如何让搜索引擎抓取AJAX内容解决方案
越来越多的网站,开始采用"单页面结构"(Single-page application)。
整个网站只有一张网页,采用Ajax技术,根据用户的输入,加载不同的内容。

这种做法的好处是用户体验好、节省流量,缺点是AJAX内容无法被搜索引擎抓取。举例来说,你有一个网站。
http://example.com 用户通过井号结构的URL,看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3 但是,搜索引擎只抓取example.com,不会理会井号,因此也就无法索引内容。
为了解决这个问题,Google提出了"井号+感叹号"的结构。
http://example.com#!1 当Google发现上面这样的URL,就自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1 只要你把AJAX内容放在这个网址,Google就会收录。但是问题是,"井号+感叹号"非常难看且烦琐。Twitter曾经采用这种结构,它把
http://twitter.com/ruanyf 改成
http://twitter.com/#!/ruanyf 结果用户抱怨连连,只用了半年就废除了。
那么,有没有什么方法,可以在保持比较直观的URL的同时,还让搜索引擎能够抓取AJAX内容?
我一直以为没有办法做到,直到前两天看到了Discourse创始人之一的Robin Ward的解决方法,不禁拍案叫绝。
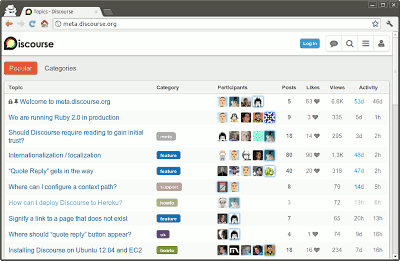
Discourse是一个论坛程序,严重依赖Ajax,但是又必须让Google收录内容。它的解决方法就是放弃井号结构,采用 History API。
所谓 History API,指的是不刷新页面的情况下,改变浏览器地址栏显示的URL(准确说,是改变网页的当前状态)。这里有一个例子,你点击上方的按钮,开始播放音乐。然后,再点击下面的链接,看看发生了什么事?
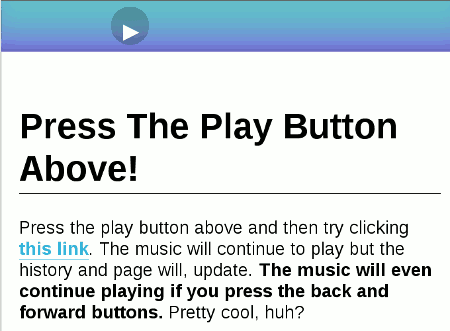
地址栏的URL变了,但是音乐播放没有中断!
History API 的详细介绍,超出这篇文章的范围。这里只简单说,它的作用就是在浏览器的History对象中,添加一条记录。
window.history.pushState(state object, title, url); 上面这行命令,可以让地址栏出现新的URL。History对象的pushState方法接受三个参数,新的URL就是第三个参数,前两个参数都可以是null。
window.history.pushState(null, null, newURL); 目前,各大浏览器都支持这个方法:Chrome(26.0+),Firefox(20.0+),IE(10.0+),Safari(5.1+),Opera(12.1+)。
下面就是Robin Ward的方法。
首先,用History API替代井号结构,让每个井号都变成正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3 然后,定义一个JavaScript函数,处理Ajax部分,根据网址抓取内容(假定使用jQuery)。
function anchorClick(link) { var linkSplit = link.split('/').pop(); $.get('api/' + linkSplit, function(data) { $('#content').html(data); }); }再定义鼠标的click事件。
$('#container').on('click', 'a', function(e) { window.history.pushState(null, null, $(this).attr('href')); anchorClick($(this).attr('href')); e.preventDefault(); }); 还要考虑到用户点击浏览器的"前进 / 后退"按钮。这时会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) { anchorClick(location.pathname); });定义完上面三段代码,就能在不刷新页面的情况下,显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为不使用井号结构,每个URL都是一个不同的请求。所以,要求服务器端对所有这些请求,都返回如下结构的网页,防止出现404错误。
<html> <body> <section id='container'></section> <noscript> ... ... </noscript> </body> </html>仔细看上面这段代码,你会发现有一个noscript标签,这就是奥妙所在。
我们把所有要让搜索引擎收录的内容,都放在noscript标签之中。这样的话,用户依然可以执行AJAX操作,不用刷新页面,但是搜索引擎会收录每个网页的主要内容!
