如何利用Python将html转为pdf、word文件
目录
- 前言
- 转 pdf
- 安装 pdfkit 库
- 安装 wkhtmltopdf 文件
- url 生成 pdf
- 本地 html 文件生成 pdf
- 转 word
- 安装 pypandoc 库
- 安装 pandoc 软件
- 使用
- 补充:用python把pdf文件转换为word文件
- 总结
前言
在日常中有时需将 html 文件转换为 pdf、word 文件。网上免费的大多数不支持多个文件转换的情况,而且在转换几个后就开始收费了。

转 pdf
转 pdf 中使用 pdfkit 库,它可以让 web 网页直接转为 pdf 文件,多个 url 可以合并成一个文件。
安装 pdfkit 库
pip3 install pdfkit
安装 wkhtmltopdf 文件
pdfkit 是基于 wkhtmltopdf 的 python 封装库,所以需要安装 wkhtmltopdf 软件。

在windows 系统中,需要将 wkhtmltopdf.exe 文件路径配置在系统环境变量中。
url 生成 pdf
这里使用 baidu 首页和 bing 首页作为示例
import pdfkit # 第一个参数可以是列表,放入多个域名,第二个参数是生成的 PDF 名称 pdfkit.from_url(['www.baidu.com','www.bing.com'],'search.pdf')
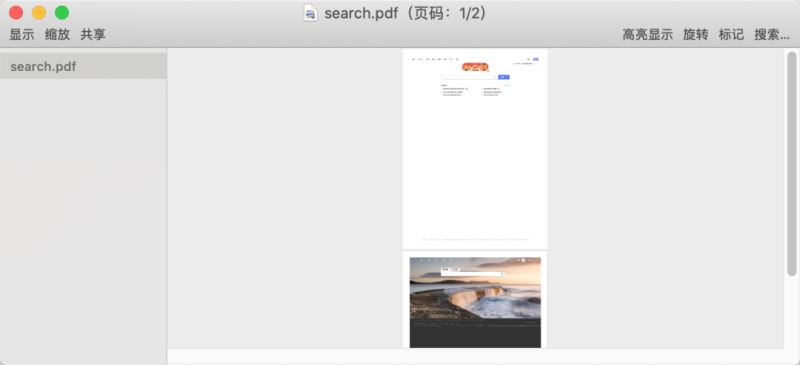
本地 html 文件生成 pdf
提前将需要转换的 html 存储到本地,也可以使用 python 爬虫代码抓取 html 文件到本地。
import pdfkit
pdfkit.from_file('/Users/xx/Desktop/html/baidu.html', 'search.pdf')
转 word
使用 pypandoc 库将 html 转换为 word 文件,pypandoc 是一个支持多种文件格式转换的 Python 库,它用到了 pandoc 软件,所以需要在电脑上安装 pandoc 软件
安装 pypandoc 库
pip install pypandoc
安装 pandoc 软件
pypandoc 是基于 pandoc 软件的库,所以要安装一下 pandoc (https://github.com/jgm/pandoc/releases/tag/2.11.4),pandoc 支持多种类型转换。下图是 pandoc 的转换类型。

使用
将 html 文件提前存储在本地,也可以用爬虫将需要转换的 html 文件在代码中抓取后使用。
import pypandoc
# convert_file('原文件','目标格式','目标文件')
output = pypandoc.convert_file('/Users/xx/Desktop/html/baidu.html', 'docx', outputfile="baidu.doc")
pypandoc 无法对 word 进行排版,所以需要小伙伴们进行 2 次排版。

