python 中xpath爬虫实例详解
案例一:

某套图网站,套图以封面形式展现在页面,需要依次点击套图,点击广告盘链接,最后到达百度网盘展示页面。
这一过程通过爬虫来实现,收集百度网盘地址和提取码,采用xpath爬虫技术
1、首先分析图片列表页,该页按照更新先后顺序暂时套图封面,查看HTML结构。每一组“li”对应一组套图。属性href后面即为套图的内页地址(即广告盘链接页)。所以,我们先得获取列表页内所有的内页地址(即广告盘链接页)

代码如下:
import requests 倒入requests库
from lxml import etree 倒入lxml 库(没有这个库,pip install lxml安装)
url = "https://www.xxxx.com/gc/" 请求地址
response = requests.get(url= url) 返回结果
wb_data = response.text 文本展示返回结果
html = etree.HTML(wb_data) 将页面转换成文档树
b = html.xpath('//ul[@class = "clearfix"]//@href') 这一步的意思是class“clearfix”下所有属性为“href”赋值给“b”,因为我们的目标内容都展示在class“clearfix”下,且在href属性后面
print(b) 打印b,这里的b是一个数组
print(b[0]) 打印b的第一项数据
执行结果:成功返回所有内页

2、打开内页(即广告盘链接页),获取广告盘地址。下图红色箭头,还不是真正的百度盘页,需要点击后才可以看的到百度盘的地址。所以这一步骤,只需要抓取红色箭头内容地址;



代码如下:
url = "https://www.xxxx.com/gc/toutiao/87098.html"
response = requests.get(url= url)
wb_data = response.text # 将页面转换成文档树
html = etree.HTML(wb_data)
b = html.xpath('//div[@class = "pictext"]//@href')
c=b[1] #需要注意的地方,class = "pictext"下有两个href,我们只需要第一个href的值,所以返回值再赋值给c且取第二项数据
print(c)
执行结果:成功返回所有内页

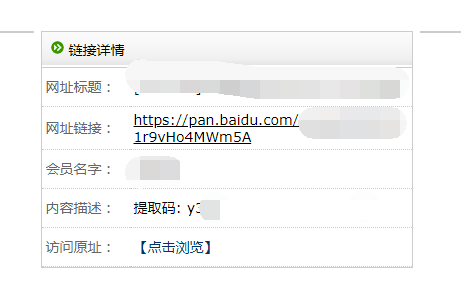
3、获取到广告盘地址,接下来要打开该地址,抓百度盘真实地址。链接和提取码在两个不同的元素中,所有最后返回两组数据。
代码如下:
url = "http://xxx.la/xam9I6"
response = requests.get(url= url)
wb_data = response.text
# 将页面转换成文档树
html = etree.HTML(wb_data)
b = html.xpath('//tr/td/text()')
c=b[6]#提取码
d = html.xpath('//tr//@href')#百度地址
print(c)
print(d)
注意,这里html.xpath写法与上面有些区别,目标元素的上级没有class,只能模糊取值
比如提取码的HTML结构如下图,结构为//tr/td/,单/代表父节点下的子节点,双/代表父节点后的子孙节点。提取码为tr的子节点。但是这个结构下有很多组数据,最后输出一个数组b(看上面代码b)。如此,我们找到提取码位于数组序列,赋值给c(看上面代码c),这样获得了真实的百度盘地址

