nodejs个人博客开发第六步 数据分页
本文为大家分享了nodejs个人博客开发的数据分页,具体内容如下
控制器路由定义
首页路由:http://localhost:8888/
首页分页路由:http://localhost:8888/index/2
/**
* 首页控制器
*/
var router=express.Router();
/*每页条数*/
var pageSize=4;
/*首页*/
router.get('/',function(req,res,next){
var cid=0;
F.model("article").assignIndexData(cid,1,pageSize,res);
});
/*首页分页*/
router.get('/index/:page',function(req,res,next){
var currentPage=parseInt(req.params.page);
var cid=0;
F.model("article").assignIndexData(cid,currentPage,pageSize,res);
});
分类列表分页路由:http://localhost:8888/category/分类id/分页
/*分类页*/
router.get('/category/:cid/:page',function(req,res,next){
var cid=req.params.cid;
var currentPage=parseInt(req.params.page);
F.model("article").assignIndexData(cid,currentPage,pageSize,res);
});
模型数据部分
控制器调用article模型的assignIndexData()方法,参数:分类id,当前页,每页条数,响应对象
调用category模型的getAllList()方法得到分类list,参数:回调函数
调用article模型的getCount()方法得到总条数,参数:分类id,回调函数
调用article模型的getArticlePager()方法得到文章对象的数据list,参数:分类id,当前页,每页条数,回调函数
对上一页,下一页进行-1和+1,并进行判断,上一页应大于0,下一页应小于等于总页数(总条数/每页条数 向上取整)
把数据分配到模板上
/**
* 文章模型文件
*/
module.exports={
/*获取条数*/
getCount:function(categoryId,callback){
var condition="";
if(categoryId!=0){
condition="where category_id="+categoryId;
}
var sql="select count(*) num from article "+condition;
db.query(sql,callback);
},
/*获取分页数据*/
getArticlePager:function(categoryId,currentPage,pageSize,callback){
if(currentPage<=0||!currentPage) currentPage=1;
var start=(currentPage-1)*pageSize;
var end=pageSize;
var condition="";
if(categoryId!=0){
condition="where category_id="+categoryId;
}
var sql="select * from article "+condition+" order by time desc limit "+start+","+end;
db.query(sql,callback);
},
/*归档*/
getArchives:function(callback){
db.query("select time from article order by time desc",callback);
},
/*分配首页数据*/
assignIndexData:function(cid,currentPage,pageSize,res){
var categoryModel=F.model("category");
var articleModel=this;
// 分类数据
categoryModel.getAllList(function(err,categoryList){
// 文章条数
articleModel.getCount(cid,function(err,nums){
// 文章分页
articleModel.getArticlePager(cid,currentPage,pageSize,function(err,articleList){
var nextPage=(currentPage+1)>=Math.ceil(nums[0].num/pageSize) ? Math.ceil(nums[0].num/pageSize) : currentPage+1;
var prePage=(currentPage-1)<=0 ? 1 : currentPage-1;
// 归档
