Gradio机器学习模型快速部署工具quickstart前篇
目录
- Gradio 是做什么的?
- Hello, World
- 类Interface
- 组件属性
- 多个输入和输出组件
Gradio 是做什么的?
先决条件:Gradio 需要 Python 3.7 或更高版本,仅此而已!
与他人分享您的机器学习模型、API 或数据科学工作流程的最佳方式_之一是创建一个交互式应用程序,让您的用户或同事可以在他们的浏览器中试用该演示。
Gradio 允许您**构建演示并共享它们,所有这些都在 Python 中。**通常只需几行代码!让我们开始吧。
Hello, World
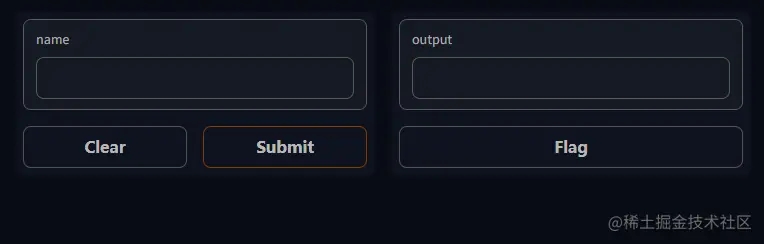
要使用简单的“Hello, World”示例运行 Gradio,请执行以下三个步骤:
1.使用pip安装Gradio:
pip install gradio
2. 将以下代码作为 Python 脚本或在 Jupyter Notebook中运行:
import gradio as gr
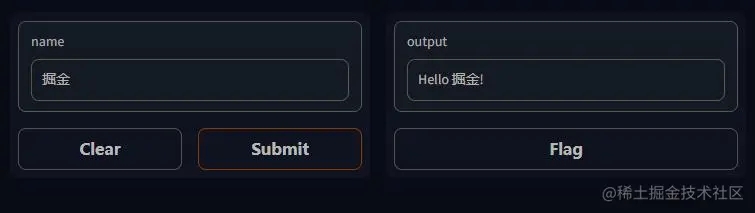
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch()
3. 下面的演示将自动出现在 Jupyter Notebook 中,或者如果从脚本运行则在浏览器中弹出 http://localhost:7860
在本地开发时,如果您想将代码作为 Python 脚本运行,您可以使用 Gradio CLI 以重新加载模式启动应用程序,这将提供无缝和快速的开发。在自动重新加载指南中了解有关重新加载的更多信息。
gradio app.py
注意:你也可以这样做python app.py,但它不会提供自动重新加载机制。
类Interface
https://gradio.app/quickstart/#the-interface-class
您会注意到,为了制作演示,我们创建了一个gradio.Interface. 此类Interface可以使用用户界面包装任何 Python 函数。在上面的示例中,我们看到了一个简单的基于文本的函数,但该函数可以是任何东西,从音乐生成器到税收计算器再到预训练机器学习模型的预测函数。
核心Interface类使用三个必需参数进行初始化:
fn: 环绕 UI 的函数inputs: 哪个组件用于输入(例如"text","image"或"audio")outputs: 用于输出的组件(例如"text","image"或"label")
让我们仔细看看这些用于提供输入和输出的组件。
组件属性
我们Textbox在前面的示例中看到了一些简单的组件,但是如果您想更改 UI 组件的外观或行为方式怎么办?
假设您想要自定义输入文本字段——例如,您希望它更大并且有一个文本占位符。如果我们使用实际的类Textbox而不是使用字符串快捷方式,您可以通过组件属性访问更多的可定制性。
import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(
fn=greet,
# 改变外观
inputs=gr.Textbox(lines=2, placeholder="Name Here..."),
outputs="text",
)
demo.launch()
多个输入和输出组件
假设您有一个更复杂的函数,具有多个输入和输出。在下面的示例中,我们定义了一个函数,它接受一个字符串、布尔值和数字,并返回一个字符串和数字。看一下如何传递输入和输出组件列表。
import gradio as gr
def greet(name, is_morning, temperature):
salutation = "Good morning" if is_morning else "Good evening"
greeting = f"{salutation} {name}. It is {temperature} degrees today"
celsius = (temperature - 32) * 5 / 9
return greeting, round(celsius, 2)
demo = gr.Interface(
fn=greet,
inputs=["text", "checkbox", gr.Slider(0, 100)],
outputs=["text", "number"],
)
demo.launch()

参考网址: gradio.app/quickstart/
以上就是Gradio机器学习模型快速部署工具quickstart前篇的详细内容,更多关于Gradio机部署quickstart的资料请关注我们其它相关文章!