网盘地址则因为有href属性,所以好爬去一些,注意/的数量即可

4、把以上步骤拼成一个脚本,这里就涉及到函数和函数之间的传参,还有循环的问题。代码直接贴出来
# -*-coding:utf8-*-
# encoding:utf-8
import requests
from lxml import etree
firstlink = "https://www.xxx.com/gc/qt/83720.html"
AA=["https://www.xxx.com/gc/",
"https://www.xxx.com/gc/index_2.html",
"https://www.xxx.com/gc/index_3.html",
"https://www.xxx.com/gq/",
"https://www.xxx.com/gq/index_2.html",
"https://www.xxx.com/gq/index_3.html",
"https://www.xxx.com/gq/index_4.html"]
#第1步,获取第一页面所有的地址
def stepa (AA):
lit=[]
for url in AA:
response = requests.get(url=url)
wb_data = response.text
# 将页面转换成文档树
html = etree.HTML(wb_data)
a = html.xpath('//ul[@class = "clearfix"]//@href')
lit.append(a)
return(lit)
alllink = stepa(AA)
#第2步,获取的地址,循环读取打开,从而获取百度网盘信息
def stepb(alllink,firstlink):
for list in alllink:
for url in list:
if url in firstlink:
continue
elif "www" in url:
url2 = url
else:
url2 ="https://www.xxx.com" +url
response = requests.get(url=url2)
wb_data = response.text # 将页面转换成文档树
html = etree.HTML(wb_data)
b = html.xpath('//div[@class = "pictext"]//@href')
c = b[1]
#print(c)
#获取到广告页地址
url3 = c
response = requests.get(url=url3)
wb_data = response.text
# 将页面转换成文档树
html = etree.HTML(wb_data)
d = html.xpath('//tr/td/text()')
#print(d)
e=d[6]#获取提取码
f = html.xpath('//tr//@href')#获取地址
test = e[-5:]#提取码值只保留提取码(4位)
test2 = f[-1]#链接只保留链接内容,去掉前后['']
test3=test2+test#把链接和提取码拼接成一条数据
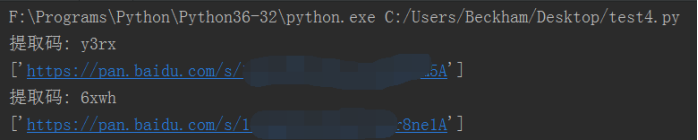
print(test3)
with open('C:/Users/Beckham/Desktop/python/1.txt', 'a',encoding='utf-8') as w:
w.write('\n'+test3)
w.close()
stepb(alllink,firstlink)
#第3步:提示爬取完成
def over():
print("ok")
over()
需要注意的地方:
1、return的用法,如果想把函数生成的值传给后面的函数用,就需要返回这个值,如def stepa 里定义的a为爬去的套图封面地址(通过打开这个地址进行下一步),就需要return(a)返回a的值,否则执行后无数据
2、Continue的应用,因为第一个套图地址打开的内容没有目标内容,这样找不到元素会报错,所以需要读取套图地址的时候要跳过第一个地址。加一个if判断,当第一个地址等于事先定义好的非正常地址的时候,跳过这个循环


打印结果:
案例二:
爬取豆瓣的读书的评论
分析html,评论存储放在标红色元素位置,且观察结构,其他评论都存储在li节点的相同位置
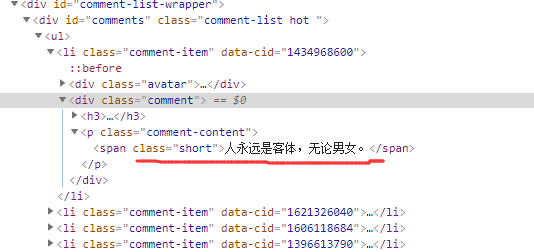
所以,xpath的解析对象为//*[@id="comments"]//div[2]/p/span
