python实现壁纸批量下载代码实例
项目地址:https://github.com/jrainlau/wallpaper-downloader
前言
好久没有写文章了,因为最近都在适应新的岗位,以及利用闲暇时间学习python。这篇文章是最近的一个python学习阶段性总结,开发了一个爬虫批量下载某壁纸网站的高清壁纸。
注意:本文所属项目仅用于python学习,严禁作为其他用途使用!
初始化项目
项目使用了virtualenv来创建一个虚拟环境,避免污染全局。使用pip3直接下载即可:
pip3 install virtualenv
然后在合适的地方新建一个wallpaper-downloader目录,使用virtualenv创建名为venv的虚拟环境:
virtualenv venv . venv/bin/activate
接下来创建依赖目录:
echo bs4 lxml requests > requirements.txt
最后yun下载安装依赖即可:
pip3 install -r requirements.txt
分析爬虫工作步骤
为了简单起见,我们直接进入分类为“aero”的壁纸列表页:http://wallpaperswide.com/aer...。
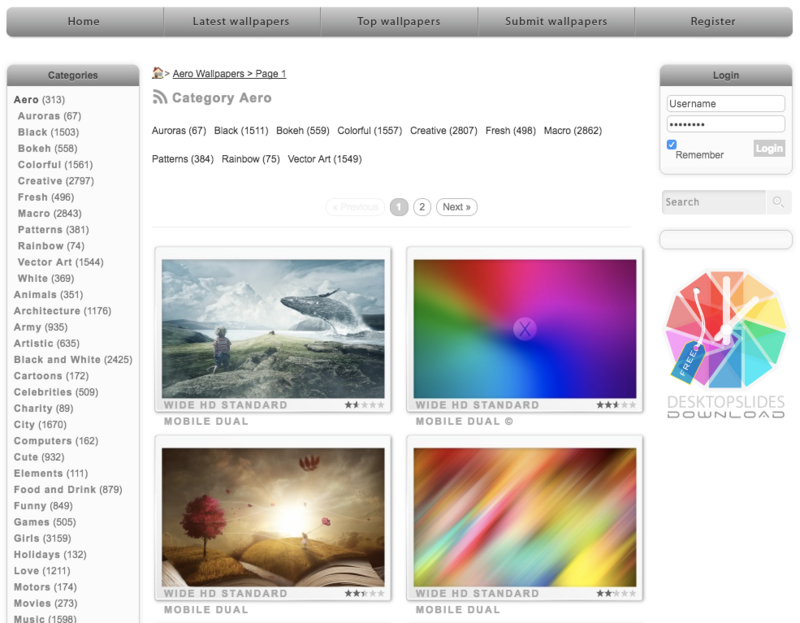
可以看到,这一页里面一共有10张可供下载的壁纸。但是由于这里显示的都是缩略图,作为壁纸来说清晰度是远远不够的,所以我们需要进入壁纸详情页,去找到高清的下载链接。从第一张壁纸点进去,可以看到一个新的页面:

因为我机器是Retina屏幕,所以我打算直接下载体积最大的那个以保证高清(红圈所示体积)。
了解了具体的步骤以后,就是通过开发者工具找到对应的dom节点,提取相应的url即可,这个过程就不再展开了,读者自行尝试即可,下面进入编码部分。
访问页面
新建一个download.py文件,然后引入两个库:
from bs4 import BeautifulSoup import requests
接下来,编写一个专门用于访问url,然后返回页面html的函数:
def visit_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'
}
r = requests.get(url, headers = headers)
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'lxml')
return soup
为了防止被网站反爬机制击中,所以我们需要通过在header添加UA把爬虫伪装成正常的浏览器,然后指定utf-8编码,最后返回字符串格式的html。
提取链接
在获取了页面的html以后,就需要提取这个页面壁纸列表所对应的url了:
def get_paper_link(page):
links = page.select('#content > div > ul > li > div > div a')
collect = []
for link in links:
collect.append(link.get('href'))
return collect
这个函数会把列表页所有壁纸详情的url给提取出来。
下载壁纸
有了详情页的地址以后,我们就可以进去挑选合适的size了。在对页面的dom结构分析后可以知道,每一个size都对应着一个链接:

所以第一步,就是把这些size对应的链接提取出来:
wallpaper_source = visit_page(link)
wallpaper_size_links = wallpaper_source.select('#wallpaper-resolutions > a')
size_list = []
for link in wallpaper_size_links:
href = link.get('href')
size_list.append({
'size': eval(link.get_text().replace('x', '*')),
'name': href.replace('/download/', ''),
'url': href
})
size_list就是这些链接的一个集合。为了方便接下来选出最高清(体积最大)的壁纸,在size中我使用了eval方法,直接把这里的5120x3200给计算出来,作为size的值。
获取了所有的集合之后,就可以使用max()方法选出最高清的一项出来了:
biggest_one = max(size_list, key = lambda item: item['size'])
这个biggest_one当中的url就是对应size的下载链接,接下来只需要通过requests库把链接的资源下载下来即可:
result = requests.get(PAGE_DOMAIN + biggest_one['url'])
if result.status_code == 200:
open('wallpapers/' + biggest_one['name'], 'wb').write(result.content)
注意,首先你需要在根目录下创建一个wallpapers目录,否则运行时会报错。
整理一下,完整的download_wallpaper函数长这样:
def download_wallpaper(link):
wallpaper_source = visit_page(PAGE_DOMAIN + link)
wallpaper_size_links = wallpaper_source.select('#wallpaper-resolutions > a')
size_list = []