相关推荐
-
js判断当页面无法回退时关闭网页否则就history.go(-1)
在做一个Web项目时遇到一个需求,当页面没有前驱历史记录时(就是当前为新弹出的页面,没法做goback操作即history.go(-1)),点击返回按钮时直接关闭页面,否则就退回到前一页. 遇到的问题就是如何判断 是否有history可以回退,这个非常麻烦,因为没有这样的函数直接能获取到,只能通过history.length这个变量做变通的处理,但是对于IE,和非IE的length的返回值不同,ie: history.length=0, 非IE的为1,因此写了一个函数实现前面所需求的这个功能.分
-
浏览器执行history.go(-1) FCKeditor编辑框内显示html源代码的解决方法
解决方法:FCK.LinkedField.value=FCKTools.HTMLEncode(FCK.LinkedField.value);改为 FCK.LinkedField.value=FCKTools.HTMLDecode(FCK.LinkedField.value); 如果问题不能解决,请注意是否清空浏览器缓存.
-
linux服务器清空MySQL的history历史记录 删除mysql操作记录
1. 不再保存历史记录或者减少历史记录保存数量 修改/etc/profile将HISTSIZE=1000 改成 0 或 要保留的数量清除用户home路径下的 .bash_history 复制代码 代码如下: echo '' > /home/user/.bash_history 2. 立即清空里的history当前历史命令的记录 复制代码 代码如下: history -c 当然,如果你想要当前执行的命令立即写入到history里面的话,可以执行 复制代码 代码如下: history -w 否则就只
-
javascript history对象(历史记录)使用方法(实现浏览器前进后退)
window.history对象在编写时可不使用 window 这个前缀.为了保护用户隐私,对 JavaScript 访问该对象的方法做出了限制. 方法: history.back() - 加载历史列表中的前一个URL,这与在浏览器中点击前进按钮是相同的history.forward() - 加载历史列表中的下一个URL,这与在浏览器中点击前进按钮是相同的 实例: 复制代码 代码如下: <html><button name="back" value="后退&
-
javascript:history.go()和History.back()的区别及应用
复制代码 代码如下: <input type=button value=刷新 onclick="window.location.reload()"> <input type=button value=前进 onclick="window.history.go(1)"> <input type=button value=后退 onclick="window.history.go(-1)"> <input t
-
基于jQuery的history历史记录插件
关于jQuery的历史 jQuery history plugin helps you to support back/forward buttons and bookmarks in your javascript applications.历史的jQuery插件可以帮助您回到您的JavaScript支持应用程序/前进按钮和书签. You can store the application state into URL hash and restore the state from it.你可
-

JavaScript的History API使搜索引擎抓取AJAX内容
大家在浏览Facebook的相册时有没有发现,页面局部刷新的同时地址栏的地址也改变了,而且不是hash的方式.它使用的就是HTML5 history新增的几个API,作为window的一个全局变量,在HTML4的时代history已不是什么新鲜的事物了.我们经常使用的就有 history.back()以及history.go() . 我一直以为没有办法做到,直到前两天看到了Discourse创始人之一的Robin Ward的解决方法,不禁拍案叫绝. Discourse是一个论坛程序,严重依赖Aj
-
如何让搜索引擎抓取AJAX内容解决方案
越来越多的网站,开始采用"单页面结构"(Single-page application). 整个网站只有一张网页,采用Ajax技术,根据用户的输入,加载不同的内容. 这种做法的好处是用户体验好.节省流量,缺点是AJAX内容无法被搜索引擎抓取.举例来说,你有一个网站. http://example.com 用户通过井号结构的URL,看到不同的内容. http://example.com#1 http://example.com#2 http://example.com#3 但是,搜索引擎
-
PHP抓取HTTPS内容和错误处理的方法