前面的实例讲过"//" 代表从当前节点选取子孙节点,这里就可以直接跳过li节点,直接选择li后的div[2]/p/span内容
代码如下:
# -*-coding:utf8-*-
# encoding:utf-8
import requests
from lxml import etree
firstlink = "https://book.douban.com/subject/30172069/comments/hot?p=6"
def stepa (firstlink):
response = requests.get(url=firstlink)
wb_data = response.text
html = etree.HTML(wb_data)
a = html.xpath('//*[@id="comments"]//div[2]/p/span')
print(a)
stepa (firstlink)
运行代码,打印出来的结果如下图,没有得到想要的评论内容
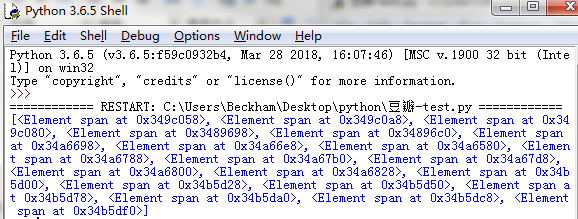
后来发现,想要获取内容,必须以文本的形式输出,即xpath的解析对象为//*[@id="comments"]//div[2]/p/span/text()
修改后的代码
# -*-coding:utf8-*-
# encoding:utf-8
import requests
from lxml import etree
firstlink = "https://book.douban.com/subject/30172069/comments/hot?p=6"
def stepa (firstlink):
response = requests.get(url=firstlink)
wb_data = response.text
html = etree.HTML(wb_data)
a = html.xpath('//*[@id="comments"]//div[2]/p/span/text()')
print(a)
stepa (firstlink)
执行一下,内容来了
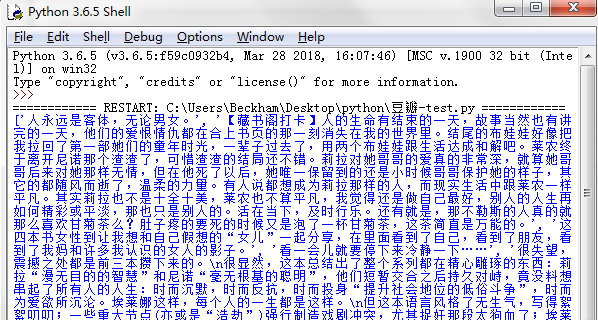
参考地址:https://cuiqingcai.com/5545.html
总结
以上所述是小编给大家介绍的python 中xpath爬虫实例详解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
python使用xpath中遇到:<Element a at 0x39a9a80>到底是什么?
前言 大家在学习python爬虫的过程中,会发现一个问题,语法我看完了,说的也很详细,我也认真看了,爬虫还是不会写,或者没有思路,所以我的所有文章都会从实例的角度来解析一些常见的问题和报错.下面话不多说了,来一起看看详细的介绍吧. Element是什么 回归正题,大家晕头转脑的看完繁杂的语法之后,已经迫不及待写点什么东西了,然后部分同学可能遇到了这个 <Element a at 0x39a9a80> 或者类似 Element a at 0x???????,这样的一个值,然后大家带着问题去搜,然
-
Python基于lxml模块解析html获取页面内所有叶子节点xpath路径功能示例
本文实例讲述了Python基于lxml模块解析html获取页面内所有叶子节点xpath路径功能.分享给大家供大家参考,具体如下: 因为需要使用叶子节点的路径来作为特征,但是原始的lxml模块解析之后得到的却是整个页面中所有节点的xpath路径,不是我们真正想要的形式,所以就要进行相关的处理才行了,差了很多网上的博客和文档也没有找到一个是关于输出html中全部叶子节点的API接口或者函数,也可能是自己没有那份耐心,没有找到合适的资源,只好放弃了寻找,但是这并不说明没有其他的方法了,在对页面全部节点
-
Python中利用xpath解析HTML的方法
在进行网页抓取的时候,分析定位html节点是获取抓取信息的关键,目前我用的是lxml模块(用来分析XML文档结构的,当然也能分析html结构), 利用其lxml.html的xpath对html进行分析,获取抓取信息. 首先,我们需要安装一个支持xpath的python库.目前在libxml2的网站上被推荐的python binding是lxml,也有beautifulsoup,不嫌麻烦的话还可以自己用正则表达式去构建,本文以lxml为例讲解. 假设有如下的HTML文档: <html> <
-