for link in wallpaper_size_links:
href = link.get('href')
size_list.append({
'size': eval(link.get_text().replace('x', '*')),
'name': href.replace('/download/', ''),
'url': href
})
biggest_one = max(size_list, key = lambda item: item['size'])
print('Downloading the ' + str(index + 1) + '/' + str(total) + ' wallpaper: ' + biggest_one['name'])
result = requests.get(PAGE_DOMAIN + biggest_one['url'])
if result.status_code == 200:
open('wallpapers/' + biggest_one['name'], 'wb').write(result.content)
批量运行
上述的步骤仅仅能够下载第一个壁纸列表页的第一张壁纸。如果我们想下载多个列表页的全部壁纸,我们就需要循环调用这些方法。首先我们定义几个常量:
import sys
if len(sys.argv) != 4:
print('3 arguments were required but only find ' + str(len(sys.argv) - 1) + '!')
exit()
category = sys.argv[1]
try:
page_start = [int(sys.argv[2])]
page_end = int(sys.argv[3])
except:
print('The second and third arguments must be a number but not a string!')
exit()
这里通过获取命令行参数,指定了三个常量category, page_start和page_end,分别对应着壁纸分类,起始页页码,终止页页码。
为了方便起见,再定义两个url相关的常量:
PAGE_DOMAIN = 'http://wallpaperswide.com' PAGE_URL = 'http://wallpaperswide.com/' + category + '-desktop-wallpapers/page/'
接下来就可以愉快地进行批量操作了,在此之前我们来定义一个start()启动函数:
def start():
if page_start[0] <= page_end:
print('Preparing to download the ' + str(page_start[0]) + ' page of all the "' + category + '" wallpapers...')
PAGE_SOURCE = visit_page(PAGE_URL + str(page_start[0]))
WALLPAPER_LINKS = get_paper_link(PAGE_SOURCE)
page_start[0] = page_start[0] + 1
for index, link in enumerate(WALLPAPER_LINKS):
download_wallpaper(link, index, len(WALLPAPER_LINKS), start)
然后把之前的download_wallpaper函数再改写一下:
def download_wallpaper(link, index, total, callback):
wallpaper_source = visit_page(PAGE_DOMAIN + link)
wallpaper_size_links = wallpaper_source.select('#wallpaper-resolutions > a')
size_list = []
for link in wallpaper_size_links:
href = link.get('href')
size_list.append({
'size': eval(link.get_text().replace('x', '*')),
'name': href.replace('/download/', ''),
'url': href
})
biggest_one = max(size_list, key = lambda item: item['size'])
print('Downloading the ' + str(index + 1) + '/' + str(total) + ' wallpaper: ' + biggest_one['name'])
result = requests.get(PAGE_DOMAIN + biggest_one['url'])
if result.status_code == 200:
open('wallpapers/' + biggest_one['name'], 'wb').write(result.content)
if index + 1 == total:
print('Download completed!\n\n')
callback()
最后指定一下启动规则:
if __name__ == '__main__': start()
运行项目
在命令行输入如下代码开始测试:
python3 download.py aero 1 2
然后可以看到下列输出:

拿charles抓一下包,可以看到正在脚本正在平稳地运行中:

此时,下载脚本已经开发完毕,终于不用担心壁纸荒啦!