相关推荐
-
对网站内嵌gradio应用的输入输出做审核实现详解
目录 前言 1 | 方案 1.1 | 基于 nginx 流量劫持和转发 1.2 | 基于 gradio sdk 的二次开发 1.3 | 比较 2 | 实施 2.1 | 创建ingress,来劫持发往 /run/predict 的请求 2.2 | 审核服务的接收和处理 3 | 效果展示 前言 在AI领域,来快速实现一个idea:前后端开发+部署+展现,如果走传统的前后端分离开发+服务器docker部署等方式,会很重且入门成本很高. 所以,行业内诞生出来了 gradio :基于python的前端+后
-
通过gradio和摄像头获取照片和视频实现过程
目录 1.环境设置 1.1gradio安装 2.ffmpeg安装 2.简单小程序 2.1 引入gradio 2.2 定义方法 2.3 定义接口 2.4 运行 3.执行情况 3.1 终端日志输出 3.2 截图 3.3 保存 1.环境设置 1.1gradio安装 需要安装 gradio,安装办法就是 pip install gradio 2.ffmpeg安装 再次需要加入到path路径. 下载地址: https://www.jb51.net/softjc/760881.html ffmpeg.exe
-
Gradio机器学习模型快速部署工具quickstart
目录 引言 1.图像示例 2.块:更多的灵活性和控制 3.更复杂的 Blocks 引言 书接上回 Gradio机器学习模型快速部署工具[quickstart]翻译,讲到多输入输出,其实很简单,就是把多个组件包装到列表,inputs和outputs对应的就是2个列表,输入输出列表,仅此而已. 1.图像示例 Gradio 支持多种类型的组件,例如Image, DataFrame, Video, 或Label. 让我们尝试一个图像到图像的功能来感受一下这些! import numpy as np im
-

Gradio机器学习模型快速部署工具应用分享
目录 1.嵌入 IFrame 2.API页面 3.验证 4.直接访问网络请求 5.在另一个 FastAPI 应用程序中安装[![图片转存失败,建议将图片保存下来直接上传 6.安全和文件访问 1.嵌入 IFrame (/assets/img/anchor.svg)]()](https://gradio.app/sharing-your-app/#embedding-with-iframes) 要改为嵌入 IFrame(例如,如果您无法将 javascript 添加到您的网站),请添加此元素: <i
-
使用ruby部署工具mina快速部署nodejs应用教程
前面有一篇文章讲到过用git的hook部署应用,hook的方法有一个缺陷就是每次都要到服务器去修改一下hook对应的配置文件,这个配置文件是与当前仓库分离的,调试上会有一些麻烦,借助ruby的一个部署工具mina可以快速的在服务器部署nodejs应用. 安装mina 复制代码 代码如下: gem install mina 安装之后,它需要一个配置文件,默认情况下是当前目录的config/deploy.rb 简单的配置 复制代码 代码如下: require 'mina/git' require '
-
python人工智能human learn绘图可创建机器学习模型
目录 什么是 human-learn 安装 human-learn 互动绘图 创建模型并进行预测 预测新数据 解释结果 预测和评估测试数据 结论 如今,数据科学家经常给带有标签的机器学习模型数据,以便它可以找出规则. 这些规则可用于预测新数据的标签. 这很方便,但是在此过程中可能会丢失一些信息.也很难知道引擎盖下发生了什么,以及为什么机器学习模型会产生特定的预测. 除了让机器学习模型弄清楚所有内容之外,还有没有一种方法可以利用我们的领域知识来设置数据标记的规则? 是的,这可以通过 human-l
-
python人工智能human learn绘图创建机器学习模型
目录 什么是 human-learn 安装 human-learn 互动绘图 创建模型并进行预测 预测新数据 解释结果 预测和评估测试数据 结论 如今,数据科学家经常给带有标签的机器学习模型数据,以便它可以找出规则. 这些规则可用于预测新数据的标签. 这很方便,但是在此过程中可能会丢失一些信息.也很难知道引擎盖下发生了什么,以及为什么机器学习模型会产生特定的预测. 除了让机器学习模型弄清楚所有内容之外,还有没有一种方法可以利用我们的领域知识来设置数据标记的规则? 是的,这可以通过 human-l
-