Python爬虫基础之XPath语法与lxml库的用法详解
前言 本来打算写的标题是XPath语法,但是想了一下Python中的解析库lxml,使用的是Xpath语法,同样也是效率比较高的解析方法,所以就写成了XPath语法和lxml库的用法 XPath 即为 XML 路径语言,它是一种用来确定 XML(标准通用标记语言的子集)文档中某部分位置的语言. XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力. XPath 同样也支持HTML. XPath 是一门小型的查询语言. python 中 lxml库 使用的是 Xpath 语法,是
-
python爬虫之xpath的基本使用详解
一.简介 XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML 文档中对元素和属性进行遍历.XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上. 二.安装 pip3 install lxml 三.使用 1.导入 from lxml import etree 2.基本使用 from lxml import etree wb_data = """ <div> <u
-
Python lxml解析HTML并用xpath获取元素的方法
代码 使用方法见注释 #-*- coding: UTF-8 -*- from lxml import etree source = u''' <div><p class="p1" data-a="1">测试数据1</p> <p class="p1" data-a="2">测试数据2</p> <p class="p1" data-a="
-
python 中xpath爬虫实例详解
案例一: 某套图网站,套图以封面形式展现在页面,需要依次点击套图,点击广告盘链接,最后到达百度网盘展示页面. 这一过程通过爬虫来实现,收集百度网盘地址和提取码,采用xpath爬虫技术 1.首先分析图片列表页,该页按照更新先后顺序暂时套图封面,查看HTML结构.每一组"li"对应一组套图.属性href后面即为套图的内页地址(即广告盘链接页).所以,我们先得获取列表页内所有的内页地址(即广告盘链接页) 代码如下: import requests 倒入requests库 from lxml
-
python中time包实例详解
在python中基础的时间运用,离不开time函数的支持.这些函数为了方便调用集中放在一个地方,叫做time包.有的人会仔细追寻time包的来源,会发现它和C语言有密不可分的关系.下面我们简单介绍time包的概念,然后就包中的一些函数进行列举,并附上对应的使用方法. 1.概念 time包基于C语言的库函数(library functions).Python的解释器通常是用C编写的,Python的一些函数也会直接调用C语言的库函数. 2.time包中的函数 time.clock()返回程序运行的整
-
python中尾递归用法实例详解
本文实例讲述了python中尾递归用法.分享给大家供大家参考.具体分析如下: 如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的.当递归调用是整个函数体中最后执行的语句且它的返回值不属于表达式的一部分时,这个递归调用就是尾递归.尾递归函数的特点是在回归过程中不用做任何操作,这个特性很重要,因为大多数现代的编译器会利用这种特点自动生成优化的代码. 原理: 当编译器检测到一个函数调用是尾递归的时候,它就覆盖当前的活跃记录而不是在栈中去创建一个新的.编译器可以做到这点,因
-
Python中的闭包实例详解
一般来说闭包这个概念在很多语言中都有涉及,本文主要谈谈python中的闭包定义及相关用法.Python中使用闭包主要是在进行函数式开发时使用.详情分析如下: 一.定义 python中的闭包从表现形式上定义(解释)为:如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是闭包(closure).这个定义是相对直白的,好理解的,不像其他定义那样学究味道十足(那些学究味道重的解释,在对一个名词的解释过程中又充满了一堆让人抓狂的其他陌生名词,不适合初学者).下面
-
python中defaultdict用法实例详解
目录 defaultdict底层代码: setdefault()和defaultdict()的区别: setdefault() defaultdict() 总结 defaultdict底层代码: 在字典中查找某个值时,若key不存在时则会返回一个KeyError错误而不是一个默认值,这时候可以使用defaultdict函数. 注意:使用dict[key]=value时,若key不存在则报错:使用dict.get(key)时,若key不存在则会返回一个默认值. defaultdict接受一个工厂函
-
使用 Python 读取电子表格中的数据实例详解
Python 是最流行.功能最强大的编程语言之一.由于它是自由开源的,因此每个人都可以使用.大多数 Fedora 系统都已安装了该语言.Python 可用于多种任务,其中包括处理逗号分隔值(CSV)数据.CSV文件一开始往往是以表格或电子表格的形式出现.本文介绍了如何在 Python 3 中处理 CSV 数据. CSV 数据正如其名.CSV 文件按行放置数据,数值之间用逗号分隔.每行由相同的字段定义.简短的 CSV 文件通常易于阅读和理解.但是较长的数据文件或具有更多字段的数据文件可能很难用肉眼
-
python open函数中newline参数实例详解
目录 问题的由来 具体实例 总结 问题的由来 我在读pythoncsv模块文档 看到了这样一句话 如果 csvfile 是文件对象,则打开它时应使用 newline=‘’.其备注:如果没有指定 newline=‘’,则嵌入引号中的换行符将无法正确解析,并且在写入时,使用 \r\n 换行的平台会有多余的 \r 写入.由于 csv 模块会执行自己的(通用)换行符处理,因此指定 newline=‘’ 应该总是安全的. 我就在思考open函数中的newline参数的作用,因为自己之前在使用open函数时
-
JAVA 多线程爬虫实例详解
JAVA 多线程爬虫实例详解 前言 以前喜欢Python的爬虫是出于他的简洁,但到了后期需要更快,更大规模的爬虫的时候,我才渐渐意识到Java的强大.Java有一个很好的机制,就是多线程.而且Java的代码效率执行起来要比python快很多.这份博客主要用于记录我对多线程爬虫的实践理解. 线程 线程是指一个任务从头至尾的执行流.线程提供了运行一个任务的机制.对于Java而言,可以在一个程序中并发地启动多个线程.这些线程可以在多处理器系统上同时运行. runnable接口 任务类必须实现runna
-
Python 迭代器与生成器实例详解
Python 迭代器与生成器实例详解 一.如何实现可迭代对象和迭代器对象 1.由可迭代对象得到迭代器对象 例如l就是可迭代对象,iter(l)是迭代器对象 In [1]: l = [1,2,3,4] In [2]: l.__iter__ Out[2]: <method-wrapper '__iter__' of list object at 0x000000000426C7C8> In [3]: t = iter(l) In [4]: t.next() Out[4]: 1 In [5]: t.
-
Python 私有函数的实例详解
Python 私有函数的实例详解 与大多数语言一样,Python 也有私有的概念: • 私有函数不可以从它们的模块外面被调用 • 私有类方法不能够从它们的类外面被调用 • 私有属性不能够从它们的类外面被访问 与大多数的语言不同,一个 Python 函数,方法,或属性是私有还是公有,完全取决于它的名字. 如果一个 Python 函数,类方法,或属性的名字以两个下划线开始 (但不是结束),它是私有的:其它所有的都是公有的. Python 没有类方法保护 的概念 (只能用于它们自已的类和子类中).类方