关于Python数据结构中字典的心得
本篇主要介绍:常见的字典方法、如何处理查不到的键、标准库中 dict 类型的变种、散列表的工作原理等。一下是全部内容:
泛映射类型
collections.abc 模块中有 Mapping 和 MutableMapping 这两个抽象基类,它们的作用是为 dict 和其他类似的类型定义形式接口。
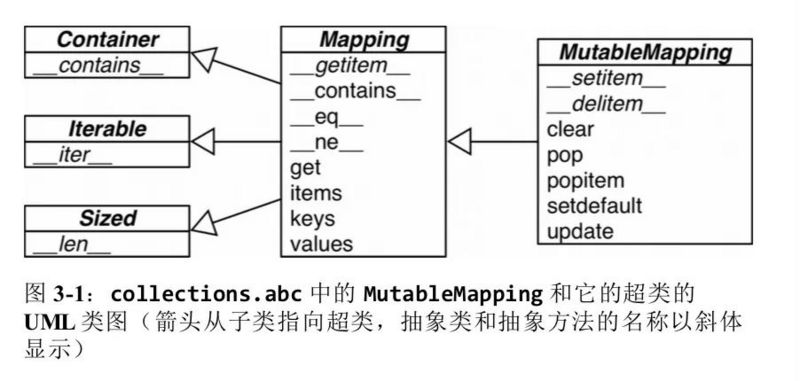
标准库里所有映射类型都是利用 dict 来实现的,它们有个共同的限制,即只有可散列的数据类型才能用做这些映射里的键。
问题: 什么是可散列的数据类型?
在 python 词汇表(https://docs.python.org/3/glossary.html#term-hashable)中,关于可散列类型的定义是这样的:
如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的,而且这个对象需要实现 __hash__() 方法。另外可散列对象还要有 __eq__() 方法,这样才能跟其他键做比较。如果两个可散列对象是相等的,那么它们的散列只一定是一样的
根据这个定义,原子不可变类型(str,bytes和数值类型)都是可散列类型,frozenset 也是可散列的(因为根据其定义,frozenset 里只能容纳可散列类型),如果元组内都是可散列类型的话,元组也是可散列的(元组虽然是不可变类型,但如果它里面的元素是可变类型,这种元组也不能被认为是不可变的)。
一般来讲,用户自定义的类型的对象都是可散列的,散列值就是它们的 id() 函数的返回值,所以这些对象在比较的时候都是不相等的。(如果一个对象实现了 eq 方法,并且在方法中用到了这个对象的内部状态的话,那么只有当所有这些内部状态都是不可变的情况下,这个对象才是可散列的。)
根据这些定义,字典提供了很多种构造方法,https://docs.python.org/3/library/stdtypes.html#mapping-types-dict 这个页面有个例子来说明创建字典的不同方式。
>>> a = dict(one=1, two=2, three=3)
>>> b = {'one': 1, 'two': 2, 'three': 3}
>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
>>> d = dict([('two', 2), ('one', 1), ('three', 3)])
>>> e = dict({'three': 3, 'one': 1, 'two': 2})
>>> a == b == c == d == e
True
除了这些方法以外,还可以用字典推导的方式来建造新 dict。
字典推导
自 Python2.7 以来,列表推导和生成器表达式的概念就移植到了字典上,从而有了字典推导。字典推导(dictcomp)可以从任何以键值对作为元素的可迭代对象中构建出字典。
比如:
>>> data = [(1, 'a'), (2, 'b'), (3, 'c')]
>>> data_dict = {num: letter for num, letter in data}
>>> data_dict
{1: 'a', 2: 'b', 3: 'c'}
常见的映射方法
下表为我们展示了 dict、defaultdict 和 OrderedDict 的常见方法(后两种是 dict 的变种,位于 collections模块内)。

default_factory 并不是一个方法,而是一个可调用对象,它的值 defaultdict 初始化的时候由用户设定。 OrderedDict.popitem() 会移除字典最先插入的元素(先进先出);可选参数 last 如果值为真,则会移除最后插入的元素(后进先出)。用 setdefault 处理找不到的键
当字典 d[k] 不能找到正确的键的时候,Python 会抛出异常,平时我们都使用d.get(k, default) 来代替 d[k],给找不到的键一个默认值,还可以使用效率更高的 setdefault
my_dict.setdefault(key, []).append(new_value) # 等同于 if key not in my_dict: my_dict[key] = [] my_dict[key].append(new_value)
这两段代码的效果一样,只不过,后者至少要进行两次键查询,如果不存在,就是三次,而用 setdefault 只需一次就可以完成整个操作。
那么,我们取值的时候,该如何处理找不到的键呢?
