python爬取cnvd漏洞库信息的实例
今天一同事需要整理http://ics.cnvd.org.cn/工控漏洞库里面的信息,一看960多个要整理到什么时候才结束。
所以我决定写个爬虫帮他抓取数据。
看了一下各类信息还是很规则的,感觉应该很好写。
but这个网站设置了各种反爬虫手段。
经过各种百度,还是解决问题了。
设计思路:
1.先抓取每一个漏洞信息对应的网页url
2.获取每个页面的漏洞信息
# -*- coding: utf-8 -*-
import requests
import re
import xlwt
import time
from bs4 import BeautifulSoup
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36'
}
cookies={'__jsluid':'8d3f4c75f437ca82cdfad85c0f4f7c25'}
myfile=xlwt.Workbook()
wtable=myfile.add_sheet(u"信息",cell_overwrite_ok=True)
j = 0
a = 900
for i in range(4):
url ="http://ics.cnvd.org.cn/?max=20&offset="+str(a)
r = requests.get(urttp://ics.cnvd.org.cnl,headers=headers,cookies=cookies)
print r.status_code
while r.status_code != 200:
r = requests.get(url,headers=headers,cookies=cookies)
print r.status_code
html = r.text
soup = BeautifulSoup(html)
#print html
for tag in soup.find('tbody',id='tr').find_all('a',href=re.compile('http://www.cnvd.org.cn/flaw/show')):
print tag.attrs['href']
wtable.write(j,0,tag.attrs['href'])
j += 1
a += 20
print u"已完成%s"%(a)
filename=str(time.strftime('%Y%m%d%H%M%S',time.localtime()))+"url.xls"
myfile.save(filename)
print u"完成%s的url备份"%time.strftime('%Y%m%d%H%M%S',time.localtime())
# -*- coding: utf-8 -*-
from selenium import webdriver
import xlrd
import xlwt
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import NoAlertPresentException
import unittest, time, re
class Gk(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(5)
self.verificationErrors = []
self.accept_next_alert = True
def test_gk(self):
myfile=xlwt.Workbook()
wtable=myfile.add_sheet(u"info",cell_overwrite_ok=True)
data = xlrd.open_workbook('url.xlsx')
table = data.sheets()[0]
nrows = table.nrows
driver = self.driver
j = 0
for i in range(nrows):
try:
s = []
driver.get(table.cell(i,0).value)
title = driver.find_element_by_xpath("//h1").text
print title
s.append(title)
trs = driver.find_element_by_xpath("//tbody").find_elements_by_tag_name('tr')
for td in trs:
tds = td.find_elements_by_tag_name("td")
for tt in tds:
print tt.text
s.append(tt.text)
k = 0
for info in s:
wtable.write(j,k,info)
k += 1
j += 1
except:
filename=str(time.strftime('%Y%m%d%H%M%S',time.localtime()))+"url.xls"
myfile.save(filename)
print u"异常自动保存%s的漏洞信息备份"%time.strftime('%Y%m%d%H%M%S',time.localtime())
filename=str(time.strftime('%Y%m%d%H%M%S',time.localtime()))+"url.xls"
myfile.save(filename)
print u"完成%s的漏洞信息备份"%time.strftime('%Y%m%d%H%M%S',time.localtime())
def is_element_present(self, how, what):
try: self.driver.find_element(by=how, value=what)
except NoSuchElementException, e: return False
return True
def is_alert_present(self):
try: self.driver.switch_to_alert()
except NoAlertPresentException, e: return False
return True
def close_alert_and_get_its_text(self):
try:
alert = self.driver.switch_to_alert()
alert_text = alert.text
if self.accept_next_alert:
alert.accept()
else:
alert.dismiss()
return alert_text
finally: self.accept_next_alert = True
def tearDown(self):
self.driver.quit()
self.assertEqual([], self.verificationErrors)
if __name__ == "__main__":
unittest.main()
好了。看看结果怎样!
