SQL 查询性能优化 解决书签查找
先来看看什么是书签查找:
当优化器所选择的非聚簇索引只包含查询请求的一部分字段时,就需要一个查找(lookup)来检索其他字段来满足请求。对一个有聚簇索引的表来说是一个键查找(key lookup),对一个堆表来说是一个RID查找(RID lookup)。这种查找即是——书签查找。
书签查找根据索引的行定位器从表中读取数据。因此,除了索引页面的逻辑读取外,还需要数据页面的逻辑读取。
从索引的行定位器到从表中读取数据这之间会产生一些额外的开销,本文就来解决这个开销。
先看下我的测试表结构: 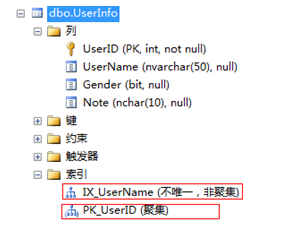
其中可以看出 有一个 聚簇索引 PK_UserID 和一个 非聚簇索引IX_UserName。
看看产生书签 查找的效果:
select UserName,Gender from dbo.UserInfo where UserName='userN600'
按上面的 SQL 产生执行计划 可以看出, 会产生一个书签查找(Key Lookup),如下图
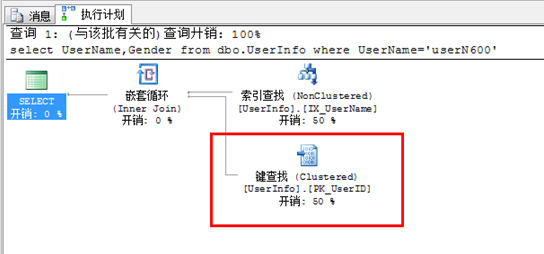
如果把上面的 SQL 改写成
select UserName from dbo.UserInfo where UserName='userN600'
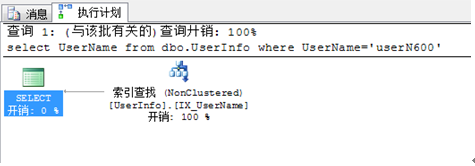
可以看出 书签查找 没有了。
本SQL 产生书签查找的 主要原因是 本SQL 优化器会选择 非聚簇索引IX_UserName,来执生SQL 。IX_UserName 索引不包含 Gender 这个字段 于是产生个从索引到 数据表的 一个 查找 即 书签查找。
解决书签查找:
方法一、使用一个 聚簇索引
对于聚簇索引, 索引的叶子页面和表的数据页面相同,因此,当读取聚簇索引 键列的值时,数据引擎可以读取其它列的值而不需要任何行定位,这样就解决了书签查找。
对于这句SQL ( select UserName,Gender from dbo.UserInfo where UserName='userN600')解决了书签查找的办法就是在UserName 上 建聚簇索引 ,因为一个表只有一个聚簇索引 ,这就意味着删除现有聚簇索引(PK_UserID),将会造成其它从表 中的外键约束 要发生更改,这需要考一些相关的工作,可能严重影响依赖于现有聚簇索引的其它查询。
方法二、使用一个 覆盖索引
覆盖索引 是在所有为满足SQL 查询不用到达基本表所需的列 建立的非聚簇索引。如果查询遇到一个索引并且完全不需要引用底层数据表,那么 该索引可以被认为是 覆盖索引。
对于这句SQL ( select UserName,Gender from dbo.UserInfo where UserName='userN600') 解决书签查找的办法就是 在非聚簇索引IX_UserName 里包含 Gender 字段。
也就是在 建索引时 用INCLUDE 语句,具体操作如下 
用INCLUDE 最好在 以下情况下使用:
1、不希望增加索引键的大小,但是仍然可以建一个 覆盖索引;
2、打算索引一种不能被索引的数据类型(除了文本、NTEXT和图像);
3、已经超过了一个索引的关键字列的最大数量
方法三、使用 索引连接
索引连接 是使用多个索引之间一个索引交叉来完全覆盖一个查询。如果覆盖索引变的非常宽,那么就可以考虑索引连接。
对于这句SQL ( select UserName,Gender from dbo.UserInfo where UserName='userN600' and Gender=1)可以在 Gender 上 建一个非聚簇索引就行了。
对于这个例 子,可能 SQL 优化器并没有同时 选 用非聚簇索引IX_UserName 和 我们新建立在Gender 上的索引,这时我们可以告知 SQL 优化器 同时使用 这个两上索引,操作如下
select Gender,UserName from UserInfo with(index (IX_Gender,IX_UserName)) where UserName='jins' and Gender=0
好了就写这么多吧.
