mysql or走索引加索引及慢查询的作用
目录
- 前言
- 一 概述
- 二 实验表结构声明
- 三 Mysql不走索引归类以及详细解析
- 1. 查询条件在索引列上使用函数操作,或者运算的情况
- 2. 查询条件字符串和数字之间的隐式转换
- 3. 特殊修饰符 %%, Or 将不走索引
- 4. 索引优化器选择最优的索引
- 四 总结以及实际应用
前言

小白白跑去鹅厂面试,面试官提出了一个很实际的问题: mysql增加索引,那些情况会失效呢?谈一下实际工作中遇到的情况。我们的小白白又抛出了白氏秘籍:用不用索引,找DBA小姐姐!啊?这是你面试哈,还是DBA小姐姐面试呀。
一 概述
日常处理mysql问题中,往往通过增加索引来提高查询速度,但在有些情况下,执行过程中并没有按照我们的预期结果执行,也就是说,即使字段加了索引,但现实也没有使用到,到底是什么地方出了差错,以下我们将一探究竟。
二 实验表结构声明
我们将对以下表结构进行实际案例分析:
CREATETABLE
三 Mysql不走索引归类以及详细解析
根据实验表做具体case分析,归纳为以下几点:
1. 查询条件在索引列上使用函数操作,或者运算的情况
例如以下case是不走索引的:
explain select * from student where abs(age) =18; explain select * from student where age + 1=18;
2. 查询条件字符串和数字之间的隐式转换
例如:name与age分别做字符串/数字(88)的隐式转换;
以下case走索引情况:
explain select * from student where name ='88'; explain select * from student where age='88'; explain select * from student where age =88;
以下case不走索引情况:
explain select * from student where name=88;
3. 特殊修饰符 %%, Or 将不走索引
explain select * from student where name like'%name%' ; explain select * from student where name ='name' or age = 18;
4. 索引优化器选择最优的索引
这一点最重要,索引到底用不用,不是列加了索引就一定会用,而是根据索引优化器来决定。
索引优化器的存在,就是找到一个索引扫描行数最少的方案去执行语句。那么扫描行数怎么来判断的?是逐行统计数据表的数据吗?其实并不是,而是根据统计信息来估算的值。这个统计信息就是我们常说的索引的“区分度”。
显然,一个索引上不同的值越多,这个索引的区分度就越好。我们把一个索引上不同的值的个数,称之为“索引基数”。也就是说,基数越大,索引的区分度就越好,执行查询的行数就越少。如何查看索引基数呢?使用 show index from 表名,cardinality字段显示的就是索引的基数。
扩展:MySQL 是怎样得到索引基数的呢?不感兴趣的小伙伴可以飘过啦。
索引基数 = 采样统计*页数。采样统计就是避免把整张表取出来一行行统计做精准计算,以免消耗系统性能。在采样统计时,InnoDB默认会选择 N 个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。统计信息不是固定不变的,他会随着数据表的变化而变化。当变更的数据行数超过 1/M 的时候,会自动触发重新做一次索引统计。
索引优化器实例一:
经常听人说,执行<>语句时,不走索引,今天我们将看一看实际执行情况,还是那句话,到底走不走,我们说了不算,还是索引优化器说了算:看截图 ,就会发现 <> 其实是走了索引。
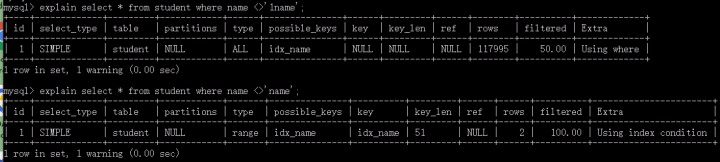
为什么会出现这样的情景呢?因为 student表中10W多条数据的值全都是'name',索引基数太小,所以在执行<>'1name'查询时,实际上要查询条数为10多W条,如果走了name字段索引,其实和全表查询没什么区别,况且,执行name字段索引,最终还是要转换为主键索引(二级索引查询都会转换为主键查询),所以索引优化器的优化结果是不走name索引。然而在执行<>'name'查询时,优化器优化结果是走name索引,因为,<>'name'的查询行数很小,大部分条数name字段的值都是'name'。
索引优化器实例二:
同理,前缀like匹配是走索引,但是,以下却展示了不一样的结果:
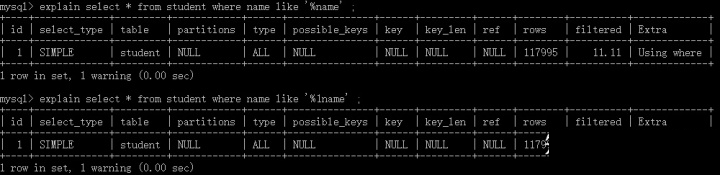
为什么会这样呢?请小伙伴们参考实例一仔细思考一下。
如何指定优化器执行固定的索引?