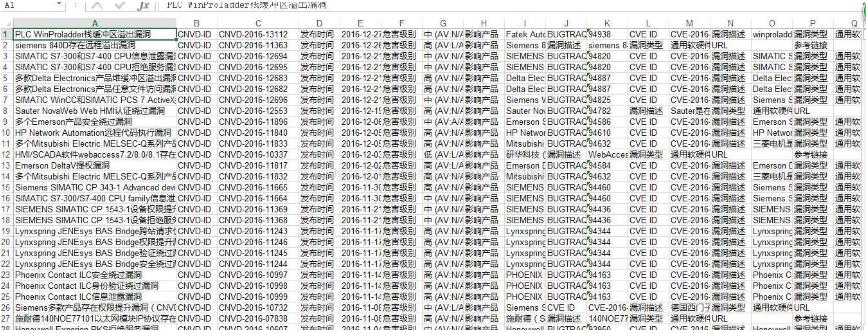
OK!剩下手动整理一下,收工!
以上这篇python爬取cnvd漏洞库信息的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
实例讲解Python爬取网页数据
一.利用webbrowser.open()打开一个网站: >>> import webbrowser >>> webbrowser.open('http://i.firefoxchina.cn/?from=worldindex') True 实例:使用脚本打开一个网页. 所有Python程序的第一行都应以#!python开头,它告诉计算机想让Python来执行这个程序.(我没带这行试了试,也可以,可能这是一种规范吧) 1.从sys.argv读取命令行参数:打开一个新的文
-

Python网络爬虫与信息提取(实例讲解)
课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解析HTML页面 4.Re框架:正则框架,提取页面关键信息 5.Scrapy框架:网络爬虫原理介绍,专业爬虫框架介绍 理念:The Website is the API ... Python语言常用的IDE工具 文本工具类IDE: IDLE.Notepad++.Sublime Text.Vim & Emacs.Atom.Komodo E
-
Python3爬虫学习之将爬取的信息保存到本地的方法详解
本文实例讲述了Python3爬虫学习之将爬取的信息保存到本地的方法.分享给大家供大家参考,具体如下: 将爬取的信息存储到本地 之前我们都是将爬取的数据直接打印到了控制台上,这样显然不利于我们对数据的分析利用,也不利于保存,所以现在就来看一下如何将爬取的数据存储到本地硬盘. 1 对.txt文件的操作 读写文件是最常见的操作之一,python3 内置了读写文件的函数:open open(file, mode='r', buffering=-1, encoding=None, errors=None,
-
Python 爬取携程所有机票的实例代码
打开携程网,查询机票,如广州到成都. 这时网址为:http://flights.ctrip.com/booking/CAN-CTU-day-1.html?DDate1=2018-06-15 其中,CAN 表示广州,CTU 表示成都,日期 "2018-06-15"就比较明显了.一般的爬虫,只有替换这几个值,就可以遍历了.但观察发现,有个链接可以看到当前网页的所有json格式的数据.如下 http://flights.ctrip.com/domesticsearch/search/Sear
-
python爬取cnvd漏洞库信息的实例
今天一同事需要整理http://ics.cnvd.org.cn/工控漏洞库里面的信息,一看960多个要整理到什么时候才结束. 所以我决定写个爬虫帮他抓取数据. 看了一下各类信息还是很规则的,感觉应该很好写. but这个网站设置了各种反爬虫手段. 经过各种百度,还是解决问题了. 设计思路: 1.先抓取每一个漏洞信息对应的网页url 2.获取每个页面的漏洞信息 # -*- coding: utf-8 -*- import requests import re import xlwt import t
-
使用Python爬取弹出窗口信息的实例
此文仅当学习笔记用. 这个实例是在Python环境下如何爬取弹出窗口的内容,有些时候我们要在页面中通过点击,然后在弹出窗口中才有我们要的信息,所以平常用的方法也许不行. 这里我用到的是Selenium这个工具, 不知道的朋友可以去搜索一下. 但是安装也是很费事的. 而且我用的浏览器是firefox,不用IE是因为好像新版的IE在Selenium下有问题,我也是百思不得其解, 网上也暂时没找到好的办法. from selenium import webdriver from selenium.we
-
Python爬取个人微信朋友信息操作示例