问题 在研究Hacker News API的时候遇到一个HTTPS问题.因为所有的Hacker News API都是通过加密的HTTPS协议访问的,跟普通的HTTP协议不同,当使用PHP里的函数 file_get_contents() 来获取API里提供的数据时,出现错误 使用的代码是这样的: <?php $data = file_get_contents("/http://blog.it985.com/"); ?> 当运行上面的代码是遇到下面的错误提示: PHP Warn
-
PHP curl 抓取AJAX异步内容示例
其实抓ajax异步内容的页面和抓普通的页面区别不大.ajax只不过是做了一次异步的http请求,只要使用firebug类似的工具,找到请求的后端服务url和传值的参数,然后对该url传递参数进行抓取即可. 利用Firebug的网络工具 如果抓去的是页面,则内容中没有显示的数据,是一堆JS代码. Code $cookie_file=tempnam('./temp','cookie'); $ch = curl_init(); $url1 = "http://www.cdut.edu.cn/defau
-
使用php方法curl抓取AJAX异步内容思路分析及代码分享
其实抓ajax异步内容的页面和抓普通的页面区别不大.ajax只不过是做了一次异步的http请求,只要使用firebug类似的工具,找到请求的后端服务url和传值的参数,然后对该url传递参数进行抓取即可. 利用Firebug的网络工具 如果抓去的是页面,则内容中没有显示的数据,是一堆JS代码. Code $cookie_file=tempnam('./temp','cookie'); $ch = curl_init(); $url1 = "http://www.cdut.edu.cn/defau
-
Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
1.引言 在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor.本文记录了确定gsExtractor的技术路线过程中所做的编程实验.这是第二部分,第一部分实验了用xslt方式一次性提取静态网页内容并转换成xml格式.留下了一个问题:javascript管理的动态内容怎样提取?那么本文就回答这个问题. 2.提取动态内容的技术部件 在上一篇python使用xslt提取网页数据中,要提取的内容是直接从网页的source code里拿到的.但是一些Aja
-
PHP实现抓取HTTPS内容
最近在研究Hacker News API时遇到一个HTTPS问题.因为所有的Hacker News API都是通过加密的HTTPS协议访问的,跟普通的HTTP协议不同,当使用PHP里的函数 file_get_contents() 来获取API里提供的数据时,出现错误,使用的代码是这样的: <?php$data = file_get_contents("https://hacker-news.firebaseio.com/v0/topstories.json?print=pretty&quo
-
Python selenium抓取微博内容的示例代码
Selenium简介与安装 Selenium是什么? Selenium也是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE.Mozilla Firefox.Mozilla Suite等. 安装 直接使用pip命令安装即可! pip install selenium Python抓取微博有两种方式,一是通过selenium自动登录后从页面直接爬取,二是通过api. 这里采用selenium的方式. 程序: from selen
-
零基础写Java知乎爬虫之将抓取的内容存储到本地
说到Java的本地存储,肯定使用IO流进行操作. 首先,我们需要一个创建文件的函数createNewFile: 复制代码 代码如下: public static boolean createNewFile(String filePath) { boolean isSuccess = true; // 如有则将"\\"转为"/",没有则不产生任何变化 String filePathTurn = filePath.r
-
PHP统计nginx访问日志中的搜索引擎抓取404链接页面路径
我在服务器上有每天切割nginx日志的习惯,所以针对每天各大搜索引擎来访,总能记录一些404页面信息,传统上我只是偶尔分析下日志,但是对于很多日志信息的朋友,人工来筛选可能不是一件容易的事情,这不我个人自己慢慢研究了一点点,针对谷歌.百度.搜搜.360搜索.宜搜.搜狗.必应等搜索引擎的404访问生成为一个txt文本文件,直接上代码test.php. 复制代码 代码如下: <?php //访问test.php?s=google $domain='http://www.jb51.net'; $spi