利用pandas读取中文数据集的方法
直接利用numpy读取非数字型的数据集时需要先进行转换,而且python3在处理中文数据方面确实比较蛋疼。最近在学习周志华老师的那本西瓜书,需要没事和一堆西瓜反复较劲,之前进行联系的时候都是利用批量替换先清理一遍数据,不过这样实在是太麻烦了,今天偶然发现可以使用pandas来实现读取中文数据集的功能。
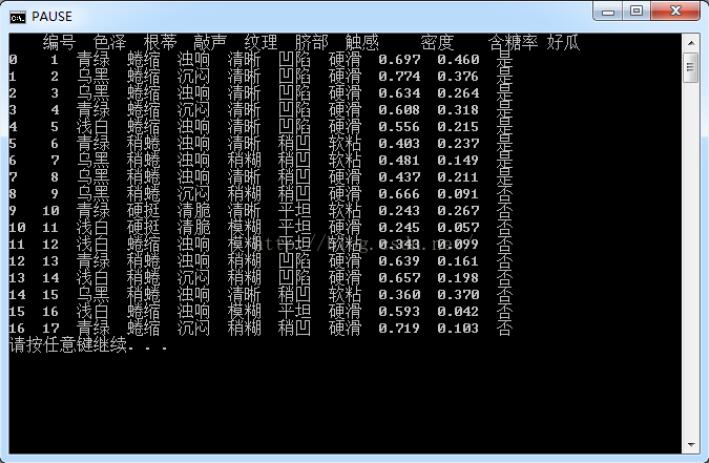
首先分享一下数据集:
编号,色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜 1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.46,是 2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.774,0.376,是 3,乌黑,蜷缩,浊响,清晰,凹陷,硬滑,0.634,0.264,是 4,青绿,蜷缩,沉闷,清晰,凹陷,硬滑,0.608,0.318,是 5,浅白,蜷缩,浊响,清晰,凹陷,硬滑,0.556,0.215,是 6,青绿,稍蜷,浊响,清晰,稍凹,软粘,0.403,0.237,是 7,乌黑,稍蜷,浊响,稍糊,稍凹,软粘,0.481,0.149,是 8,乌黑,稍蜷,浊响,清晰,稍凹,硬滑,0.437,0.211,是 9,乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,0.666,0.091,否 10,青绿,硬挺,清脆,清晰,平坦,软粘,0.243,0.267,否 11,浅白,硬挺,清脆,模糊,平坦,硬滑,0.245,0.057,否 12,浅白,蜷缩,浊响,模糊,平坦,软粘,0.343,0.099,否 13,青绿,稍蜷,浊响,稍糊,凹陷,硬滑,0.639,0.161,否 14,浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,0.657,0.198,否 15,乌黑,稍蜷,浊响,清晰,稍凹,软粘,0.36,0.37,否 16,浅白,蜷缩,浊响,模糊,平坦,硬滑,0.593,0.042,否 17,青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,0.719,0.103,否
然后利用pandas将它读进来:
import pandas d = pandas.read_csv(r"d:\data.csv",sep=",") print(d)
如果要选取某一行数据,可以使用head方法:
d.head(1)
其中参数是行号。
也可以直接取某一列,如:
d['色泽']
如果要取某一个数据则可以将两种方法结合使用:
d.head(1)['色泽']
以上这篇利用pandas读取中文数据集的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python遍历pandas数据方法总结
前言 Pandas是python的一个数据分析包,提供了大量的快速便捷处理数据的函数和方法.其中Pandas定义了Series 和 DataFrame两种数据类型,这使数据操作变得更简单.Series 是一种一维的数据结构,类似于将列表数据值与索引值相结合.DataFrame 是一种二维的数据结构,接近于电子表格或者mysql数据库的形式. 在数据分析中不可避免的涉及到对数据的遍历查询和处理,比如我们需要将dataframe两列数据两两相除,并将结果存储于一个新的列表中.本文通过该例程介绍对pa
-
对pandas写入读取h5文件的方法详解
1.引言 通过参考相关博客对hdf5格式简要介绍. hdf5在存储的是支持压缩,使用的方式是blosc,这个是速度最快的也是pandas默认支持的. 使用压缩可以提磁盘利用率,节省空间. 开启压缩也没有什么劣势,只会慢一点点. 压缩在小数据量的时候优势不明显,数据量大了才有优势. 同时发现hdf读取文件的时候只能是一次写,写的时候可以append,可以put,但是写完成了之后关闭文件,就不能再写了, 会覆盖. 另外,为什么单独说pandas,主要因为本人目前对于h5py这个包的理解不是很深入,不
-
对python pandas读取剪贴板内容的方法详解
我使用的Python3.5,32版本win764位系统,pandas0.19版本,使用df=pd.read_clipboard()的时候读不到数据,百度查找解决方法,找到了一个比较靠谱的 打开site-packages\pandas\io\clipboard.py 在 text = clipboard_get() 后面一行 加入这句: text = text.decode('UTF-8') 保存,然后就可以使用了 df=pd.read_clipboard() #变成正常的了 下次可以在其他地方复
-
通过Pandas读取大文件的实例
当数据文件过大时,由于计算机内存有限,需要对大文件进行分块读取: import pandas as pd f = open('E:/学习相关/Python/数据样例/用户侧数据/test数据.csv') reader = pd.read_csv(f, sep=',', iterator=True) loop = True chunkSize = 100000 chunks = [] while loop: try: chunk = reader.get_chunk(chunkSize) chun
-
python用pandas数据加载、存储与文件格式的实例
数据加载.存储与文件格式 pandas提供了一些用于将表格型数据读取为DataFrame对象的函数.其中read_csv和read_talbe用得最多 pandas中的解析函数: 函数 说明 read_csv 从文件.URL.文件型对象中加载带分隔符的数据,默认分隔符为逗号 read_table 从文件.URL.文件型对象中加载带分隔符的数据.默认分隔符为制表符("\t") read_fwf 读取定宽列格式数据(也就是说,没有分隔符) read_clipboard 读取剪贴板中的数据,
-
Python pandas常用函数详解
