解决Python selenium get页面很慢时的问题
driver.get("url")等到页面全部加载渲染完成后才会执行后续的脚本。
在执行脚本时,driver.get("url") ,如果当前的url页面内容较多加载特别慢,很费时间,但是我们需要操作的元素已经加载出来,可以将页面加载停掉,不影响后面的脚本执行,解决办法
设置页面加载timeout,get操作: try get except 脚本window.stop(), 使用GeckoDriver上有效果,
但是在ChromeDriver上还是会有问题,抛出异常timeout后续脚本不会继续执行
GeckoDriver执行具体如下:
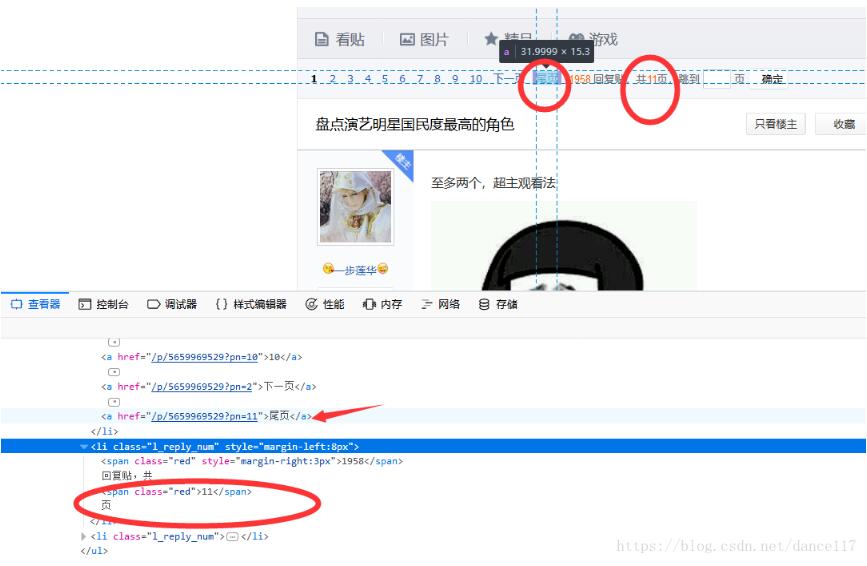
访问百度贴吧某个获取其帖子总页数:
可以通过两种方式获取,简单的就是直接定位元素共11页
代码用定位尾页获取总页数
from selenium import webdriver
import re
driver = webdriver.Firefox()
#设定页面加载timeout时长,需要的元素能加载出来就行
driver.set_page_load_timeout(20)
driver.set_script_timeout(20)
#try去get
try:
driver.get("http://tieba.baidu.com/p/5659969529?red_tag=w0852861182")
except:
print("加载页面太慢,停止加载,继续下一步操作")
driver.execute_script("window.stop()")
last_page_element = driver.find_element_by_css_selector("li.l_pager.pager_theme_4.pb_list_pager >a:nth-child(12)") #定位到元素尾页元素
#获取尾页页码链接文本
text = last_page_element.get_attribute("href")
all_page_num = re.search("\d+$",text).group() # 正则匹配到页码
print("当前贴吧贴子总页数为:%s"%all_page_num)
以上这篇解决Python selenium get页面很慢时的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

python 字典 setdefault()和get()方法比较详解
dict.setdefault(key, default=None) --> 有key获取值,否则设置 key:default,并返回default,default默认值为None dict.get(key, default=None) --> 有key获取值,否则返回default.default默认值为None. 例子:循环迭代message字符串中每个字符,计算每个字符出现的次数 import pprint message = "It is a good day, is not
-
python通过get,post方式发送http请求和接收http响应的方法
本文实例讲述了python通过get,post方式发送http请求和接收http响应的方法.分享给大家供大家参考.具体如下: 测试用CGI,名字为test.py,放在apache的cgi-bin目录下: #!/usr/bin/python import cgi def main(): print "Content-type: text/html\n" form = cgi.FieldStorage() if form.has_key("ServiceCode") a
-
Python中字典的setdefault()方法教程
前言 在python基础知识中有说过,字典是可变的数据类型,其参数又是键对值.setdefault()方法和字典的get()方法在一些地方比较相像,都可以得到给定键对应的值.但setdefault()方法可以在字典中并不包含有给定键的情况下,为给定键设定相应的值. Python 字典的 setdefault 方法原型如下: dict.setdefault(key, default=None) 如果给定的 key 在字典中则返回该值,如果不在字典中,就将 key 插入到字典中,并将值设置为指定的
-
在Python中操作字典之setdefault()方法的使用
setdefault()方法类似于get()方法,但会设置字典[键]=默认情况下,如果键不是已经在字典中. 方法 以下是setdefault()方法的语法: dict.setdefault(key, default=None) 参数 key -- 这是要被搜索的键 default -- 这是没有找到键的情况下返回的值. 返回值 此方法返回字典可用的键值,如果给定键不可用,则它会返回所提供的默认值. 例子 下面的例子显示了setdefault()方法的使用. #!/usr/bin/python d
-
在Python中用get()方法获取字典键值的教程
get()方法返回给定键的值.如果键不可用,则返回默认值None. 语法 以下是get()方法的语法: dict.get(key, default=None) 参数 key -- 这是要搜索在字典中的键. default -- 这是要返回键不存在的的情况下默认值. 返回值 该方法返回一个给定键的值.如果键不可用,则返回默认值为None. 例子 下面的例子显示了get()方法的使用. #!/usr/bin/python dict = {'Name': 'Zara', 'Age': 27} prin
-
python错误:AttributeError: 'module' object has no attribute 'setdefaultencoding'问题的解决方法
Python的字符集处理实在蛋疼,目前使用UTF-8居多,然后默认使用的字符集是ascii,所以我们需要改成utf-8 查看目前系统字符集 复制代码 代码如下: import sys print sys.getdefaultencoding() 执行: 复制代码 代码如下: [root@lee ~]# python a.py ascii 修改成utf-8 复制代码 代码如下: import sys sys.setdefaultencoding('utf-8') print sys.get
-
解析Python中的__getitem__专有方法