以上就是本次为大家整理的全部内容,大家有任何疑问可以在下方的留言区讨论,感谢你对我们的支持。
您可能感兴趣的文章:
- Python爬取qq music中的音乐url及批量下载
- Python实现Youku视频批量下载功能
- Python实现批量下载图片的方法
- python实现批量下载新浪博客的方法
- Python实现批量下载文件
- 编写Python脚本批量下载DesktopNexus壁纸的教程
- Python实现的批量下载RFC文档
- python批量下载图片的三种方法
- python批量下载壁纸的实现代码
相关推荐
-
Python实现批量下载文件
Python实现批量下载文件 #!/usr/bin/env python # -*- coding:utf-8 -*- from gevent import monkey monkey.patch_all() from gevent.pool import Pool import requests import sys import os def download(url): chrome = 'Mozilla/5.0 (X11; Linux i86_64) AppleWebKit/537.36
-
Python实现批量下载图片的方法
本文实例讲述了Python实现批量下载图片的方法.分享给大家供大家参考.具体实现方法如下: #!/usr/bin/env python #-*-coding:utf-8-*-' #Filename:download_file.py import os,sys import re import urllib import urllib2 base_url = 'xxx' array_url = list() pic_url = list() inner_url = list() def get_a
-
python实现批量下载新浪博客的方法
本文实例讲述了python实现批量下载新浪博客的方法.分享给大家供大家参考.具体实现方法如下: # coding=utf-8 import urllib2 import sys, os import re import string from BeautifulSoup import BeautifulSoup def encode(s): return s.decode('utf-8').encode(sys.stdout.encoding, 'ignore') def getHTML(url
-
python批量下载图片的三种方法
有三种方法,一是用微软提供的扩展库win32com来操作IE,二是用selenium的webdriver,三是用python自带的HTMLParser解析.win32com可以获得类似js里面的document对象,但貌似是只读的(文档都没找到).selenium则提供了Chrome,IE,FireFox等的支持,每种浏览器都有execute_script和find_element_by_xx方法,可以方便的执行js脚本(包括修改元素)和读取html里面的元素.不足是selenium只提供对py
-

Python爬取qq music中的音乐url及批量下载
前言 qq music上的音乐还是不少的,有些时候想要下载好听的音乐,但有每次在网页下载都是烦人的登录什么的.于是,来了个qqmusic的爬虫.至少我觉得for循环爬虫,最核心的应该就是找到待爬元素所在url吧.下面开始找吧(讲的不对不要笑我) 实现如下 #寻找url: 这个url可不想其他的网站那么好找.把我给累得不轻,关键是数据多,从那么多数据里面挑出有用的数据,最后组合为music真正的music.昨天做的时候整理的几个中间url: #url1:https://c.y.qq.com/sos
-
编写Python脚本批量下载DesktopNexus壁纸的教程
DesktopNexus 是我最喜爱的一个壁纸下载网站,上面有许多高质量的壁纸,几乎每天必上, 每月也必会坚持分享我这个月来收集的壁纸 但是 DesktopNexus 壁纸的下载很麻烦,而且因为壁纸会通过浏览器检测你当前分辨率来展示 合适你当前分辨率的壁纸,再加上是国外的网站,速度上很不乐观. 于是我写了个脚本,检测输入的页面中壁纸页面的链接,然后批量下载到指定文件夹中. 脚本使用 python 写的,所以需要机器上安装有 python . 用法: $ python desktop_nexus.
-
Python实现Youku视频批量下载功能
前段时间由于收集视频数据的需要,自己捣鼓了一个YouKu视频批量下载的程序.东西虽然简单,但还挺实用的,拿出来分享给大家. 版本:Python2.7+BeautifulSoup3.2.1 import urllib,urllib2,sys,os from BeautifulSoup import BeautifulSoup import itertools,re url_i =1 pic_num = 1 #自己定义的引号格式转换函数 def _en_to_cn(str): obj = itert
-
Python实现的批量下载RFC文档
RFC文档有很多,有时候在没有联网的情况下也想翻阅,只能下载一份留存本地了. 看了看地址列表,大概是这个范围: http://www.networksorcery.com/enp/rfc/rfc1000.txt ... http://www.networksorcery.com/enp/rfc/rfc6409.txt 哈哈,很适合批量下载,第一个想到的就是迅雷-- 可用的时候发现它只支持三位数的扩展(用的是迅雷7),我想要下的刚好是四位数-- 郁闷之下萌生自己做一个的想法! 这东西很适合用pyt
-
python批量下载壁纸的实现代码
复制代码 代码如下: #! /usr/bin/env python ##python2.7-批量下载壁纸 ##壁纸来自桌酷网站,所有权归属其网站 ##本代码仅做为交流学习使用,请勿用于商业用途,否则后果自负 ##Code by Dreamlikes import re,urllib,urllib2 #保存图片的路径 savepath = 'd:\\picture\\' #壁纸集合的URL,如下 url = 'http://www.zhuoku.com/zhuomianbizhi/game-gam