本文研究的主要是pandas常用函数,具体介绍如下. 1 import语句 import pandas as pd import numpy as np import matplotlib.pyplot as plt import datetime import re 2 文件读取 df = pd.read_csv(path='file.csv') 参数:header=None 用默认列名,0,1,2,3... names=['A', 'B', 'C'...] 自定义列名 index_col='
-
利用pandas读取中文数据集的方法
直接利用numpy读取非数字型的数据集时需要先进行转换,而且python3在处理中文数据方面确实比较蛋疼.最近在学习周志华老师的那本西瓜书,需要没事和一堆西瓜反复较劲,之前进行联系的时候都是利用批量替换先清理一遍数据,不过这样实在是太麻烦了,今天偶然发现可以使用pandas来实现读取中文数据集的功能. 首先分享一下数据集: 编号,色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜 1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.46,是 2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.7
-
利用Pandas读取文件路径或文件名称包含中文的csv文件方法
利用Pandas的read_csv函数导入数据文件时,若文件路径或文件名包含中文,会报错,无法导入: import pandas as pd df=pd.read_csv('E:/学习相关/Python/数据样例/用户侧数据/账单.csv') 解决方法如下: import pandas as pd f=open('E:/学习相关/Python/数据样例/用户侧数据/账单.csv') df=pd.read_csv(f) 以上这篇利用Pandas读取文件路径或文件名称包含中文的csv文件方法就是小编
-
对pandas读取中文unicode的csv和添加行标题的方法详解
pandas这个库就是这么智能.有了dateframe格式一切都好办了.相比csv库对中文支持就渣了. reader = pd.read_csv(leg2CsvReadFile, delimiter="," ,header=0,encoding = "gbk") header=None 即指明原始文件数据没有列索引,这样read_csv为自动加上列索引,除非你给定列索引的名字. obj_2=pd.read_csv('f:/ceshi.csv',header=0,na
-
利用Pandas读取表格行数据判断是否相同的方法
描述: 下午快下班的时候公司供应链部门的同事跑过来问我能不能以程序的方法帮他解决一些excel表格每周都需要手工重复做的事情,Excel 是数据处理最常用的办公工具对于市场.运营都应该很熟练.哈哈,然而程序员是不怎么会用excel的.下面给大家介绍一下pandas, Pandas是一个强大的分析结构化数据的工具集:它的使用基础是Numpy(提供高性能的矩阵运算):用于数据挖掘和数据分析,同时也提供数据清洗功能. 具体需求: 找出相同的数字,把与数字对应的英文字母合并在一起. 期望最终生成值:
-
利用Pandas读取某列某行数据之loc和iloc用法总结
目录 1.loc方法 2.iloc方法 补充:利用loc.iloc提取所有数据 总结 实际操作中我们经常需要寻找数据的某行或者某列,这里介绍我在使用Pandas时用到的两种方法:iloc和loc. loc:通过行.列的名称或标签来索引 iloc:通过行.列的索引位置来寻找数据 首先,我们先创建一个Dataframe,生成数据,用于下面的演示 import pandas as pd import numpy as np # 生成DataFrame data = pd.DataFrame(np.ar
-
Python如何利用pandas读取csv数据并绘图
目录 如何利用pandas读取csv数据并绘图 绘制图像 展示结果 pandas画pearson相关系数热力图 pearson相关系数计算函数 如何利用pandas读取csv数据并绘图 导包,常用的numpy和pandas,绘图模块matplotlib, import matplotlib.pyplot as plt import pandas as pd import numpy as np fig = plt.figure() ax = fig.add_subplot(111) 读取csv文
-
利用Pandas 创建空的DataFrame方法
平时写pyhton的时候习惯初始化一些list啊,tuple啊,dict啊这样的.一用到Pandas的DataFrame数据结构也就总想着初始化一个空的DataFrame,虽然没什么太大的用处,不过还是记录一下: # 创建一个空的 DataFrame df_empty = pd.DataFrame(columns=['A', 'B', 'C', 'D']) 上面创建的DataFrame有4列,每一行没有成员是空的. 输出一下结果: Empty DataFrame Columns: [A, B,
-
java利用POI读取excel文件的方法
摘要:利用java读取excel文件,读取文件并获取文件中每一个sheet中的值. 一.需要提前导入的包: import java.io.File; import java.io.FileInputStream; import org.apache.poi.hssf.usermodel.HSSFRow; import org.apache.poi.hssf.usermodel.HSSFSheet; import org.apache.poi.hssf.usermodel.HSSFWorkbook
-
python 使用pandas读取csv文件的方法
目录 pandas读取csv文件的操作 1. 读取csv文件 在这里记录一下,python使用pandas读取文件的方法用到pandas库的read_csv函数 # -*- coding: utf-8 -*- """ Created on Mon Jan 24 16:48:32 2022 @author: zxy """ # 导入包 import numpy as np import pandas as pd import matplotlib.