码来转换,可能出现乱码 System.out.println(str1); String str2=new String(bytes2); System.out.println(str2); String str3=new String(bytes2,"utf-8"); System.out.println(str3);
运行结果:

四、文本文件(txt)的编码问题
文本文件就是字节序列,可以是任意编码的字节序列。
如果我们在中文机器上直接创建文本文件,那么该文件只认识ANSI编码(例如直接在电脑中右键创建文本文件)。
这里要注意:只有直接创建文本文件时,该文件的编码只认识ANSI,但是文本文件本身是可以放任意编码的字节序列。
注意:中文系统下,ANSI编码即是GBK编码。
这里举个例子:
我们在eclipse新建一个项目,把它的默认编码改为utf-8
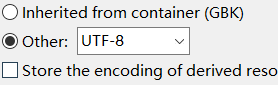
那么对于这个项目而言,它只认识utf-8的编码文件。
接下来,我们在这个项目中新建一个文本文件utf-8.txt,并在里面输入内容如下:


如果直接把这个文本文件拷贝到其他项目中(默认为GBK编码),里面的内容将会变成乱码!因为编码不一样!
但是如果是将里面的内容复制粘贴过去,系统会自动转化为相应的编码,是不会出现乱码的。

注意:如果把这个文本文件拷贝到其他地方(比如系统的桌面)上,它不会出现乱码!!因为文本文件可以是任意的编码序列,系统在读取文本文件时会自动转化为相应的编码格式。
了解文件的编码有什么用呢??在Java的IO流中,我们需要对文件进行读写,使用字节流进行读写的时候,就必须根据不同的编码方式进行读写。因为不同编码方式的各个字符所占用的字节数不同,我们要按照实际情况进行操作。
以上这篇老生常谈计算机中的编码问题(必看篇)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
计算机中的字符串编码、乱码、BOM等问题详解
因为电脑是windows 7系统,开发环境又在linux,经常在linux碰到乱码问题,很是痛苦,于是决定好好了解编码的来龙气脉,并分享个各位,免得出现乱码时不知所措. 是否存在文件编码 在讲解字符编码之前,我们需先明确文件本身没有编码一说,只有文字才有编码的概念,我们通常说某个文件是什么编码,通常是指文件里字符的编码. vim为什么会出现乱码 我在linux下一般使用vim进行文件编辑,发现经常会碰到乱码的情况,那么为什么会出现乱码呢? 首先我们了解下vim编码方面的基础知识,关于编码方面vi
-