相关推荐
-
Sql语句与存储过程查询数据的性能测试实现代码
一.建立数据库Liezui_Test ID int 主键 自增 Title varchar(100) ReadNum int 二.向数据库中插入100万条数据 declare @i int set @i=1 while @i<=500000 begin insert into Liezui_Test(Title,ReadNum) values('执行总数统计',@i) set @i=@i+1 end GO declare @i int set @i=1 while @i<=500000 beg
-
1亿条记录的MongoDB数据库随机查询性能测试
mongdb性能压力测试,随机查询,数据量1亿条记录 操作系统centos6.4x64位 从测试结果看,当mongodb将数据全部载入到内存后,查询速度根据文档的大小,性能瓶颈通常会是在网络流量和CPU的处理性能(该次测试中当数据全部在内存后,纯粹的查询速度可以稳定在10W/S左右,系统load可以维持在1以下,由于此时CPU已经被使用到极限了,当并发再大时load值会直线飙升,性能急剧下降). 压力生成服务器与Mongodb服务器基本配置 cpu型号:Intel(R) Xeon(R) CPU
-

MongoDB数据库查询性能提高40倍的经历分享
前言 数据库性能对软件整体性能有着至关重要的影响,本文给大家分享了一次MongoDB数据库查询性能提高40倍的经历,感兴趣的朋友们可以参考学习. 背景说明 1.数据库:MongoDB 2.数据集: A:字段数不定,这里主要用到的两个UID和Date B:三个字段,UID.Date.Actions.其中Actions字段是包含260元素JSON数组,每个JSON对象有6个字段.共有数据800万条左右. 3.业务场景:求平均数 通过组合条件从A数据表查询出(UID,Date)列表,最多可能包含数万条
-
MongoDB查询性能优化验证及验证
结论: 1. 200w数据,合理使用索引的情况下,单个stationId下4w数据.mongodb查询和排序的性能理想,无正则时client可以在600ms+完成查询,qps300+.有正则时client可以在1300ms+完成查询,qps140+. 2. Mongodb的count性能比较差,非并发情况下client可以在330ms完成查询,在并发情况下则需要1-3s.可以考虑估算总数的方法,http://blog.sina.com.cn/s/blog_56545fd30101442b.htm
-
数据库查询性能需注意几点经验
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0 3.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放
-
SQL 查询性能优化 解决书签查找
先来看看什么是书签查找: 当优化器所选择的非聚簇索引只包含查询请求的一部分字段时,就需要一个查找(lookup)来检索其他字段来满足请求.对一个有聚簇索引的表来说是一个键查找(key lookup),对一个堆表来说是一个RID查找(RID lookup).这种查找即是--书签查找. 书签查找根据索引的行定位器从表中读取数据.因此,除了索引页面的逻辑读取外,还需要数据页面的逻辑读取. 从索引的行定位器到从表中读取数据这之间会产生一些额外的开销,本文就来解决这个开销. 先看下我的测试表结构: 其中可
-
Sql Server查询性能优化之不可小觑的书签查找介绍
小小程序猿SQL Server认知的成长 1.没毕业或工作没多久,只知道有数据库.SQL这么个东东,浑然分不清SQL和Sql Server Oracle.MySql的关系,通常认为SQL就是SQL Server 2.工作好几年了,也写过不少SQL,却浑然不知道索引为何物,只知道数据库有索引这么个东西,分不清聚集索引和非聚集索引,只知道查询慢了建个索引查询就快了,到头来索引也建了不少,查询也确实快了,偶然问之:汝建之索引为何类型?答曰:... 3.终于受到刺激开始奋发图强,买书,gg查资料终于知道
-
Sql Server 查询性能优化之走出索引的误区分析
据了解绝大多数开发人员对于索引的理解都是一知半解,局限于大多数日常工作没有机会.也什么没有必要去关心.了解索引,实在哪天某个查询太慢了找到查询条件建个索引就ok,哪天又有个查询慢了,再建立个索引就是,或者干脆把整个查询SQL直接发给DBA,让DBA直接帮忙优化了,所以造成的状况就是开发人员对于索引的理解.认识很局限,以下就把我个人对于索引的理解及浅薄认识和大家分享下,希望能解除一些大家的疑惑,一起走出索引的误区 误区1.在表上建立了索引,在查询时用到了索引的列,索引就一定会生效 首先明确下这样的
-
sql server 性能优化之nolock
伴随着时间的增长,公司的数据库会越来越多,查询速度也会越来越慢.打开数据库看到几十万条的数据,查询起来难免不废时间. 要提升SQL的查询效能,一般来说大家会以建立索引(index)为第一考虑.其实除了index的建立之外,当我们在下SQL Command时,在语法中加一段WITH (NOLOCK)可以改善在线大量查询的环境中数据集被LOCK的现象藉此改善查询的效能. 不过有一点千万要注意的就是,WITH (NOLOCK)的SQL SELECT有可能会造成Dirty Read,就是读到无效的数据.