索引优化器的存在,我们就没办法指定强制走我们指定的索引?答案就是通过 force index强制来实现,
执行语句和分析结果如下图所示:

四 总结以及实际应用
实际应用中,应该牢记上述索引优化的原则,比如在实际工作中,由于索引优化器选错索引,导致数据查询缓慢,阻塞线上业务,而当时的解决办法,就是上述文章的分析过程,以及采用force 强制索引才解决的,前车之鉴,希望广大读者避免踩坑。
到此这篇关于mysql or走索引加索引及慢查询的作用的文章就介绍到这了,更多相关mysql or索引 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

MySQL优化方案之开启慢查询日志
目录 前言 设置慢查询日志 测试 附:日志分析工具mysqldumpslow 总结 前言 本方案只适应于小的项目.项目未上线或者紧急情况下可采用这种方式,一旦开启慢日志查询会增加数据库的压力,所以一般采用后台对数据操作时间写入日志文件中,每一周定时进行清除日志 mysql优化方案:开启慢查询日志(查询sql执行超过一秒以上sql等等) 开启慢查询日志:可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能. 参数说明: slow_query_log
-
MySQL中or、in、union与索引优化详析
本文缘起自<一分钟了解索引技巧>的作业题. 假设订单业务表结构为: order(oid, date, uid, status, money, time, -) 其中: oid,订单ID,主键 date,下单日期,有普通索引,管理后台经常按照date查询 uid,用户ID,有普通索引,用户查询自己订单 status,订单状态,有普通索引,管理后台经常按照status查询 money/time,订单金额/时间,被查询字段,无索引 - 假设订单有三种状态:0已下单,1已支付,2已完成 业务需求,查询
-
MySQL 通过索引优化含ORDER BY的语句
关于建立索引的几个准则: 1.合理的建立索引能够加速数据读取效率,不合理的建立索引反而会拖慢数据库的响应速度. 2.索引越多,更新数据的速度越慢. 3.尽量在采用MyIsam作为引擎的时候使用索引(因为MySQL以BTree存储索引),而不是InnoDB.但MyISAM不支持Transcation. 4.当你的程序和数据库结构/SQL语句已经优化到无法优化的程度,而程序瓶颈并不能顺利解决,那就是应该考虑使用诸如memcached这样的分布式缓存系统的时候了. 5.习惯和强迫自己用EXPLAIN来
-
MySQL数据库索引order by排序精讲
排序这个词,我的第一感觉是几乎所有App都有排序的地方,淘宝商品有按照购买时间的排序.B站的评论有按照热度排序的... 对于MySQL,一说到排序,你第一时间想到的是什么?关键字order by?order by的字段最好有索引?叶子结点已经是顺序的?还是说尽量不要在MySQL内部排序? 事情的起因 现在假设有一张用户的朋友表: CREATE TABLE `user` ( `id` int(10) AUTO_INCREMENT, `user_id` int(10), `friend_addr`
-
MySQL定位并优化慢查询sql的详细实例