映射的弹性查询
有时候,就算某个键在映射里不存在,我们也希望在通过这个键读取值的时候能得到一个默认值。有两个途径能帮我们达到这个目的,一个是通过 defaultdict 这个类型而不是普通的 dict,另一个是给自己定义一个 dict 的子类,然后在子类中实现 __missing__ 方法。
defaultdict:处理找不到的键的一个选择
首先我们看下如何使用 defaultdict :
import collections index = collections.defaultdict(list) index[new_key].append(new_value)
这里我们新建了一个字典 index,如果键 new_key 在 index 中不存在,表达式 index[new_key] 会按以下步骤来操作:
调用 list() 来建立一个新的列表把这个新列表作为值,'new_key' 作为它的键,放入 index 中返回这个列表的引用。
而这个用来生成默认值的可调用对象存放在名为 default_factory 的实例属性中。
defaultdict 中的 default_factory 只会在 getitem 里调用,在其他方法中不会发生作用。比如 index[k] 这个表达式会调用 default_factory 创造的某个默认值,而 index.get(k) 则会返回 None。(这是因为特殊方法 missing 会在 defaultdict 遇到找不到的键的时候调用 default_factory,实际上,这个特性所有映射方法都可以支持)。
特殊方法 missing
所有映射在处理找不到的键的时候,都会牵扯到 missing 方法。但基类 dict 并没有提供 这个方法。不过,如果有一个类继承了 dict ,然后这个继承类提供了 missing 方法,那么在 getitem 碰到找不到键的时候,Python 会自动调用它,而不是抛出一个 KeyError 异常。
__missing__ 方法只会被 __getitem__ 调用。提供 missing 方法对 get 或者 __contains__(in 运算符会用到这个方法)这些方法的是有没有影响。
下面这段代码实现了 StrKeyDict0 类,StrKeyDict0 类在查询的时候把非字符串的键转化为字符串。
class StrKeyDict0(dict): # 继承 dict def __missing__(self, key): if isinstance(key, str): # 如果找不到的键本身就是字符串,抛出 KeyError raise KeyError(key) # 如果找不到的键不是字符串,转化为字符串再找一次 return self[str(key)] def get(self, key, default=None): # get 方法把查找工作用 self[key] 的形式委托给 __getitem__,这样在宣布查找失败钱,还能通过 __missing__ 再给键一个机会 try: return self[key] except KeyError: # 如果抛出 KeyError 说明 __missing__ 也失败了,于是返回 default return default def __contains__(self, key): # 先按传入的键查找,如果没有再把键转为字符串再找一次 return key in self.keys() or str(key) in self.keys()
contains 方法存在是为了保持一致性,因为 k in d 这个操作会调用它,但我们从 dict 继承到的 contains 方法不会在找不到键的时候用 missing 方法。
my_dict.keys() 在 Python3 中返回值是一个 "视图","视图"就像是一个集合,而且和字典一样速度很快。但在 Python2中,my_dict.keys() 返回的是一个列表。 所以 k in my_dict.keys() 操作在 python3中速度很快,但在 python2 中,处理效率并不高。
如果要自定义一个映射类型,合适的策略是继承 collections.UserDict 类。这个类就是把标准 dict 用 python 又实现了一遍,UserDict 是让用户继承写子类的,改进后的代码如下:
import collections class StrKeyDict(collections.UserDict): def __missing__(self, key): if isinstance(key, str): raise KeyError(key) return self[str(key)] def __contains__(self, key): # 这里可以放心假设所有已经存储的键都是字符串。因此只要在 self.data 上查询就好了 return str(key) in self.data def __setitem__(self, key, item): # 这个方法会把所有的键都转化成字符串。 self.data[str(key)] = item
因为 UserDict 继承的是 MutableMapping,所以 StrKeyDict 里剩下的那些映射类型都是从 UserDict、MutableMapping 和 Mapping 这些超类继承而来的。
Mapping 中提供了 get 方法,和我们在 StrKeyDict0 中定义的一样,所以我们在这里不需要定义 get 方法。
字典的变种
在 collections 模块中,除了 defaultdict 之外还有其他的映射类型。
collections.OrderedDict collections.ChainMap collections.Counter 不可变的映射类型
问题:标准库中所有的映射类型都是可变的,如果我们想给用户提供一个不可变的映射类型该如何处理呢?