本文实例讲述了Python爬取个人微信朋友信息操作.分享给大家供大家参考,具体如下: 利用Python的itchat包爬取个人微信号的朋友信息,并将信息保存在本地文本中 思路要点: 1.利用itchat.login(),实现微信号的扫码登录 2.通过itchat.get_friends()函数获取朋友信息 代码: 本文代码只获取了几个常用的信息,更多信息可从itchat.get_friends()中取 #获取个人微信号中朋友信息 #导入itchat包 import itchat #获取个人微信号
-
用Python爬取LOL所有的英雄信息以及英雄皮肤的示例代码
实现思路:分为两部分,第一部分,获取网页上数据并使用xlwt生成excel(当然你也可以选择保存到数据库),第二部分获取网页数据使用IO流将图片保存到本地 一.爬取所有英雄属性并生成excel 1.代码 import json import requests import xlwt # 设置头部信息,防止被检测出是爬虫 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (
-
python爬取招聘要求等信息实例
在我们人生的路途中,找工作是每个人都会经历的阶段,小编曾经也是苦苦求职大军中的一员.怀着对以后的规划和想象,我们在找工作的时候,会看一些招聘信息,然后从中挑选合适的岗位.不过招聘的岗位每个公司都有不少的需求,我们如何从中获取数据,来进行针对岗位方面的查找呢? 大致流程如下: 1.从代码中取出pid 2.根据pid拼接网址 => 得到 detail_url,使用requests.get,防止爬虫挂掉,一旦发现爬取的detail重复,就重新启动爬虫 3.根据detail_url获取网页html信息
-
Python 爬取淘宝商品信息栏目的实现
一.相关知识点 1.1.Selenium Selenium是一个强大的开源Web功能测试工具系列,可进行读入测试套件.执行测试和记录测试结果,模拟真实用户操作,包括浏览页面.点击链接.输入文字.提交表单.触发鼠标事件等操作,并且能够对页面结果进行种种验证.也就是说,只要在测试用例中把预期的用户行为与结果都描述出来,我们就得到了一个可以自动化运行的功能测试套件. 1.2.ActionChains Actionchains是selenium里面专门处理鼠标相关的操作如:鼠标移动,鼠标按钮操作,按键和
-
python爬取安居客二手房网站数据(实例讲解)
是小打小闹 哈哈,现在开始正式进行爬虫书写首先,需要分析一下要爬取的网站的结构:作为一名河南的学生,那就看看郑州的二手房信息吧! 在上面这个页面中,我们可以看到一条条的房源信息,从中我们发现了什么,发现了连郑州的二手房都是这么的贵,作为即将毕业的学生狗惹不起啊惹不起 还是正文吧!!!由上可以看到网页一条条的房源信息,点击进去后就会发现: 房源的详细信息.OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说
-
python 爬取B站原视频的实例代码
B站原视频爬取,我就不多说直接上代码.直接运行就好. B站是把视频和音频分开.要把2个合并起来使用.这个需要分析才能看出来.然后就是登陆这块是比较难的. import os import re import argparse import subprocess import prettytable from DecryptLogin import login '''B站类''' class Bilibili(): def __init__(self, username, password, **
-
python爬取2021猫眼票房字体加密实例
春节假期刚过,大家有没有看春节档的电影呢?今年的春节档电影很是火爆,我们可以在猫眼票房app查看有关数据,因为数据一致在更新,所以他的字体是动态的,想要爬取有些困难,再加上猫眼app对字体进行加密,该如何爬取呢?本文介绍反爬2021猫眼票房字体加密的实例. 一.字体加密原理 简单来说就是程序员在设计网站的时候使用了自己设计的字体代码对关键字进行编码,在浏览器加载的时会根据这个字体文件对这些字体进行编码,从而显示出正确的字体. 二.爬取实例 1.得到字体斜率字典 import requestsim