-
python实现壁纸批量下载代码实例
项目地址:https://github.com/jrainlau/wallpaper-downloader 前言 好久没有写文章了,因为最近都在适应新的岗位,以及利用闲暇时间学习python.这篇文章是最近的一个python学习阶段性总结,开发了一个爬虫批量下载某壁纸网站的高清壁纸. 注意:本文所属项目仅用于python学习,严禁作为其他用途使用! 初始化项目 项目使用了virtualenv来创建一个虚拟环境,避免污染全局.使用pip3直接下载即可: pip3 install virtualen
-
Python unittest discover批量执行代码实例
代码如下 import unittest dir = "D:\\work_doc\\pycharm2\\python_Basics" #自动化用例所存放的路径 suit = unittest.defaultTestLoader.discover(dir,pattern="XFS*.py",top_level_dir=None) #匹配出需要执行的py文件 runner = unittest.TextTestRunner() #TextTestRunner类实例化,目
-
使用Python进行QQ批量登录的实例代码
具体代码如下所示: #coding=utf-8 __author__ = 'Eagle' import os import time import win32gui import win32api import win32con import SendKeys from ctypes import * def QQ(qq,pwd): a = win32gui.FindWindow(None, "QQ") #运行QQ os.system('"C:\Program Files (
-
python3获取文件中url内容并下载代码实例
这篇文章主要介绍了python3获取文件中url内容并下载代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2019-12-25 11:33 # @Author : Anthony # @Email : ianghont7@163.com # @File : get_video_audio_file.py import xlrd
-
Python爬虫之批量下载喜马拉雅音频
一.解析网站 1.1 获取音频地址 在喜马拉雅网站上,随便点开一个音频,打开"开发者工具",再点击播放按钮,可以看到出现了多个请求: 经过排查,发现可疑url: 查看它的响应信息,发现音频地址就在里面: 接下来,解析这个返回音频地址的url: https://www.ximalaya.com/revision/play/v1/audio?id=348451879&ptype=1 发现url中的id参数就决定了返回的音频地址,而id参数是音频的id号. 1.2 解析专栏网页 我们
-
Python Pyqt5多线程更新UI代码实例(防止界面卡死)
""" 在编写GUI界面中,通常用会有一些按钮,点击后触发事件, 比如去下载一个文件或者做一些操作, 这些操作会耗时,如果不能及时结束,主线程将会阻塞, 这样界面就会出现未响应的状态,因此必须使用多线程来解决这个问题. """ 代码实例 from PyQt5.Qt import (QApplication, QWidget, QPushButton,QThread,QMutex,pyqtSignal) import sys import time
-
Python文件操作基本流程代码实例
文件操作之基本流程 #文本 近日,上市药企--浙江莎普爱思药业股份有限公司频遭质疑. 12月2日,一篇名为<一年卖出7.5亿的洗脑"神药",请放过中国老人>的文章称, 多位眼科医生并不认可莎普爱思滴眼液的"白内障防治功效".质疑者认为, 莎普爱思滴眼液是"假科普,真营销",通过广告误导患者. 针对质疑,莎普爱思3日晚发布的公告称, 0.5%苄达 赖氨酸滴眼液已于上世纪90年代通过了临床试验, 是一种安全的.有效的抗白内障药物.假的 #
-
php生成word并下载代码实例
本文实例讲述了php如何生成word并下载的具体实例.分享给大家供大家参考,具体如下: 1.前端代码 <!DOCTYPE html> <html> <head> <title>PHP生成Word文档</title> <meta charset="utf-8"> </head> <body> <h1 style="text-align: center">xxx的
-
python的unittest测试类代码实例
nittest单元测试框架不仅可以适用于单元测试,还可以适用WEB自动化测试用例的开发与执行,该测试框架可组织执行测试用例,并且提供了丰富的断言方法,判断测试用例是否通过,最终生成测试结果.今天笔者就总结下如何使用unittest单元测试框架来进行WEB自动化测试. 题目: 编写一个名为Employee的类,其方法__init__()接受名.姓和年薪,并将它们都存储在属性中.编写一个名为give_raise()的方法,它默认将年薪增加5000美元,但也能够接受其他的年薪增加量. 为Employe
-
python识别文字(基于tesseract)代码实例
这篇文章主要介绍了python识别文字(基于tesseract)代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Ubuntu版本: 1.tesseract-ocr安装 sudo apt-get install tesseract-ocr 2.pytesseract安装 sudo pip install pytesseract 3.Pillow 安装 sudo pip install pillow 开始写代码: from PIL impo