从 Python3.3 开始 types 模块中引入了一个封装类名叫 MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图(如果原映射做了改动,这个视图的结果页会相应的改变)。例如
>>> from types import MappingProxy Type
>>> d = {1: 'A'}
>>> d_proxy = MappingProxyType(d)
>>> d_proxy
mappingproxy({1: 'A'})
>>> d_proxy[1]
'A'
>>> d_proxy[2] = 'x'
Traceback(most recent call last):
File "<stdin", line 1, in <module>
TypeError: 'MappingProxy' object does not support item assignment
>>> d[2] = 'B'
>>> d_proxy[2] # d_proxy 是动态的,d 的改动会反馈到它上边
'B'
字典中的散列表
散列表其实是一个稀疏数组(总有空白元素的数组叫稀疏数组),在 dict 的散列表中,每个键值都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。因为所有表元的大小一致,所以可以通过偏移量来读取某个表元。
python 会设法保证大概有1/3 的表元是空的,所以在快要达到这个阈值的时候,原有的散列表会被复制到一个更大的空间。
如果要把一个对象放入散列表,那么首先要计算这个元素的散列值。
Python内置的 hash() 方法可以用于计算所有的内置类型对象。
如果两个对象在比较的时候是相等的,那么它们的散列值也必须相等。例如 1==1.0 那么,hash(1) == hash(1.0)
散列表算法
为了获取 my_dict[search_key] 的值,Python 会首先调用 hash(search_key) 来计算 search_key 的散列值,把这个值的最低几位当做偏移量在散列表中查找元。若表元为空,抛出 KeyError 异常。若不为空,则表元会有一对 found_key:found_value。
这时需要校验 search_key == found_key,如果相等,返回 found_value。
如果不匹配(散列冲突),再在散列表中再取几位,然后处理一下,用处理后的结果当做索引再找表元。 然后重复上面的步骤。
取值流程图如下:

添加新值和上述的流程基本一致,只不过对于前者,在发现空表元的时候会放入一个新元素,而对于后者,在找到相应表元后,原表里的值对象会被替换成新值。
另外,在插入新值是,Python 可能会按照散列表的拥挤程度来决定是否重新分配内存为它扩容,如果增加了散列表的大小,那散列值所占的位数和用作索引的位数都会随之增加字典的优势和限制
1、键必须是可散列的
可散列对象要求如下:
支持 hash 函数,并且通过__hash__() 方法所得的散列值不变支持通过 __eq__() 方法检测相等性若 a == b 为真, 则 hash(a) == hash(b) 也为真
2、字典开销巨大
因为字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上效率低下。
3、键查询很快
dict 的实现是典型的空间换时间:字典类型由着巨大的内存开销,但提供了无视数据量大小的快速访问。
4、键的次序决定于添加顺序
当往 dict 里添加新键而又发生散列冲突时,新建可能会被安排存放在另一个位置。
5、往字典里添加新键可能会改变已有键的顺序
无论何时向字典中添加新的键,Python 解释器都可能做出为字典扩容的决定。扩容导致的结果就是要新建一个更大的散列表,并把原有的键添加到新的散列表中,这个过程中可能会发生新的散列冲突,导致新散列表中次序发生变化。
因此,不要对字典同时进行迭代和修改。
相关推荐
-

Python数据结构之顺序表的实现代码示例
顺序表即线性表的顺序存储结构.它是通过一组地址连续的存储单元对线性表中的数据进行存储的,相邻的两个元素在物理位置上也是相邻的.比如,第1个元素是存储在线性表的起始位置LOC(1),那么第i个元素即是存储在LOC(1)+(i-1)*sizeof(ElemType)位置上,其中sizeof(ElemType)表示每一个元素所占的空间. 追加直接往列表后面添加元素,插入是将插入位置后的元素全部往后面移动一个位置,然后再将这个元素放到指定的位置,将长度加1删除是将该位置后面的元素往前移动,覆盖该元素,然
-
Python数据结构与算法之常见的分配排序法示例【桶排序与基数排序】
本文实例讲述了Python数据结构与算法之常见的分配排序法.分享给大家供大家参考,具体如下: 箱排序(桶排序) 箱排序是根据关键字的取值范围1~m,预先建立m个箱子,箱排序要求关键字类型为有限类型,可能会有无限个箱子,实用价值不大,一般用于基数排序的中间过程. 桶排序是箱排序的实用化变种,其对数据集的范围,如[0,1) 进行划分为n个大小相同的子区间,每一个子区间为一个桶,然后将n非记录分配到各桶中.因为关键字序列是均匀分布在[0,1)上的,所以一般不会有很多记录落入同一个桶中. 以下的桶排序方