-
MySQL数据库查询性能优化的4个技巧干货
目录 前言 SQL的执行频率 慢查询日志 show profiles详情分析 explain执行计划 1.ID参数 2.select_type参数 3.type参数 前言 MySQL性能优化是一个老生常谈的问题,无论是在实际工作中还是面试中,都不可避免遇到相应的场景,下面博主就总结一些能够帮助大家解决这个问题的小技巧. SQL优化之前需要确认哪些SQL需要优化,这时就需要引起SQL性能分析工具,主要优化的是查询语句. SQL的执行频率 SQL性能优化一般是针对查询语句,所以在定位是否需要优化之前
-
Oracle分页查询性能优化代码详解
对于数据库中表的数据的 Web 显示,如果没有展示顺序的需要,而且因为满足条件的记录如此之多,就不得不对数据进行分页处理.常常用户并不是对所有数据都感兴趣的,或者大部分情况下,他们只看前几页. 通常有以下两种分页技术可供选择. Select * from ( Select rownum rn,t.* from table t) Where rn>&minnum and rn<=&maxnum 或者 Select * from ( Select rownum rn,t.* fro
-
MySQL查询性能优化七种方式索引潜水
目录 前言: 有读者可能会一脸懵? 啥是索引潜水? 你给起的名字的吗?有没有索引蛙泳? 这个名字还真不是我起的,今天要讲的知识点就叫索引潜水(Index dive) . 先要从一件怪事说起: 我先造点数据复现一下问题,创建一张用户表: CREATE TABLE `user` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID', `name` varchar(100) NOT NULL DEFAULT '' COM
-
MySQL查询性能优化武器之链路追踪
目录 前言 1. 查看optimizer trace配置 2. 开启optimizer trace 3. 线上问题复现 3. 使用optimizer trace 前言 MySQL优化器可以生成Explain执行计划,我们可以通过执行计划查看是否使用了索引,使用了哪种索引? 但是到底为什么会使用这个索引,我们却无从得知. 好在MySQL提供了一个好用的分析工具 — optimizer trace(优化器追踪),可以帮助我们查看优化器生成执行计划的整个过程,以及做出的各种决策,包括访问表的方法.各种
-
MySQL查询性能优化索引下推
目录 前言 1. 索引下推的作用 2. 案例实践 3. 索引下推配置 4. 索引下推原理剖析 5. 索引下推应用范围 前言 前面已经讲了MySQL的其他查询性能优化方式,没看过可以去了解一下: MySQL查询性能优化七种方式索引潜水 MySQL查询性能优化武器之链路追踪 今天要讲的是MySQL的另一种查询性能优化方式 — 索引下推(Index Condition Pushdown,简称ICP),是MySQL5.6版本增加的特性. 1. 索引下推的作用 主要作用有两个: 减少回表查询的次数 减少存
-
SQL语句性能优化(续)
上篇介绍了一下自己在项目中遇到的一种使用sql语句的优化方式(性能优化--SQL语句),但是说的不够完整.在对比的过程中,没有将max函数考虑在内,经人提醒之后赶紧做了一个测试,测试过程中又学到了不少的东西. 上次用的是select count(*) 和select * 的执行效率问题,因为我的需求是获取数据的一个总数来自动给出新的id,然后网友给出可以使用max的方式给出新id.其实这也是一种不错的思路(当时我们也用过该函数,只不过因为系统数据本身问题,不适合用该函数),然后我就对max函数的