目录 1.如何定位并优化慢查询sql a.根据慢日志定位慢查询sql b.使用explain等工具分析sql c.修改sql或者尽量让sql走索引 2.联合索引的最左匹配原则的成因 简单说下什么是最左匹配原则 最左匹配原则的原理 3.索引是建立得越多越好吗 总结 1.如何定位并优化慢查询sql a.根据慢日志定位慢查询sql SHOW VARIABLES LIKE '%query%' 查询慢日志相关信息 slow_query_log 默认是off关闭的,使用时,需要改为on 打开 slow_qu
-
Oracle与Mysql主键、索引及分页的区别小结
区别: 1.主键,Oracle不可以实现自增,mysql可以实现自增. oracle新建序列,SEQ_USER_Id.nextval 2.索引: mysql索引从0开始,Oracle从1开始. 3.分页, mysql: select * from user order by desc limit n ,m. 表示,从第n条数据开始查找,一共查找m条数据. Oracle:select * from user select rownum a * from ((select * from user)a
-
MySQL利用索引优化ORDER BY排序语句的方法
创建表&创建索引 create table tbl1 ( id int unique, sname varchar(50), index tbl1_index_sname(sname desc) ); 在已有的表创建索引语法 create [unique|fulltext|spatial] index 索引名 on 表名(字段名 [长度] [asc|desc]); MySQL也能利用索引来快速地执行ORDER BY和GROUP BY语句的排序和分组操作. 通过索引优化来实现MySQL的ORDER
-
MySQL索引类型Normal、Unique和Full Text的讲解
MySQL的索引类型有普通索引(normal),唯一索引(unique)和全文索引(full text),合理使用索引可大大提升数据库的查询效率,下面是三种类型的索引的介绍 normal:这是最基本的索引,它没有任何限制,MyIASM中默认的BTREE类型的索引,是我们大多数情况下用到的索引. unique:表示唯一的,不允许重复的索引,如果该字段信息保证不会重复.例如身份证号用作索引时,可设置为unique. full text : 表示全文搜索的索引,仅可用于 MyISAM 表. FULLT
-
MySQL Order By索引优化方法
尽管 ORDER BY 不是和索引的顺序准确匹配,索引还是可以被用到,只要不用的索引部分和所有的额外的 ORDER BY 字段在 WHERE 子句中都被包括了. 使用索引的MySQL Order By 下列的几个查询都会使用索引来解决 ORDER BY 或 GROUP BY 部分: 复制代码 代码如下: SELECT * FROM t1 ORDER BY key_part1,key_part2,... ; SELECT * FROM t1 WHERE key_part1=constant ORD
-
mysql or走索引加索引及慢查询的作用
目录 前言 一 概述 二 实验表结构声明 三 Mysql不走索引归类以及详细解析 1. 查询条件在索引列上使用函数操作,或者运算的情况 2. 查询条件字符串和数字之间的隐式转换 3. 特殊修饰符 %%, Or 将不走索引 4. 索引优化器选择最优的索引 四 总结以及实际应用 前言 小白白跑去鹅厂面试,面试官提出了一个很实际的问题: mysql增加索引,那些情况会失效呢?谈一下实际工作中遇到的情况.我们的小白白又抛出了白氏秘籍:用不用索引,找DBA小姐姐!啊?这是你面试哈,还是DBA小姐姐面试呀.