-
Python数据结构之栈、队列的实现代码分享
1. 栈 栈(stack)又名堆栈,它是一种运算受限的线性表.其限制是仅允许在表的一端进行插入和删除运算.这一端被称为栈顶,相对地,把另一端称为栈底.向一个栈插入新元素又称作进栈.入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素:从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素. 栈(Stack)是限制插入和删除操作只能在一个位置进行的表,该位置是表的末端,称为栈的顶(top).栈的基本操作有PUSH(入栈)和POP(出栈).栈又被称为LIF
-
Python数据结构与算法之链表定义与用法实例详解【单链表、循环链表】
本文实例讲述了Python数据结构与算法之链表定义与用法.分享给大家供大家参考,具体如下: 本文将为大家讲解: (1)从链表节点的定义开始,以类的方式,面向对象的思想进行链表的设计 (2)链表类插入和删除等成员函数实现时需要考虑的边界条件, prepend(头部插入).pop(头部删除).append(尾部插入).pop_last(尾部删除) 2.1 插入: 空链表 链表长度为1 插入到末尾 2.2 删除 空链表 链表长度为1 删除末尾元素 (3)从单链表到单链表的一众变体: 带尾节点的单链表
-
Python中顺序表的实现简单代码分享
顺序表python版的实现(部分功能未实现) 结果展示: 代码示例: #!/usr/bin/env python # -*- coding:utf-8 -*- class SeqList(object): def __init__(self, max=8): self.max = max #创建默认为8 self.num = 0 self.date = [None] * self.max #list()会默认创建八个元素大小的列表,num=0,并有链接关系 #用list实现list有些荒谬,全当
-
Python数据结构与算法之图的广度优先与深度优先搜索算法示例
本文实例讲述了Python数据结构与算法之图的广度优先与深度优先搜索算法.分享给大家供大家参考,具体如下: 根据维基百科的伪代码实现: 广度优先BFS: 使用队列,集合 标记初始结点已被发现,放入队列 每次循环从队列弹出一个结点 将该节点的所有相连结点放入队列,并标记已被发现 通过队列,将迷宫路口所有的门打开,从一个门进去继续打开里面的门,然后返回前一个门处 """ procedure BFS(G,v) is let Q be a queue Q.enqueue(v) lab
-
Python数据结构与算法之列表(链表,linked list)简单实现
Python 中的 list 并不是我们传统(计算机科学)意义上的列表,这也是其 append 操作会比 insert 操作效率高的原因.传统列表--通常也叫作链表(linked list)--通常是由一系列节点(node)来实现的,其每一个节点(尾节点除外)都持有一个指向下一个节点的引用. 其简单实现: class Node: def __init__(value, next=None): self.value = value self.next = next 接下来,我们就可使用链表的结构来
-
Python数据结构与算法之使用队列解决小猫钓鱼问题
本文实例讲述了Python数据结构与算法之使用队列解决小猫钓鱼问题.分享给大家供大家参考,具体如下: 按照<啊哈>里的思路实现这道题目,但是和结果不一样,我自己用一幅牌试了一下,发现是我的结果像一点,可能我理解的有偏差. # 小猫钓鱼 # 计算桌上每种牌的数量 # 使用defaultdict类,并设置默认类型为int型,即默认值为0 # cardcounts = defaultdict(int) # 不过deque有对应的方法 def henhenhaahaa(): from collecti
-
关于Python数据结构中字典的心得
本篇主要介绍:常见的字典方法.如何处理查不到的键.标准库中 dict 类型的变种.散列表的工作原理等.一下是全部内容: 泛映射类型 collections.abc 模块中有 Mapping 和 MutableMapping 这两个抽象基类,它们的作用是为 dict 和其他类似的类型定义形式接口. 标准库里所有映射类型都是利用 dict 来实现的,它们有个共同的限制,即只有可散列的数据类型才能用做这些映射里的键. 问题: 什么是可散列的数据类型? 在 python 词汇表(https://docs
-
Python数据容器dict(字典)的实现
目录 字典的定义 字典数据的获取 字典的嵌套 字典的各种操作 新增与更新元素 [Key] = Value 删除元素 pop和del 清空字典 clear 获取全部的键 keys 遍历字典 容器通用功能总览 字典的定义 使用{},不过存储的元素是一个个的:键值对,如下语法: 使用{}存储原始,每一个元素是一个键值对 每一个键值对包含Key和Value(用冒号分隔) 键值对之间使用逗号分隔 Key和Value可以是任意类型的数据(key不可为字典) Key不可重复,重复会对原有数据覆盖 字典不可用
