选择Python写网络爬虫的优势和理由
什么是网络爬虫?
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件
爬虫有什么用?
- 做为通用搜索引擎网页收集器。(google,baidu)
- 做垂直搜索引擎.
- 科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器。
- 偷窥,hacking,发垃圾邮件……
爬虫是搜索引擎的第一步也是最容易的一步
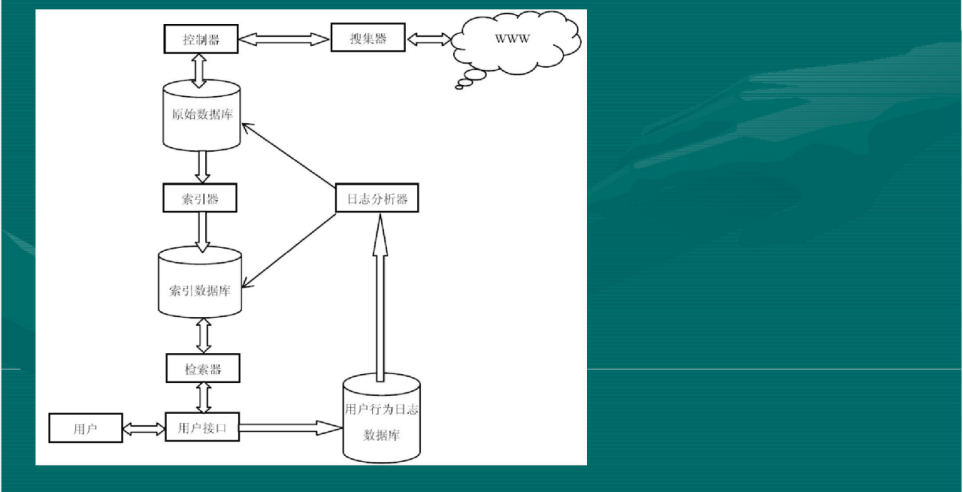
• 网页搜集
• 建立索引
• 查询排序
用什么语言写爬虫?
C,C++。高效率,快速,适合通用搜索引擎做全网爬取。缺点,开发慢,写起来又臭又长,例如:天网搜索源代码。
脚本语言:Perl, Python, Java, Ruby。简单,易学,良好的文本处理能方便网页内容的细致提取,但效率往往不高,适合对少量网站的聚焦爬取
C#?(貌似信息管理的人比较喜欢的语言)
为什么最终选择Python?
- 跨平台,对Linux和windows都有不错的支持。
- 科学计算,数值拟合:Numpy,Scipy
- 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2
- 复杂网络:Networkx
- 统计:与R语言接口:Rpy
- 交互式终端
- 网站的快速开发?
一个简单的Python爬虫
import urllib
import urllib.request
def loadPage(url,filename):
"""
作用:根据url发送请求,获取html数据;
:param url:
:return:
"""
request=urllib.request.Request(url)
html1= urllib.request.urlopen(request).read()
return html1.decode('utf-8')
def writePage(html,filename):
"""
作用将html写入本地
:param html: 服务器相应的文件内容
:return:
"""
with open(filename,'w') as f:
f.write(html)
print('-'*30)
def tiebaSpider(url,beginPage,endPage):
"""
作用贴吧爬虫调度器,负责处理每一个页面url;
:param url:
:param beginPage:
:param endPage:
:return:
"""
for page in range(beginPage,endPage+1):
pn=(page - 1)*50
fullurl=url+"&pn="+str(pn)
print(fullurl)
filename='第'+str(page)+'页.html'
html= loadPage(url,filename)
writePage(html,filename)
if __name__=="__main__":
kw=input('请输入你要需要爬取的贴吧名:')
beginPage=int(input('请输入起始页'))
endPage=int(input('请输入结束页'))
url='https://tieba.baidu.com/f?'