在Docker快速部署Node.js应用的详细步骤
一.前言 可能还有一些同学不了解docker这个项目,docker是由go语言编写的,一个快速部署的轻量级虚拟技术项目,他允许开发人员将自己的程序和运行环境一起打包,制作成一个docker的image(镜像),这样部署到服务器上,也只需要下载这个image就可以将程序跑起来,免去每次都安装各种依赖和环境的麻烦,还能够做到应用程序之间的隔离 二.实现准备 我会先创建一个简单的Node.js web app,来构建一个镜像.然后基于这个Image运行一个container.从而实现快速部署. 由于网
-
用Docker swarm快速部署Nebula Graph集群的教程
一.前言 本文介绍如何使用 Docker Swarm 来部署 Nebula Graph 集群. 二.nebula集群搭建 2.1 环境准备 机器准备 ip 内存(Gb) cpu(核数) 192.168.1.166 16 4 192.168.1.167 16 4 192.168.1.168 16 4 在安装前确保所有机器已安装docker 2.2 初始化swarm集群 在192.168.1.166机器上执行 $ docker swarm init --advertise-addr 192.168.
-
SpringBoot应用快速部署到K8S的详细教程
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容: 所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS等: 背景 对于生产环境,我们一般会用CI&&CD工具完成整个构建和部署,因此本文不适合生产环境:对于学习和开发环境,我们频繁修改代码,又想快速见到效果,本文就是针对这种场景的: 内容简介 如果您正在开发SpringBoot应用,并且应用部署在K8S环境,可以参考本文将应用快速部署到K8S环
-
idea整合docker快速部署springboot应用的详细过程
目录 一.前言 二.环境及工具 三.安装docker以及配置远程连接 四.idea连接远程docker 一.前言 容器化一词相信大家已经不陌生了,听到它我们可能会想到docker.k8s.jenkins.rancher等等.那么今天我来说一下idea如何使用docker快速部署springboot应用. 二.环境及工具 windows10(开发) centos 7.6 (部署) idea docker xshell 三.安装docker以及配置远程连接 安装docker步骤网上有很多,在这里还是
-
python数据挖掘使用Evidently创建机器学习模型仪表板
目录 1.安装包 2.导入所需的库 3.加载数据集 4.创建模型 5.创建仪表板 6.可用报告类型 1)数据漂移 2)数值目标漂移 3)分类目标漂移 4)回归模型性能 5)分类模型性能 6)概率分类模型性能 解释机器学习模型是一个困难的过程,因为通常大多数模型都是一个黑匣子,我们不知道模型内部发生了什么.创建不同类型的可视化有助于理解模型是如何执行的,但是很少有库可以用来解释模型是如何工作的. Evidently 是一个开源 Python 库,用于创建交互式可视化报告.仪表板和 JSON 配置文
-
Docker Compose快速部署多容器服务实战的实例详解
目录 1 什么是Docker Compose 2 安装Docker Compose 3 Docker Compose文件格式的简单介绍 4 Docker Compose常用命令 5 使用Docker Compose一键部署Spring Boot+Redis实战 5.1 构建应用 5.1.1 Spring Boot项目 5.1.2 Redis配置文件 5.2 打包应用并构建目录 5.2.1 打包Spring Boot项目 5.2.2 上传redis.conf配置文件 5.3 编写Dockerfil
-
快速部署 Scrapy项目scrapyd的详细流程
快速部署 Scrapy项目 scrapyd 给服务端 install scrapyd pip install scrapyd -i https://pypi.tuna.tsinghua.edu.cn/simple 运行 scrapyd 修改配置项 , 以便远程访问 使用Ctrl +c 停止 上一步的运行的scrapyd 在要运行scrapyd 命令的路径下,新建文件scrapyd.cnf 文件 输入以下内容 [scrapyd] # 网页和Json服务监听的IP地址,默认为127.0.0.1(只