__getitem__ 来看个简单的例子就明白: def __getitem__(self, key): return self.data[key] >>> f = fileinfo.FileInfo("/music/_singles/kairo.mp3") >>> f {'name':'/music/_singles/kairo.mp3'} >>> f.__getitem__("name") '/music/_
-
解决Python selenium get页面很慢时的问题
driver.get("url")等到页面全部加载渲染完成后才会执行后续的脚本. 在执行脚本时,driver.get("url") ,如果当前的url页面内容较多加载特别慢,很费时间,但是我们需要操作的元素已经加载出来,可以将页面加载停掉,不影响后面的脚本执行,解决办法 设置页面加载timeout,get操作: try get except 脚本window.stop(), 使用GeckoDriver上有效果, 但是在ChromeDriver上还是会有问题,抛出异常
-
解决Python的str强转int时遇到的问题
数字字符串前后有空格没事: >>> print(int(" 3 ")) 3 但是下面这种带小数点的情况是不可取的: >>> print(int("3.0")) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: invalid literal for int() with b
-
解决python给列表里添加字典时被最后一个覆盖的问题
如下所示: >>> item={} ; items=[] #先声明一个字典和一个列表,字典用来添加到列表里面 >>> item['index']=1 #给字典赋值 >>> items.append(item) >>> items [{'index': 1}] #添加到列表里面复合预期 >>> item['index']=2 #现在修改字典 >>> item {'index': 2} #修改成功 &g
-
Python Selenium自动化获取页面信息的方法
1.获取页面title title:获取当前页面的标题显示的字段 from selenium import webdriver import time browser = webdriver.Chrome() browser.get('https://www.baidu.com') #打印网页标题 print(browser.title) #输出内容:百度一下,你就知道 2.获取页面URL current_url:获取当前页面的URL from selenium import webdriver
-
python+Selenium自动化测试——输入,点击操作
这是我的第一个真正意思上的自动化脚本. 1.练习的测试用例为: 打开百度首页,搜索"胡歌",然后检索列表,有无"胡歌的新浪微博"这个链接 2.在写脚本之前,需要明确测试的步骤,具体到每个步骤需要做什么,既拆分测试场景,考虑好之后,再去写脚本. 此测试场景拆分如下: 1)启动Chrome浏览器 2)打开百度首页,https://www.baidu.com 3)定位搜索输入框,输入框元素XPath表达式://*[@id="kw"] 4)定位搜索提交按
-
Python+Selenium定位不到元素常见原因及解决办法(报:NoSuchElementException)
在做web应用的自动化测试时,定位元素是必不可少的,这个过程经常会碰到定位不到元素的情况(报selenium.common.exceptions.NoSuchElementException),一般可以从以下几个方面着手解决: 1.Frame/Iframe原因定位不到元素: 这个是最常见的原因,首先要理解下frame的实质,frame中实际上是嵌入了另一个页面,而webdriver每次只能在一个页面识别,因此需要先定位到相应的frame,对那个页面里的元素进行定位. 解决方案: 如果iframe
-
python selenium UI自动化解决验证码的4种方法
本文介绍了python selenium UI自动化解决验证码的4种方法,分享给大家,具体如下: 测试环境 windows7+ firefox50+ geckodriver # firefox浏览器驱动 python3 selenium3 selenium UI自动化解决验证码的4种方法:去掉验证码.设置万能码.验证码识别技术-tesseract.添加cookie登录,本次主要讲解验证码识别技术-tesseract和添加cookie登录. 1. 去掉验证码 去掉验证码,直接通过用户名和密码登陆网
-
关于python selenium 运行时弹出窗口问题
近期在做一个网页代填项目时,用到了python的selenium,虽然实现了代填功能但是每次运行时都会弹出窗口,初始是python窗口,后续改进了又弹出了driver的窗口.在我看来是无伤大雅的,不过测试不接受,只能改,经过了各种尝试与搜索最后终算是较完美的解决了. 去除python窗口 项目初始是通过C++的process去调起python然后执行脚本的,后来发现会弹出python窗口. 使用的命令为 python.exe ie.py 效果如下 打开了页面但是同时会出现一个python窗口.
-
完美解决JS文件页面加载时的阻塞问题
关于页面加载时的时间消费,许多书中都做出了介绍,也提出了很多种方法.本文章就详细介绍XHR注入. 概述:JS分拆的方法 1.XHR注入:就是用ajax异步请求同域包含脚本的文件,然后将返回的字符串转化为脚本使用,该方法不会造成页面渲染和onload事件的阻塞,因为是异步处理,推荐使用. 2.iframe注入:加载一个iframe框架,通过使用iframe框架中的脚本来避免src方式加载脚本的阻塞,但是iframe元素开销较大,不推荐. 3.DOM注入:就是创建script元素,通过制定该元素的s
-
解决Python plt.savefig 保存图片时一片空白的问题
更新 这里我会列出对本文的更新. 2017 年 9 月 28 日:修正几处错字,优化排版. 问题 当使用如下代码保存使用 plt.savefig 保存生成的图片时,结果打开生成的图片却是一片空白. import matplotlib.pyplot as plt """ 一些画图代码 """ plt.show() plt.savefig("filename.png") 原因 其实产生这个现象的原因很简单:在 plt.show()