补充:用python把pdf文件转换为word文件
安装pip install pdf2docx:
pip install pdf2docx
如果安装过程出现报错,可能是版本匹配问题,先安装PyMuPDF这个库即可正常安装pip install PyMuPDF。
pip install PyMuPDF
安装好后,把需要转换的PDF文档放到和python代码同一个文件夹内。
python代码:
import os
from pdf2docx import Converter
def pdf_docx():
# 获取当前工作目录
file_path = os.getcwd()
# 获取所有文件
files = os.listdir(file_path)
# 遍历所有文件
for file in files:
# 过滤临时文件
if '~$' in file:
continue
# 过滤非pdf格式文件
if file.split('.')[-1] != 'pdf':
continue
# 获取文件名称
file_name = file.split('.')[0]
# pdf文件名称
pdf_name = os.getcwd() + '\\' + file
# docx文件名称
docx_name = os.getcwd() + '\\' + file_name + '.docx'
# 加载pdf文档
cv = Converter(pdf_name)
cv.convert(docx_name, start=0, end=12)
cv.close()
if __name__ == '__main__':
pdf_docx()
start是pdf转换的起始页,end是结束页。如果不传入start和end这两个参数,默认就是从第一页转换到最后一页。也可以通过pages方法确定转换页数,方法为:cv.convert(docx_file, pages=[0,2, 5])
总结
利用好 Python 第三方库类,可以为小伙伴写出各种个性化定制的小程序
到此这篇关于如何利用Python将html转为pdf、word文件的文章就介绍到这了,更多相关Python将html转pdf word内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python将html转成PDF的实现代码(包含中文)
前提: 安装xhtml2pdf https://pypi.python.org/pypi/xhtml2pdf/下载字体:微软雅黑:给个地址:http://www.jb51.net/fonts/8481.html 待转换的文件:1.htm 复制代码 代码如下: <meta charset="utf8"/><style type='text/css'>@font-face { font-family: "code2000";
-
Python实现批量将word转html并将html内容发布至网站的方法
本文实例讲述了Python实现批量将word转html并将html内容发布至网站的方法.分享给大家供大家参考.具体实现方法如下: #coding=utf-8 __author__ = 'zhm' from win32com import client as wc import os import time import random import MySQLdb import re def wordsToHtml(dir): #批量把文件夹的word文档转换成html文件 #金山WPS调用,抢先
-
Python实现html转换为pdf报告(生成pdf报告)功能示例
本文实例讲述了Python实现html转换为pdf报告(生成pdf报告)功能.分享给大家供大家参考,具体如下: 1.先说下html转换为pdf:其实支持直接生成,有三个函数pdfkit.f 安装python包:pip Install pdfkit 系统安装wkhtmltopdf:参考 https://github.com/JazzCore/python-pdfkit/wiki/Installing-wkhtmltopdf mac下的wkhtmltopdf: brew install Caskro
-
Python实现抓取HTML网页并以PDF文件形式保存的方法
本文实例讲述了Python实现抓取HTML网页并以PDF文件形式保存的方法.分享给大家供大家参考,具体如下: 一.前言 今天介绍将HTML网页抓取下来,然后以PDF保存,废话不多说直接进入教程. 今天的例子以廖雪峰老师的Python教程网站为例:http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000 二.准备工作 1. PyPDF2的安装使用(用来合并PDF): PyPDF2版本:1.2
-
python包pdfkit(wkhtmltopdf) 将HTML转换为PDF的操作方法
目录 python包-pdfkit 将HTML转换为PDF 什么是pdfkit 安装 使用 将url生成pdf文件 字符串生成pdf[pdfkit.from_string()函数] 报错OSError: No wkhtmltopdf executable found 报错 python包-pdfkit 将HTML转换为PDF 什么是pdfkit pdfkit,把HTML+CSS格式的文件转换成PDF格式文档的一种工具.它就是html转成pdf工具包wkhtmltopdf的Python封装.所以,
-
python如何实现word批量转HTML
今天我们说一下使用python将word内容转换成html文件.下面一起来看一下. 准备工作 使用python类库PyDocX,安装方法(使用pip进行安装),命令如下: pip install python-docx 类库介绍 python-docx是用于创建和更新Microsoft Word(.docx)文件的Python库.它可以针对word做很多操作.比如打开文件.写入内容.编写内容样式.解析内容.读取内容等等.主要就是针对word做的一款功能库. 说代码 下面一起来说一下代码.首先是做
-