-
Python 实现数据结构中的的栈队列
栈(stack)又名堆栈,它是一种运算受限的线性表.其限制是仅允许在表的一端进行插入和删除运算.这一端被称为栈顶,相对地,把另一端称为栈底.向一个栈插入新元素又称作进栈.入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素:从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素. 栈可以用顺序表实现,也可以用链表实现,这里为了方便就用顺序表实现. # -*- coding: utf-8 -*- class Stack(object): ""&
-
python实现数据结构中双向循环链表操作的示例
看此博客之前建议先看看B站的视频python数据结构与算法系列课程,该课程中未实现双向循环链表的操作,所以我按照该视频的链表思路实现了双向循环链表的操作,欢迎大家阅读与交流,如有侵权,请联系博主! 下面附上代码: class Node: def __init__(self, elem): self.elem = elem self.prev = None self.next = None class DoubleCycleLinkList: def __init__(self, node=Non
-
python接口测试返回数据为字典取值方式
目录 接口测试返回数据为字典取值 实例 python接口测试--sign签名 接口签名规范 实现代码 接口测试返回数据为字典取值 接口测试通常需要校验返回数据跟预期结果是否一致,这个时候如果返回数据为字典,那么我们要拿到我们想要的key对应的values时,需巧妙的运用dict.keys().dict.values()和for循环,以及列表相关知识点. 实例 这是我调接口返回的数据,该数据为dict类型,我的目标是要拿到account. #接口返回的数据: api_result = {'code
-
Python保存dict字典类型数据到Mysql并自动创建表与列
字典是另一种可变容器模型,且可存储任意类型对象,主要是工具类, 接下来使用pymysql来创建表与SQL 下面来看看示例代码: import pymysql class UseMysql(object): def __init__(self, user, passwd, db, host="127.0.0.1", port=3306): self.db = db self.conn = pymysql.connect( h
-
Python数据存储之XML文档和字典的互转
目录 面试题 解析 总结 考点: 将字典转换为XML文档: 将XML文档转换为字典. 面试题 1.面试题一:如何将一个字典转换为XML文档,并将该XML文档保存为文本文件. 2.面试题二:如何读取XML文件的内容,并将其转换为字典. 解析 如何将一个字典转换为XML文档,并将该XML文档保存为文本文件: 这里需要用到第三方库:dicttoxml.需要安装一下 # coding=utf-8 import dicttoxml from xml.dom.minidom import parseStri
-
Python字符串和字典相关操作的实例详解
Python字符串和字典相关操作的实例详解 字符串操作: 字符串的 % 格式化操作: str = "Hello,%s.%s enough for ya ?" values = ('world','hot') print str % values 输出结果: Hello,world.hot enough for ya ? 模板字符串: #coding=utf-8 from string import Template ## 单个变量替换 s1 = Template('$x, glorio
-
完美解决python遍历删除字典里值为空的元素报错问题
exam = { 'math': '95', 'eng': '96', 'chn': '90', 'phy': '', 'chem': '' } 使用下列遍历的方法删除: 1. for e in exam: 2. if exam[e] == '': 3. del exam[e] 结果出现下列错误,怎么解决: Traceback (most recent call last): File "Untitled.py", line 3, in <module> for e in
-
分享python数据统计的一些小技巧
最近在用python做数据统计,这里总结了一些最近使用时查找和总结的一些小技巧,希望能帮助在做这方面时的一些童鞋.有些技巧是很平常的用法,平时我们没有注意,但是在特定场景,这些小方法还是能带来很大的帮助. 1.在字典中将键映射到多个值上面 {'b': [4, 5, 6], 'a': [1, 2, 3]} 有时候我们在统计相同key值的时候,希望把所有相同key的条目添加到以key为键的一个字典中,然后再进行各种操作,这时候我们就可以使用下面的代码进行操作: from collections im