-
mysql中索引使用不当速度比没加索引还慢的测试
下面是我们插入到这个tuangou表的数据: id web city type 1 拉手网 北京 餐饮美食 2 拉手网 上海 休闲娱乐 3 百分团 天津 餐饮美食 4 拉手网 深圳 网上购物 5 百分团 石家庄 优惠卷票 6 百分团 邯郸 美容保健 .. 4999 百分团 重庆 旅游酒店 5000 拉手网 西安 优惠卷票 执行mysql语句: $sql = "select from tuangou where web='拉手网' and city='上海'"; (1)如果没有加索引,执
-
使用shell脚本来给mysql加索引的方法
用shell脚本来给mysql加索引 刚好用到, mark一下: #! /bin/bash tb_base=tb_student_ arr=("0" "1" "2" "3" "4" "5" "6" "7" "8" "9" "a" "b" "c" &q
-
MySQL怎么给字符串字段加索引
假设,你现在维护一个支持邮箱登录的系统,用户表是这么定义的: create table SUser( ID bigint unsigned primary key, email varchar(64), ... )engine=innodb; 由于要使用邮箱登录,所以业务代码中一定会出现类似于这样的语句: select f1, f2 from SUser where email='xxx'; 如果 email 这个字段上没有索引,那么这个语句就只能做全表扫描. 1)那我可以在邮箱地址这个
-
mysql添加索引方法详解(Navicat可视化加索引与sql语句加索引)
目录 使用索引的场景: 下面是通过sql语句添加索引的方法: 1.普通索引 1).直接创建索引 2).修改表结构的方式添加索引 3).删除索引 2.唯一索引 1).创建唯一索引 2).修改表结构 3.主键索引 4.组合索引 5.全文索引 1).创建表的适合添加全文索引 2).修改表结构添加全文索引 3).直接创建索引 总结 使用索引的场景: 阿里云日志里出现了慢sql 然后发现publish_works_id字段会经常用于一些关联,所以决定把这个字段加上索引,优化sql 可视化navicat操作
-
MySQL使用B+Tree当索引的优势有哪些
数据库为什么需要索引呢? 我们都是知道数据库的数据都是存储在磁盘上的,当我们程序启动起来的时候,就相当于一个进程运行在了机器的内存当中.所以当我们程序要查询数据时,必须要从内存出来到磁盘里面去查找数据,然后将数据写回到内存当中.但是磁盘的io效率是远不如内存的,所有查找数据的快慢直接影响程序运行的效率. 而数据库加索引的主要目的就是为了使用一种合适的数据结构,可以使得查询数据的效率变高,减少磁盘io的次数,提升数据查找的速率,而不再是愣头青式的全局遍历. 那索引为啥要用B+Tree的数据结构呢?
-
MySQL数据库的事务和索引详解
目录 一.事务: 事务四大特性: 并发事务带来哪些问题?(隔离所导致的一些问题) 事务隔离级别有哪些? MySQL的默认隔离级别: 二.索引: 索引的作用: 索引的分类: 索引准则: 索引的数据结构: 总结 一.事务: 事务是逻辑上的一组操作,要么都成功,要么都失败! ---------------------------------- 1.SQL执行 A:1000元 -->转账200元 B:200元 2.SQL执行 A:800元 -
-
MySQL索引失效原因以及SQL查询语句不走索引原因详解
目录 前言 1. 隐式的类型转换,索引失效 2. 查询条件包含 or,可能导致索引失效 3. like 通配符可能导致索引失效 4. 查询条件不满足联合索引的最左匹配原则 5. 在索引列login_time上使用 mysql 的内置函数 6. 对索引列age进行列运算(如,+.-.*./), 索引不生效 7. 索引字段age上使用(!= 或者 < >, not in),索引可能失效 8. 索引字段上使用 is null, is not null,索引可能失效 (查询结果行数) 9. 左右joi
-
MySQL数据库优化技术之索引使用技巧总结
本文实例总结了MySQL数据库优化技术的索引用法.分享给大家供大家参考,具体如下: 这里紧接上一篇<MySQL数据库优化技术之配置技巧总结>,进一步分析索引优化的技巧: (七)表的优化 1. 选择合适的数据引擎 MyISAM:适用于大量的读操作的表 InnoDB:适用于大量的写读作的表 2.选择合适的列类型 使用 SELECT * FROM TB_TEST PROCEDURE ANALYSE()可以对这个表的每一个字段进行分析,给出优化列类型建议 3.对于不保存NULL值的列使用NOT NUL
-
浅谈MySQL的B树索引与索引优化小结
MySQL的MyISAM.InnoDB引擎默认均使用B+树索引(查询时都显示为"BTREE"),本文讨论两个问题: 为什么MySQL等主流数据库选择B+树的索引结构? 如何基于索引结构,理解常见的MySQL索引优化思路? 为什么索引无法全部装入内存 索引结构的选择基于这样一个性质:大数据量时,索引无法全部装入内存. 为什么索引无法全部装入内存?假设使用树结构组织索引,简单估算一下: 假设单个索引节点12B,1000w个数据行,unique索引,则叶子节点共占约100MB,整棵树最多20