kw1={'kw':kw}
key = urllib.parse.urlencode(kw1)
fullurl=url+key
tiebaSpider(fullurl,beginPage,endPage)
以上就是关于为什么Python写网络爬虫的全部理由和知识点,感谢大家的阅读和对我们的支持。
相关推荐
-
Python网络爬虫之爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库 url= https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6 1.分析网页的源代码:右键--查看网页源代码. 从网页代码中可以获取到信息 (1)热搜的名字都在<td class="td-02">的子节点<a>里 (2)热搜的排名都在<td class=td-01 ranktop>的里(注意置顶微博是
-
python网络爬虫学习笔记(1)
本文实例为大家分享了python网络爬虫的笔记,供大家参考,具体内容如下 (一) 三种网页抓取方法 1. 正则表达式: 模块使用C语言编写,速度快,但是很脆弱,可能网页更新后就不能用了. 2.Beautiful Soup 模块使用Python编写,速度慢. 安装: pip install beautifulsoup4 3. Lxml 模块使用C语言编写,即快速又健壮,通常应该是最好的选择. (二) Lxml安装 pip install lxml 如果使用lxml的css选择器,还要安装下面的
-
Python3网络爬虫中的requests高级用法详解
本节我们再来了解下 Requests 的一些高级用法,如文件上传,代理设置,Cookies 设置等等. 1. 文件上传 我们知道 Reqeuests 可以模拟提交一些数据,假如有的网站需要我们上传文件,我们同样可以利用它来上传,实现非常简单,实例如下: import requests files = {'file': open('favicon.ico', 'rb')} r = requests.post('http://httpbin.org/post', files=files) print
-
Python发展史及网络爬虫
Python 简介 Python 是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言. Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构. Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节.类似于PHP和Perl语言. Python 是交互式语言: 这意味着,您可以在一个Python提示符,直接互动执行写你的程序. Python 是面向对象语言: 这意味着Python支持面向对象的风格
-
Python即时网络爬虫项目启动说明详解
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心. 我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级了,推翻了老版本很多东西,不得不花费很多时间和精力去移植和升级,至今还有一些隐藏在某处的代码埋着雷.我估计Python也避免不了这个问题(其实这种声音已经不少,比如Python 3 正在毁灭 Python). 但是,我还是启动了这个Python即时网络爬虫项目.我用C++.Java和Javascript编写爬虫相关
-

Python网络爬虫实例讲解
聊一聊Python与网络爬虫. 1.爬虫的定义 爬虫:自动抓取互联网数据的程序. 2.爬虫的主要框架 爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链接,爬虫调度器调用网页下载器下载相应网页,然后调用网页解析器解析该网页,并将该网页中新的URL添加到URL管理器中,将有价值的数据输出. 3.爬虫的时序图 4.URL管理器 URL管理器管理待抓取的URL集合和已抓取的URL集合,防止重复抓取与循环抓取.URL管理器的主要职能如下图
-
选择Python写网络爬虫的优势和理由
什么是网络爬虫? 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件 爬虫有什么用? 做为通用搜索引擎网页收集器.(google,baidu) 做垂直搜索引擎. 科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器.
-
详解用python写网络爬虫-爬取新浪微博评论
新浪微博需要登录才能爬取,这里使用m.weibo.cn这个移动端网站即可实现简化操作,用这个访问可以直接得到的微博id. 分析新浪微博的评论获取方式得知,其采用动态加载.所以使用json模块解析json代码 单独编写了字符优化函数,解决微博评论中的嘈杂干扰字符 本函数是用python写网络爬虫的终极目的,所以采用函数化方式编写,方便后期优化和添加各种功能 # -*- coding:gbk -*- import re import requests import json from lxml im
-
python教程网络爬虫及数据可视化原理解析
目录 1 项目背景 1.1Python的优势 1.2网络爬虫 1.3数据可视化 1.4Python环境介绍 1.4.1简介 1.4.2特点 1.5扩展库介绍 1.5.1安装模块 1.5.2主要模块介绍 2需求分析 2.1 网络爬虫需求 2.2 数据可视化需求 3总体设计 3.1 网页分析 3.2 数据可视化设计 4方案实施 4.1网络爬虫代码 4.2 数据可视化代码 5 效果展示 5.1 网络爬虫 5.1.1 爬取近五年主要城市数据 5.1.2 爬取2019年各省GDP 5.1.3 爬取豆瓣电影
-
给你选择Python语言实现机器学习算法的三大理由
基于以下三个原因,我们选择Python作为实现机器学习算法的编程语言:(1) Python的语法清晰:(2) 易于操作纯文本文件:(3) 使用广泛,存在大量的开发文档. 可执行伪代码 Python具有清晰的语法结构,大家也把它称作可执行伪代码(executable pseudo-code).默认安装的Python开发环境已经附带了很多高级数据类型,如列表.元组.字典.集合.队列等,无需进一步编程就可以使用这些数据类型的操作.使用这些数据类型使得实现抽象的数学概念非常简单.此外,读者还可以使用自己
-
python实现selenium网络爬虫的方法小结
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题,selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转.输入.点击.下拉等,来拿到网页渲染之后的结果,可支持多种浏览器,这里只用到谷歌浏览器. 1.selenium初始化 方法一:会打开网页 # 该方法会打开goole网页 from selenium import webdriver url = '网址' driver = webdriver.Chrom
-
Python网络爬虫项目:内容提取器的定义
1. 项目背景 在python 即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间,从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端的数据处理工作中. 2. 解决方案 为了解决这个问题,我们把影响通用性和工作效率的提取器隔离出来,描述了如下的数据处理流程图: 图中"可插拔提取器"必须很强的模块化,那么关键的接口有: 标准化的输入:以标准的HTML DOM对象为输入 标准化的内容提取:使用标准的xslt模板提取网页内容 标准化的输出:
-
python中数据爬虫requests库使用方法详解
一.什么是Requests Requests 是Python语编写,基于urllib,采Apache2 Licensed开源协议的 HTTP 库.它urllib 更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 一句话--requests是python实现的简单易用的HTTP库 二.安装Requests库 进入命令行win+R执行 命令:pip install requests 项目导入:import requests 三.各种请求方式 直接上代码,不明白可以查看我的urllib的基