articleModel.getArchives(function(err,allArticleTime){
var newArticleTime=[];
for(var i=0;i<allArticleTime.length;i++){
newArticleTime.push(F.phpDate("y年m月",allArticleTime[i].time));
}
/*分配数据*/
var data={
categoryList:categoryList,
articleList:articleList,
cid:cid,
nextPage:nextPage==0 ? 1 : nextPage,
prePage:prePage,
allArticleTime:newArticleTime,
currentPage:currentPage
};
/*渲染模板*/
res.render("home/index",data);
});
});
});
});
}
};
模板部分
<nav>
<ul class="pager">
<li><a class="btn <%if(currentPage==prePage){%>disabled<%}%>"
href="/<%if(cid!=0){%>category/<%=cid%>/<%}else{%>index/<%}%><%=prePage%>" rel="external nofollow" >上一页</a></li>
<li><a class="btn <%if(currentPage==nextPage){%>disabled<%}%>"
href="/<%if(cid!=0){%>category/<%=cid%>/<%}else{%>index/<%}%><%=nextPage%>" rel="external nofollow" >下一页</a></li>
</ul>
</nav>
效果图:
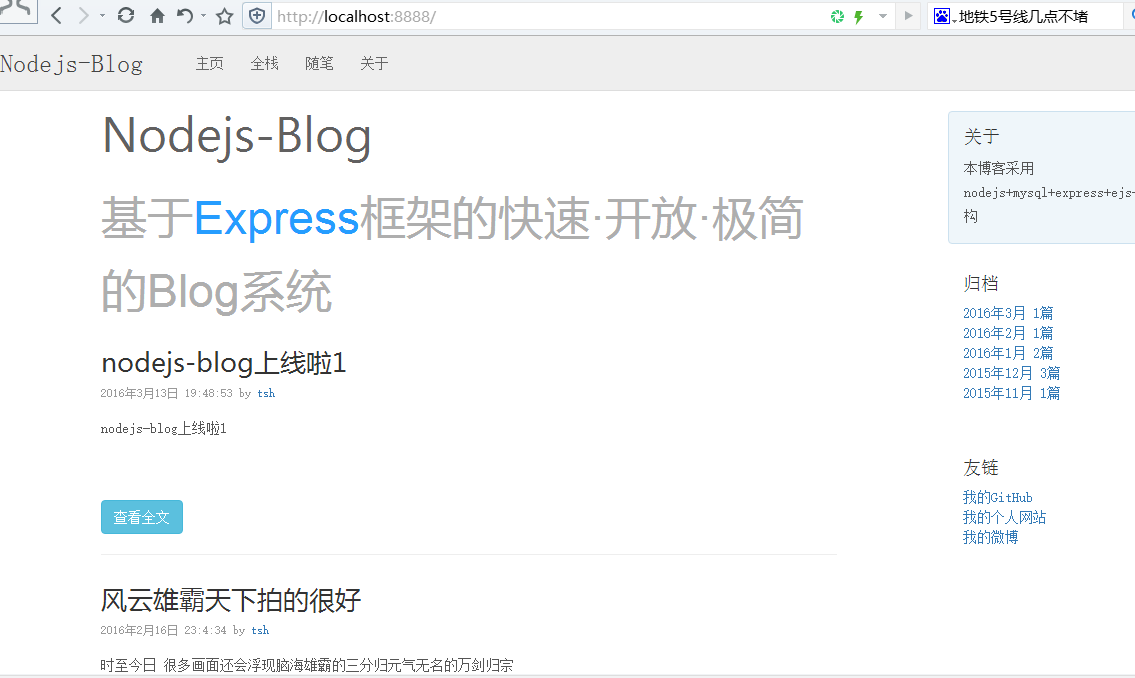
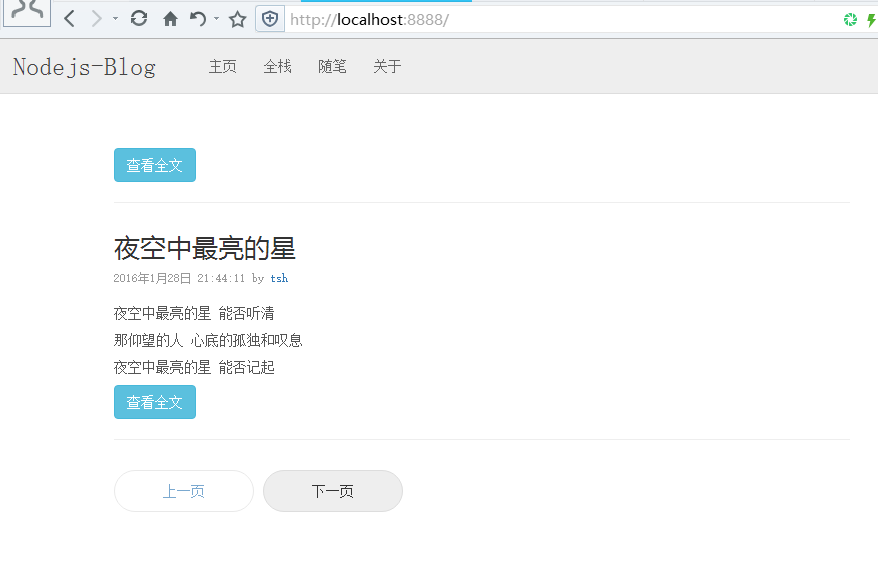
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

nodejs个人博客开发第一步 准备工作
前言 nodejs是运行在服务端的js,基于google的v8引擎.个人博客系统包含对数据库的增删查改,功能齐备,并且业务逻辑比较简单,是很多后台程序员为了检测学习成果,最先拿来练手的小网站程序.我也是在去年年末接触的nodejs,接下来随便纪录一下这个小blog的功能点和注意事项. 语言和环境 1. 进入nodejs的官方网站,下载nodejs运行环境 下载安装完成以后是这个样子的 2. express是基于nodejs平台的web开发框架,进入express框架的官方网站,了解express
-
nodejs个人博客开发第四步 数据模型
本文为大家分享了nodejs个人博客开发的数据模型,具体内容如下 数据库模型 /model/db.js 数据库操作类,完成链接数据库和数据库的增删查改 查询表 /*查询*/ select:function(tableName,callback,where,field){ field=field ? field : '*'; var sql="select "+field+" from "+this.C.DB_PRE+tableName; if(where){ sql
-
nodejs个人博客开发第二步 入口文件
本文为大家分享了nodejs个人博客开发的入口文件,具体内容如下 错误处理中间件 定义错误处理中间件必须使用4个参数,否则会被作为普通中间件 /*错误处理器*/ application.use(function(err,req,res,next){ console.error(err.stack); res.status(500).send("代码出错了,错误信息:<br/>"+err.stack); }); /*404*/ application.use(function
-
[将免费进行到底]在Amazon的一年免费服务器上安装Node.JS, NPM和OurJS博客
这里选用的操作系统是社区版Debian,Debian和Ubuntu的操作指令是一脉相承的,再加上之前玩过一段时间的Raspberry PI,个人比较熟悉,以下的安装过程其实同样适用于树霉派(安装node.js和NPM那一部分). 1) 注册并选型 在aws上注册并绑定信号卡后即可使用亚马逊的一年免费EC2主机,不过配置通常比较低,通常为0.612Mb(linux)和1G(Win)内存. http://aws.amazon.com/ 这里选用的是社区版Debian的版本是 Debian-squee
-
node.js实现博客小爬虫的实例代码
前言 爬虫,是一种自动获取网页内容的程序.是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化. 这篇文章介绍的是利用node.js实现博客小爬虫,核心的注释我都标注好了,可以自行理解,只需修改url和按照要趴的博客内部dom构造改一下filterchapters和filterchapters1就行了! 下面话不多说,直接来看实例代码 var http=require('http'); var Promise=require('Bluebird'); var cheeri