python 将html转换为pdf的几种方法
将 HTML 网页转换为 PDF 是很多人常见的一个需求,在浏览器上,我们可以通过浏览器的"打印"功能直接将网页打印输出为 PDF. 但是如果有多个网页就不好办了. 二进制软件 网络上存在很多将 HTML 转换为 PDF 的软件和工具.比较著名的有 Carelib.wkhtmltopdf. whtmltopdf wkhtmltopdf 真是一个优秀的 HTML 转换 PDF 工具.其借助 Qt 的 WebKit 渲染引擎,将 HTML 文档渲染导出为 PDF 文档或图像. 功能十分完善
-
Python3转换html到pdf的不同解决方案
问题:python3 如何转换html到pdf 描述: 我的电脑是windows764位,python3.4 我想用python 转换html到pdf. 我尝试了html2pdf,貌似它只支持Python2 我又尝试了wkhtmltox-0.12.2.2_msvc2013-win64和pdfkit,并用下面的例子测试. import pdfkit pdfkit.from_url('http://google.com', 'out.pdf') 报错信息 Traceback (most recent
-
Python实现将HTML转成PDF的方法分析
本文实例讲述了Python实现将HTML转成PDF的方法.分享给大家供大家参考,具体如下: 主要使用的是wkhtmltopdf的Python封装--pdfkit 安装 1. Install python-pdfkit: $ pip install pdfkit 2. Install wkhtmltopdf: Debian/Ubuntu: $ sudo apt-get install wkhtmltopdf Redhat/CentOS sudo yum intsall wkhtmltopdf Ma
-
如何利用Python将html转为pdf、word文件
目录 前言 转 pdf 安装 pdfkit 库 安装 wkhtmltopdf 文件 url 生成 pdf 本地 html 文件生成 pdf 转 word 安装 pypandoc 库 安装 pandoc 软件 使用 补充:用python把pdf文件转换为word文件 总结 前言 在日常中有时需将 html 文件转换为 pdf.word 文件.网上免费的大多数不支持多个文件转换的情况,而且在转换几个后就开始收费了. 转 pdf 转 pdf 中使用 pdfkit 库,它可以让 web 网页直接转为 p
-
利用Python将彩色图像转为灰度图像的两种方法
目录 第一种方法 第二种方法 python 批量将图片转为灰度图 总结 第一种方法 Python的cv2库中自带彩色转灰度的方法,而且非常简单,代码就9行,核心代码就1行. 大题思路就是先读取一张彩色图片,然后在窗口中显示出来,再然后就让cv2处理一下,转换成灰度图像,这时候它是个二维的灰度矩阵,所以,我们想保存得先将它从array转成image,最后在另一个窗口中显示出来,为了避免窗口一闪而过,我们需要加上waitKey(0)这一句. import cv2 from PIL import Im
-
如何利用Python将字典转为成员变量
目录 技术背景 使用__dict__定义成员变量 嵌套字典转成员变量 总结概要 参考链接 技术背景 当我们在Python中写一个class时,如果有一部分的成员变量需要用一个字典来命名和赋值,此时应该如何操作呢?这个场景最常见于从一个文件(比如json.npz之类的文件)中读取字典变量到内存当中,再赋值给一个类的成员变量,或者已经生成的实例变量. 使用__dict__定义成员变量 在python中直接支持了__dict__.update()这样的方法来操作,避免了对locals().vars()
-
利用Python实现快速批量转换HEIC文件
目录 1. 前言 2. 准备 3. 实战 4.最后 1. 前言 最近打算做一批日历给亲朋好友,但是从 iPhone 上导出的照片格式是 HEIC 格式,而商家的在线制作网站不支持这种图片格式 PS:HEIC 是苹果采用的新的默认图片格式,它能在不损失图片画质的情况下,减少图片大小 有很多在线网站支持图片批量转换,但是安全隐私又没法得到保证:如果使用 PS 等软件去一张张转换,浪费时间的同时效率太低 本篇文章将使用 Python 批量实现 HEIC 图片文件的格式转换 2. 准备 首先,我们安装
-
利用python库在局域网内传输文件的方法
1.电脑已经搭建python环境 2.深入到需要传输的文件目录下,此处以分享 nemo-huiyuanfei 文件为例 3.在路径栏输入 cmd 按回车进入终端 4.输入命令 python -m SimpleHTTPServer 8090 按回车 (端口号可以任意,不用必须为8090) 5.在局域网中任意浏览器输入框输入 文件所在主机 IP + Port 即可访问此文件目录并下载 () 6.点击需要下载的文件即可下载 7. [注意]python3.X 的命令输入为 python -m http.
-
如何利用python实现windows的批处理及文件夹操作
目录 1.批量处理 2. 文件夹操作 2.1 读取文件中的文件名 2.2 创建文件夹 2.3.获取某指定目录下的所有文件的列表 2.4.将一个路径名分解为目录名和文件名两部分 总结 1.批量处理 所谓的批处理就是批量处理cmd里面的命令. python要想实现批处理功能需要导入os库,然后利用批处理的命令为os.system(cmd_line)其中cmd_line是输入cmd里面的命令. import os # 批量处理的exe文件 EXE_PATH="C:\\Users\\AAA\\Deskt
-
利用Python实现字幕挂载(把字幕文件与视频合并)思路详解
其实超简单超简单!python好现成的库,一下子省略了好多步骤! 本文在Windows环境下!linux只是不需要手动输入imagicmagick的位置! 需要用到的环境 python(基本上只要不是很老的就行) pip(这个其实python版本>2.8.9或者>3.4的都自带了),可以通过cmd命令pip -V查询是否安装了,没有的话就输入命令 需要用到的工具: 我用的是pycharm,用来写python代码的. Flie->setting->Project:Test->p
-
利用python将图片版PDF转文字版PDF
图片版PDF无法复制,转化成文字版的PDF后使用更方便. 我们需要用到python3.6,pypdf2,ghostscript,PythonMagick,百度文字识别服务和pdfkit. 安装 安装python3.6 略 安装ghostscript https://ghostscript.com/download/gsdnld.html 安装wkhtmltopdf https://wkhtmltopdf.org/downloads.html pip安装PyPDF2,ghostscript,bai
-
Python解析并读取PDF文件内容的方法
本文实例讲述了Python解析并读取PDF文件内容的方法.分享给大家供大家参考,具体如下: 一.问题描述 利用python,去读取pdf文本内容. 二.效果 三.运行环境 python2.7 四.需要安装的库 pip install pdfminer 五.实现源代码 代码1(win64) # coding=utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time time1=time.time() impor
-
利用Python实现字幕挂载的思路详解
其实超简单超简单!python好现成的库,一下子省略了好多步骤! 本文在Windows环境下!linux只是不需要手动输入imagicmagick的位置! 需要用到的环境 python(基本上只要不是很老的就行) pip(这个其实python版本>2.8.9或者>3.4的都自带了),可以通过cmd命令pip -V查询是否安装了,没有的话就输入命令 需要用到的工具: 我用的是pycharm,用来写python代码的. Flie->setting->Project:Test->p