Java中的字符编码问题处理心得总结
当面对一串字节流的时候,如果不指定它的编码,其实际意义是无法知道的. 这句话应该也是我们面对"字符转字节,字节转字符"问题时候时刻记在脑子里的.否则乱码问题可能就接踵而至. 其实乱码问题的本质就是Encoding和Decoding用的不是一个编码,明白了这个道理就很好解决乱码问题了. Java中常见的时候有如下: 1. String类使用byte[]的构造函数 String(byte[] bytes),String类同时提供了两个重载 (1)String(byte[] bytes, C
-
微信开发中mysql字符编码问题
问题描述:获取code以后不能用ajax请求微信api数据.这个和ajax跨域访问有关系得到用户信息之后存到mysql,发现中文全部变成了??(乱码) 通过上网查阅了相关资料,判断问题根本原因是字符编码问题. 解决方案: 修改配置文件/etc/mysql/my.conf 在[mysql]下 复制代码 代码如下: default-character-set=utf8 在[mysqld]下 复制代码 代码如下: character-set-server=utf8 重启就失败 复制代码 代码如下: j
-
老生常谈计算机中的编码问题(必看篇)
计算机中的编码问题 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节.比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295. 一.目前常用的编码 ASCII编码:由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小
-
老生常谈PHP 文件写入和读取(必看篇)
文章提纲: 一.实现文件读取和写入的基本思路 二.使用fopen方法打开文件 三.文件读取和文件写入操作 四.使用fclose方法关闭文件 五.文件指针的移动 六.Windows和UNIX下的回车和换行 一.实现文件读取和写入的基本思路: 1.通过fopen方法打开文件:$fp =fopen(/*参数,参数*/),fp为Resource类型 2.进行文件读取或者文件写入操作(这里使用的函数以1中返回的$fp作为参数) 3. 调用fclose($fp)关闭关闭文件 二:使用fopen方法打开文件
-
老生常谈python的私有公有属性(必看篇)
python中,类内方法外的变量叫属性,类内方法内的变量叫字段.他们的私有公有访问方法类似. class C: __name="私有属性" def func(self): print(C.__name) class sub_C(C): def info(self): print(C.__name)#派生类中不可以访问父类的私有字段 obj=C() obj.func() obj=sub_C() obj.info() 方法.属性的访问于上述方式相似,即:私有成员只能在类内部使用 以上这篇老
-
老生常谈PHP面向对象之命令模式(必看篇)
这个模式主要由 命令类.用户请求数据类.业务逻辑类.命令类工厂类及调用类构成,各个类的作用概括如下: 1.命令类:调用用户请求数据类和业务逻辑类: 2.用户请求数据类:获取用户请求数据及保存后台处理后返回的结果: 3.业务逻辑类:如以下的示例中验证用户登陆信息是否正确的功能等: 4.命令工厂类(我自己取的名字,哈哈):生成命令类的实例,这个类第一次看的时候我觉得有点屌,当然看了几遍了还是觉得很屌 :): 5.调用类:调用命令类,生成视图: 直接看代码: //命令类 abstract class
-
老生常谈python函数参数的区别(必看篇)
在运用python的过程中,发现当函数参数为list的时候,在函数内部调用list.append()会改变形参,与C/C++的不太一样,查阅相关资料,在这里记录一下. python中id可以获取对象的内存地址 >>> num1 = 10 >>> num2 = num1 >>> num3 = 10 >>> id(num1) >>> id(num2) >>> id(num3) 可以看到num1.num2
-
老生常谈Java网络编程TCP通信(必看篇)
Socket简介: Socket称为"套接字",描述IP地址和端口.在Internet上的主机一般运行多个服务软件,同时提供几种服务,每种服务都打开一个Socket,并绑定在一个端口上,不同的端口对应于不同的服务.Socket和ServerSocket类位于java.net包中.ServerSocket用于服务端,Socket是建立网络连接时使用的.连接成功时,应用程序两端都会产生一个Socket实例,通过操作这个实例完成所需会话. Socket常用方法: -int getLocalP
-
老生常谈Java虚拟机垃圾回收机制(必看篇)
在Java虚拟机中,对象和数组的内存都是在堆中分配的,垃圾收集器主要回收的内存就是再堆内存中.如果在Java程序运行过程中,动态创建的对象或者数组没有及时得到回收,持续积累,最终堆内存就会被占满,导致OOM. JVM提供了一种垃圾回收机制,简称GC机制.通过GC机制,能够在运行过程中将堆中的垃圾对象不断回收,从而保证程序的正常运行. 垃圾对象的判定 我们都知道,所谓"垃圾"对象,就是指我们在程序的运行过程中不再有用的对象,即不再存活的对象.那么怎么来判断堆中的对象是"垃圾&q
-
老生常谈mysql event事件调度器(必看篇)
概述 MySQL也有自己的事件调度器,简单地可以理解为linux的crontab job,不过对于SQL应用来说,它的功能更齐全,也更易于维护.个人感觉如果数量创建太多的话,也可能影响DB性能,且不易调试. MySQL事件调度器的主要内容 总开关 参数event_scheduler为事件调度器的总开关,一般来说设置为ON或者OFF就好,不建议设置成disabled,如果设置为ON,show processlist可看到该线程 创建,修改,查看等语法 关于如何创建,修改event这里不做叙述,创建
-
老生常谈php中传统验证与thinkphp框架(必看篇)
PHP(超文本预处理器)可用于小型网站的搭建,当用户需要注册登录是,需要与后台数据库进行匹配合格才能注册和登录,传统的方式步骤繁多,需要先连接数据库再用sql语句进行插入. <?php header("Content-type: text/html; charset=utf-8"); $conn =mysqli_connect("localhost","root",""); if (!$conn){ echo "
-
老生常谈Eclipse中的BuildPath(必看篇)
什么是Build Path? Build Path是指定Java工程所包含的资源属性集合. 在一个成熟的Java工程中,不仅仅有自己编写的源代码,还需要引用系统运行库(JRE).第三方的功能扩展库.工作空间中的其他工程,甚至外部的类文件,所有这些资源都是被这个工程所依赖的,并且只有被引用后,才能够将该工程编译成功,而Build Path就是用来配置和管理对这些资源的引用的. Build Path一般包括: JRE运行库 第三方的功能扩展库(*.jar格式文件) 其他的工程 其他的源代码或Clas