-
利用Vue.js+Node.js+MongoDB实现一个博客系统(附源码)
前言 这篇文章实现的博客系统使用 Vue 做前端框架,Node + express 做后端,数据库使用的是 MongoDB.实现了用户注册.用户登录.博客管理(文章的修改和删除).文章编辑(Markdown).标签分类等功能. 前端模仿的是 hexo 的经典主题 NexT,本来是想把源码直接拿过来用的,后来发现还不如自己写来得快,就全部自己动手实现成 vue components. 实现的功能 1.文章的编辑,修改,删除 2.支持使用 Markdown 编辑与实时预览 3.支持代码高亮 4.给文
-
nodejs个人博客开发第五步 分配数据
本文为大家分享了nodejs个人博客开发的分配数据,具体内容如下 使用回掉大坑进行取数据 能看明白的就看,看不明白的手动滑稽 /** * 首页控制器 */ var router=express.Router(); /*每页条数*/ var pageSize=5; router.get('/',function(req,res,next){ var currentPage=parseInt(req.params.page); var cid=0; var categoryModel=F.model
-
nodejs个人博客开发第三步 载入页面
本文为大家分享了nodejs个人博客开发的载入页面,具体内容如下 模板引擎 使用ejs作为我们博客的前端模板引擎,用来从json数据生成html字符串 安装:npm install ejs -save 使用:入口文件中写入下面代码,定义/view/目录为视图目录 /*模板引擎*/ application.set('views',__dirname+'/views'); application.engine('.html',require("ejs").__express); appli
-
nodejs个人博客开发第七步 后台登陆
本文为大家分享了nodejs个人博客开发的后台登陆,具体内容如下 定义后台路径 访问这个路径进入后台页面 http://localhost:8888/admin/login 在后台路由控制器里面(/admin/index.js)调用登陆控制器(/admin/login.js) //调用router对象的use方法,使用路由中间件 router.use("/login",require("./login")); 登陆控制器里面,定义登陆界面的路由,定义登陆提交验证的路
-
nodejs个人博客开发第六步 数据分页
本文为大家分享了nodejs个人博客开发的数据分页,具体内容如下 控制器路由定义 首页路由:http://localhost:8888/ 首页分页路由:http://localhost:8888/index/2 /** * 首页控制器 */ var router=express.Router(); /*每页条数*/ var pageSize=4; /*首页*/ router.get('/',function(req,res,next){ var cid=0; F.model("article&q
-
node.js博客项目开发手记
需要安装的模块 body-parser 解析post请求 cookies 读写cookie express 搭建服务器 markdown Markdown语法解析生成器 mongoose 操作Mongodb数据库 swig 模板解析引擎 目录结构 db 数据库存储目录 models 数据库模型文件目录 public 公共文件目录(css,js,img) routers 路由文件目录 schemas 数据库结构文件 views 模板视图文件目录 app.js 启动文件 package.json a
-
python爬虫 正则表达式使用技巧及爬取个人博客的实例讲解
这篇博客是自己<数据挖掘与分析>课程讲到正则表达式爬虫的相关内容,主要简单介绍Python正则表达式爬虫,同时讲述常见的正则表达式分析方法,最后通过实例爬取作者的个人博客网站.希望这篇基础文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵.真的太忙了,太长时间没有写博客了,抱歉~ 一.正则表达式 正则表达式(Regular Expression,简称Regex或RE)又称为正规表示法或常规表示法,常常用来检索.替换那些符合某个模式的文本,它首先设定好了一些特殊的字及字符组合,通过组合的&
-
利用正则表达式抓取博客园列表数据
鉴于我在要完成的asp.net MVC 3 仿照博客园企业系统要用到测试数据,我自己输入太累,所以我就抓取了博客园的部分列表数据,还请dudu不要见怪. 在抓取博客园数据的时候采用了正则表达式,所以有不熟悉正则表达式的朋友可以参考相关资料,其实很容易掌握,就是在具体的实例中会花些时间. 现在我就来把我抓取博客园数据的过程叙述一下,如果有朋友有更好的意见,欢迎提出来. 要使用正则表达式抓取数据,首先就要创建一个正则表达式进行匹配,我推荐使用regulator,这个正则表达式工具,我们可以先使用这个